Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Skewed X-inactivation wikipedia , lookup
Designer baby wikipedia , lookup
History of genetic engineering wikipedia , lookup
Viral phylodynamics wikipedia , lookup
Public health genomics wikipedia , lookup
Hybrid (biology) wikipedia , lookup
Genetic testing wikipedia , lookup
Heritability of IQ wikipedia , lookup
Polymorphism (biology) wikipedia , lookup
Koinophilia wikipedia , lookup
Human genetic variation wikipedia , lookup
Y chromosome wikipedia , lookup
X-inactivation wikipedia , lookup
Neocentromere wikipedia , lookup
Genetic drift wikipedia , lookup
Genome (book) wikipedia , lookup
Gene expression programming wikipedia , lookup
An Introduction to
Genetic Algorithm (GA)
By:
Dola Pathak
For:
STAT 992:Computational Statistics
SPRING 2015
1
Motivating Example
The data were collected at Baystate Medical Center in Spring- field,
Massachusetts, in 1986, on 189 births and the response variable was the
birth weight of the baby. There were eight explanatory variables/factors
which were considered. This data, called the low birth weight data, is in the
Appendix I of Hosmer and Lemeshow’s book “Applied Logistic Regression”.
What is the best fitted model?
Are all the variables important?
How many models are possible with main effects only
– 256!
Any alternatives?
2
What is Genetic Algorithm (GA)?
A genetic algorithm is an optimization method based on
natural selection.
3
The concept
• Inspired by Darwin’s Theory of evolution popularly termed
as “Survival of the fittest”
• Fittest – ability to adapt to the environment which increases
the likelihood of survival
• The fitness is maintained through the process of
reproduction, crossover and mutation.
4
From the statistical point of view
A GA is a stochastic technique with simple operations based on the
theory of natural selection. The basic operations are :
1. Selecting population members for the next generation
2. Mating these members via crossover of “chromosomes”
In statistical terms chromosomes will be the individual members of
the population and the genes of the chromosomes are the variables.
3. Performing mutations on the chromosomes to preserve
population diversity so as to avoid convergence to local optima.
4. Finally, determining the fitness of each member in the new
generation using an evaluation (fitness) function. This fitness
influences the selection process for the next generation.
5
Development
• Alan Turing -----“learning machine” ----- evolution process
•
In 1960s the idea of evolution strategy/programming was
developed in Germany and in the USA.
• John Holland and his students in the early 1970s (book:
"Adaption in Natural and Artificial Systems"(1975)).
• David Goldberg, who was a graduate student of Holland’s
presented an award-winning doctoral thesis on his GA
application to gas pipeline optimization.
6
Why Genetic Algorithm?
• Exhaustive search (where every possible combination is checked)
- accurate result
- time consuming
- inefficient when the numbers of variables are large
- optimizers tend to :
- limit the number of variables they use or
- limit the number of values these variables can take.
• The genetic algorithm (does not try every possible combination)
- optimal solution by selecting variables intelligently.
- far more variables can be utilized
- all values of a variable can be checked
- simultaneous searching - less likely to become stuck in "local minima"
- less time
- efficient
7
Where are Genetic Algorithms applied?
There are at least three situations where genetic
algorithms are applied:
1. The objective function is not smooth (i.e., not
differentiable).
2. There are multiple local optima( often happens with
non linear functions).
3. There are a large number of parameters (the meaning
of “large” keeps changing).
8
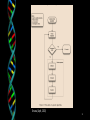
Outline of the Basic Genetic Algorithm
[Start] Generate random population of n chromosomes (suitable
solutions for the problem)
[Fitness] Evaluate the fitness f(x) of each chromosome x in the
population
[New population] Create a new population by repeating the
following steps until the new population is complete
[Selection] Select two parent chromosomes from a population
according to their fitness (the better fitness, the bigger chance to
be selected)
9
[Crossover] With a crossover probability cross over the parents
to form a new offspring (children). If no crossover was
performed, offspring is an exact copy of parents.
[Mutation] With a mutation probability mutate new offspring at
each locus (position in chromosome).
[Accepting] Place new offspring in a new population
[Replace] Use new generated population for a further run of
algorithm
[Test] If the end condition is satisfied, stop, and return the best
solution in current population
[Loop] Go to step 2
10
Scrucca (April, 2013)
11
Example 1
Going back to the example that was presented at the
beginning of the presentation, let us see how a first
generation of optimum variable values are calculated using
a Genetic Algorithm.
