Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
CS 636 Computer Vision
Discriminative and Generative
Recognition
Nathan Jacobs
Slides adapted from Lazebnik
Discriminative and generative methods for
bags of features
Zebra
Non-zebra
Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba
Image classification
• Given the bag-of-features representations of
images from different classes, how do we
learn a model for distinguishing them?
Discriminative methods
• Learn a decision rule (classifier) assigning bagof-features representations of images to
different classes
Decision
boundary
Zebra
Non-zebra
Classification
• Assign input vector to one of two or more
classes
• Any decision rule divides input space into
decision regions separated by decision
boundaries
Nearest Neighbor Classifier
• Assign label of nearest training data point
to each test data point
from Duda et al.
Voronoi partitioning of feature space
for two-category 2D and 3D data
Source: D. Lowe
K-Nearest Neighbors
• For a new point, find the k closest points from
training data
• Labels of the k points “vote” to classify
• Works well provided there is lots of data and the
distance function is good
k=5
Source: D. Lowe
Functions for comparing histograms
N
• L1 distance
D(h1, h2 ) = å| h1 (i) - h2 (i) |
i=1
N
•
χ2
distance
D(h1, h2 ) = å
( h1 (i) - h2 (i))
i=1
2
h1 (i) + h2 (i)
• Quadratic distance (cross-bin)
D(h1, h2 ) = å Aij (h1 (i) - h2 ( j))2
i, j
Jan Puzicha, Yossi Rubner, Carlo Tomasi, Joachim M. Buhmann: Empirical Evaluation of
Dissimilarity Measures for Color and Texture. ICCV 1999
Earth Mover’s Distance
• Each image is represented by a signature S consisting of a
set of centers {mi } and weights {wi }
• Centers can be codewords from universal vocabulary,
clusters of features in the image, or individual features (in
which case quantization is not required)
• Earth Mover’s Distance has the form
EMD(S1, S2 ) = å
i, j
fij d(m1i , m2 j )
fij
where the flows fij are given by the solution of a
transportation problem
Y. Rubner, C. Tomasi, and L. Guibas: A Metric for Distributions with Applications to Image
Databases. ICCV 1998
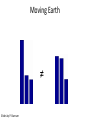
Moving Earth
≠
Slides by P. Barnum
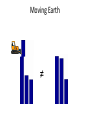
Moving Earth
≠
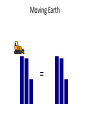
Moving Earth
=
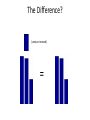
The Difference?
(amount moved)
=
The Difference?
(amount moved) * (distance moved)
=
Earth Mover’s Distance
Can be formulated as a linear program…
a transportation problem.
=
Y. Rubner, C. Tomasi, and L. J. Guibas. A
Metric for Distributions with Applications to
Image Databases. ICCV 1998
Why might EMD be
better or worse than these?
N
• L1 distance
D(h1, h2 ) = å| h1 (i) - h2 (i) |
i=1
N
•
χ2
distance
D(h1, h2 ) = å
( h1 (i) - h2 (i))
i=1
2
h1 (i) + h2 (i)
• Quadratic distance (cross-bin)
D(h1, h2 ) = å Aij (h1 (i) - h2 ( j))2
i, j
Jan Puzicha, Yossi Rubner, Carlo Tomasi, Joachim M. Buhmann: Empirical Evaluation of
Dissimilarity Measures for Color and Texture. ICCV 1999
recall: K-Nearest Neighbors
• For a new point, find the k closest points from
training data
• Labels of the k points “vote” to classify
• Works well provided there is lots of data and the
distance function is good
k=5
Source: D. Lowe
Linear classifiers
• Find linear function (hyperplane) to separate
positive and negative examples
xi positive :
xi w b 0
xi negative :
xi w b 0
Why not just use KNN?
Which hyperplane is best?
