Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Programming Multi-Core
Processors based Embedded
Systems
A Hands-On Experience on Cavium
Octeon based Platforms
Lecture 1 (Overview)
Course Objectives
A hands-on opportunity to learn:
Multi-core architectures; and
Programming multi-core systems
Emphasis on programming:
Using multi-threading paradigm
Understand the complexities
Apply to generic computing/networking problems
Implement on an popular embedded multi-core
platform
1-8
KICS, UET
Grading Policy and Reference Books
Grading Policy
Lectures
Labs
Quizzes (daily)
(40%)
(50%)
(10%)
Reference material:
Shameem Akhtar and Jason Roberts, Multi-Core
Programming, Intel Press, 2006
David E. Culler and Jaswinder Pal Singh, Parallel
Class notes
Computer Architecture: A Hardware/Software
Approach, Morgan Kaufmann, 1998
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Course Outline
Introduction
Parallel architectures and terminology
Context for current interest: multi-core processors
Programming paradigms for multi-core
Octeon processor architecture
Multi-threading on multi-core processors
Applications for multi-core processors
Application layer computing on multi-core
Performance measurement and tuning
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
An Introduction to Parallel
Computing in the context of
Multi-Core Architectures
Developing Software for Multi-Core:
A Paradigm Shift
Application developers are typically oblivious
of underlying hardware architecture
Sequential program
Automatic/guaranteed performance benefit with
processor upgrade
No work on the programmer
No “free lunch” with multi-core systems
Multiple cores in modern processors
Parallel programs needed to exploit parallelim
Parallel computing is now part of main-stream
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Parallel Computing for Main-Stream:
Old vs. New Programming Paradigms
Known tools and techniques:
Multi-threading for multi-core
High performance computing and communication (HPCC)
Wealth of existing knowledge about parallel algorithms,
programming paradigms, languages and compilers, and
scientific/engineering applications
Common in desktop and enterprise applications
Exploits parallelism of multi-core with its challenges
New realizations of old paradigms:
Parallel computing on Playstation 3
Parallel computing on GPUs
Cluster computing for large volume data
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Dealing with the Challenge of Multi-Core
Programming with Hands-On Experience
Our objective is two-fold
Overview the known paradigms for background
Learn using the state-of-the-art implementations
Choice of platform for hands-on experience
Cavium Networks’ Octeon processor based system
Multiple cores (1 to 16)
Suitable for embedded products
Commonly used in networking products
Standard Linux based development environment
Copyright © 2010 Cavium University Program
1-8
KICS, UET
Agenda for Today
Parallel architectures and terminology
Why multi-core architectures?
Traditional parallel computing
Transition to multi-core architectures
Programming paradigms
Processor technology trends
Architecture trends
Taxonomy
Traditional
Recent additions
Introduction to Octeon processor based systems
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Architecture and Terminology
Background of parallel architectures
and commonly used terminology
Architectures and Terminology
Objectives of this section:
Understand the processor technology trends
Realize that parallel architectures evolve based on
technology and architecture trends
Terminology used in parallel computing
Von Neumann
Flynn’s taxonomy
Bell’s taxonomy
Other commonly used terminology
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Processor Technology Trends
Processor technology evolution,
Moore’s law, ILP, and current trends
Processor Technology Evolution
Increasing number of transistors on a chip
Increasing clock rates during 90’s
Moore’s law: number of transistors on a chip is expected to
double every 18 months
Chip densities are reaching their physical limits
Technological breakthroughs have kept Moore’s law alive
Faster and smaller transistors, gates, and circuits on a chip
Clock rates of microprocessors increase by ~30% per year
Benchmark (e.g., SPEC suite) results indicate
performance improvement with technology
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Moore’s Law
Gordon Moore , Founder of Intel
1965: since the integrated circuit was invented,
the number of transistors/inch2 in these circuits
roughly doubled every year this trend would
continue for the foreseeable future
1975: revised - circuit complexity doubles every
18 months
This was simply a prediction
Based on little data
However, it has defined the processor industry
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Moore’s
Original
Law (2)
ftp://download.intel.com/research/
Copyright © 2010
silicon/moorespaper.pdf
Cavium University
Program
1-8
KICS, UET
Moore’s Original Issues
Design cost still valid
Power dissipation still valid
What to do with all the functionality possible
Copyright ftp://download.intel.com/research/silicon/moorespaper.pdf
© 2010
Cavium University
Program
1-8
KICS, UET
Moore’s Law and Intel Processors
Copyright
© 2010
From: http://www.intel.com/technology/silicon/mooreslaw/pix/mooreslaw_chart.gif
Cavium University
Program
KICS, UET
1-8
Good News:
Moore’s Law isn’t done yet
Copyright
© 2010by Dr. Tim Mattson, Intel Corp.