12
The model
The multiple linear regression equation:
𝑏𝑤𝑡=1.0116+0.0033*x+0.0019*y+0.007*z
#x= age , 14<x<45
#y=weight of the mother in her lmp in pounds, 80<y<250
#z= ftv, 0<z<6
13
STEP1: Generate random population of 4 chromosomes
(individuals)
> set.seed(7777)
> x<-floor(runif(4, 14,45))
> y<-floor(runif(4, 80,250))
> z<-floor(runif(4, 0,6))
> population_chrom<-matrix(c(x,y,z),byrow =
TRUE,nrow=3,ncol=4) #population units
PARENT POPULATION
population_chrom
[,1] [,2] [,3] [,4]
[1,]
14
29
33
44
[2,] 144 230 229 196
[3,]
2
3
5
1
STEP2 Evaluate the fitness f(x) of each
chromosome x in the population
> fitness<-fit(population_chrom)
> fitness
[,1] [,2] [,3] [,4]
[1,] 1.3454 1.5653 1.5906 1.5362
14
STEP 3: Select two parent chromosomes from a population
according to their fitness (the better fitness, the bigger chance to
be selected)
Determining the new ordering
> prob<-objective/total #probabilities associated with each chromosome
> set.seed(9001)
> gen_prob<-runif(4, min=0, max=1)
> data.frame(t(prob), gen_prob)
t.prob.
gen_prob
1 0.2228406 0.2316537
2 0.2592629 0.9483070
3 0.2634534 0.1912030
4 0.2544431 0.6869134
#generating the new order of the parent population (chromosomes) for the 1st
generation
> Chrom_reordered
[,1] [,2] [,3] [,4]
[1,]
29
14
33
44
[2,]
230
144
229
196
[3,]
3
2
5
1
15
STEP 4: CROSSOVER
Let the crossover probability, 𝝆𝒄 = 𝟎. 𝟑𝟓
We generate random number between 0 and 1 and perform crossover between
those chromosomes whose randomly generated numbers are less than 0.35
> set.seed(7755)
> for(k in 1:4){
R[k]<-runif(1, min=0, max=1)
R[k]
}
> R
[,1]
[1,] 0.5204274
[2,] 0.9641516
[3,] 0.2732612
[4,] 0.2740294
It is seen that chromosome # 3 and #4 will undergo crossover and we
determine the position at which they will undergo the crossover by:
> set.seed(6655)
> cross_pos<-floor(runif(1, min=1, max=2))
> cross_pos
[1] 1
16
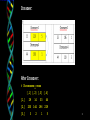
> Chromosome_cross [,1] [,2] [,3] [,4] [1,] 29 14 33 44 [2,] 230 144 196 229 [3,] 3 2 1 5
Crossover:
After Crossover:
> Chromosome_cross
[,1] [,2] [,3] [,4]
[1,]
29
14
33
44
[2,]
230
144
196
229
[3,]
3
2
1
5
17
STEP 5:Mutation
Let the mutation probability, 𝝆𝑴 = 𝟎. 𝟐𝟎
Total length of genes= #of chromosomes*genes per chromosome
#of genes to be mutated =𝜌𝑀 * total length of the gene =2 (rounded)
Thus of the 24 position of the genes, two positions are randomly selected to
be mutated.
> set.seed(7761)
> #values to be mutuated
> floor(runif(2, min=1, max=12))
[1] 5 4
The 5th position is in the 2nd population and represents weight of the mother
(ranges from 80-250) and the 4th position is also in the 2nd population and it
represents the age of the mother (14 to 45 years).
Two numbers are generated within the range of values for lwt and age of the
mother and these are mutated in the 5th and 4th position of the second
chromosome.
> #for position 5: lwt
> floor(runif(1, min=80, max=250))
[1] 235
> # for position 4: Age
> floor(runif(1, min=14, max=45))
[1] 29
> Chromosome_cross[2,2]<-235
> Chromosome_cross[1,2]<-29
18
1st Generation:
> first_gen<-Chromosome_cross
> first_gen
[,1] [,2] [,3] [,4]
[1,]
29
29
33
44
[2,] 230 235 196 229
[3,]
3
2
1
5
Comparing the fitness function:
> fitness_new<-fit(first_gen)
> data.frame(t(fitness),t(fitness_new))
t.fitness. t.fitness_new.
1
1.3454
1.5653
2
1.5653
1.5678
3
1.5906
1.4999
4
1.5362
1.6269
19
Example 2: Efficiency of GA in searching for the best fitted
model?
