
A comparative study of survivial models for breast cancer
... supervised classification the regression methods, but demands the adoption of specific survival analysis techniques, like the semi-parametric Cox’s proportional hazards model. • When the number of explanatory variables exceeds by far the number of petients in the sample cohort, overfitting of naivel ...
... supervised classification the regression methods, but demands the adoption of specific survival analysis techniques, like the semi-parametric Cox’s proportional hazards model. • When the number of explanatory variables exceeds by far the number of petients in the sample cohort, overfitting of naivel ...

Editorial Computational Intelligence in Image Processing
... international conference proceedings. When the idea of this special issue was first conceived, the goal was to mainly expose the readers to the cutting-edge research and applications that are going on across the domain ...
... international conference proceedings. When the idea of this special issue was first conceived, the goal was to mainly expose the readers to the cutting-edge research and applications that are going on across the domain ...

Horizontal gene transfer and microbial evolution: Is the Tree-of
... find that tree that explains sequence data with minimum number of substitutions (tree includes hypothesis of sequence at each of the nodes) Maximum Likelihood analyses given a model for sequence evolution, find the tree that has the highest probability under this model. This approach can also be use ...
... find that tree that explains sequence data with minimum number of substitutions (tree includes hypothesis of sequence at each of the nodes) Maximum Likelihood analyses given a model for sequence evolution, find the tree that has the highest probability under this model. This approach can also be use ...

Amsterdam 2004 - Theoretical Biology & Bioinformatics
... to eliminate false-positives and to identify groups that contain multidomain proteins by examining the pictorial representation of the BLAST search outputs. The sequences of detected multidomain proteins are split into single-domain segments and steps 1–4 are repeated with these sequences, which res ...
... to eliminate false-positives and to identify groups that contain multidomain proteins by examining the pictorial representation of the BLAST search outputs. The sequences of detected multidomain proteins are split into single-domain segments and steps 1–4 are repeated with these sequences, which res ...

doc - BeanBeetles.org
... Use multiple trees to model the most likely evolutionary relationship between taxa. ...
... Use multiple trees to model the most likely evolutionary relationship between taxa. ...

WAS template - Write About Science
... Long, short, research, review, all papers have: 1. An introduction (first or several paragraphs) 2. Description of methods and results (several paragraphs to many pages) 3. Discussion of the relationship of this work to previous work, and potential implications 4. A short conclusion ...
... Long, short, research, review, all papers have: 1. An introduction (first or several paragraphs) 2. Description of methods and results (several paragraphs to many pages) 3. Discussion of the relationship of this work to previous work, and potential implications 4. A short conclusion ...
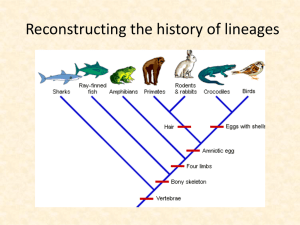
12-History of Lineages
... How can we reconstruct the history of evolution without seeing speciation events? Identification of key characters that represent evolved ...
... How can we reconstruct the history of evolution without seeing speciation events? Identification of key characters that represent evolved ...


OUTLINE
... Fisher Exact Test Misclassification cost and rate Cost-complexity and complexity parameter Optimal sub-trees ...
... Fisher Exact Test Misclassification cost and rate Cost-complexity and complexity parameter Optimal sub-trees ...

F(x)
... of the data or on formal models for the data Data= smooth + rough where the smooth is the underlying regularity or pattern in the data. The objective of EDA is to separate the smooth from the rough with minimal use of formal mathematics or ...
... of the data or on formal models for the data Data= smooth + rough where the smooth is the underlying regularity or pattern in the data. The objective of EDA is to separate the smooth from the rough with minimal use of formal mathematics or ...


Storage and Manipulation of Data by Computers for Determinative
... to keep track of the history, it would be more practical t o keep the information in a computer-indexed microfilm system. Perhaps synonymous strain numbers could be stored in the computer, but little else of the history of a strain that passes from laboratory t o laboratory could be justified for th ...
... to keep track of the history, it would be more practical t o keep the information in a computer-indexed microfilm system. Perhaps synonymous strain numbers could be stored in the computer, but little else of the history of a strain that passes from laboratory t o laboratory could be justified for th ...

Prior Knowledge Driven Causality Analysis in Gene Regulatory
... TDA10 might play a signal transduction role in late M/early G1 phase. ...
... TDA10 might play a signal transduction role in late M/early G1 phase. ...

created by shannon martin gracey
... If, under a given assumption, the ________________________ of a particular observed is extremely ______________________, we conclude that the ___________________________ is probably not ...
... If, under a given assumption, the ________________________ of a particular observed is extremely ______________________, we conclude that the ___________________________ is probably not ...

