Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Text mining
The Standard Data Mining process
Text Mining
•
•
•
•
Machine learning on text data
Text Data mining
Text analysis
Part of Web mining
• Typical tasks include:
–
–
–
–
–
Text categorization (document classification)
Text clustering
Text summarization
Opinion mining
Entity/concept extraction
– Information retrieval: search engines
– information extraction: Question answering
Supervised learning algorithms
– Decision tree learning
– Naïve Bayes
– K-nearest neighbour
– Support Vector Machines
– Neural Networks
– Genetic algorithms
Unsupervised Learning
– Document clustering
•
•
•
•
HAC
K-means
BIRCH
…
Applying machine learning on text
Text Representation (Feature Extraction)
preprocessing
Indexing
Weighting Model
Dimensionality Reduction
Similarity measure: how to compare text
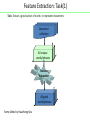
Feature Extraction: Task(1)
Task: Extract a good subset of words to represent documents
Document
collection
All unique
words/phrases
Feature
Extraction
All good
words/phrases
Some slides by Huaizhong Kou
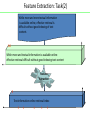
Feature Extraction: Task(2)
While more and more textual information
is available online, effective retrieval is
difficult without good indexing of text
content.
16
While-more-and-textual-information-is-available-onlineeffective-retrieval-difficult-without-good-indexing-text-content
Feature
Extraction
5
Text-information-online-retrieval-index
2
1
1
1
1
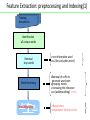
Feature Extraction: preprocessing and Indexing(1)
Training
documents
Identification
all unique words
Removal
stop words
non-informative word
ex.{the,and,when,more}
Removal of suffix to
Word Stemming
Term Weighting
generate word stem
grouping words
increasing the relevance
ex.{walker,walking}walk
•Naive terms
•Importance of term in Doc
Feature Extraction: Indexing(2)
Vector Space Model (VSM) is one of the most commonly used Text
data models
Any text document is represented by a vector of terms
• Terms are typically words and/or phrases
• Every term in the vocabulary becomes an independent dimension
• Each term in the text document would be represented by a non
zero value which will be added in the corresponding dimension
• A document collection is represented as a matrix:
• Where xji represents the weight of the ith term in jth document
Feature Extraction:Weighting Model(1)
•tf - Term Frequency weighting
wij = Freqij
Freqij : := the number of times jth term
occurs in document Di.
Drawback: without reflection of importance
factor for document discrimination.
•Ex.
D1
D2
A
ABRTSAQWA
XAO
RTABBAXA
QSAK
B K
O Q
R S T
D1
4 1
0
1
D2
4 2
1
0 1 1 1 1
W X
1 1 1 1 1
1
0 1
Feature Extraction:Weighting Model(2)
Tf-idf: simple version
wij = Freqij * log(N/ DocFreqj) .
N : := the number of documents in the training
document collection.
DocFreqj ::= the number of documents in
which the jth term occurs.
Advantage: with reflection of importance factor for
document discrimination.
Assumption:terms with low DocFreq are better discriminator
than ones with high DocFreq in document collection
A B
K O Q R S T
W X
D1
0 0
0 0.3 0 0 0 0 0.3 0
D2
0 0
0.3 0 0 0 0 0 0 0
Feature Extraction: Weighting Model(3)
•Tf-IDF weighting = TF * IDF
A
B
K
O
Q
R
0
4/12 * (lg(2/2)
]
1/12*(lg(2/1)
S
T
W
X
Feature Extraction: Dimension Reduction
• Document Frequency Thresholding
• X2-statistic
• Latent Semantic Indexing
• Information Gain
• Mutual information
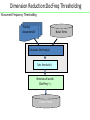
Dimension Reduction:DocFreq Thresholding
•Document Frequency Thresholding
Training
documents D
Naive Terms
Calculates DocFreq(w)
Sets threshold
Removes all words:
DocFreq <
Feature Terms
Similarity measure
There are many different ways to measure how
similar two documents are, or how similar a
document is to a query
• Highly depending on the choice of terms to
represent text documents
– Euclidian distance (L2 norm)
– L1 norm
– Cosine similarity
Document Similarity Measures
Document Similarity measures
Document Clustering: Algorithms
• k-means
• Hierarchic Agglomerative Clustering (HAC)
•….
• BIRCH
• Association Rule Hypergraph Partitioning (ARHP)
•Categorical clustering (CACTUS, STIRR)
•……
•STC
•QDC