Source: Webinar
Cavium University
Program
1-8
KICS, UET
Bad News:
Single Thread Performance is Falling Off
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Worse News:
Power (normalized to i486) Trend
Copyright © 2010
Cavium
Source: University
Webinar by Dr. Tim Mattson, Intel Corp.
Program
1-8
KICS, UET
Addressing Power Issues
Source: Webinar by Dr. Tim Mattson, Intel Corp.
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Architecture Optimized for Power:
a big step in the right direction
Copyright © 2010
Cavium
Source: University
Webinar by Dr. Tim Mattson, Intel Corp.
Program
1-8
KICS, UET
Long term solution: Multi-Core
Copyright © 2010
Cavium University
Program
Source: Webinar by Dr. Tim Mattson, Intel Corp.
1-8
KICS, UET
Summary of Technology Trends
Moore’s law is still relevant
Need to deal with related issues
Design complexity
Power consumption
Uniprocessor performance is slowing down
Multiple processor cores resolve these issues
Parallelism at hardware level
End user is exposed to it
Added complexities related to programming such
systems
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Taxonomy for Parallel
Architectures
Von Neumann, Flynn, and Bell’s
taxonomies and other common
terminology
Von Neumann Architecture Evolution
Von Neumann architecture
Scalar
Sequential
Lookahead
I/E overlap
Functional
parallelism
Multiple
func.units
Pipeline
Implicit
vector
Explicit
vector
Memory to
memory
Register to
register
SIMD
Associative
processor
MIMD
Processor
array
Multicomputer
Multiprocessor
Massively Parallel Processors
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Pipelining and Parallelism
Instructions prefetch to overlap execution
Functional parallelism supported by:
Multiple functional units
Pipelining
Pipelining
Pipelined instruction execution
Pipelined arithmetic computations
Pipelined memory access operations
Pipelining is attractive for performing identical
operations repeatedly over vector data strings
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Flynn’s Classification
Michael Flynn classified architectures in 1972
based on instruction and data streams
Single Instruction stream over a Single Data
stream (SISD)
Conventional sequential machines
Single Instruction stream over Multiple Data
streams (SIMD)
Vector computers are equipped with scalar and
vector hardware
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Flynn’s Classification (2)
Multiple Instruction streams over Single Data
stream (MISD)
Same data flowing through a linear array of
processors
Aka systolic arrays for pipelined execution of
algorithms
Multiple Instruction streams over Multiple
Data streams (MIMD)
Suitable model for general purpose parallel
architectures
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Bell’s Taxonomy for MIMD
Multicomputers
Multiple address spaces
System consists of
multiple computers,
called nodes
Nodes are interconnected
by a message-passing
network
Each node has its own
processor, memory, NIC,
and I/O devices
Copyright © 2010
Cavium University
Program
Multiprocessors
Shared address space
Further classified based
on how memory is
accessed
1-8
Uniform Memory Access
(UMA)
Non-Uniform Memory
Access (NUMA)
Cache-Only Memory
Access (COMA)
Cache-Coherent NonUniform Memory Access
(cc-NUMA)
KICS, UET
Multicomputer Genenrations
First generation (1983-87)
Second generation (1988-1992)