A Bayesian Framework for Inference of the Genotype–Phenotype
... network from the natural genetic variation in segregating populations. Networks are decomposed into local models with continuous children and scored using a Bayesian posterior probability. Structural priors that can encode sparsity and biological knowledge are used to constrain the model space. The ...
... network from the natural genetic variation in segregating populations. Networks are decomposed into local models with continuous children and scored using a Bayesian posterior probability. Structural priors that can encode sparsity and biological knowledge are used to constrain the model space. The ...

Document
... To identify the groups of samples that consistently clustered together in the 24 dendrograms (that is robust consensus clusters obtained independently from a given clustering method and/or threshold for unsupervised genes selection), we first calculated a consensus dendrogram using an algorithm prop ...
... To identify the groups of samples that consistently clustered together in the 24 dendrograms (that is robust consensus clusters obtained independently from a given clustering method and/or threshold for unsupervised genes selection), we first calculated a consensus dendrogram using an algorithm prop ...

Presentation Title Goes Here
... data set from each scenario. The proposed ODP approach is in black and the other methods are in gray. In general, the data sets increase in complexity from panels (a) to (d). (a) In this scenario, two groups are compared, there is perfectly symmetric differential expression, and the variances are si ...
... data set from each scenario. The proposed ODP approach is in black and the other methods are in gray. In general, the data sets increase in complexity from panels (a) to (d). (a) In this scenario, two groups are compared, there is perfectly symmetric differential expression, and the variances are si ...

Phylogeography
... Dn – Nested clade distance (geographic relationship to other same level categories) I-T – average distance between interior and tip clades within nested group Use random permutation testing to test significance of associations ...
... Dn – Nested clade distance (geographic relationship to other same level categories) I-T – average distance between interior and tip clades within nested group Use random permutation testing to test significance of associations ...

3 Related works
... defined as g ( xi ) . In this method convergence of the sequence xi should be checked. [2] [10] 2.2 Newton Method Using fixed point method in which f xi xi 1 xi is called Newton f ' xi method. There are some special methods for polynomials. The first problem with numerical methods i ...
... defined as g ( xi ) . In this method convergence of the sequence xi should be checked. [2] [10] 2.2 Newton Method Using fixed point method in which f xi xi 1 xi is called Newton f ' xi method. There are some special methods for polynomials. The first problem with numerical methods i ...

Microarrays 2 BMI 731 Winter 2005
... nonlinear modeling, classical statistical tests, time-series analysis, classification, clustering, ...) and graphical techniques, and is highly extensible. The S language is often the vehicle of choice for research in statistical methodology, and R provides an Open Source route to participation in t ...
... nonlinear modeling, classical statistical tests, time-series analysis, classification, clustering, ...) and graphical techniques, and is highly extensible. The S language is often the vehicle of choice for research in statistical methodology, and R provides an Open Source route to participation in t ...

“biology driven” challenges for the stc cs researchers
... – Most current techniques in data analysis are rendered useless because of this. ...
... – Most current techniques in data analysis are rendered useless because of this. ...

Presentation Tuesday
... mutations. Slower (requires in principle the examination of all trees), but branch & bound makes it faster ...
... mutations. Slower (requires in principle the examination of all trees), but branch & bound makes it faster ...

Infinite Sites Model
... • Under the assumption of the infinite sites model all SNP pairs exhibit the property no more that 3 out of the possible 4 allele combinations occur • Direct consequence of only one mutation per site • Showing that all SNP pair combinations satisfy the four gamete test is a necessary and sufficient ...
... • Under the assumption of the infinite sites model all SNP pairs exhibit the property no more that 3 out of the possible 4 allele combinations occur • Direct consequence of only one mutation per site • Showing that all SNP pair combinations satisfy the four gamete test is a necessary and sufficient ...

ppt - Chair of Computational Biology
... uncertain alignment left with 76% of the sequence of each gene on average. Tree construction with PAUP by branch-and-bound algorithm which guarantees to find the optimal tree. Estimate tree reliability using non-parametric bootstrap resampling. Analysis of the 106 genes gave more than 20 alternati ...
... uncertain alignment left with 76% of the sequence of each gene on average. Tree construction with PAUP by branch-and-bound algorithm which guarantees to find the optimal tree. Estimate tree reliability using non-parametric bootstrap resampling. Analysis of the 106 genes gave more than 20 alternati ...

Phylogenetic relationships among iguanian lizards using alternative
... mixture model that employs a reversible-jump algorithm to estimate the number of rate matrices that best explains the data. This method chooses the appropriate number of independent rate matrices using Bayes factors during the MCMC procedure. By default, BayesPhylogenies assigns uniform priors on a ...
... mixture model that employs a reversible-jump algorithm to estimate the number of rate matrices that best explains the data. This method chooses the appropriate number of independent rate matrices using Bayes factors during the MCMC procedure. By default, BayesPhylogenies assigns uniform priors on a ...