Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Open Database Connectivity wikipedia , lookup
Microsoft SQL Server wikipedia , lookup
Concurrency control wikipedia , lookup
Entity–attribute–value model wikipedia , lookup
Microsoft Jet Database Engine wikipedia , lookup
Extensible Storage Engine wikipedia , lookup
Relational algebra wikipedia , lookup
Clusterpoint wikipedia , lookup
Versant Object Database wikipedia , lookup
Keyword search
in relational
databases
By SO Tsz Yan Amanda &
HON Ka Lam Ethan
1
Introduction
● Ubiquitous relational databases
● Need to know SQL and database structure
● Hard to define an “object”
2
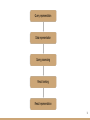
Query representation
How can we apply keyword
search on relational
databases?
Data representation
Query processing
Result ranking
Result representation
3
Query representation
●
What is a query?
●
Pre-processing operations
The first step
4
Query representation
Query = (finite) list of keywords
The query needs to be pre-processed to
understand better about the user’s need.
It will then be used for internal queries.
Possible operations
●
●
●
●
Logical conjunction (AND) vs
disjunction (OR)
Condition/filtering (e.g. year >
3000)
Categorize keywords into types
(NUITS)
And more...
5
Logical conjunction (AND) vs disjunction (OR)
● AND = all keywords
● OR = some keywords
● Less common = OR (in top-k query
processing)
6
Filtering/condition
● e.g. year > 3000
● Limit candidate data
7
Data representation
How a database is modeled
●
Graph-based
●
Data graph
●
Schema graph
●
Comparison
8
Finding top-k min-cost connected trees [2]
9
Finding top-k min-cost connected trees [2]
●
●
●
Node = tuple
Edge = relationship between 2
tuples
Edge/node weight = function
defined by the authors
10
Finding top-k min-cost connected trees [2]
●
Query = {Keyword, Query, DB, Jim}
●
●
●
2 Steiner trees (candidates)
Steiner tree = tree of subset of
vertices
Tree-1 is ranked higher (lower cost)
●
Tree cost = ∑ edge weights
11
IR-Style Keyword Search [3]
12
IR-Style Keyword Search [3]
● Node = relation
● Edge = foreign key
relationship from one
relation to another
13
IR-Style Keyword Search [3]
1. Construct a schema graph
2. Use the schema graph to compute joining trees of tuples
a.
Joining tree ≈ nodes of tuples connected by an edge of foreign key
relationship
3. Return the trees of the highest scores
14
Data graphs vs schema graphs
Data graphs
Schema graphs
1.
Larger
(nodes = records)
1.
Smaller
(nodes = relations)
2.
Don’t need access to database
2.
Need access to database
3.
Harder to maintain
3.
Easier to maintain
15
Query processing
●
Constructing an index
●
Top-k query processing
Effectiveness - Crucial requirement.
16
Indexing Structure - Inverted Index
MOTIVATION : Avoid the need to linearly scan
all of the tables in the database for every query.
Traditional Way of finding location of a keyword:
Inverted index
Balmin A, Hristidis V, Papakonstantinou Y (2004) ObjectRank: authority-based keyword search in databases. In:
Proceedings of the 30th international conference on very large data bases, pp 564–575, August 31–September
03, 2004, Toronto, Canada
An inverted index that supports phrase searches
17
Indexing Structure - 2 Main Challenges
1. How to control granularity of
indexed content
2. How to efficiently find the exact
results from the indexed context
18
Indexing Structure - Symbol table
A symbol table maintains the list of columns
or cells that contain the keywords.
Agrawal S, Chaudhuri S, Das G (2002) DBXplorer: a system for keyword-based search over relational
databases. In: Proceedings of the 18th international conference on data engineering, pp 5–17, February
26–March 01, 2002, San Jose, California, USA
19
Indexing Structure - Symbol table (Compression)
Larger symbol table increases the I/O cost during the search step
⇒ Need to reduce the space needed for this auxiliary data.
Compression
Goldman R, Shivakumar N, Venkatasubramanian S, Garcia-Molina H (1998) Proximity search in databases. In:
Proceedings of the 24th international conference on very large data bases, pp 26–37, August 24–27, 1998, San
Francisco, California, USA
20
Indexing Structure Symbol table (Granularity levels)
To reduce the scan time and storage space costs,
symbol table is designed to several granularity levels of
schema elements: column level and record level.
21
Why we need top-k processing techniques?
Retrieve information scattered across several tables ⇒ Require multiple JOIN operations.
If the system attempts to join ALL of the
tuples with ALL of the query keywords
→
Extremely inefficient
∴ Only a few matches for query keywords are of interest.
⇒
requires efficient top-k processing techniques.
22
Top-k query processing
Users are only interested in a small number of
results, k, that best match the given query keywords.
23
Top-k query processing - Candidate Network (CN)
DISCOVER executes top-k queries by avoiding creation
of ALL query results
⇒ Shares intermediate results that are used for
evaluating CN
The top-k results are only distributed in a few CNs.