Processor boards connected in hypercube architecture
Software-controlled message switching
Examples: Caltech Cosmic, Intel iPSC/1
Mesh connected architecture
Hardware message routing
Software environment for medium grain distributed
computing
Example: Intel Paragon
Third generation (1993-1997)
Fine grain multicomputers
MIT J-Machine and Caltech Mosaic
Copyright © 2010
Cavium
University
Examples:
Program
1-8
KICS, UET
Multiprocessor Examples
Distributed memory (scalable)
Dynamic binding of address to processors (KSR)
Static binding, caching (Alliant, DASH)
Static program binding (BBN, Cedar)
Central memory (not scalable)
Cross-point or multi-stage (Cray, Fujitsu, Hitachi,
IBM, NEC, Tera)
Simple multi bus (DEC, Encore, NCR, Sequent,
SGI, Sun)
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Supercomputers
Supercomputers use vector processing and
data parallelism
Classified into two categories
Vector supercomputers
SIMD supercomputers
SIMD machines with massive data parallelism
Instruction is broadcast to large number of Pes
Examples: Illiac (64 PEs), MasPar MP-1 (16,384 PEs),
and CM-2 (65,538 PEs)
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Vector supercomputers
Machines with powerful vector processors
If decoded instruction is a vector operation, it
is sent to vector unit
Register-register architecture:
Memory-to-memory architecture:
Fujitsu VP2000 series
Cyber 205
Pipelined vector supercomputers:
Cray Y-MP
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
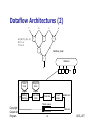
Dataflow Architectures
Represent computation as a graph of
essential dependences
Logical processor at each node, activated by
availability of operands
Message (tokens) carrying tag of next instruction
sent to next processor
Tag compared with others in matching store;
match fires execution
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Dataflow Architectures (2)
1
a = (b +1) (b c)
d=ce
f =ad
b
c
e
+
d
Dataflow graph
a
Netw ork
f
Token
store
Program
store
Waiting
Matching
Instruction
f etch
Execute
Form
token
Netw ork
Token queue
Copyright © 2010
Cavium University
Program
Netw ork
1-8
KICS, UET
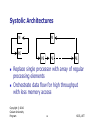
Systolic Architectures
M
M
PE
PE
PE
PE
Replace single processor with array of regular
processing elements
Orchestrate data flow for high throughput
with less memory access
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Systolic Architectures (2)
Different from pipelining
Nonlinear array structure, multidirection data flow,
each PE may have (small) local instruction and
data memory
Different from SIMD: each PE may do
something different
Initial motivation: VLSI enables inexpensive
special-purpose chips
Represent algorithms directly by chips
connected in regular pattern
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Systolic Arrays (Cont’d)
• Example: Systolic array for 1-D convolution
y(i) = w1 x(i) + w2 x(i + 1) + w3 x(i + 2) + w4 x(i + 3)
x8
x7
x6
x5
x4
x3
x2
w4
y3
y2
yin
w1
x
w
xout
xout = x
x = xin
yout = yin + w xin
yout
Enable variety of algorithms on same hardware
But dedicated interconnect channels
w2
Practical realizations (e.g. iWARP) use quite general processors
w3
y1
xin
x1
Data transfer directly from register to register across channel
Specialized, and same problems as SIMD
General
purpose systems work well for same algorithms (locality etc.)