(Using the package glmulti)
The basic model is:
𝒃𝒕𝒘 ~ age + lwt + race.cat + sm + preterm + ht + ui + ftv.cat
Without interaction
CASE 1: Exhaustive Search
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept)
1.3051026 0.1107701 11.782 < 2e-16 ***
race.catBlack -0.2117263 0.0659755 -3.209 0.001575 **
race.catOther -0.1524077 0.0510387 -2.986 0.003217 **
preterm1+
-0.0944738 0.0606883 -1.557 0.121287
lwt
0.0018382 0.0007607
2.416 0.016666 *
sm
-0.1474951 0.0477114 -3.091 0.002307 **
ht
-0.2606070 0.0904447 -2.881 0.004438 **
ui
-0.2225058 0.0617916 -3.601 0.000409 ***
20
CASE 2: GA Search
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept)
1.3051026 0.1107701 11.782 < 2e-16 ***
race.catBlack -0.2117263 0.0659755 -3.209 0.001575 **
race.catOther -0.1524077 0.0510387 -2.986 0.003217 **
preterm1+
-0.0944738 0.0606883 -1.557 0.121287
lwt
0.0018382 0.0007607
2.416 0.016666 *
sm
-0.1474951 0.0477114 -3.091 0.002307 **
ht
-0.2606070 0.0904447 -2.881 0.004438 **
ui
-0.2225058 0.0617916 -3.601 0.000409 ***
COMPARISON:
21
With pairwise interaction:
CASE 1:Exhaustive Search
For the Exhaustive case the iterations went on for a long
time and it failed to give the best fitted model.
The program ran for approximately 710 minutes before it
was terminated.
22
CASE 2: GA Search
Coefficients:
Estimate Std. Error t value Pr(>|t|)
1.243534
0.159220
7.810 5.27e-13 ***
-0.155676
0.066214 -2.351 0.01985 *
-0.102393
0.052312 -1.957 0.05191 .
-0.590434
0.299435 -1.972 0.05022 .
0.019363
0.005991
3.232 0.00147 **
-0.001286
0.001080 -1.191 0.23523
0.276818
0.203220
1.362 0.17492
-0.017958
0.008412 -2.135 0.03419 *
-0.028554
0.012304 -2.321 0.02147 *
0.002484
0.001827
1.360 0.17567
-0.010769
0.002614 -4.120 5.86e-05 ***
0.004184
0.002398
1.745 0.08278 .
-0.023259
0.006973 -3.336 0.00104 **
-0.022184
0.010763 -2.061 0.04079 *
0.003848
0.001244
3.094 0.00231 **
0.003630
0.001970
1.843 0.06705 .
(Intercept)
race.catBlack
race.catOther
preterm1+
age
lwt
sm
age:sm
age:ht
lwt:ht
age:ui
preterm1+:lwt
age:ftv.catNone
age:ftv.catMany
lwt:ftv.catNone
lwt:ftv.catMany
--Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
23
Comparison of time taken for the methods to converge:
Method
Exhaustive Search
Genetic Algorithm
Time taken to find the best fit
model
710.7032 minutes
0.5055 minutes
(failed to give the
optimum solution)
(260 generations)
Conclusion: It is seen that for models with pairwise interactions,
GA gets to the best fitted model much faster than the exhaustive
search.
24
GAs are used for
• Building Double Threshold Auto Regressive Conditional
Heteroscedastic (DTARCH) models
• Multilayer neural network
• Optimal Component Selection for component based systems
• Robotics
• VLSI layout optimization
• Modelling the behavior of economic agents in
macroeconomic models, etc.
25
Computers and GA:
With the advent of different packages and softwares the
use of GA has definitely gained popularity.
Apart from glmulti, some of the packages which I came
across while researching for this presentation were:
GA
genalg
PROC GA
PROC CONNECT ( uses Parallel Genetic Algorithm)
Genetic Algorithm Toolbox in MATLAB
GAlib (available for the UNIX system)
26
References and further readings:
• Denny Hermawanto. Genetic Algorithm for Solving Simple Mathematical Equality
Problem.
• Hillier and Lieberman. Introduction to Operations Research (9th Ed.)
• Hosmer, D.W. and Lemeshow, S. Applied Logistic Regression. New York: Wiley
• Givens & Hoeting.Computational Statistics (2nd Ed.)
• K.F Man, et all. Genetic Algorithms: Concepts and Applications. IEEE
Transactions on Industrial Electronics, Vol.43 No 5, Oct 1996
• Luca Scrucca. GA: A Package for Genetic Algorithms in R. Journal of Statistical
Software, Vol 23 , Issue 4, April 2013
• V. Calcagno, et all. glmulti: An R Package for Easy Automated Model
Selection with (Generalized) Linear Models. Journal of Statistical
Software, Vol 24 Issue 12, May 2010.
• http://www.r-bloggers.com/genetic-algorithms-a-simple-r-example/
• http://www.obitko.com/tutorials/genetic-algorithms/
27
Thank you
28