Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
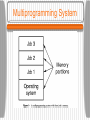
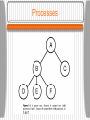
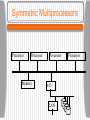
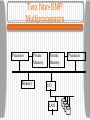
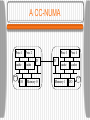
CS 620 Advanced Operating Systems Lecture 1 - Introduction Professor Timothy Arndt BU 331 Operating Systems Review • An operating system is a program which is interposed between users and the hardware of a system • An operating system can also be seen as a manager of resources (e.g. processes, files and I/O devices) Examples include Windows 98, Windows XP, Mac OS X, Palm OS, and various varieties of UNIX (HP-UX, Linux, AIX, etc.) The Place of Operating Systems Early Operating Systems Early computers were controlled directly by a programmer or computer operator who entered a job (given on a deck of punched cards) and collected the output (from a line printer). Groups of jobs were placed together in a single deck giving rise to batch systems. In order to minimize wasted time, a program called an operating system was developed. The program was always in the computer’s memory and controlled the execution of the jobs. Early Operating Systems Batch Operating Systems In a batch system, various types of cards were put together in a deck • Job control cards contained cards often distinguished by a particular character in the first row, column position. These cards contained instructions for the OS written in the machine’s job control language (JCL) • Program source code (in a language such as FORTRAN) were compiled into an executable form. • Data cards contained the data needed for a run of the program. Batch Operating Systems Multiprogramming System These systems were inefficient since the CPU was idle while a running program waited for (e.g.) a slow I/O operation to finish. In order to get around this problem, several jobs were kept in memory, and when the running program was blocked waiting for I/O, the OS switched to one of the other jobs. This type of system is called a multiprogramming system. • Note that this type of system is still not interactive.The user must wait for his job to finish before he sees the output. Multiprogramming System Timesharing systems As time went on, users were connected to the CPU via terminals, and the switching between jobs was fast enough that each user had the illusion of being the sole user of the system (if the system wasn’t overloaded!). This type of system is called a timesharing system. • In this type of system the OS’s scheme for control of the CPU must be much more complicated. In general, each job consists of one or more processes. • Processes can create other processes called child processes. Processes Processes • A running process consists of several segments in the computer’s main memory. The text segment contains the processes executable machine instructions. The global segment contains global and static (variables declared in a procedure whose value doesn’t change between invocations of the procedure) variables. The data segment (or heap) contains dynamically allocated memory. The stack contains activation records for subprograms. The activation records contain local variables, parameters, return location, etc. When a subprogram is called an activation record is pushed on the stack. When a subprogram exits, it’s record is popped off the stack. A Running Process Processes Each process has its own virtual address space. The size of the space depends on the word size of the computer. The virtual address space is in general larger than the computer’s physical memory, so some virtual memory scheme is needed. The OS ensures the virtual to physical mapping for each process and also that each process can only access memory locations in its own address space. File System Another important resource that the OS manages is the set of files that programs access. • The file system is typically structured as a tree in which leaf nodes are files and interior nodes are directories. • Even if files are on separate physical devices, they can be combined in a single virtual hierarchy. The command used to add a new subtree (on a separate physical device) to the file system is called mount. • A single file (or directory) can be placed in multiple directories without copying the file by linking the file. A link is a special type of file. File System Virtual File Hierarchy Interprocess Communication Separate processes can communicate with each other using an OS provided service called Interprocess Communication (IPC). UNIX processes can use sockets or pipes to establish communication with other processes. IPC and process spawning are relatively slow, leading to the idea of light-weight processes or threads in many modern OSs. Threads spawned by the same process can communicate through shared memory. Interprocess Communication User vs. Kernel Mode In order to make the system more stable, many OSs distinguish between processes operating in user mode versus those operating in kernel mode. User mode processes can access only their memory locations in their own address space, cannot directly access hardware, etc. Kernel mode processes have no such restrictions. • The fewer processes which run in kernel mode, the more robust the system should be. On the other hand, mode switching slows down the system. User vs. Kernel Mode Other OS Requirements • Besides controlling files, processes and IPC, an OS has several other important tasks: Controlling I/O and other peripheral devices Networking Security and access control for the various resources Processing user commands Introduction to Distributed Systems Distributed systems (as opposed to centralized systems) are composed of large numbers of CPUs connected by a high-speed network. Definition of a Distributed System • A distributed system is: • A collection of independent computers that appears to its users as a single coherent system. Introduction to Distributed Systems Advantages of distributed systems: • Some applications involve spatially separated machines. • If one machine crashes, the system as a whole can still survive. • Computing power can be added in small increments. • Allow many users to share expensive peripherals like color printers. • Spread the workload over the available machines in the most cost effective way. Introduction to Distributed Systems Disadvantages of distributed systems: • Less software exists for distributed systems. • The network can saturate or cause other problems. • Easy access also applies to secret data. Classification of Multiple CPU Systems Distributed systems are multiple CPU systems (as are parallel systems - we don’t distinguish between these two). In order to compare various multiple CPU systems, we would like a classification. There is no completely satisfactory classification. The most well-known (but now outdated) is due to Flynn: • MIMD Multiprocessor (shared memory) Multicomputer (no shared memory) Introduction to Distributed Systems • SIMD (Single Instruction Multiple Data Stream) • SISD (Single Instruction Single Data Stream): traditional computers. • MISD (Multiple Instruction Stream Single Data Stream): No known examples. Each of these categories can further be characterized as either: • • • • bus or switch tightly coupled or loosely coupled Hardware Concepts 1.6 Bus-Based Multiprocessors Bus-based multiprocessors consist of some number of CPUs all connected to a common bus, along with a memory module. • A typical bus has 32 or 64 address lines, 32 or 64 data lines, and 32 or more control lines, all operating in parallel. • Since there is just one memory, if one CPU writes a word of memory, and another CPU immediately reads that word, the value read will be that written. • The memory is said to be coherent. • This configuration soon causes the bus to be overloaded. Bus-Based Multiprocessors • A bus-based multiprocessor. 1.7 Bus-Based Multiprocessors The solution to this problem is to add a highspeed cache memory between the CPU and the bus. The cache holds the most recently accessed words. All memory request go through the cache. The probability that a requested word is found in the cache is called the hit rate. If the hit rate is high, the bus traffic will be dramatically reduced. Bus-Based Multiprocessors The use of a cache gives rise to the cache coherence problem. • One solution is the use of a write-through cache. • The caches must also the monitor the bus and invalidate cache entries when writes to that address occur. This process is called snooping. • Most bus-based multiprocessors use these techniques. Bus-Based Multiprocessors • Facts about caches: • They can be write through, when the processor issues a store the value goes in the cache and also is sent to memory • They can be write back, the value only goes to the cache. In this case, the cache line is marked dirty and when it is evicted it must be written back to memory. • Because of the broadcast nature of the bus it is not hard to design snooping caches that maintain consistency. Bus-Based Multiprocessors Bus-based multiprocessors are also called Symmetric Multiprocessors (SMPs) and they are very common. The bus can also connect multiple processors on the same die, leading to Multicore Systems Disadvantage (this is really a limitation) • Cannot be used for a large number of processors since the bus bandwidth grows with the number of processors and this gets increasingly difficult and expensive to supply. • Moreover the latency grows as the number of processors for both speed of light and more complicated (electrical) reasons. Symmetric Multiprocessors Processor Processor Memory Processor I/O LAN Processor Two Non-SMP Multiprocessors Processor Memory Private Memory Private Memory I/O LAN Processor Two Non-SMP Multiprocessors Processor Processor Memory I/O LAN Dual-core Dual-Processor System Switched Multiprocessors • To build a multiprocessor with more than (say) 64 processors, a different method is needed to connect the CPUs with the memory. One interconnection method is the use of a crossbar switch in which each CPU is connected to each interleaved bank of memory. • This method requires n2 crosspoint switches for n memories and CPUs, which can be expensive for a large n. Switched Multiprocessors a) A crossbar switch b) An omega switching network 1.8 Switched Multiprocessors The omega network is an example of a multistage network which requires a smaller number of switches - (nlog2n)/2 with log2n switching stages. • The number of stages slows down memory access, however. Another alternative is the use of hierarchical systems called NUMA (NonUniform Memory Access). • Each CPU accesses its own memory quickly, but everyone else’s more slowly. A CC-NUMA Proc 1 cache I/O Proc 2 cache D Memory 0 D Proc 3 Proc 4 cache cache Memory 1 I/O NUMA Production of cc-NUMAs is well-supported by the AMD Opteron (e.g. by SGI). Other cc-NUMA systems are being built using Intel’s Itanium processor with additional hardware support (e.g. by HP running HP-UX). NUMA CC-NUMAs (Cache Coherent NUMAs) are programmed like SMPs but to get good performance: • must try to exploit the memory hierarchy and have most references hit in your local cache • most others must hit in the part of the shared memory in your "node” (CPUs on the local bus). NC-NUMAs (Non Coherent NUMAs) are still harder to program as you must maintain cache consistent manually (or with compiler help). Bus-Based Multicomputers Multicomputers (with no shared memory) are much easier to build (i.e. scale much more easily). Each CPU has a direct connection to its own local memory. The only traffic on the interconnection network is CPU-to-CPU, so the volume of traffic is much lower. The interconnection can be done using a LAN rather than a high-speed backplane bus. Bus-Based Multicomputers In some sense all the computers on the internet form one enormous multicomputer. The interesting case is when there is some closer cooperation between processors; say the workstations in one distributed systems research lab cooperating on a single problem. Application must tolerate long-latency communication and modest bandwidth, using current state-of-the-practice. Switched Multicomputers • The final class of systems are switched multicomputers. Various interconnection networks have been proposed and built. Examples are grids and hypercubes. A hypercube is an n-dimensional cube. For an ndimensional hypercube, each CPU has n connections to other CPUs. Hypercubes with 1000s of CPUs (Massively Parallel Processors or MPPs) have been available for several years. Switched Multicomputers a) Grid b) Hypercube 1-9 Software Concepts System Description Main Goal DOS Tightly-coupled operating system for multiprocessors and homogeneous multicomputers Hide and manage hardware resources NOS