Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
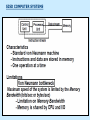
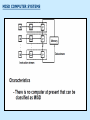
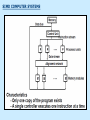
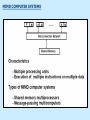
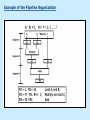
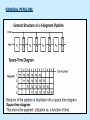
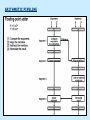
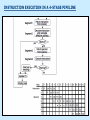
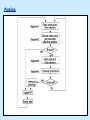
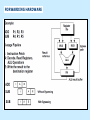
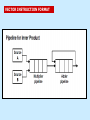
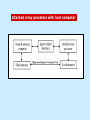
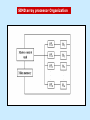
Pipeline And Vector Processing Parallel Processing Execution of Concurrent Events in the computing process to achieve faster Computational Speed The purpose of parallel processing is to speed up the computer processing capability and increase its throughput, that is, the amount of processing that can be accomplished during a given interval of time. The amount of hardware increases with parallel processing, and with it, the cost of the system increases. However, technological developments have reduced hardware costs to the point where parallel processing techniques are economically feasible. Parallel processing according to levels of complexity At the lower level Serial Shift register VS parallel load registers At the higher level Multiplicity of functional units that performer identical or different operations simultaneously. Parallel Computers SISD COMPUTER SYSTEMS Von Neumann Architecture MISD COMPUTER SYSTEMS SIMD COMPUTER SYSTEMS MIMD COMPUTER SYSTEMS PIPELINING A technique of decomposing a sequential process into suboperations, with each subprocess being executed in a partial dedicated segment that operates concurrently with all other segments. A pipeline can be visualized as a collection of processing segments through which binary information flows. The name “pipeline” implies a flow of information analogous to an industrial assembly line. Example of the Pipeline Organization OPERATIONS IN EACH PIPELINE STAGE GENERAL PIPELINE Cont. Speedup ratio of pipeline Cont. PIPELINE AND MULTIPLE FUNCTION UNITS Cont. ARITHMETIC PIPELINE Cont. See the example in P. 310 INSTRUCTION CYCLE INSTRUCTION PIPELINE INSTRUCTION EXECUTION IN A 4-STAGE PIPELINE Pipeline Space time diagram MAJOR HAZARDS IN PIPELINED EXECUTION Structural hazards (Resource Conflicts): Hardware resources required by the instructions simultaneous overlapped execution cannot be met. Data hazards (Data Dependency Conflicts): An instruction scheduled to be executed in the pipeline requires the result of a previous instruction, which is not yet available. Control hazards (Branch difficulties): Branches and other instructions that change the PC make the fetch of the next instruction to be delayed. Data hazards Control hazards STRUCTURAL HAZARDS Occur when some resource has not been duplicated enough to allow all combinations of instructions in the pipeline to execute. Example: With one memory-port, a data and an instruction fetch cannot be initiated in the same clock. The Pipeline is stalled for a structural hazard <- Two Loads with one port memory -> Two-port memory will serve without stall DATA HAZARDS FORWARDING HARDWARE INSTRUCTION SCHEDULING CONTROL HAZARDS CONTROL HAZARDS CONTROL HAZARDS VECTOR PROCESSING There is a class of computational problems that are beyond the capabilities of conventional computer. These problems are characterized by the fact that they require a vast number of computations that will take a conventional computer days or even weeks to complete. VECTOR PROCESSING VECTOR PROGRAMMING VECTOR INSTRUCTIONS Matrix Multiplication The multiplication of two nxn matrices consists of n2 inner products or n3 multiply-add operations. Example: Product of two 3x3 matrices c11= a11b11+a12b21+a13b31 This requires 3 multiplications and 3 additions. The total number of multiply-add required to compute the matrix product is 9x3=27. In general, the inner product consists of the sum of k product terms of the form C = A1B1+A2B2+A3B3+…+Ak Bk C = A1B1+A5B5+A9B9+A13 B13+… +A2B2+A6B6+A10B10+A14 B14+… +A3B3+A7B7+A11B11+A15 B15+… +A4B4+A8B8+A12B12+A16 B16+… VECTOR INSTRUCTION FORMAT MULTIPLE MEMORY MODULE AND INTERLEAVING MULTIPLE MEMORY MODULE AND INTERLEAVING MULTIPLE MEMORY MODULE AND INTERLEAVING ARRAY PROCESSOR attached array processor with host computer SIMD array processor Organization Don’t forget, try to solve the questions of the chapter