∴ search system has to decide which CN will produce
top-k results
CN: JOIN expressions to be used to create joining
trees of tuples that will be considered as potential
answers to the query.
Architecture of DISCOVER
Hristidis V, Papakonstantinou Y (2002) DISCOVER: keyword search in relational databases. In: Proceedings of
the 28th international conference on very large data bases, pp 670–681, August 20–23, 2002, Hong Kong, China
24
Result ranking
1. RELEVANCE
2. IMPORTANCE
●
R- Size of an answer
●
R- Graph Representation
●
R- IR weighting methods
●
I- Authority transferring
methods
25
Relevance - Size of an answer
To measure the relevance, many approaches have
considered the size of an answer as a ranking factor.
⇒ Answers with smaller number of joins are generally
more meaningful/ helpful.
Luo Y, Lin X, Wang W, Zhou X (2007) SPARK: Top-k keyword query in relational databases. In: Proceedings of
the 2007 ACM SIGMOD international conference on management of data, pp 115–126, June 11–14, 2007
Beijing, China
26
Relevance - Graph Representation
Answers represent as minimal subgraph that
includes ALL of the query keywords.
⇒ includes nodes that are not matched to the
query keywords but just connect the matched
nodes, e.g. T2 and T5
∴ Should minimize non-matched nodes, and
find a complete transitive closure
STEINER TREE PROBLEM
Join Trees
Hulgeri A, Nakhe C (2002) Keyword searching and browsing in databases using BANKS. In: Proceedings of the
18th international conference on data engineering, pp 431–441, February 26–March 01, 2002, San Jose,
California, USA
27
Relevance - Number of edges
Nodes
Edges
Dataspot ranks candidate
answers by the number of
edges in the subgraph.
Dataspot: Sample database (left), Hyperbase (right)
Dar S, Entin G, Geva S, Palmon E (1998) DTL’s dataspot: database exploration using plain language. In:
Proceedings of the 24th international conference on very large data bases, pp 645–649, August 24–27, 1998,
San Francisco, California, USA
28
Relevance - Semantic Closeness
Proximity search differentiates distance
between different kinds of schema
elements
-
between a table and its attributes
between tuples in the same table
between tuples related through
primary and foreign keys
⇒ Regards the distance as the
semantic closeness between objects.
A fragment of the movie database relational schema and a database instance as a graph
Using the shortest path between schema elements to
measure size of an answer.
Goldman R, Shivakumar N, Venkatasubramanian S, Garcia-Molina H (1998) Proximity search in databases. In: Proceedings of
the 24th international conference on very large data bases, pp 26–37, August 24–27, 1998, San Francisco, California, USA
29
Relevance - IR weighting methods
Ranking function considers each text column as a collection,
and uses the standard IR weighting methods, e.g. tf-idf to
compute a weight for each term in the field.
[Focus on improving quality of relevance ranking for text documents]
30
Importance - Authority transferring methods
The DBLP schema graph.
Nodes with an incoming
link with high authority
are assumed to have higher
importance.
⇒ compute importance of
node based on the link
structure in the graph model.
The DBLP authority transfer schema graph.
Hristidis V, Hwang H, Papakonstantinou Y (2008) Authority-based keyword search in databases. ACM Trans
Database Syst 33(1):1–40
31
Importance - Authority transferring methods
Authority transfer data graph.
A subset of the DBLP graph.
Sum of authority transfer rates of outgoing edges
determines authority of the node within the same
domain.
⇒ a node that is referenced by other authoritative
nodes obtains authority.
Hristidis V, Hwang H, Papakonstantinou Y (2008) Authority-based keyword search in databases. ACM Trans
Database Syst 33(1):1–40
●
An edge is omitted only if the transfer
rate is 0 in that direction.
●
Edge weights are assigned as the
authority transfer rate.
Result representation
●
Examples
Little but essential
33
BANKS [4]
{soumen, sunita}
34
Finding top-k min-cost connected trees [2]
35
Query representation
Data representation
Query processing
Result ranking
Result representation
36
References
1.
2.
3.
4.
Park, Jaehui, and Sang-goo Lee. "Keyword search in relational databases." Knowledge and Information Systems
26.2 (2011): 175-193.
Ding, Bolin, et al. "Finding top-k min-cost connected trees in databases." Data Engineering, 2007. ICDE 2007.
IEEE 23rd International Conference on. IEEE, 2007.
Hristidis, Vagelis, Luis Gravano, and Yannis Papakonstantinou. "Efficient IR-style keyword search over relational
databases." Proceedings of the 29th international conference on Very large data bases-Volume 29. VLDB
Endowment, 2003.
Bhalotia, Gaurav, et al. "Keyword searching and browsing in databases using BANKS." Data Engineering, 2002.
Proceedings. 18th International Conference on. IEEE, 2002.
37