Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
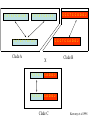
Recent developments in genetic epidemiology relevant to PURE Bernard Keavney Institute of Human Genetics University of Newcastle, UK. Objectives • Brief revision of some genetic “basics” • Developments 2003-2005 in genetic markers and genotyping technology • Ethnicity, genetic variation and disease • The potential impact of rare variants on common diseases: epidemiological and technological challenges. Genetic contribution to cardiovascular diseases genes Monogenic (disease genes) oligogenic (large-effect susceptibility genes) polygenic (small-effect susceptibility genes) environment HCM, LQTS Non-genetic Congenital HD Hypertension T II DM Atherosclerosis Common variants which affect human diseases • • • • • • • • • • HLA: APOE4: FV Leiden: PPARG: KCJN11: PTPN22: Insulin: NOD2: CF-H: RET: Autoimmunity and infection Alzheimer’s, CHD, lipids Venous thrombosis Type II Diabetes Type II Diabetes RhA, Type 1 Diabetes Type I Diabetes Crohn’s disease Age-related MD Hirschprung disease Candidate gene association studies: a uniquely non-replicable area of science • Six of 166 replicated in >75% of studies (4%)* • Study sizes too small • Statistical significance levels not stringent enough • Meta-analyses: problem of publication bias • Most conducted in urban Western Caucasian populations • Minimal environmental heterogeneity within individual studies • Minimal amount of “gene space” tested *Hirschhorn et al. Genet. Med. 2002 Genome figures • The human genome: 3,200,000,000 base pairs • 5% gene coding regions (1% expressed sequence) • Noncoding regulatory elements are situated near genes • 20,000 genes • Any two genomes: 99.9% identical • 3.2M differences between any two individuals • 11,000,000 sites vary in at least 1% of the world’s population (Polymorphisms) • Every site compatible with life has been mutated several times in this generation alone Single nucleotide polymorphisms (SNPs): the mapping tool for association studies CAACTGTGTAGGTTGAG Coding (amino acid change) Minority CAACTGTGTTGGTTGAG Noncoding Some regulatory Between 2000 and 2005 10 million SNPs have been identified. For mapping, focus hitherto on common SNPs (MAF > 0.05): ancient power to detect given effect greater 90% of human variation is due to common alleles Most common variants are found in all world populations Technology to find rare variants has not been available thus far Expect one common SNP every ~600 bp Total of 7M genomewide……Which ones to type? And how many? SNPs in dbSNP 2000-2005 The degree of association between a disease allele and a marker allele determines power Disease Testing two associations in one. Causal SNP Locus 1 D H D H Locus 2 A B B A Marker SNP The arrangement of two or more alleles on a chromosome is called a haplotype The degree of association between a disease allele and a marker allele determines power Disease Testing two associations in one. Causal SNP Locus 1 D H D H Locus 2 A B B A Marker SNP The arrangement of two or more alleles on a chromosome is called a haplotype Chromosomes are mosaics reflecting ancestral haplotypes MD after n generations D MD D MD M MD MD D ACE gene diagram Position of 10 polymorphisms typed at the ACE locus 210 haplotypes could be generated from these genotypes . T A T A T C G I A 3 C C C T C C G D G 2 T A T A T C A I A 3 C C C T C C A D G 2 T A T A T T G I A 3 Clade A X T A T A T C A D G 2 T A C A T C A D G 2 Clade C Clade B Keavney et al 1998 Oct 2005: Characterisation of most of the common genetic variation present genomewide in four world populations HapMap project • Phase I: 1 common SNP (MAF>0.05) every 5 Kb in 269 DNA samples (1 million SNPs) • • • • Yoruba from Ibadan, Nigeria European ancestry from Utah, US Han Chinese from Beijing Japanese from Tokyo • 10 x 500Kb regions • Resequenced in 48 individuals • All SNPs genotyped in 269 samples • Phase II : 4 million common SNPs • Goal: to assess feasibility of whole-genome association studies and provide the “road map”of SNPs to type HapMap phase I data Recombination rates, haplotype lengths and gene location Chromosome 9q13 The POMC gene Exon 1 (85bp) Intron 1 (3709bp) Exon 2 (151bp) Intron 2 (2887bp) Exon 3 (833bp) 5’ RsaI C1032G C8246T There are no common polymorphisms in the translated sequence Baker et al Diabetes 2005 0.5 Adjusted standardised WHR 0.4 0.3 0.2 0.1 0.0 -0.1 P<0.0001 Means (95% CIs) -0.2 C/C C/T POMC C8246T genotype T/T WHR adjusted for age, sex, smoking, alcohol, exercise, with or without BMI Difference 0.2 SD per allele. P=0.003 for C1032G; p=NS for RsaI N=1426 Baker et al. Diabetes 2005 Genome-wide association studies are feasible: HapMap data Chip-based genotyping provides the possibility to type 500,000 SNPs in a single individual today. Chip-based WGA study using 116,204 SNPs identified the role of Factor H in AMD (Klein et al. April 2005) The within-population component of genetic variation accounts for most of human genetic diversity 1052 individuals from 52 populations; 377 autosomal microsatellites 47% of 4199 alleles present in all regions 7% alleles region-specific; median q=0.01 Rosenberg et al. Science 2003 Few SNPs rare in one panel are common in another HapMap 2005 Heterogeneity of allele frequencies and disease O.R.s in meta-analyses of 43 gene-disease associations I2=75% shown by red line Ioannidis et al. Nat Genet. 2004 Disease-causing variants: common or rare alleles? With a few exceptions (e.g. ACE I/D and plasma ACE) this is empirically confirmed Leptin gene polymorphisms and cardiovascular risk 20Kb shown All common haplotypes at LEP are captured by these markers C538T is a rare allele (q<0.01) Gaukrodger et al. 2005 LEP C538T polymorphism, arterial stiffness and carotid IMT Trait Pulse pressure Mean IMT Estimate (SE) 95% CI Displacement* 1.00 (0.31) 0.39 – 1.61 Polygenic h2$ 0.24 (0.06) 0.12 – 0.36 Displacement 0.90 (0.36) 0.19 – 1.61 Polygenic h2 0.20 (0.07) 0.06 – 0.34 Residual correlation 0.13 (0.04) 0.04 – 0.21 Gaukrodger et al. JMG 2005 Rare alleles with large effect contribute to HDL cholesterol variation in the “normal range” Sequenced Coding Region APOA1 ABCA1 LCAT 128 High HDLC (>95%) 128 Low HDLC (<5%) Low HDLC High HDLC Var + 21 3 Var - 107 125 Cohen et al. Science 2004 • Variants affected function • Replicated in 2nd population • No association between HDLC and common variants in these genes • 1/6 of those with HDLC <5% had a mutation • These would be missed by a “common variant only” strategy High-throughput sequencing technologies from September 2005 issues of “Science” and “Nature” Conclusions • Technological progress is very rapid: prospect of WGA scans on large numbers of samples in near future • Many studies (eg UK Biobank) focus on geneenvironment interaction but often environmental heterogeneity is minimal • There remains a pressing need to describe and validate genetic associations with CVD in populations other than US and Western European Caucasians