Copyright
© 2010
Cavium University
Program
KICS, UET
1-8
Cluster of Computers
Started as a poor man’s parallel system
In-expensive PCs
In-expensive switched Ethernet switch
Run-time system to support message-passing
Low performance for HPCC applications
High network I/O latency
Low bandwidth
Suitable for high throughput applications
Data center applications
Virtualized resources
Independent threads or processes
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Summary of Taxonomy
Multiple taxonomies
Based on functional parallelism
Based on programming paradigm
Von Neumann and Flynn’s taxonomies
Bell’s taxonomy
Parallel architecture types
Multi-computers (distributed address space)
Multi-processors (shared address space)
Multi-core
Multi-threaded
Others: vector, data flow, systolic, and cluster
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Why Multi-Core Architectures
Based on technology and architecture
trends
Multi-Core Architectures
Traditional architectures
Transition to multi-core
Sequential Moore’s law = increasing clk freq
Parallel
Diminishing returns from ILP
Architecture similar to SMPs
Programming typically SAS
Challenges to transition
Performance = efficient parallelization
Selecting a suitable programming paradigm
Performance tuning
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Traditional Parallel
Architectures
Definition and development tracks
Defining a Parallel Architecture
A sequential architecture is characterized by:
Parallel architecture:
Single processor
Single control flow path
Multiple processors with interconnection network
Multiple control flow paths
Communication and synchronization
A parallel computer can be defined as a collection of
processing elements that communicate and
cooperate to solve large problems fast
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Broad Issues in Parallel
Architectures
Resource allocation:
Data access, communication and synchronization
how large a collection?
how powerful are the elements?
how much memory?
how do the elements cooperate and communicate?
how are data transmitted between processors?
what are the abstractions and primitives for cooperation?
Performance and scalability
how does it all translate into performance?
how does it scale?
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
General Context: Multiprocessors
Multiprocessor is any
computer with several
processors
SIMD
Single instruction, multiple data
Modern graphics cards
MIMD
Multiple instructions, multiple data
Copyright © 2010
Cavium University
Program
1-8
Lemieux cluster,
Pittsburgh
supercomputing
center
KICS, UET
Architecture Developments Tracks
Multiple-Processor Tracks
Shared-memory track
Message-passing track
Multivector and SIMD Tracks
Multithreaded and Dataflow Tracks
Multi-core track
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Shared-Memory Track
Starts with C.mmp system developed at CMU in 1972
Illinois Cedar (1987)
UMA multiprocessor with 16 PDP 11/40 processors
Connected to 16 shared memory modules via crossbar
switch
Pioneering multiprocessor OS (Hydra) development effort
IBM RP3 (1985)
BBN Butterfly (1989)
NYU/Ultracomputer (1983)
Stanford/DASH (1992)
Fujitsu VPP500 (1992)
KSR1 (1990)
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Message-Passing Track
The Cosmic Cube (1981) pioneered messagepassing computers
Intel iPSCs (1983)
Intel Paragon (1992)
Medium-grain multicomputers
nCUBE-2 (1990)
Mosaic (1992)
MIT/J Machine (1992)
Fine-grain multicomputers
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Multivector Track
CDC 7600 (1970)
Cray 1 (1978)
Cray Y-MP (1989)
Fujitsu, NEC, Hitachi models
CDC Cyber205 (1982)
ETA 10 (1989)
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
SIMD Track
Illiac IV (1968)
Goodyear MPP (1980)
DAP 610 (AMT, Inc. 1987)
CM2 (TMC, 1990)
BSP (1982)
IBM GF/11 (1985)
MasPar MP1 (1990)
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Multi-Threaded Track
Each processor can execute multiple threads of
control at the same time
Multi-threading helps hide long latencies in building
large-scale multiprocessors
Multithreaded architecture was pioneered by Burton
Smith in HEP system (1978)
MIT/Alewife (1989)
Tera (1990)
Symmetric Multi-Threading (SMT)
Two hardware threads
Available in Intel processors
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Dataflow Track
Instead of control-flow in von Neumann
architecture, dataflow architectures are based
on dataflow mechanism
Dataflow concept was pioneered by Jack
Dennis (1974) with a static architecture
This concept later inspired dynamic dataflow
MIT tagged token (1980)
Manchester (1982)
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Multi-Core Track
Intel Dual core processors
AMD Opteron
IBM Cell processor
SUN processors
Cavium processor
Freescale processors
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Multi-Core processor is a special kind
of a Multiprocessor
All processors are on the same chip
Multi-core processors are MIMD:
Different cores execute different threads (Multiple
Instructions),
Operate on different parts of memory (Multiple
Data)
Multi-core is a shared memory
multiprocessor:
All cores share the same address space
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Summary: Why Parallel
Architecture?
