Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Recurrent
Network
Inputs
Outputs
Motivation
• Associative Memory Concept
• Time Series Processing
– Forecasting of Time series
– Classification Time series
– Modeling of Time series
– Mapping one Time series onto other
• Signal Processing ( a field very close to TS processing)
• Optimization problems (like Traveling Salesman)
Address – addressable Vs.
content addressable Memory
AM provide an approach of storing and retrieving data
based on content rather than storage address.
Storage in a NN is distributed throughout the system in the
net’s weights, hence a pattern does not have a storage .
Auto associative vs. HeteroAssociative
Memory
• Each association is an i/p o/p vector pair , s:f.
Association (for two patterns s and f)
s=f
auto-associative memory
s = !f
hetero-associative memory
So What’s the difference?
evoke associated
patterns
Associative Recalls
recall a pattern
by part of it
evoke/recall with incomplete/
noisy patterns
• The net not only learns
the specific patterns
pairs that were used for
training, but is also able
to recall the desired
response pattern when
given an I/P stimulus
that is similar, but not
identical, to the training
I/P.
Training an AM NN
• The original patterns must be converted to an
appropriate representation for computation.
“on” →+1 , “off”→0 (binary representation)
“on”→+1, “off”→-1 (bipolar representation).
OR
• Two common training methods for single layer
nets are usually :
– Hebbian learning rule
– Its variations–gradient descent
Hebbian Learning Rule
• ”When one cell repeatedly assists in firing another, the axon of the first cell
• develops synaptic knobs (or enlarges them if they already exist) in contact
• with the soma of the second cell.” (Hebb, 1949)
• In an associative neural net, if we compare two pattern components (e.g. pixels)
within many patterns and find that they are frequently in:
a) the same state, then the arc weight between their NN nodes should be +ve
b) different states, then the arc weight between their NN nodes shoud be -ve
The weights must store the average correlations between all pattern
components across all patterns. A net presented with a partial pattern can then
use the correlations to recreate the entire pattern.
Weights = Average Correlations
Quantative definition of Hebbian Learning Rule
• Auto-Association:
w jk i pk i pj
* When the two components are the same (different), increase (decrease) the weight
Hetero-Association:
w jk i pk o pj
i = input component
o = output component
Ideally, the weights will record the average correlations across all patterns:
P
Auto:
w jk i pk i pj
p 1
P
Hetero:
w jk i pk o pj
p 1
Hebbian Principle: If all the input patterns are known prior to retrieval time,
then init weights as:
Auto:
1 P
w jk i pk i pj
P p 1
Hetero:
1 P
w jk i pk o pj
P p 1
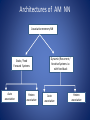
Architectures of AM NN
Associative memory NN
Static / Feed
Forward Systems
Auto
associative
Hetero
associative
Dynamic /Recurrent /
Iterative Systems i.e.
with feed back
Auto
associative
Hetero
associative
Mapping of Inputs to Outputs
Information Recording
Information Retrieval
• M is expressed as the
prototype vectors stored.
• Mapping: x →v
•Linear or nonlinear
• v = M [x]
• Input a key vector x and find a desired vector.
• M is matrix type operator
• v previously stored in the network.
Static vs. Dynamic
Static Memory
Recurrent Autoassociative Memory
The operator M2 operates at present instant k on the present input xk and output
vk to produce the o/p in the next instant k+1 Δ is a unit delay needed for cyclic
operation. The pattern is associated to itself (auto-)
Heteroassociative Memory Net
• Memory Association of pairs (x,v)This AM operates with a cycle of 2Δ.
• It associates pairs of vectors (x(i),v(i)).
Hop Field Model
(A recurrent auto associative network)
The input x0 is used to initialize v0, i.e. x0= v0, and the input is then
removed for the following evolution:
Operator M2 consists of multiplication by a weight matrix followed by the
ensemble of non-linear mapping operations vi = f(neti) performed by the
layer of neurons.
