Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Neuroesthetics wikipedia , lookup
Types of artificial neural networks wikipedia , lookup
Metastability in the brain wikipedia , lookup
Recurrent neural network wikipedia , lookup
Nervous system network models wikipedia , lookup
Convolutional neural network wikipedia , lookup
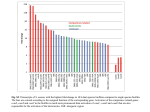
Modeling the Visual Word Form Area Using a Deep Convolutional Neural Network Sandy Wiraatmadja ([email protected]) Garrison W. Cottrell ([email protected]) Computer Science and Engineering Department, University of California, San Diego Introduction The visual word form area (VWFA) is a region of the cortex located in the left fusiform gyrus, that appears to be a waystation in the reading pathway. A recent study using fMRI rapid adaptation (fMRI-RA, Glezer, et al., 2009) provided evidence that neurons in the VWFA are selectively tuned to real words, and that pseudowords are represented in a more graded manner, consistent with the Interactive Activation model (McClelland & Rumelhart, 1981). The experiment consisted of showing subjects repeated words, and then releasing them from adaptation by showing them either a completely different word, or a word with one letter different. The signal increase from adaptation level was the same in both cases. On the other hand, when subjects were adapted to a pseudoword, there was an increase for a 1-letter different pseudoword, and a similar increase to a completely different pseudoword. This contradicts the hypothesis that the VWFA is tuned to the sublexical structure of visual words, and therefore has no preference for real words over pseudowords. The VWFA Model We developed a realistic model of the VWFA by training a deep convolutional neural network to map printed words to their labels. The model is a modification of the LeNet-5 architecture (LeCun, Bottou, Bengio, & Haffner, 1998), and is trained on the 850 words of Basic English, with an additional 47 words used in the Glezer et al. experiment. We used 75 different font types, with three different font sizes, 12, 15, and 18 pt. We also rotated the words slightly, with a rotation angle ranging from -15 to 15 degrees, and translated the center of the text to be at least 75 and 100 pixels away from the top/bottom border and left/right border, respectively, maintaining enough space for longer words. We generated 1,296 images per word, totaling over 1.1 million images. The network achieves 98.5% correct on the test set. We then analyzed this network to see if it can account for the data Glezer et al. found for words and pseudowords. We used the distance in activation at the output level as a measure of the difference in neural representation, and hence the amount of release, for each pair of words. Using an unmodified softmax activation, the distances between the real words are all about 1.414. In order to reveal the “dark knowledge” in the activations for the pseudowords, it was necessary to increase the temperature to 4 on the softmax, but once this was done, the distances matched the data from the Glezer et al. experiment. The current model is just the first step in modeling the VWFA. There are many other experiments that could be modeled by this same architecture. For example, Dehaene et al. (2004) compared activation to the “same” words in different cases and positions, but they also include “circular anagrams,” where pairs of words can transform into one another simply by moving a single letter from the front to the back, and vice versa. An example of circular anagrams are the French words “reflet” and “trefle.” This goes a step further than the “1L” condition because the target word is made up of exactly the same letters as the prime word, but with one location shift, instead of one letter change. If we still observe the same high percent signal change in the fMRI data, or high Euclidean distance in the VWFANet, then we provide stronger support for the hypothesis that the neurons in the VWFA are highly selective to whole words. Acknowledgments This work was supported by NSF grants IIS-1219252 and SMA 1041755 to GWC. References Glezer, L. S., Jiang, X., & Riesenhuber, M. (2009). Evidence for highly selective neuronal tuning to whole words in the ”visual word form area”. Neuron, 62(2), 199–204. McClelland, J. L., & Rumelhart, D. E. (1981). An interactive activation model of context effects in letter perception: Part 1. an account of basic findings. Psychological Review, 88(5), 375-407. Figure 3. Glezer results. Figure 1. VWFA Net Figure 2. Example training images. Figure 4. Our results.