Increasingly attractive
Economics, technology, architecture, application demand
Readily available multi-core processors based systems
Increasingly central and mainstream
Parallelism exploited at many levels
Instruction-level parallelism
Multiple threads of software
Multiple cores
Multiprocessor processors
Focus of this class:
Multiple cores and/or processors
Programming paradigms
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Example: Intel Pentium Pro Quad
CPU
P-Pr o
module
256-KB
Interrupt
L2 $
controller
Bus interface
P-Pr o
module
P-Pr o
module
Copyright © 2010
Cavium University
Program
1-8
PCI
bridge
PCI bus
PCI
I/O
cards
PCI
bridge
PCI bus
P-Pr o bus (64-bit data, 36-bit address, 66 MHz)
Memory
controller
MIU
1-, 2-, or 4-w ay
interleaved
DRAM
All coherence and
multiprocessing glue
in processor module
Highly integrated,
targeted at high
volume
Low latency and
KICS, UET
bandwidth
Example: SUN Enterprise
P
$
P
$
$2
$2
CPU/mem
cards
Mem ctrl
Bus interf ace/sw itch
Gigaplane bus (256 data, 41 address, 83 MHz)
I/O cards
2 FiberChannel
SBUS
SBUS
SBUS
100bT, SCSI
Bus interf ace
16 cards of either type: processors + memory, or
I/O
All memory accessed over bus, so symmetric
Copyright © 2010
Higher bandwidth, higher latency bus
Cavium
University
Program
1-8
KICS, UET
Example: Cray T3E
External I/O
P
$
Mem
Mem
ctrl
and NI
XY
Sw itch
Z
Scale up to 1024 processors, 480MB/s links
Memory controller generates comm. request for nonlocal
references
No hardware mechanism for coherence (SGI Origin etc.
Copyrightprovide
© 2010 this)
Cavium University
Program
1-8
KICS, UET
Example: IBM SP-2
Pow er 2
CPU
IBM SP-2 node
L2 $
Memory bus
General interconnection
netw ork formed fom
r
8-port sw itches
4-w ay
interleaved
DRAM
Memory
controller
MicroChannel bus
I/O
DMA
i860
NI
DRAM
NIC
Made out of essentially complete RS6000 workstations
Network
interface integrated in I/O bus (bw limited by I/O
Copyright
© 2010
Cavium University
bus)
Program
1-8
KICS, UET
Example Intel Paragon
i860
i860
L1 $
L1 $
Intel
Paragon
node
Memory bus (64-bit, 50 MHz)
Mem
ctrl
DMA
Driver
4-w ay
interleaved
DRAM
Sandia’ s Intel Paragon XP/S-based Super computer
8 bits,
175 MHz,
bidirectional
2D grid netw ork
w ith processing node
attached to every sw itch
Copyright © 2010
Cavium University
Program
NI
1-8
KICS, UET
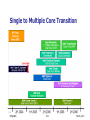
Transition to Multi-Core
Selected multi-core processors
Single to Multiple Core Transition
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Multi-Core Processor Architectures
Copyright © 2010
Source:
Michael
Perrone of IBM
Cavium
University
Program
1-8
KICS, UET
IBM POWER 4
Shipped in Dec. 2004
Technology: 180 nm
lithography
Dual processor cores
8-way superscalar
Out of order execution
2 load/store units
2 fixed and fp units
>200 insts in flight
Hardware instruction
and data pre-fetch
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
IBM POWER 5
Shipped in Aug. 2003
Technology: 130 nm
lithgraphy
Dual processor core
8-way superscalar
SMT core
Up to 2 virtual cores
Natural extension to
POWER4 design
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
IBM Cell Processor
IBM, Sony, and Toshiba
alliance in 2000
Based on IBM POWER5
64 bit architectures
9 cores, 10 threads
1 dual thread power
processor element (PPE)
for control
8 synergistic processor
element (SPE) for
processing
Up to 25 GB/s memory bw
Up to 75 GB/s I/O bw
>300 GB/s Element
Interface Bus bandwidth
Copyright © 2010
source: Dr.