Hopfield Model
Hopfields AutoassociativeMemory
(1982,1984)
Distributed Representation
Info is stored as a pattern of activations/weights
Multiple info is imprinted on the same network
Content-addressable memory
Store patterns in a network by adjusting weights
To retrieve a pattern, specify a portion
Distributed, asynchronous control
Individual processing elements behave independently
Fault tolerance
Few processors can fail, and the network will still work
Active or Inactive
processing units are in one of two states
Units are connected with weighted, symmetric connections
Multiple-loop feedback system
with no self-feedback
X1
weight
1
+1
-1
+1
-1
X2
2
Example of Hopfield NN for
3 dimensional input data
-1
3
X3
-1
neuron
Attribute 3 of input (x1,x2,x3)
Execution:
Input pattern attributes are initial states of neurons
Repeatedly update state of neurons asynchronously until states do not change
Hopfields Autoassociative Memory
• Input vectors values are in {-1,1} (or {0,1}).
• The number of neurons is equal to the input dimension.
• Every neuron has a link from every other neuron (recurrent
• architecture) except itself (no self-feedback).
• The activation function used to update a neuron state is the
• sign function but if the input of the activation function is 0
then the new output (state) of the neuron is equal to the old one.
•
The weights are symmetric
w w
ij
ji
NN Training
1. Storage: . Let f1, f2, … , fM denote a known set of N-dimensional
fundamental memories. The weights of the network are:
w
ji
•
•
f
•
x (n)
i
,i
1
M
0
M
f ,i f , j
1
j i
j i
i-th component of the fundamental memory.
State of neuron i at time n.
• wji is the weight from neuron i to neuron j.
• The elements of the vector fμ are in {-1,+1}. Once they are computed, the
synaptic weights are kept fixed.
• N: input dimension ;
• M: number of patterns (called fundamental memories) are used to
compute the weights.
NN Training
• Each stored pattern (fundamental memory) establishes a
correlation between pairs of neurons: neurons tend to be
of the same sign or opposite sign according to their value
in the pattern.
• If wji is large, this expresses an expectation that neurons i
and j are positively correlated. If it is small (negative) this
indicates a negative correlation.
•
wij xi x j
i, j
will thus be large for a state x equal to a
fundamental memory (since wij will be positive if the
product xi xj > 0 and negative if xi xj < 0).
• The negative of the sum will thus be small.
NN Execution
2. Initialization: Let x denote an input vector(
probe) presented to the network. The
algorithm is initialized by setting:
x (0) x
j
probe, j j = 1……N
x
probe, j
x (0)
j
is the j-th element of the probe vector x probe.
is the state of neuron j at time t =0
NN Execution
3. Iteration Until Convergence
Update the elements of network state vector
x(n) asynchronously (i.e. randomly and one at
the time) according to the rule:
N
x (t 1) sgn j 1 w x (t )
j
ji i
Repeat the iteration until the state vector x remains
unchanged.
NN Execution
• Outputting: Let x fixed denote the fixed point
(or stable state, that is such that x(t+1)=x(t))
computed at the end of step 3. The resulting
output y of the network is:
y x
fixed
Pictorial Execution of Hop field Net
3. Retrieval
1. Auto-Associative Patterns to Remember
1
2
1
2
3
4
3
4
Comp/Node value legend:
dark (blue) with x => +1
dark (red) w/o x => -1
light (green) => 0
2. Distributed Storage of All Patterns:
-1
1
2
1
3
4
• No. Of neuron = dimension of pattern
• Fully connected
• Weights = avg correlations across
all patterns of the corresponding units
1
2
3
4
1
2
3
4
1
2
3
4
1
2
3
4
Hopfield Network Example
1. Patterns to Remember
p1
p2
1
2
3
1
4
3
3. Build Network
p3
1
2
4
3
1/3
2
1
2
4
-1/3
-1/3
p1 p2 p3
Avg
1 1 -1
1 -1 -1
1/3
-1/3
1
2
3
4
W14 -1
1
1
1/3
W23 1
-1
1
1/3
W24 -1
1 -1
-1/3
W34 -1
-1 -1
-1
[+]
1/3
4
3
W12
W13
[-]
1/3
-1
4. Enter Test Pattern
1/3
+1
1/3
-1/3
-1/3
1/3
0
-1
-1
Hopfield Network Example (2)
5. Synchronous Iteration (update all nodes at once)
Inputs
Node
1
2
3
4
1
1
1/3
-1/3
1/3
2
0
0
0
0
From discrete output rule: sign(sum)
3
0
0
0
0
4
Output
-1/3
1
1/3
1
1
1
-1
-1
Values from Input Layer
1/3
p1
1/3
-1/3
=
-1/3
1/3
-1
Stable State
1
2
3
4
Matrices Computation
Goal: Set weights such that an input vector Vi, yields itself when
multiplied by the weights, W.
