Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
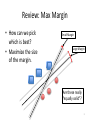
Support Vector Machines and Kernel Methods Machine Learning March 25, 2010 Last Time • Basics of the Support Vector Machines Review: Max Margin • How can we pick which is best? • Maximize the size of the margin. Small Margin Large Margin Are these really “equally valid”? 3 Review: Max Margin Optimization • The margin is the projection of x1 – x2 onto w, the normal of the hyperplane. Projection: Size of the Margin: 4 Review: Maximizing the margin • Goal: maximize the margin Linear Separability of the data by the decision boundary 5 Review: Max Margin Loss Function Primal Dual Review: Support Vector Expansion Independent of the Dimension of x! New decision Function • When αi is non-zero then xi is a support vector • When αi is zero xi is not a support vector 7 Review: Visualization of Support Vectors 8 Today • How support vector machines deal with data that are not linearly separable – Soft-margin – Kernels! Why we like SVMs • They work – Good generalization • Easily interpreted. – Decision boundary is based on the data in the form of the support vectors. • Not so in multilayer perceptron networks • Principled bounds on testing error from Learning Theory (VC dimension) 10 SVM vs. MLP • SVMs have many fewer parameters – SVM: Maybe just a kernel parameter – MLP: Number and arrangement of nodes and eta learning rate • SVM: Convex optimization task – MLP: likelihood is non-convex -- local minima 11 Linear Separability • So far, support vector machines can only handle linearly separable data • But most data isn’t. Soft margin example • Points are allowed within the margin, but cost is introduced. Hinge Loss 13 Soft margin classification • There can be outliers on the other side of the decision boundary, or leading to a small margin. • Solution: Introduce a penalty term to the constraint function 14 Soft Max Dual Still Quadratic Programming! 15 Probabilities from SVMs • Support Vector Machines are discriminant functions – Discriminant functions: f(x)=c – Discriminative models: f(x) = argmaxc p(c|x) – Generative Models: f(x) = argmaxc p(x|c)p(c)/p(x) • No (principled) probabilities from SVMs • SVMs are not based on probability distribution functions of class instances. 16 Efficiency of SVMs • Not especially fast. • Training – n^3 – Quadratic Programming efficiency • Evaluation – n – Need to evaluate against each support vector (potentially n) 17 Kernel Methods • Points that are not linearly separable in 2 dimension, might be linearly separable in 3. Kernel Methods • Points that are not linearly separable in 2 dimension, might be linearly separable in 3. Kernel Methods • We will look at a way to add dimensionality to the data in order to make it linearly separable. • In the extreme. we can construct a dimension for each data point • May lead to overfitting. Remember the Dual? Primal Dual 21 Basis of Kernel Methods • The decision process doesn’t depend on the dimensionality of the data. • We can map to a higher dimensionality of the data space. • Note: data points only appear within a dot product. • The objective function is based on the dot product of data points – not the data points themselves. 22 Basis of Kernel Methods • Since data points only appear within a dot product. • Thus we can map to another space through a replacement • The objective function is based on the dot product of data points – not the data points themselves. 23 Kernels • The objective function is based on a dot product of data points, rather than the data points themselves. • We can represent this dot product as a Kernel – Kernel Function, Kernel Matrix • Finite (if large) dimensionality of K(xi,xj) unrelated to dimensionality of x Kernels • Kernels are a mapping Kernels • Gram Matrix: Consider the following Kernel: Kernels • Gram Matrix: Consider the following Kernel: Kernels • In general we don’t need to know the form of ϕ. • Just specifying the kernel function is sufficient. • A good kernel: Computing K(xi,xj) is cheaper than ϕ(xi) Kernels • Valid Kernels: – Symmetric – Must be decomposable into ϕ functions • • • • Harder to show. Gram matrix is positive semi-definite (psd). Positive entries are definitely psd. Negative entries may still be psd Kernels • Given a valid kernels, K(x,z) and K’(x,z), more kernels can be made from them. – cK(x,z) – K(x,z)+K’(x,z) – K(x,z)K’(x,z) – exp(K(x,z)) – …and more Incorporating Kernels in SVMs • Optimize αi’s and bias w.r.t. kernel • Decision function: Some popular kernels • • • • Polynomial Kernel Radial Basis Functions String Kernels Graph Kernels Polynomial Kernels • The dot product is related to a polynomial power of the original dot product. • if c is large then focus on linear terms • if c is small focus on higher order terms • Very fast to calculate 33 Radial Basis Functions • The inner product of two points is related to the distance in space between the two points. • Placing a bump on each point. 34 String kernels • Not a gaussian, but still a legitimate Kernel – K(s,s’) = difference in length – K(s,s’) = count of different letters – K(s,s’) = minimum edit distance • Kernels allow for infinite dimensional inputs. – The Kernel is a FUNCTION defined over the input space. Don’t need to specify the input space exactly • We don’t need to manually encode the input. 35 Graph Kernels • Define the kernel function based on graph properties – These properties must be computable in poly-time • • • • Walks of length < k Paths Spanning trees Cycles • Kernels allow us to incorporate knowledge about the input without direct “feature extraction”. – Just similarity in some space. 36 Where else can we apply Kernels? • Anywhere that the dot product of x is used in an optimization. • Perceptron: Kernels in Clustering • In clustering, it’s very common to define cluster similarity by the distance between points – k-nn (k-means) • This distance can be replaced by a kernel. • We’ll return to this more in the section on unsupervised techniques Bye • Next time – Supervised Learning Review – Clustering