Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
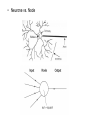
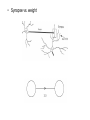
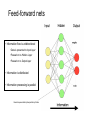
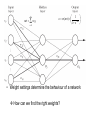
Data Mining: Concepts and Techniques — Chapter 6 — May 22, 2017 Data Mining: Concepts and Techniques 1 Chapter 6. Classification and Prediction • • What is classification? What is • Support Vector Machines (SVM) prediction? • Lazy learners (or learning from and prediction • your neighbors) Issues regarding classification • Frequent-pattern-based classification Classification by decision tree induction • Other classification methods • Bayesian classification • Prediction • Rule-based classification • Accuracy and error measures • Classification by back • Ensemble methods propagation • Model selection May 22, 2017 Data Mining: Concepts and • Summary Techniques 2 What are Neural Networks? • Models of the brain and nervous system • Highly parallel – Process information much more like the brain than a serial computer • Learning • Very simple principles • Very complex behaviours • Applications – As powerful problem solvers – As biological models Biological Neural Nets • Pigeons as art experts (Watanabe et al. 1995) – Experiment: • Pigeon in Skinner box • Present paintings of two different artists (e.g. Chagall / Van Gogh) • Reward for pecking when presented a particular artist (e.g. Van Gogh) • Pigeons were able to discriminate between Van Gogh and Chagall with 95% accuracy (when presented with pictures they had been trained on) • Discrimination still 85% successful for previously unseen paintings of the artists • Pigeons do not simply memorise the pictures • They can extract and recognise patterns (the ‘style’) • They generalise from the already seen to make predictions • This is what neural networks (biological and artificial) are good at (unlike conventional computer) ANNs – The basics • ANNs incorporate the two fundamental components of biological neural nets: 1. Neurones (nodes) 2. Synapses (weights) • Neurone vs. Node • Structure of a node: • Squashing function limits node output: • Synapse vs. weight Feed-forward nets • Information flow is unidirectional • Data is presented to Input layer • Passed on to Hidden Layer • Passed on to Output layer • Information is distributed • Information processing is parallel Internal representation (interpretation) of data • Feeding data through the net: n net wi xi i 0 1 o (net ) net 1 e (1 0.25) + (0.5 (-1.5)) = 0.25 + (-0.75) = - 0.5 Squashing: 1 0.3775 0.5 1 e • Data is presented to the network in the form of activations in the input layer • Data usually requires preprocessing – Analogous to senses in biology Defining a Network Topology • First decide the network topology: – # of units in the input layer, – # of hidden layers (if > 1), – # of units in each hidden layer, – and # of units in the output layer • Normalizing the input values for each attribute measured in the training tuples to [0.0—1.0] • One input unit per domain value • Output, if for classification and more than two classes, one output unit per class is used May 22, 2017 Data Mining: Concepts and Techniques 16 age <=30 <=30 31…40 >40 >40 >40 31…40 <=30 <=30 >40 <=30 31…40 31…40 >40 buys_computer income studentcredit_rating no no fair high no no excellent high yes no fair high yes medium no fair yes yes fair low no yes excellent low yes excellent yes low no medium no fair yes yes fair low yes medium yes fair medium yes excellent yes medium no excellent yes yes yes fair high no medium no excellent •# of units in the input layer, •# of hidden layers (if > 1), •# of units in each hidden layer, •and # of units in the output layer n net wi xi i 0 1 o (net ) net 1 e • Weight settings determine the behaviour of a network How can we find the right weights? Training the Network - Learning • Backpropagation – Requires training set (input / output pairs) – Starts with small random weights – Error is used to adjust weights (supervised learning) Gradient descent on error landscape Backpropagation • Iteratively process a set of training tuples & compare the network's prediction with the actual known target value • For each training tuple, the weights are modified to minimize the mean squared error between the network's prediction and the actual target value • Modifications are made in the “backwards” direction: from the output layer, through each hidden layer down to the first hidden layer, hence “backpropagation” • Steps – Initialize weights (to small random #s) and biases in the network – Propagate the inputs forward (by applying activation function) – Backpropagate the error (by updating weights and biases) – Terminating condition (when error is very small, etc.) May 22, 2017 Data Mining: Concepts and Techniques 20 n net wi xi i 0 1 o (net ) net 1 e k ok (1 ok )(tk ok ) h oh (1 oh ) w ji w ji w ji w koutputs kh k where w ji j x ji Termination Conditions • Fixed number of iterations • Error on training examples falls below threshold • Error on validation set meets some criteria Example 1 4 2 6 5 3 •Learning rate l=0.9 and class label=1 Avoiding overfitting • Weight decay – Decrease weights by small factor during each iteration – Stay away from complex surfaces • Validation Data – Train with training set – Get error with validation set – Keep best weights so far on validation data • Cross-validation to determine best number of iterations