X = V1,V2..Vp,
where p = # input vectors (i.e., patterns)
So Y=X, and the Hebbian weight calculation is:
1
1 1 1 -1
1
X=
1 1 -1 1
XT=
1
-1 1 1 -1
-1
XTX =
3 1 -1 1
1 3 1 -1
-1 1 3 -3
1 -1 -3 3
W = XTY = XTX
1 -1
1 1
-1 1
1 -1
Common index = pattern #, so
this is correlation sum.
w2,4 = w4,2 = xT2,1x1,4 + xT2,2x2,4 + xT2,3x3,4
Matrices computation
• The upper and lower triangles of the product matrix represents the 6
weights wi,j = wj,i
• Scale the weights by dividing by p (i.e., averaging) .
• This produces the same weights as in the non-matrix description.
• Testing with input = ( 1 0 0 -1)
(1 0 0 -1)
3 1 -1 1
1 3 1 -1
-1 1 3 -3
= (2 2 2 -2)
1 -1 -3 3
Scaling by p = 3 and using 0 as a threshold gives:
(2/3 2/3 2/3 -2/3) => (1 1 1 -1)
Associative Retrieval = Search
p3
p1
p2
Back-propagation:
• Search in space of weight vectors to minimize output error
Associative Memory Retrieval:
• Search in space of node values to minimize conflicts between
a) node-value pairs and average correlations (weights), and
b) node values and their initial values.
• Input patterns are local (sometimes global) minima, but many
spurious patterns are also minima.
• High dependence upon initial pattern and update sequence (if asynchronous)
Energy Function
Energy of the associative memory should be low when pairs of node values
mirror the average correlations (i.e. weights) on the arcs that connect the node pair, and
when current node values equal their initial values (from the test pattern).
E a wkj x j xk b I k xk
k
j
k
When pairs match
correlations,
wkjxjxk > 0
When current values match input values,
Ikxk > 0
Gradient Descent
A little math shows that asynchronous updates using the discrete rule:
n
x pk (t 1) sgn( wkj x pj (t ) I pk )
j 1
yield a gradient descent search along the energy landscape for the E defined above.
Storage Capacity of Hopfield Networks
Capacity = Relationship between # patterns that can be stored &
retrieved without error to the size of the network.
Capacity = # patterns / # nodes or # patterns / # weights
• If we use the following definition of 100% correct retrieval:
When any of the stored patterns is entered completely (no noise), then that
same pattern is returned by the network; i.e. The pattern is a stable attractor.
• A detailed proof shows that a Hopfield network of N nodes can
achieve 100% correct retrieval on P patterns if: P < N/(4*ln(N))
In general, as more patterns are added to a network,
the avg correlations will be less likely to match the
correlations in any particular pattern. Hence, the
likelihood of retrieval error will increase.
=> The key to perfect recall is selective ignorance!!
N Max P
10
1
100
5
1000
36
10000 271
1011
109
Things to Remember
• Auto-Associative -vs- Hetero-associative
Wide variety of net topologies
All use Hebbian Learning => weights ~ avg correlations
• One-shot -vs- Iterative Retrieval
Iterative gives much better error correction.
• Asynchronous -vs- Synchronous state updates
Synchronous updates can easily lead to oscillation
Asynchronous updates can quickly find a local optima (attractor)
Update order can determine attractor that is reached.
• Pattern Retrieval = Search in node-state space.
Spurious patterns are hard to avoid, since many are attractors also.
Stochasticity helps jiggle out of local minima.
Memory load increase => recall error increase.
• Associative -vs- Feed-Forward Nets
Assoc: Many - 1 mapping Feed-Forward: many-many mapping
Backprop is resource-intensive, while Hopfield iterative update is O(n)
Gradient-Descent on an Error -vs- Energy Landscape:
Backprop => arc-weight space
Hopfield => node-state space