Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Ground (electricity) wikipedia , lookup
Pulse-width modulation wikipedia , lookup
Solar micro-inverter wikipedia , lookup
Audio power wikipedia , lookup
Stray voltage wikipedia , lookup
Buck converter wikipedia , lookup
Voltage optimisation wikipedia , lookup
Power engineering wikipedia , lookup
Alternating current wikipedia , lookup
Resistive opto-isolator wikipedia , lookup
Thermal runaway wikipedia , lookup
Immunity-aware programming wikipedia , lookup
Power inverter wikipedia , lookup
Opto-isolator wikipedia , lookup
Power electronics wikipedia , lookup
Mains electricity wikipedia , lookup
Oscilloscope history wikipedia , lookup
Switched-mode power supply wikipedia , lookup
Rectiverter wikipedia , lookup
Earthing system wikipedia , lookup
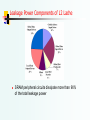
ZZ-HVS: Zig-Zag Horizontal and Vertical Sleep Transistor Sharing to Reduce Leakage Power in On-Chip SRAM Peripheral Circuits Houman Homayoun Avesta Makhzan and Alex Veidenbaum Dept. of Computer Science, UC Irvine [email protected] Outline Cache Power Dissipation Why Cache Peripheral ? Proposed Circuit Technique to Reduce Leakage in Cache Peripheral Circuit Evaluation Proposed Architecture to Control the Circuit Results Conclusion On-chip Caches and Power On-chip caches in high-performance processors are large more than 60% of chip budget Dissipate significant portion of power via leakage Much of it was in the SRAM cells Many architectural techniques proposed to remedy this Today, there is also significant leakage in the peripheral circuits of an SRAM (cache) In part because cell design has been optimized Pentium M processor die photo Courtesy of intel.com Peripherals ? Addr Input Global Drivers Bitline addr0 Global Wordline addr1 Decoder Bitline Local Wordline addr2 addr3 Predecoder and Global Wordline Drivers addr Sense amp Global Output Drivers Data Input/Output Driver Address Input/Output Driver Row Pre-decoder Wordline Driver Row Decoder Others : sense-amp, bitline pre-charger, memory cells, decoder logic Why Peripherals ? 100000 10000 1000 6300X ( pw ) 100 200X 10 m em or y ce ll IN V IN X V2 X IN V3 X IN V4 X IN V5 X IN V6 X IN V8 IN X V1 2 IN X V1 6 IN X V2 0 IN X V2 4 IN X V3 2X 1 Using minimal sized transistor for area considerations in cells and larger, faster and accordingly more leaky transistors to satisfy timing requirements in peripherals. Using high vt transistors in cells compared with typical threshold voltage transistors in peripherals Leakage Power Components of L2 Lache SRAM peripheral circuits dissipate more than 90% of the total leakage power Circuit Techniques Address Leakage in SRAM Cell Gated-Vdd, Gated-Vss Voltage Scaling (DVFS) ABB-MTCMOS Forward Body Biasing (FBB), RBB Sleepy Stack Sleepy Keeper Target SRAM memory cell Architectural Techniques Way Prediction, Way Caching, Phased Access Drowsy Cache Evict lines not used for a while, then power them down Applying DVS, Gated Vdd, Gated Vss to memory cell Keeps cache lines in low-power state, w/ data retention Cache Decay Predict or cache recently access ways, read tag first Many architectural support to do that. All target cache SRAM memory cell Sleep Transistor Stacking Effect Subthreshold current: inverse exponential function of threshold voltage VT VT 0 ( (2) F VSB 2 F ) Stacking transistor N with slpN: The source to body voltage (VM ) of transistor N increases, reduces its subthreshold leakage current, when both transistors are off Drawback : rise time, fall time, wakeup delay, area, dynamic power, instability vdd VC Vgn N CL VM Vgslpn vss slpN vss Source of Subthreshold Leakage in the Peripheral Circuitry vdd vdd W 6 L W 3 L P4 I leakage P3 P2 P1 vdd vdd W 24 L W 12 L addr0 Bitline Bitline z addr1 addr2 addr3 0 1 0 W 1.5 L W 3 L N1 I leakage N2 vss vss 0 1 W 6 L N3 vss W 12 L N4 vss The inverter chain has to drive a logic value 0 to the pass transistors when a memory row is not selected N1,N3 and P2,P4 are in the off state and are leaking A Redundant Circuit