Support vector machines
• Find hyperplane that maximizes the margin
between the positive and negative examples
C. Burges, A Tutorial on Support Vector Machines for Pattern Recognition, Data Mining and
Knowledge Discovery, 1998
Support vector machines
• Find hyperplane that maximizes the margin
between the positive and negative examples
xi positive (yi =1):
xi negative(yi = -1):
For support vectors,
Distance between point
and hyperplane:
xi × w + b ³1
xi × w + b £ -1
xi × w + b = ±1
| xi × w + b |
|| w ||
Therefore, the margin is 2 / ||w||
Support vectors
Margin
C. Burges, A Tutorial on Support Vector Machines for Pattern Recognition, Data Mining and
Knowledge Discovery, 1998
What if they aren’t separable?
Quadratic optimization problem:
1 T
w w
2
Subject to yi(w·xi+b) ≥ 1
Quadratic optimization problem:
1 T
w w + å si
2
Subject to
yi(w·xi+b) ≥ 1 – si
si ≥ 0
Introducing the “Kernel Trick”
• Notice:
w i i yi xi
learned weights
support
vector
C. Burges, A Tutorial on Support Vector Machines for Pattern Recognition, Data Mining and
Knowledge Discovery, 1998
Introducing the “Kernel Trick”
w i i yi xi
• Recall:
w·xi + b = yi for any support vector
• Classification function (decision boundary):
w × x + b = å ai yi xi × x + b
i
• Notice that it relies on an inner product between
the test point x and the support vectors xi
• Solving the optimization problem can also be
done with only the inner products xi · xj between
all pairs of training points
C. Burges, A Tutorial on Support Vector Machines for Pattern Recognition, Data Mining and
Knowledge Discovery, 1998
Nonlinear SVMs
• Datasets that are linearly separable work out great:
x
0
• But what if the dataset is just too hard?
x
0
• We can map it to a higher-dimensional space:
x2
0
x
Slide credit: Andrew Moore
Nonlinear SVMs
• General idea: the original input space can
always be mapped to some higherdimensional feature space where the training
set is separable:
Φ: x → φ(x)
Lifting Transformation
Slide credit: Andrew Moore
Nonlinear SVMs
• The kernel trick: instead of explicitly
computing the lifting transformation φ(x),
define a kernel function K such that
K(xi ,xj) = φ(xi ) · φ(xj)
• This gives a nonlinear decision boundary in
the original feature space:
y K ( x , x) b
i
i
i
i
C. Burges, A Tutorial on Support Vector Machines for Pattern Recognition, Data Mining and
Knowledge Discovery, 1998
Kernels for bags of features
• Histogram intersection kernel:
N
I(h1, h2 ) = å min(h1 (i), h2 (i))
i=1
• Generalized Gaussian kernel:
æ 1
2ö
K(h1, h2 ) = exp ç - D(h1, h2 ) ÷
è A
ø
• D can be Euclidean distance, χ2 distance, Earth
Mover’s Distance, etc.
J. Zhang, M. Marszalek, S. Lazebnik, and C. Schmid, Local Features and Kernels for Classifcation
of Texture and Object Categories: A Comprehensive Study, IJCV 2007
Summary: SVMs for image classification
1. Pick an image representation (in our case, bag
of features)
2. Pick a kernel function for that representation
3. Compute the matrix of kernel values between
every pair of training examples
4. Feed the kernel matrix into your favorite SVM
solver to obtain support vectors and weights
5. At test time: compute kernel values for your
test example and each support vector, and
combine them with the learned weights to get
the value of the decision function
What about multi-class SVMs?