Loosely-coupled operating system for heterogeneous multicomputers (LAN and WAN) Offer local services to remote clients Middleware Additional layer atop of NOS implementing general-purpose services Provide distribution transparency • DOS (Distributed Operating Systems) • NOS (Network Operating Systems) • Middleware Network Operating Systems Network operating systems allow one or machines on a LAN to serve as file servers which provide a global file system accessible from all workstations. An example of the use of a file server is NFS (Network File System). • The file server receives requests from nonserver machines called clients, to read and write files. It is possible that the machines all run the same OS, but it is not required. Network Operating Systems A situation like this, where each machine has a high degree of autonomy and there are few system-wide requirements is known as a network operating system. It is apparent to the users such a system consists of numerous computers. • There is no coordination among the computers, except that the client-server traffic must obey the system’s protocols. • The next step up consists of tightly-coupled software on the same loosely-coupled hardware. Network Operating Systems • General structure of a network operating system. 1-19 Network Operating Systems • Two clients and a server in a network operating system. 1-20 Network Operating Systems • Different clients may mount the servers in different places. 1.21 Distributed Operating Systems (DOS) The goal of such a system is to create the illusion that the entire network of computers is a single timesharing system. The characteristics of a distributed system include: • • • • • • A single, global IPC mechanism A global protection scheme Homogeneous process management A single set of system calls A homogeneous file systems Identical kernels on all CPUs DOS • A global file system Multiprocessor timesharing systems consist of tightly-coupled software on tightly-coupled hardware. The key character of this class of system is the existence of a single run queue. • Ready to run processes can be run on any of the CPUs of the system. The operating system in this type of organization normally maintains a traditional file system. DOS • General structure of a multicomputer operating system 1.14 Middleware • Middleware allows heterogeneous systems to achieve the appearance of a single coherent system • An additional layer is added on top of the NOS services Middleware • General structure of a distributed system as middleware. 1-22 Middleware and Openness 1.23 • In an open middleware-based distributed system, the protocols used by each middleware layer should be the same, as well as the interfaces they offer to applications. Comparison between Systems Item Distributed OS Network OS Middlewarebased OS Multiproc. Multicomp. Degree of transparency Very High High Low High Same OS on all nodes Yes Yes No No Number of copies of OS 1 N N N Basis for communication Shared memory Messages Files Model specific Resource management Global, central Global, distributed Per node Per node Scalability No Moderately Yes Varies Openness Closed Closed Open Open Design Issues The single most important issue is the achievement of transparency. There are several types of transparency that we might try to achieve: • Location transparency: users cannot tell where resources are located. • Migration transparency: resources can move at will without changing names. • Replication transparency: users cannot tell how many copies exist. Design Issues • Concurrency transparency: multiple users can share resources automatically. • Parallelism transparency: activities can happen in parallel without users knowing. The second key design issue is flexibility. • Flexibility can be provided by a microkernel (as opposed to a monolithic kernel) which provides just: An IPC mechanism. Some memory management. A small amount of low-level process management and scheduling. Low-level input/output. Design Issues • All other OS services are implemented as user-level services: file system directory system full process management system call handling This leads to a highly modular approach in which new services are easily added without stopping the system and booting a new kernel. Services can also be substituted with customized services. Design Issues In a uniprocessor system, the monolithic kernel may have a performance advantage (no context switches). However in a distributed system, the advantage is less. Another design goal for distributed systems is reliability. • One aspect of reliability is availability, or uptime. This can be improved by exploiting redundancy. • Another aspect is security. This issue is even more difficult in distributed systems then in uniprocessor systems. Design Issues • A final issue of reliability is fault tolerance. Performance in distributed systems is a critical issue due to the slow communication times. • We can attempt to increase the performance by selecting the correct grain size of computations. • Jobs which involve fine-grained parallelism will necessarily spend a large amount of time on message passing. They are poor candidates for distributed systems. • Jobs that involve large computations and low interaction - coarse-grained parallelism - are better bets for distributed systems. Design Issues Scalability is another critical issue. Scalability can be achieved by avoiding: • Centralized components • Centralized tables • Centralized algorithms Decentralized algorithms have the following characteristics: • No machine has complete information about the system state. • Machines make decisions based only on local information. Design Issues • Failure of one machine does not ruin the algorithm. • There is no implicit assumption that a global clock exists. Scalability Problems Concept Example Centralized services A single server for all users Centralized data A single on-line telephone book Centralized algorithms Doing routing based on complete information Examples of scalability limitations. Scaling Techniques (1) 1.4 The difference between letting: a) a server or b) a client check forms as they are being filled Scaling Techniques (2) 1.5 An example of dividing the DNS name space into zones. New Distributed Systems Architectures • • • • • • Cluster Computing Grid Computing Cloud Computing Mobile Ad Hoc Network (MANET) Wireless Sensor Network Peer-to-Peer Network