Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Data analysis wikipedia , lookup
Machine learning wikipedia , lookup
Inverse problem wikipedia , lookup
Expectation–maximization algorithm wikipedia , lookup
Genetic algorithm wikipedia , lookup
Corecursion wikipedia , lookup
Theoretical computer science wikipedia , lookup
Learning classifier system wikipedia , lookup
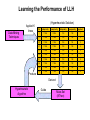
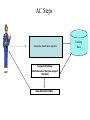
Associative Classification (AC) Mining for A Personnel Scheduling Problem Fadi Thabtah Trainer scheduling problem Schedule Courses (events) Locations Staff (trainers) Resources Timeslots Trainer scheduling problem • Assigning a number of training courses (events) to a limited number of training staff, locations, and timeslots • Each course has a numerical priority value • Each trainer is penalised depending on the travel distance Objective Function Total priority for scheduled events Total penalty for training staff MAX Hyperheuristic approach • Operates at a higher level of abstraction than metaheuristics • You may think of it as a supervisor that manages the choice of simple local search neighbourhoods (low-level heuristics) at any time Low-level heuristics • • • • Problem-oriented Represent simple methods used by human experts Easy to implement Examples: - Add new event to the schedule - Swap two events in the schedule - Replace one event in the schedule by another Hyperheuristi c Current solution Low Level Heuristic 1 Low Level Heuristic 2 Perturbed solution Low Level Heuristic 3 Building a Schedule using A hyperheuristic Initial solution Objective value Hyperheuristic algorithm CPU time Set of lowlevel heuristics Selected lowlevel heuristic Objective value Perturbed solution Objective value Current solution (according to acceptance criterion) Advantages of hyperheuristics • Cheap and fast to implement • Produce solutions of good quality (comparable to those obtained by hardto-implement metaheuristic methods) • Require limited domain-specific knowledge • Robustness: can be effectively applied to a wide range of problems and problem instances Current Hyperheuristics Approaches • Simple hyperheuristics (Cowling et al., 2001-2002) • Choice-function-based (Cowling et al., 2001 – 2002) • Based on genetic algorithms (Cowling et al., 2002; Han et al., 2002) • Hybrid Hyperheuristics. (Cowling, Chakhlevitch 2003-2004) Why Data Mining Scenario: While constructing the solution of the scheduling problem, the hyperheuristic manages the choice of appropriate LLH in each choice point, therefore an expert decision maker is needed (Classification). Two approaches: 1. Learn the performance of LLH from past schedules to predict appropriate LLH in current one 2. While constructing schedule learn and predict LLH Or what so called, Learn “On-the-fly” Classification : A Two-Step Process 1. Classifier building: Describing a set of predetermined classes 2. Classifier usage: Classification Algorithm • Calculate error rate • If Error rate is acceptable, then apply the classifier to test data Training Data Test Data RowId A1 A2 1 2 3 x1 x2 x1 y1 y4 y1 Class Classification Rules RowIds A1 A2 Class/ LLH 1 2 3 4 5 6 7 8 9 10 x1 x1 x1 x1 x2 x2 x2 x1 x2 x3 y1 y2 y1 y2 y1 y1 y3 y3 y4 y1 c1 c2 c2 c1 c2 c1 c2 c1 c1 c1 Learning the Performance of LLH Data Mining Techniques Applied K times Produce (Hyperheuristic Solution) llh oldpriority newpriority oldpenalty newpenalty applied 1 71954 72054 793 790 1 2 71954 71954 793 793 0 20 71954 71054 793 761 0 27 71954 71954 793 793 0 37 71954 71954 793 793 0 43 71954 71954 793 793 0 47 71954 71954 793 793 0 58 71954 71954 793 793 0 68 71954 71954 793 793 0 74 71954 71954 793 793 0 Derived Hyperheuristic Algorithm Guide Rules Set (If/Then) Association Rules Mining • Strong tool that aims to find relationships between variables in a database. • Its applied widely especially in market basket analysis in order to infer items from the presence of other items in the customer’s shopping cart • Example : if a customer buys milk, what is the probability that he/she buys cereal as well? • Unlike classification, the target class is not pre-specified in association rule mining. Advantages: • Items shelving • Sales promotions • Future planning Transactional Database Transaction Id Items Time 12 bread, milk, juice 10:12 13 bread, juice, milk 12:13 14 milk, beer, bread, juice bread, eggs, milk 13:22 beer, basket, bread, juice 15:11 15 16 13:26 Associative Classification (AC) • Special case of association rule that considers only the class label as a consequent of a rule. • Derive a set of class association rules from the training data set which satisfy certain user-constraints, i.e support and confidence thresholds. • To discover the correlations