• Unfortunately, there is no “definitive” multi-class SVM
formulation
• In practice, we have to obtain a multi-class SVM by
combining multiple two-class SVMs
• One vs. others
– Traning: learn an SVM for each class vs. the others
– Testing: apply each SVM to test example and assign to it
the class of the SVM that returns the highest decision
value
• One vs. one
– Training: learn an SVM for each pair of classes
– Testing: each learned SVM “votes” for a class to assign to
the test example
SVMs: Pros and cons
• Pros
– Many publicly available SVM packages:
http://www.kernel-machines.org/software
– Kernel-based framework is very powerful, flexible
– SVMs work very well in practice, even with very
small training sample sizes
• Cons
– No “direct” multi-class SVM, must combine twoclass SVMs
– Computation, memory
• During training time, must compute matrix of kernel
values for every pair of examples
• Learning can take a very long time for large-scale
problems
Summary: Discriminative methods
• Nearest-neighbor and k-nearest-neighbor classifiers
– L1 distance, χ2 distance, quadratic distance,
Earth Mover’s Distance
• Support vector machines
–
–
–
–
Linear classifiers
Margin maximization
The kernel trick
Kernel functions: histogram intersection, generalized
Gaussian, pyramid match
– Multi-class
• Of course, there are many other classifiers out there
– Neural networks, boosting, decision trees, …
Generative learning methods for bags of features
p(class | image)µ p(image | class)p(class)
posterior
likelihood
prior
• Model the probability of a bag of features
given a class
Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba
Generative methods
• We will cover two models, both inspired by
text document analysis:
– Naïve Bayes
– Probabilistic Latent Semantic Analysis
The Naïve Bayes model
• Start with the likelihood
p(image | c) = p( f1,… , fN | c)
Csurka et al. 2004
The Naïve Bayes model
• Assume that each feature is conditionally
independent given the class
N
p( f1,… , fN | c) = Õ p( fi | c)
i=1
fi: ith feature in the image
N: number of features in the image
Csurka et al. 2004
The Naïve Bayes model
• Assume that each feature is conditionally
independent given the class
N
M
i=1
j=1
p( f1,… , fN | c) = Õ p( fi | c) = Õ p(w j | c)
n(w j )
fi: ith feature in the image
N: number of features in the image
wj: jth visual word in the vocabulary
M: size of visual vocabulary
n(wj): number of features of type wj in the image
Csurka et al. 2004
The Naïve Bayes model
• Assume that each feature is conditionally
independent given the class
N
M
i=1
j=1
p( f1,… , fN | c) = Õ p( fi | c) = Õ p(w j | c)
p(wj | c) =
n(w j )
No. of features of type wj in training images of class c
Total no. of features in training images of class c
Csurka et al. 2004
The Naïve Bayes model
• Assume that each feature is conditionally
independent given the class
N
M
i=1
j=1
p( f1,… , fN | c) = Õ p( fi | c) = Õ p(w j | c)
p(wj | c) =
n(w j )
No. of features of type wj in training images of class c + 1
Total no. of features in training images of class c + M
(psuedocounts to avoid zero counts)
Csurka et al. 2004
The Naïve Bayes model
• Maximum A Posteriori decision:
M
c* = arg max c p(c)Õ p(w j | c)
n(w j )
j=1
M
= arg max c log p(c) + å n(w j )log p(w j | c)
j=1
(you should compute the log of the likelihood
instead of the likelihood itself in order to avoid
underflow)
Csurka et al. 2004
The Naïve Bayes model
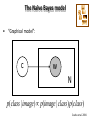
• “Graphical model”:
c
w
N
p(class | image)µ p(image | class)p(class)
Csurka et al. 2004
Probabilistic Latent Semantic Analysis
= p1
Image
+ p2
zebra
+ p3
grass
“visual topics”
T. Hofmann, Probabilistic Latent Semantic Analysis, UAI 1999
tree
Probabilistic Latent Semantic Analysis
• Unsupervised technique
• Two-level generative model: a document is a
mixture of topics, and each topic has its own
characteristic word distribution
d
z
w
document
topic
P(z|d)
word
P(w|z)
T. Hofmann, Probabilistic Latent Semantic Analysis, UAI 1999
Probabilistic Latent Semantic Analysis
• Unsupervised technique
• Two-level generative model: a document is a
mixture of topics, and each topic has its own
characteristic word distribution
z
d
w
K
p(wi | d j ) = å p(wi | zk )p(zk | d j )
k=1
T. Hofmann, Probabilistic Latent Semantic Analysis, UAI 1999
The pLSA model
K
p(wi | d j ) = å p(wi | zk )p(zk | d j )
k=1
Probability of word i
in document j
(known)
Probability of
word i given
topic k
(unknown)
Probability of
topic k given
document j
(unknown)
The pLSA model
K
p(wi | d j ) = å p(wi | zk )p(zk | d j )
k=1
p(wi|dj)
Observed codeword
distributions
(M×N)
=
documents
topics
topics
words
words
documents
p(zk|dj)
p(wi|zk)
Codeword distributions
per topic (class)
(M×K)
Class distributions
per image
(K×N)
Learning pLSA parameters
Maximize likelihood of data:
Observed counts of
word i in document j
M … number of codewords
N … number of images
Slide credit: Josef Sivic
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
function [W,S]=plsa(x,K,iter);
% Maximum Likelihood estimation of the Probabilistic Latent Semantic Analysis model of Th. Hofmann
% Teaching material for Machine Learning -- Practical Assignment 3, written by Ata Kaban, 2005.
