Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
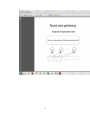
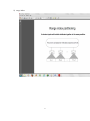
A parallel database system seeks to improve performance through parallelization of various operations, such as loading data, building indexes and evaluating queries. Although data may be stored in a distributed fashion, the distribution is governed solely by performance considerations. Parallel databases improve processing and input/output speeds by using multiple CPUs and disks in parallel. Centralized and client–server database systems are not powerful enough to handle such applications. In parallel processing, many operations are performed simultaneously, as opposed to serial processing, in which the computational steps are performed sequentially. Thus they are preferred for the following reasons: High performance - short response time or total time - good load balancing among processors High availability - handling failures of hardware elements - redundancy and consistency Extensibility - more processing and storage power can be added Parallel databases can be roughly divided into two groups, the first group of architecture is the multiprocessor architecture, the alternatives of which are the followings : Shared memory architecture, where multiple processors share the main memory space, as well as mass storage (e.g. hard disk drives). 1 2 Shared disk architecture, where each node has its own main memory, but all nodes share mass storage, usually a storage area network. In practice, each node usually also has multiple processors. 3 Shared nothing architecture, where each node has its own mass storage as well as main memory. 4 DATA PARTITIONING IN PARALLEL DATABASES The whole process of partitioning involves distributing the tuples of a relation over several disks. This is done in a bid to allow parallel databases to exploit the I/O bandwidth of multiple disks by reading and writing them in parallel. The relations are declustered (partitioned horizontally) based on 3 different functions: i) round-robin 5 6 ii) range index 7 iii) hash function 8 PARALLEL QUERY PROCESSING Parallel query processing 1. translation- of the relational algebra expression to a query tree 2. optimisation- reordering of join operations in the query tree and choose among different join algorithms to minimise the cost of the execution 3. parallelisation- transforming the query tree to a physical operator tree and loading the plan to the processors 4. execution- running the concurrent transactions (example on how to process the query we did in class) 9 Examples of Parallel Database Systems include: Research systems and projects Gamma Bubba Prisma/DB HC16-186 XPRS project Volcano project Commercial systems Oracle Parallel Server Sybase MPP Informix Online XPS IBM DB2 Parallel Edition NCR Teradata DBS Tandem NonStop SQL 10