Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
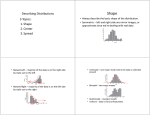
Chapter 4 Displaying and Summarizing Quantitative Data Math2200 Example: Tsunamis and Earthquake - The most disastrous tsunami - Dec 26, 2004, in Sumatra - Earthquake: magnitude 9.0 - Killed 225,000 people Question • Was the earthquake that caused it truly unusually big? • US National Geophysical Data Center • Data on the magnitude of underlying earthquakes for 1240 historical tsunamis • How do we learn the data Year Country Magnitude -1300 GREECE 6 -479 GREECE 6.7 -426 GREECE 7.1 -373 GREECE 7.3 -330 GREECE 7 -227 GREECE 7.2 -57 ALBANIA 6.6 -26 CYPRUS ISLAND 7.3 2003 NEW ZEALAND 7.5 2003 JAPAN 8.1 2003 JAPAN 6.8 2003 USA 7.2 2004 INDONESIA 6.5 2004 JAPAN 7.2 2004 JAPAN 7.4 2004 INDONESIA 9 Histogram • Display a quantitative variable by discretizing it into equal-width bins • Counts for the bins give the distribution of the quantitative variable • Make a bar chart based on these counts and align the bar according to the bin values, we get a histogram – Do not leave gaps between bars 200 150 100 50 0 Frequency 250 300 350 Historgram of earthquake magnitude 3 4 5 6 Magnitude 7 8 9 150 100 0 50 Frequency 100 50 0 Frequency 150 With different number of bins 3 4 5 6 7 8 9 3 4 5 8 9 7 8 9 500 400 300 100 200 Frequency 250 150 0 50 0 Frequency 7 Magnitude 350 Magnitude 6 3 4 5 6 Magnitude 7 8 9 3 4 5 6 Magnitude Summarize the histogram • • • • • Magnitudes are typically around 7 Most are between 5.5 and 8.5 Minimum is around 3 Maximum is around 9 Why there is a sharp peak in the middle? Stem-and-Leaf Plot • John W. Tukey • Useful for small data sets • Similar to histogram, but the bars give numerical values more than counts 5|6 6 | 0444 6 | 8888 7 | 2222 7 | 6666 8 | 000044 8|8 Pulse-rates of 24 woman (8|8 means 88 beats/min) Handwriting • Handwriting may not give the same space for different digits. That violates the area principle • When you make a stem-and-leaf plot, be sure to give each digit the same width. Dotplot • Replace digits in stem-and-leaf plot by dots How to summarize the distribution of a quantitative variable? • shape mode, symmetry, outlier • center mean, median • Spread sd, IQR Shape • Peak / Mode – Is there a peak? If so, how many peaks? – For quantitative variables, the mode is where the peak is at. – No peak: uniform – One peak: unimodal – Two peaks: bimodal – More than two peaks: multimodal 0 0 20 20 60 -2 80 100 100 0.2 0 0.4 0.6 2 4 x 0.8 6 60 80 0.0 40 Frequency 40 Frequency 0 0 2 5 6 8 10 Frequency 4 Frequency 15 10 20 12 uniform unimodal 1.0 -2 -5 -1 0 x x bimodal multimodal 0 x 1 2 5 Shape • Symmetry – Tail: thinner ends of a distribution – Skewed: If one tail stretches out farther than the other, we say the histogram is skewed to the side of the longer tail skewed to the left 80 60 80 0.0 0.5 1.0 1.5 x1 2.0 2.5 3.0 20 0 0 20 40 40 Frequency 60 Frequency 0 20 40 Frequency 60 80 100 100 symmetric 100 skewed to the right -3 -2 -1 0 x 1 2 3 -3.0 -2.5 -2.0 -1.5 x2 -1.0 -0.5 0.0 Shape 10 5 0 Frequency – Those that stand away from the body of the distribution – The judgment is vague sometimes 15 • Outliers -6 -4 -2 0 2 Center • When a histogram is symmetric and unimodal, the center is obvious – The corresponding numerical value can be taken as the sample average, or say the sample mean – The sample mean is actually where the histogram balances Center • For skewed distribution – The sample mean is dragged to the side of the longer tail – Usually, much more than 50% values will be less or larger than the sample mean – Median is more appropriate • Median is the value that splits the data in half Finding the median • Suppose that we have n numbers • Order them first – If n is odd, the median is middle value. That is, the value in the (n+1)/2 position – If n is even, we take median as the average of the values in positionsn/2 and n/2+1 Mean versus median • Extreme values / outliers: – Median only considers the order of the values, so it is resistant to extreme values – Mean is very sensitive • Skewed distribution – Median is preferred than mean • Unimodal and symmetric distribution – Mean is preferred because it uses more information from the data Spread To quantify the variation • Range • Interquartile range (IQR) • Standard deviation Range • Range = max – min • Very sensitive to extreme values Interquartile Range • Quartiles – Q1 (lower quartile or the 25th percentile): one quarter of the data lies below Q1 – Q2 (median or the 50th percentile) – Q3 (upper quartile or the 75th percentile): one quarter of the data lies above Q3 • IQR = Q3-Q1 – Not sensitive to extreme values • How to find Q1 and Q3? – Split the order values into two halves using the median – Q1 is the median of the first half – Q3 is the median of the second half Standard deviation • Sample variance = average of squared deviations • Standard deviation (sd) – Sensitive to extreme values σX in TI-83 How to obtain these numbers using TI-83? • • • • • Press STAT Move the cursor to CALC Press 1 The screen shows 1-Var Stats Put the list you want the statistics for. For example, L1. • Press ENTER, then you will see – Sample mean, sample sum, sample sum squares, sample standard deviation (Sx),σx (the same as except divided by n instead of n-1), sample size n, minimum, Q1, median, Q3, maximum Summary • Make a picture – Histogram, stem-and-leaf plot, dot plot • Shape – How many modes? – Symmetric? – Outliers? • If there are outliers, summarize once with the outliers and another time without the outliers • Center and spread – Skewed distribution: median and IQR – Symmetric and unimodal distribution: mean and sd What can go wrong? • Do not use what we learned in chapter 4 for a categorical variable – Do not make histogram of a categorical variable – Do not look for shape and center and spread of a bar chart – Do not use mean, sd, IQR, etc. for a categorical variable • • • • Graph with bars are not always histograms or bar charts Choose a bin width appropriate to the data Check the summary numbers. Do they make sense? Do not worry about small differences when using different methods – No need to use too many digits for the summary numbers – Using one or two more digits than data is enough • Do not round in the middle of a calculation • Multiple modes, outliers (make a picture)