% OUTPUTS:
% W: terms by topics matrix, containing entries W(term,topic) = P(term|topic) for each term and topic
% S: topics by documents matrix, containing entries S(topic,doc) = P(topic|doc) for each topic and doc
%
if nargin<3, iter=100; end % 100 iterations by default
[T,N]=size(x);
% Initialisation
W=rand(T,K); W=W./repmat(sum(W),T,1);
S=rand(K,N); S=S./repmat(sum(S),K,1);
K
p(wi | d j ) = å p(wi | zk )p(zk | d j )
k=1
% Loop (eqs are written in matrix format, which makes the MatLab code more efficient)
for i=1:iter
S=S.*(W'*((x+eps) ./ (W*S+eps))); % ./ is element-wise division
S=S./repmat(sum(S),K,1);
W=W.*(( (x+eps) ./ (W*S+eps) )*S'); % the small number eps is added to avoid numerical problems
W=W./repmat(sum(W),T,1);
end;
Inference
• Finding the most likely topic (class) for an image:
*
z = argmax p(z | d)
z
Inference
• Finding the most likely topic (class) for an image:
*
z = argmax p(z | d)
z
• Finding the most likely topic (class) for a visual
word in a given image:
p(w | z)p(z | d)
z = argmax p(z | w, d) = arg max
z
z
å p(w | z¢)p(z¢ | d)
*
z¢
Topic discovery in images
J. Sivic, B. Russell, A. Efros, A. Zisserman, B. Freeman, Discovering Objects and their Location
in Images, ICCV 2005
Application of pLSA: Action recognition
Space-time interest points
Juan Carlos Niebles, Hongcheng Wang and Li Fei-Fei, Unsupervised Learning of Human Action
Categories Using Spatial-Temporal Words, IJCV 2008.
Application of pLSA: Action recognition
Juan Carlos Niebles, Hongcheng Wang and Li Fei-Fei, Unsupervised Learning of Human Action
Categories Using Spatial-Temporal Words, IJCV 2008.
pLSA model
K
p(wi | d j ) = å p(wi | zk )p(zk | d j )
k=1
Probability of word i
in video j
(known)
Probability of
word i given
topic k
(unknown)
Probability of
topic k given
video j
(unknown)
– wi = spatial-temporal word
– dj = video
– n(wi, dj) = co-occurrence table
(# of occurrences of word wi in video dj)
– z = topic, corresponding to an action
Action recognition example
Multiple Actions
Multiple Actions
Summary: Generative models
• Naïve Bayes
– Unigram models in document analysis
– Assumes conditional independence of words given
class
– Parameter estimation: frequency counting
• Probabilistic Latent Semantic Analysis
– Unsupervised technique
– Each document is a mixture of topics (image is a
mixture of classes)
– Can be thought of as matrix decomposition
– Parameter estimation: Expectation-Maximization
Summary
• Recognition is the “grand challenge” of computer
vision
• History
–
–
–
–
–
–
Geometric methods
Appearance-based methods
Sliding window approaches
Local features
Parts-and-shape approaches
Bag-of-features approaches
• Statistical recognition concepts
– Generative vs. discriminative models
– Generalization, overfitting, underfitting
– Supervision
• Tasks, datasets