Approach Sleep signal vdd vdd vdd slpP2 slpP1 W 12 L slpP3 W 12 L W 12 L P3 1 0 slpP4 W 12 L P2 P1 vdd P4 0 1 slpN5 N1 slpN1 Sleep signal VM W 6 L vss N2 slpN2 W 6 L vss N3 slpN3 W L W 1.5 L N4 6 vss slpN4 W 6 L vss Sleep signal Drawback impact on wordline driver output rise time, fall time and propagation delay Impact on Rise Time and Fall Time vdd The rise time and fall time of the output of an inverter is proportional to the Rpeq * CL and Rneq * CL slpP1 P2 P1 I leakage 1 0 vdd slpP2 Inserting the sleep transistors increases both Rneq and Rpeq 0 N1 slpN1 N2 slpN2 I leakage vss vss Increasing in rise time Impact on performance Increasing in fall time Impact on memory functionality Fall Time Increase Impact Bitline Vdd Wordline pulse global wordline driver Bitline 1 0 M1 M2 local wordline driver Sense-amp Wordline pulse generator Fall time increase pass transistor active period increase (read operation) The bitline over-discharge, the memory content over-charge during the read operation. Such over-discharge increases the dynamic power dissipation of bitlines can cause cell content flip if the over-discharge period is large The sense amplifier timing circuit and the wordline pulse generator circuit need to be redesigned! A Zig-Zag Circuit Sleep signal vdd vdd slpP4 slpP2 W 12 L vdd 1 0 P4 P3 P2 P1 W 12 L vdd 0 1 0 slpN5 N1 slpN1 Sleep signal W 6 L vss N3 N2 vss slpN3 W 6 L W 1.5 L N4 vss vss vss Sleep signal Rpeq for the first and third inverters and Rneq for the second and fourth inverters doesn’t change. Fall time of the circuit does not change A Zig-Zag Share Circuit To improve leakage reduction and area-efficiency of the zig-zag scheme, using one set of sleep transistors shared between multiple stages of inverters Zig-Zag Horizontal Sharing Zig-Zag Horizontal and Vertical Sharing Zig-Zag Horizontal Sharing Zz-hs less impact on rise time Both reduce leakage almost the same vdd vdd Comparing zz-hs with zigzag scheme, with the same area overhead Sleep signal slpP P2 P1 1 0 N1 vdd P3 P4 N3 N4 0 N2 VM Sleep signal 2 x slpN vss R Neq I share vss vss R N1 I share R nslp zz hs vss R nslp zz 2 Zig-Zag Horizontal and Vertical Sharing vdd Sleep signal vdd vdd Word-line Driver line K vdd vdd Word-line Driver line K +1 slpP P 11 P12 P 13 P14 P 21 P22 P 23 P24 N11 VM N 12 N 13 N 14 N21 N 22 N 23 N 24 Sleep signal slpN vss vss vss vss vss Leakage Reduction of Zig-Zag Horizontal and Vertical Sharing (a) (b) vdd Vg0 Vg0 N 11 IN11 Vg0 vdd VM1 I slpN slpN vss Vg0 N 21 IN21 Vg0 vdd VM1 I slpN slpN Vg0 N11 N21 IN 21 IN11 VM2 Vg0 vdd I slpN slpN vss Increase in virtual ground voltage increase leakage reduction vss VM 1 VM 2 n. log WN 1 1 Wslp N 10 Vdd Vg 0 2 n. log 2.WN 1 1 Wslp N 10 Vdd Vg 0 2 Circuit Evaluation Test Experiment Wordline inverter chain drives 256 one-bit memory cells. Using Mentor Graphic IC-Station in TSMC 65nm technology Use Synopsis Hspice and the supply voltage of 1.08V at typical corner (250 C) The empirical results presented are for the leakage current rise time and fall time propagation delay dynamic power area 50 4 45 3.9 40 3.8 35 3.7 30 3.6 25 3.5 20 3.4 15 3.3 10 3.2 5 3.1 0 3 e li n se a b nt da n u red g za zig Leakage Power hs zz- -1W hs zz- -2W dynamic power Dynamic power increase of 1.5% to 3.5% Max leakage reduction of 94% (uW) (nW) Zig-zag Horizontal Sharing: Power Results Zig-zag Horizontal Sharing: Latency Results 210 (ps) 190 170 150 130 110 90 70 50 li se ba ne u red nd t an g za z ig Propagation Delay hs z z- -1W Fall Time -2W hs z z- Rise Time Both zig-zag and zig-zag share wordline driver fall time is not affected zz-hs-2W has the least impact on rise time and propagation delay Zig-zag Horizontal Sharing: Area Results 16 14 12 8 ( 2 ) 10 6 4 2 0 t ine an l d e n s u ba red W W z ag g s -1 s -2 i h h z zz zz Area increase varies significantly from 25% for zz-hs-1W circuit to 115% for the redundant scheme ZZ-HVS Evaluation : Power Result 1000 (a) x100 log (nW) 100 x10 x12 10 x2 1 1 2 3 4 5 6 7 8 9 10 number of wordline row baseline redundant zigzag