Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Data Protection Act, 2012 wikipedia , lookup
Data center wikipedia , lookup
Database model wikipedia , lookup
Data analysis wikipedia , lookup
Web analytics wikipedia , lookup
Semantic Web wikipedia , lookup
Forecasting wikipedia , lookup
Data vault modeling wikipedia , lookup
Information privacy law wikipedia , lookup
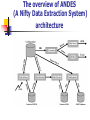
Effective Web Data Extraction with Standard XML Technologies Source:International World Wide Web Conference Proceedings of the tenth international conference on World Wide Web Hong Kong Pages: 689 - 696 Year of Publication: 2001 Author:Jussi Myllymaki Outline Introduction Problem ANDES architecture Conclusion and future work Introduction 在這篇論文中,主要是討論如何從網站 中精鍊出資料的問題,以及提出一個以 XML為基礎的方法來解決data extraction 的問題。 In this paper we focus on systemsoriented issues in Web data extraction and describe our approach for building a dependable extraction process. Extracting structured data requires solving five problems navigation problem:finding target HTML pages on a site by following hyperlinks. data extraction problem:extracting relevant pieces of data from these pages. structure synthesis problem:distilling the data and improving its structured-ness. data mapping problem:ensuring data homogeneity. data integration problem:merging data from separate HTML pages. Extracting structured data from web sites Web site navigation Data extraction Hyperlink synthesis Structure synthesis Data mapping Data integration Web site navigation In the ANDES data extraction framework, viewing Web sites as consisting of two types of HTML pages: target HTML pages and navigational HTML pages. ANDES uses the Grand Central Station (GCS) as a crawler, it is a flexible and extensible crawler framework developed at the IBM Almaden Research Center. Data extraction First step in data extraction is to translate the content to a well-formed XML syntax. The specific approach taken in the ANDES framework is to pass the original HTML page through a filter to produce XHTML. The first XSLT file merely extracts data from XHTML page, while subsequent XSLT files in the pipeline can refine the data and fill in missing data from domain knowledge. Hyperlink synthesis One shortcoming of today’s crawlers is only follow static hyperlinks but not dynamic hyperlinks that are a result of HTML forms and JavaScript code. Structure synthesis What makes this difficult is that a Web site may not provide enough structure to make direct mapping to an XML structure possible. In ANDES, missing data can be filled in by XSLT code that encapsulates domain knowledge. Data mapping Mapping discrete values into a standard format improves the quality of the extracted data. Homogenization of discrete values and measured values is performed in ANDES with a combination of conditional statements, regular expressions, and domain-specific knowledge encapsulated in the XSLT code. Data integration Why this is necessary? Some web sites use HTML frames of layout, which breaks up a logical data unit into separate HTML documents. Some web sites break up the data across multiple “sibling pages” so as not to overload a single page with too much information. Solving steps: The original HTML documents are crawled normally and data is extracted from them individually. Concatenating these partial outputs into one output and passing the resulting file through an XSLT filter the merges related data. The overview of ANDES (A Nifty Data Extraction System) architecture ANDES這個架構包含了五個元件: data retriever:ANDES的預設data retriever是Grand Central Station ( GCS ) crawler‧而GCS從網站中擷取出target HTML pages;而這些網頁被傳送到extractor。 extractor:它是用來執行data extraction, structure synthesis, data mapping functions, and data integration functions. checker:extractor所產生出來的output XML文件將被轉交給 checker,來檢查所送交來的資料是否正確。 exporter:ANDES所預設的data exporter是將XML資料轉換 relational tuples和將這些tuples插入一個JDBC的資料庫。 scheduler/manager interface:scheduler的責任是用來 trigger the data extraction在predefined times和定時地重覆做 extraction的動作。而web-based management interface是一個系 統管理者,用來monitor and control ANDES。 Conclusion and future work The paper expect to use the XML Schema syntax for expressing data validation rules.