Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
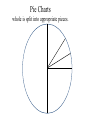
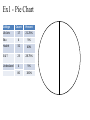
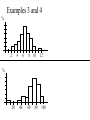
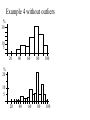
Introduction Population – the entire group of concern Sample – only a part of the whole Based on sample, we’ll make a prediction about the population. Bad sampling: convenience, bias, voluntary Good sampling: simple random sample(SRS). Inferential Stats: making predictions or inferences about a population based on a sample Experiments Observation – no attempt to influence Experiment– deliberately imposes some treatment Basic design principles: Control the effects of lurking variables Randomize which subject gets which treatment Use large sample size to reduce chance variation Statistical Significance: An observed effect so big that it would rarely occur just by chance. Picturing Distributions with Graphs What makes up any set of data? • Individuals – objects described by data – can be • Variables – characteristic of individuals of particular interest – different values possible for different people Two kinds of variables Categorical (Qualitative) – describes an individual by category or quality. – examples like Numerical (Quantitative) – describes an individual by number or quantity. – discrete for variables that are – continuous for variables that are – examples like Describing Categorical Variables Tables summarize the data set by – listing possible categories. – giving the number of objects in each category. – or show the count as a percentage. Picture the distribution of a cat. var. with – Pie charts – Bar graphs Pie Charts whole is split into appropriate pieces. Bar Graph Horizontal line keeps track of categorical values. Vertical bars at each value keeps track of # or %. % # 25 20 15 12 5 4 A B C D E F Example 1 80 AASU students in an Elem. Stats class come from one of four colleges (S & T, Edu, Health, Lib. Arts). The breakdown of these 80 students is given below. College Count Liberal Arts 17 Education 4 32 Health Professions Science & Technology Undeclared 23 4 80 Percent Ex1 - Pie Chart College Count Percent Lib Arts 17 21.25% Edu 4 5% Health 32 40% S&T 23 28.75% Undeclared 4 5% 80 100% Ex1 – Bar Graph College Count Percent Lib Arts 17 21.25% Edu 4 5% Health 32 40% 30 S& T 23 28.75% 20 Undeclared 4 5% 10 80 100% % LA E H ST U Describing Quantitative Variables Tables summarize the data set by – listing possible intervals (ranges, classes). – giving the number of individuals in each class – or showing the number as a percentage. Picture the distribution of a quant. var. with – Histogram (similar to bar graph but now vertical bars of neighboring classes touch) Where one class ends, the next begins. Example 2 Consider the ages of the full-time faculty in the math dept. The breakdown of these 19 individuals is given in the table. Age Class % Count Percent 30 20-30 5 26.3% 30-40 3 15.8% 40-50 5 26.3% 50-60 4 21.1% 60-70 2 10.5% 19 100% 20 10 10 30 50 70 Info from histograms Helps to describe a distribution with – pattern (shape, center, spread) – deviations (outliers) from the rest of the data • Could result from unusual observation or typo – For shape, look at symmetric vs. skewed Examples 3 and 4 % 2 4 6 8 10 12 % v 20 40 60 80 100 Example 4 without outliers % 30 10 5 v 20 40 60 80 100 % 20 10 5 v v 20 40 v 60 80 100 Describing Distributions with Numbers There are better ways to describe a quantitative data set than by an estimation from a graph. Center: mean, median, mode Spread: quartiles, standard deviation Center: Mean The mean of a data set is the arithmetic average of all the observations. Given a data set: x1 , x2 ,, xn Mean – Example 1 Your test scores in a Stats Class are: 60, 75, 92, 80 Your mean score is: Mean – Example 2 Compare high temperatures in Savannah for July 2010 and July 2011. July 2010 high temps: 83, 87, 84, …, 97, 100, 92 July 2011 high temps: 94, 91, 93, …, 97, 99, 99 83 87 92 x2010 31 94 91 99 x2011 31 Center: Median The median of a data set is the middle value of all the (ordered) observations. Given a data set: x1 , x2 ,, xn Median – Examples 3/4 11 tests: 60, 77, 92, 80, 84, 93, 80, 95, 65, 66, 75 Ordered data set: 60, 65, 66, 75, 77, 80, 80, 84, 92, 93, 95 10 dice rolls: 2, 4, 5, 5, 6, 7, 7, 8, 9, 10 Center: Mode The mode of a data set is the value that appears the most. Tests data set: 60, 65, 66, 75, 77, 80, 80, 84, 92, 93, 95 Dice rolls: 2, 4, 5, 5, 6, 7, 7, 8, 9, 10 2010 July High Temps mode: 2011 July High Temps mode: Spread: Quartiles A measure of center is not useful by itself – Are other observations close or far from center? Take an ordered data set and find: – M, – Q1, – Q3, – IQR = Summary of data in the “Five-Number Summary”: Quartiles – Example 5 11 tests: 60, 65, 66, 75, 77, 80, 80, 84, 92, 93, 95 5-num-sum: Visualize 5-num-sum with a boxplot. • Draw rectangle with ends at Q1 and Q3. • Draw line in the box for the median. • Draw lines to the last observations within 1.5IQR of the quartiles. • Observations outside 1.5IQR of the quartiles are suspected outliers. Boxplot – Example 6 5-Num-Sum: 60, ____, 80, ____, 95 50 • • • • 60 70 80 90 100 Draw rectangle with ends at Q1 and Q3 Draw line in the box for the median Draw lines to last observations within 1.5IQR of the quartiles Observations outside 1.5IQR of the quartiles are suspected outliers Boxplot – Example 7 July 2010 5-Num-Sum: 83, 92, 94, 97, 102 July 2011 5-Num-Sum: 84, 91, 95, 98, 99 2010 IQR = 97-92=5 2010 2011 2011 IQR = 98-91=7 80 85 90 95 100 105 Spread: Standard Deviation More common measure of spread (in conjunction with the mean) is the standard deviation. A single deviation from the mean looks like For every value in a data set, deviations are either positive, negative or zero. Finding an average of those will be trouble, since when you add the deviations together, you’ll get 0. Example 1 data: 60, 75, 92, 80 x 76.75 To deal with this “adding to zero”, we get rid of any negative terms by squaring each deviation. A single squared deviation from the mean looks like: The average of the squared deviations is called the variance: n-1 is called the degrees of freedom, since knowledge of the first (n-1) deviations will automatically set the last one. The standard deviation is the square root of the variance. x x 2 s Observations Deviations i n 1 Squared Dev s 2 60 75 92 80 mean=76.75 s When to use what? For skewed data: For (nearly) symmetric data: Outliers have a big impact on mean and std. dev. Consider two data sets: Set 1: 1, 1, 3, 5, 10 Set 2: 1, 1, 3, 5, 70