Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
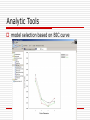
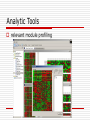
ArrayCluster: an analytic tool for clustering, data visualization and module finder on gene expression profiles 組員:李祥豪 謝紹陽 江建霖 Outline Introduction Mixed Factors Model Analytic Tools Summary Demo Introduction This task can be addressed by grouping gene expression patterns of a large number of genes Typical microarray data have a fairly small sample size, less than 100, whereas the number of genes involved is more than several thousands Introduction One major difficulty in this problem is that the number of samples to be clustered is much smaller than the dimension of data Most clustering technologies, e.g. kmeans, Gaussian mixture clustering, hierarchical clustering and so on, would be limited by over-learning Introduction In statistics, overfitting is fitting a statistical model that has too many parameters. When the degrees of freedom in parameter selection exceed the data, this leads to arbitrariness in the final (fitted) model parameters which reduces or destroys the ability of the model to generalize beyond the fitting data. Introduction In machine learning, usually a learning algorithm is trained using some set of training examples, especially in learning was performed too long or training are rare, the learner may adjust to very specific random features of the training data, that have no causal relation to the target function. Introduction In both statistics and machine learning, in order to avoid overfitting, it is necessary to use additional techniques (e.g. cross-validation, early stopping, Bayesian Priors on parameters or model comparison), that can indicate when further training is not resulting in better generalization. Mixed Factors Model The mixed factors model presents a parsimonious parameterization of Gaussian mixture model Our primal intention is parsimoniously to describe the group structure of data based on the factor variables. To this end, we devise the mixed factors that follow a Gcomponents Gaussian mixture as G p( f j ) g ( f j ; g , g ) g 1 Mixed Factors Model The mixed factors model, we possibly avoid the over-fitting of the Gaussian mixture by choosing an appropriate factor dimension regardless to the high dimensionality of data. Once the model has been fitted to a given dataset, clustering can be addressed by the Bayes rule. Mixed Factors Model To avoid it, we impose the orthogonality on the q columns of the factor loading matrix This imposition leads to a canonical representation of the mixed factors model as AT X j f j AT j From this equation, one achieves the fact that the q canonical variates in ATxj€Rq are distributed according to G p( AT X j ) g ( AT X j ; g , g I ) g 1 Mixed Factors Model The canonical variates can be considered as the q modules of genes which are relevant to the existing molecular subtypes. This process yields a feature selection that constructs good discriminators for existing groups as linear combination d genes. Analytic Tools File format of data file Analytic Tools model selection based on BIC curve Analytic Tools In this plot, the horizontal and vertical axes correspond to the factor dimension and the BIC scores, respectively. The each line represents curve of BIC scores against to varying factor dimensions (q) for a fixed number of clusters (G) Analytic Tools File format of mixed_factors Analytic Tools Box plot of the computed factor scores Analytic Tools Each cluster is separated with the blank lines. All samples in one cluster are ordered according to the degree of the belongings that are measured by the Maharanobis distance between each sample point and the corresponding group centeroid. The calculated distances are indicated next to the sample identifiers Analytic Tools File format of relevant_set Analytic Tools relevant module profiling After selecting rows (genes) of interest, the enlarged expression image will be displayed on the right window Analytic Tools The ArrayCluster provides users an usable environment to perform the following tasks: Parameter estimation of the mixed factors model: The ArrayCluster computes the maximum likelihood estimators by using the EM algorithm Determination of the number of clusters and the factor dimension (the number of grouprelatedmodules):These are selected based on the Bayesian information criterion (BIC) Clustering based on the Bayes rule Analytic Tools Dimension reduction of data: This task is addressed by the same way of the classical factor analysis, the mixed factors analysis explicitly reflects the existing group structure of original data, while the classical factor analysis ignores it during the dimension reduction Identification of the group-related genes: In the ArrayCluster, the relevant genes in each module are selected to be top L (user can specify) of the highest positive (negative) correlation with each element of the factor vector Analytic Tools Identification of the modules: By separating positive and negative correlated genes with the factor vector in a module, totally we identify 2q modules Missing data imputation Data preprocessing: The methods include normalization and gene filtering Summary The ArrayCluster visualizes the computed factor scores using the box plot matrix Enhancing the graphical understanding of the group structure. A casual link from the calibrated clusters to biological knowledge can be elucidated through the inspection of the group-related modules. Summary The ArrayCluster displays the expression patterns of these modules. Genes at these modules and their visualization give us a scope to question where the calibrated clusters come from. Thanks for your attention Next->DEMO



























![Mathematics 414 2003–04 Exercises 5 [Due Monday February 16th, 2004.]](http://s1.studyres.com/store/data/000084574_1-c1027704d816dc0676e3e61ce7dab3b7-150x150.png)