between objects and class labels. Ex: • CBA • CPAR • CMAR AC Steps Associative classification Algorithm Frequent Ruleitems: user Attribute values that pass support threshold Class Association Rules Training Data Rule support and confidence Given a training data set T, for a rule R : P c • The support of R, denoted as sup(R) , is the number of objects in T matching R condition and having a class label c • The confidence of R , denoted as conf(R), is the the number of objects matching R condition and having class label c over the number of objects matching R condition • Any Item has a support larger than the user minimum support is called frequent itemset Current Developed Techniques • • MCAR (Thabtah et al., Pceeding of the 3rd IEEE International Conference on Computer Systems and Applications (pp. 1-7) MMAC (Thabtah, et al., Journal of Knowledge and Information System (2006)00:1-21. MCAR Characteristics: MMACC characteristics: Combinations of two general Produces classifiers of the form: data mining approaches, i.e. v1 v2 ... v c1 c2 ...c (association rule, classification) that are suitable to not only Suitable for traditional traditional binary classification classification problems problems but also useful to multi Employs a new method of class labels problems such as finding the rules Medical Diagnoses and Text Classification. Presents three Evaluation Accuracy measures k i Data and Experiments Learning Approach : Learn the performance of LLH from past schedules to predict appropriate LLH in current one Supp=5%, confidence=40% Number of datasets : 12-16 UCI data and 9 solutions Of the training scheduling problem Algorithms used: CBA (AC algorithm) • MMAC (AC algorithm) • Decision Tree algorithms (C4.5) • Covering algorithms (RIPPER) • Hybrid Classification algorithm (PART) Relative prediction accuracy in term of PART for the Accuracy Measures of MMAC algorithm 110.00% 90.00% ( AccMMAC AccPART ) AccPART 70.00% 50.00% 30.00% 10.00% -10.00% 1 2 3 4 5 6 7 8 9 -30.00% -50.00% Top-label Label-w eight Support-w eight PART Any-Label Relative prediction accuracy in term of CBA for the Accuracy Measures of MMAC algorithm 95.00% Difference in Accuracy % 85.00% 75.00% ( AccMMAC AccCBA ) AccCBA 65.00% 55.00% 45.00% 35.00% 25.00% 15.00% 5.00% -5.00% 1 2 3 4 5 6 7 8 9 -15.00% -25.00% -35.00% Nine Scheduling Runs CB A To p-label A ll-label A ny-label Number of Rules of CBA, PART and Toplabel Number of Rules 26 24 22 20 18 16 14 12 10 8 6 4 2 0 Run1 Run2 To p Label P A RT Run3 CB A Run4 Run5 Run6 Run7 Run8 Ten Runs Scheduling Data Run9 Co Ti c nt ac - Ta t-l c en se s Br L ea st e d7 -c an W ce r ea th He er ar t He -c ar tLy s M mp pr ush h im r a r oo m ytu m or Vo te CR X Ba Si la nc c e- k sc al e Au Br tos Hy ea s po t-w th yr oi d z kr oo -v skp (%) Accuracy (%) for PART, RIPPER, CBA and MMAC on UCI data sets 100 90 80 70 60 50 40 30 20 10 0 PART RIPPER CBA MMAC Data sets Comparison between AC algorithms on 12 UCI data sets 30 27 24 (%) 21 18 CBA 15 CMAR CPAR 12 MCAR 9 6 3 0 1 2 3 4 5 6 Data 7 8 9 10 11 12 MCAR vs. CBA and C4.5 On UCI data sets Classifier Number of Rules Dataset MCAR CBA C4.5 MCAR CBA C4.5 Tic-tac 100 100 83.61 26 25 95 Balloon 100 100 100 3 3 3 Contact 100 93.33 83.33 9 6 4 Led7 72.32 71.1 73.34 192 50 37 Breast-cancer 71.61 69.66 75.52 71 45 4 Weather 100 100 50 6 6 5 MACR Support and Confidence Values for contact dataset 1.2 1 Percentage % Classification Accuracy % 0.8 Supp 0.6 Conf 0.4 0.2 0 1 2 3 4 5 6 7 8 9 R anked R ules Heart-c 80.4 79.87 78.12 72 44 12 Heart-s 81.35 79.2 81.29 31 22 2 CBA Support and Confidence Values for contact dataset 1.2 78.5 75.09 83.78 48 38 12 Mushroom 97.65 94.18 100 48 45 33 primary-tumour 40.5 25.47 42.47 28 1 23 Vote 90.1 86.91 88.27 84 40 4 CRX 83.05 85.31 80.72 97 43 54 Sick 93.88 93.9 93.87 17 10 1 Credit-Card 70.26 70.4 71.8 162 116 54 1 Percentage % Lymph 0.8 0.6 Supp Conf 0.4 0.2 0 1 2 3 4 Ranked Rules 5 6 Conclusions • Associative classification is a promising approach in data mining • Since more than LLHs could improve the objective function in the hyperheuristic, we need a multi-label rules in the classifier • Associative classifiers produce more accurate classification models than traditional classification algorithms such as decision trees and rule induction approaches • One challenge in associative classification is the exponential growth of rules, therefore pruning becomes essential Future Work • Constructing a hyperheuristic approach for the personnel scheduling problem • Investigating the use of multi-class labels classification algorithms with a hyperheuristic • Implementing of a new data mining techniques based on dynamic learning suitable for scheduling and optimization problem. • Investigate rule pruning in AC mining Questions ?