Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
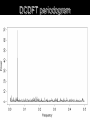
Basic Time Series Analyzing variable star data for the amateur astronomer What Is Time Series? Single variable x that changes over time t can be multiple variables, W W W A T Light curve: x = brightness (magnitude) Each observation consists of two numbers Time t is considered perfectly precise Data (observation/measurement/estimate) x is not perfectly precise Two meanings of “Time Series” TS is a process, how the variable changes over time TS is an execution of the process, often called a realization of the TS process A realization (observed TS) consists of pairs of numbers (tn,xn), one such pair for each observation Goals of TS analysis Use the process to define the behavior of its realizations Use a realization, i.e. observed data (tn,xn), to discover the process This is our main goal Special Needs Astronomical data creates special circumstances for time series analysis Mainly because the data are irregularly spaced in time – uneven sampling Sometimes the time spacing (the “sampling”) is even pathological – with big gaps that have periods all their own Analysis Step 1 Plot the data and look at the graph! (visual inspection) Eye+brain combination is the world’s best pattern-recognition system BUT – also the most easily fooled “pictures in the clouds” Use visual inspection to get ideas Confirm them with numerical analysis Data = Signal + Noise True brightness is a function of time f(t) it’s probably smooth (or nearly so) There’s some measurement error ε it’s random It’s almost certainly not smooth Additive model: data xn at time tn is sum of signal f(tn) and noise εn xn = f(tn) + εn Noise is Random That’s its definition! Deterministic part = signal Random part = noise Usually – the true brightness is deterministic, therefore it’s the signal Usually – the noise is measurement error Achieve the Goal Means we have to figure out how the signal behaves and how the noise behaves For light curves, we usually just assume how the noise behaves But we still should determine its parameters What Determines Random? Probability distribution (pdf or pmf) pdf: probability that the value falls in a small range of width dε, centered on ε is Probability = P(ε) dε pmf: probability that the value is ε is P(ε) pdf/pmf has some mean value μ pdf/pmf has some standard deviation σ Most Common Noise Model i.i.d. = “independent identically distributed” Each noise value is independent of others P12(x1,x2) = P1(x1)P2(x2) They’re all identically distributed P1(x1) = P2(x2) What is the Distribution? Most common is Gaussian (a.k.a. Normal) P( ) e 1 2 2 ( ) / 2 2 Noise Parameters μ = mean = <ε> Usually assumed zero (i.e., data unbiased) σ2 = variance = <(ε-μ)2> σ = √(σ2) = standard deviation Typical value is 0.2 mag. for visual data Smaller for CCD/photoelectric (we hope!) Note: don’t diparage visual data, what they lack in individual precision they make up by the power of sheer numbers Is the default noise model right? No! We know it’s wrong Bias: μ values not zero NOT identically distributed – different observers have different μ, σ values Sometimes not even independent (autocorrelated noise) BUT – i.i.d. Gaussian is still a useful working hypothesis, so W W W A T Even if … Even if we know the form of the noise … We still have to figure out its parameters Is it unbiased (i.e. centered at zero so μ = 0)? How big does it tend to be (what’s σ )? And … We still have to separate the signal from the noise And of course figure out the form of the signal, i.e., Figure out the process which determines the signal Whew! Simplest Possible Signal None at all! f(t) = constant = βo This is the null hypothesis for many tests But we can’t be sure f(t) is constant … … that’s only a model of the signal Separate Signal from Noise We already said data = signal + noise Therefore data – signal = noise Approximate signal by model Approximate noise by residuals data – model = residuals xn – yn = R n If model is correct, residuals are all noise Estimate Noise Parameters Use residuals Rn to estimate noise parameters 1 Estimate mean μ by average R N R N j 1 Estimate standard deviation σ by sample standard deviation N s (R j 1 j R) N 1 2 j Averages When we average i.i.d. noise we expect to get the mean Standard deviation of the average (usually called the standard error) is less than standard deviation of the data ( ave) " s.e." ( raw) N Confidence Interval 95% confidence interval is the range in which we expect the average to lie, 95% of the time About 2 standard errors above or below the expected value 95% C.I . x 2 ( ave) x 2 ( raw) / N Does average change? Divide time into bins Usually of equal time width (often 10 days) Sometimes of equal number of data N Compute average and standard deviation within each bin IF signal is constant AND noise is consistent, THEN expected value of data average will be constant So: do the “bin averages” show more variation than is expected from noise? ANOVA test Compare variance of averages to variance of data (ANalysis Of VAriance = ANOVA) In other words… compare variance between bins to variance within bins “F-test” gives a “p-value,” probability of getting that result IF the data are just noise Low p-value probably NOT just noise Either we haven’t found all the signal Or the noise isn’t the simple kind ANOVA test 50-day averages: Fstat df.between df.within p 0.315563 2 147 0.729871 NOT significant 10-day averages: Fstat df.between df.within p 0.728138 14 135 0.743133 NOT significant ANOVA test 50-day averages: Fstat df.between df.within 13.25758 2 147 IS significant p 5e-06 10-day averages: Fstat df.between df.within p 2.546476 14 135 0.002879 IS significant Averages Rule! Excellent way to reduce the noise because σ(ave) = σ(raw) / √N Excellent way to measure the noise Very little change to signal unless signal changes faster than averaging time So in most cases averages smooth the data, i.e., reduce noise but not signal Decompose the Signal Additive model: sum of component signals Non-periodic part sometimes called trend sometimes called secular variation Repeating (periodic) part or almost-periodic (pseudoperiodic) part can be multiple periodic parts (multiperiodic) f(t) = S(t) + P(t) Periodic Signal Discover that it’s periodic! Find the period P Or frequency ν Pν = 1 ν = 1 / P Find amplitude A = size of variation P=1/ν Often use A to denote the semi-amplitude, which is half the full amplitude Find waveform (i.e., cycle shape) Periodogram Searches for periodic behavior Test many frequencies (i.e., many periods) For each frequency, compute a power Higher power more likely it’s periodic with that frequency (that period) Plot of power vs frequency is a periodogram, a.k.a. power spectrum Periodograms Fourier analysis Fourier periodogram Don’t use DFT or FFT because of uneven time sampling Use Lomb-Scargle modified periodogram OR DCDFT (date-compensated discrete Fourier transform) Folded light curve AoV periodogram Many more … these are the most common DCDFT periodogram AoV periodogram Lots lots more … Non-periodic signals Periodic but not perfectly periodic (parameters are changing) What if the noise is something “different”? Come to the next workshop! Enjoy observing variables See your own data used in real scientific study (AJ, ApJ, MNRAS, A&A, PASP, …) Participate in monitoring and observing programs Assist in space science and astronomy Make your own discoveries! http://www.aavso.org/