Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
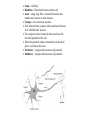
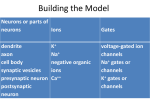
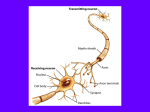
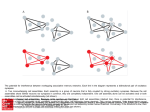
Brains •Your brain is where you think - either •Brains cause minds •Mysticism •Brains are made up of neurons – and other cells •Neurons appear to be the primary method of information transfer – are there others? Soma = cell body Dendrites = fibers that branch out from cell Axon = single long fiber, eventually branches into strands and connects to other neurons Synapse = the connection junction Each neuron forms synapses with somewhere between 10 to 100,000 other neurons The synapses release chemicals that raise/lower the electrical potential of the cell When the potential releases a threshold, an electrical pulse is sent down the axon Excitatory = synapses that increase cell potential Inhibitory = synapses that decrease cell potential Learning: synaptic connections change their excitatory/inhibitory nature neurons form new connections groups of neurons can migrate from 1 location to another in the brain Artificial Neural Networks Many simple processing elements (nodes) Nodes are highly interconnected Localist processing High parallelism Self organizing Distributed solution Fault tolerant Non-parametric – all you need is a set of labeled examples from the problem domain Human Visual System Perceptron x1 w1 x2 w2 x3 w3 x4 w4 1 if net Z 0 if net wi c(T Z ) xi (Delta Rule) Calculating the direction of steepest increase in error Derivation of the gradient descent training rule We want to find out how munging with the weights changes the error – take the derivative the error function with respect to the weights! The gradient (tells us the direction of steepest increase in the error surface): E E E E w , ,..., w w w 1 n 0 Once we know that, the weight update formula is then w w w Where w E w Or alternately: wi wi wi , wi E wi Derivation of the gradient descent training rule for a single layer network E 1 2 t o d d wi wi 2 d D 1 t d od 2 2 d D wi 1 t d od 2t d od 2 d D wi t d w xd t d od wi d D t d od xid d D So, wi t d od xid d D Multilayer Perceptron Z j f net j 1 1e ne t j j t j Z j f ' net j (output node) j k w jk f' net j (hidden node) k wij cxi j More on Backpropagation: Momentum w ji ( n ) j x ji w ji ( n 1) Representational power of MLPs Boolean functions: Can represent any Boolean function with 2 layers of nodes. Worse case requires exponential number of nodes in the hidden layer. Continuous functions: Every bounded continuous function can be approximated with arbitrarily small error with a two layer network. Arbitrary functions: Can approximate any function to arbitrary accuracy with a network with 3 layers. Output layer uses linear units. Properties of backpropagation training algorithm: The bad o Not guaranteed to converge because error surface may contain many local minima o For one case (3 node network) training problem shown to be NP-Complete – probably NPcomplete in general o Fudge factors affect performance – lrate, momentum, architecture, etc. o Difficult to know how to set up network, what it means after you’re done The good o In general, the bigger the network the less likely it will be for it to fall into a sub-optimal local minima during training o Can usually get good results in less than exponential time – but still take a long time! o Have proven to be very good function approximaters in practice