zz-hs zz-hvs Increasing the number of wordline rows share sleep transistors increases the leakage reduction and reduces the area overhead Leakage power reduction varies form a 10X to a 100X when 1 to 10 wordline shares the same sleep transistors 2~10X more leakage reduction, compare to the zig-zag scheme ZZ-HVS Evaluation : Area Result 160 (b) 140 120 80 ( 2) 100 60 40 20 0 1 2 3 baseline 4 5 6 7 number of wordline row redundant zigzag 8 zz-hs 9 10 zz-hvs zz-hvs has the least impact on area, 4~25% depends on the number of wordline rows shared ZZ-HVS Circuit Evaluation: Sleep Transistor Sizing Leakage power (nW) Propagation delay (ps) baseline W(1X) 2W(2X) 3W(3X) 4W(4X) 460 5.11 9.13 12.63 15.7 164 198 180 174 169 Trade-off between the leakage savings and impact on the wordline driver propagation delay zz-hvs-3W (3X) show an optimal trade-off 40X reduction in leakage at 5% increase in propagation delay Wakeup Latency To benefit the most from the leakage savings of stacking sleep transistors keep the bias voltage of NMOS sleep transistor as low as possible (and for PMOS as high as possible) Drawback: impact on the wakeup latency of wordline drivers Wakeup latency associated with the zz-hvs-3W circuit is 1.3ns 4 processor cycles (3.3 GHz) For large memory, such as 2MB L2 cache the overall wake up latency can be as high 6 to 10 cycles Impact on Propagation Delay The zz-hvs increases the propagation delay of the peripheral circuit by 5%, when applied to wordline drivers, input/output drivers, etc Translate to 5% reduction in maximum operating clock frequency of the memory in a single pipeline memory Deep pipelined memories such as L1 and L2 cache hide negligible increase in peripheral circuit latency Sleep-Share: ZZ-HVS + Architectural Control When an L2 cache miss occurs the processor executes a number of miss-independent instructions and then ends up stalling The processor stays idle until the L2 cache miss is serviced. This may take hundreds of cycle (300 cycles for our processor architecture) During such a stall period there is no access to L1 and L2 caches and they can be put into low-power mode Detecting Processor Idle Period The instruction queue and functional units of the processor monitored after an L2 miss Instruction queue has not issued any instructions Functional units have not executed any instructions for K consecutive cycles (K=10) The sleep signal is asserted The sleep signal is de-asserted 10 cycles before the miss service is completed Assumption: memory access latency is deterministic. No performance loss Simulated Processor Architecture Parameter Value L1 I-cache L1 D-cache L2 cache Fetch, dispatch Issue Memory Reorder buffer Instruction queue Register file Load/store queue Branch predictor Arithmetic unit Complex unit Pipeline 128KB, 2 cycles 128KB, 2 cycles 2MB, 8 way, 20 cycles 4 wide 4 way out of order 300 cycles 96 entry 32 entry 128 integer and 125 floating point 32 entry 64KB entry g-share 4 integer, 4 floating point units 2 INT, 2 FP multiply/divide units 15 cycles SimpleScalar 4.0 SPEC2K benchmarks Compiled with the -O4 flag using the Compaq compiler targeting the Alpha 21264 processor fast–forwarded for 3 billion instructions, then fully simulated for 4 billion instructions using the reference data sets. L1 and L2 Leakage Power Reduction 60% 50% 40% 30% 20% 10% vp r am m p ap pl eq u ua k fa e ce re c lu ca s m gr id sw i w up m w i av se er ag e m p e cf rl bm k pa rs er gc c ga p bz ip 2 0% L1 Leakage power reduction L2 Leakage power reduction Leakage reduction of 30% for the L2 cache and 28% for the L1 cache Conclusion Study break down of leakage in L2 cache components, show peripheral circuit leaking considerably proposed zig-zag share to reduce leakage in SRAM memory peripheral circuits zig-zag share reduces peripheral leakage by up to 40X with only a small increase in memory area and delay Propose Sleep-Share to control zig-zag share circuits in L1 and L2 cache peripherals Leakage reduction of 30% for the L2 cache and 28% for the L1 cache