Cavium University
Program
Michael Perrone, IBM
1-8
KICS, UET
Future Multi-Core Platforms
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
A Many Core Example:
Intel’s 80 Core Test Chip
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Programming the Multi-Core
Programming, OS interaction,
applications, synchronization, and
scheduling
Parallel Computing is Ubiquitous
Over the next few years, all computing devices will
be parallel computers
Servers
Laptops
Cell phones
What about software?
Herb Sutter of Microsoft said in Dr. Dobbs’ Journal:
The free lunch is over: Fundamental Turn towards
Concurrency in software
Software will no longer increase from one generation to the
next as hardware improves … unless it is parallel software
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Interaction with OS
OS perceives each core as a separate
processor
OS scheduler maps threads/processes
to different cores
Same for SMP processor
Linux SMP kernel works on multi-core processors
Migration is possible
Also, possible to pin processes to processors
Most major OSes support multi-core today:
Windows, Linux, Mac OS X, …
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
What Applications Benefit from
Multi-Core?
Database servers
Web servers (Web commerce)
Compilers
Multimedia applications
Scientific applications,
CAD/CAM
In general, applications with
Each can
run on its
own core
Thread-level parallelism
(as opposed to instructionlevel parallelism)
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
More examples
Editing a photo while recording a TV show
through a digital video recorder
Downloading software while running an antivirus program
“Anything that can be threaded today will
map efficiently to multi-core”
BUT: some applications difficult to
parallelize
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Programming for Multi-Core
Programmers must use threads or processes
Spread the workload across multiple cores
Threads are relevant for business/desktop apps
Multiple processes with complex systems or SPMD
based parallel applications
OS maps threads/processes to cores
Transparent to the programmer
Write parallel algorithms
True for scientific/engineering applications
Programmer needs to define the mapping to cores
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Thread Safety is very important
Pre-emptive context switching:
context switch can happen AT ANY TIME
True concurrency, not just uniprocessor timeslicing
Concurrency bugs exposed much faster with
multi-core
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
However: Need to use synchronization even if
only time-slicing on a uniprocessor
int counter=0;
void thread1() {
int temp1=counter;
counter = temp1 + 1;
}
void thread2() {
int temp2=counter;
counter = temp2 + 1;
}
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Need to use synchronization even if only time-slicing
on a uniprocessor
temp1=counter;
counter = temp1 + 1;
temp2=counter;
counter = temp2 + 1
gives counter=2
temp1=counter;
temp2=counter;
counter = temp1 + 1;
counter = temp2 + 1
Copyright © 2010
Cavium University
Program
gives counter=1
1-8
KICS, UET
Assigning Threads to the Cores
Each thread/process has an affinity mask
Affinity mask specifies what cores the thread
is allowed to run on
Different threads can have different masks
Affinities are inherited across fork()
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Affinity Masks are Bit Vectors
Example: 4-way multi-core, without SMT
1
1
0
core 3
core 2
core 1
1
core 0
• Process/thread is allowed to run on
cores 0,2,3, but not on core 1
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Affinity Masks when Multi-Core and
SMT are Combined
Separate bits for each simultaneous thread
Example: 4-way multi-core, 2 threads per
core
1
1
core 3
thread
1
thread
0
0
0
core 2
thread
1
thread
0
1
0
core 1
thread
1
thread
0
1
1
core 0
thread
1
thread
0
• Core 2 can’t run the process
Copyright © 2010
• Core
1 can only use one simultaneous thread
Cavium University
Program
1-8
KICS, UET
Default Affinities
Default affinity mask is all 1s:
all threads can run on all processors
Then, the OS scheduler decides what threads
run on what core
OS scheduler detects skewed workloads,
migrating threads to less busy processors
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Process Migration is Costly
Need to restart the execution pipeline
Cached data is invalidated
OS scheduler tries to avoid migration as much
as possible:
it tends to keeps a thread on the same core
This is called soft affinity
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Hard Affinities
The programmer can prescribe their own
affinities (hard affinities)
Rule of thumb: use the default scheduler
unless a good reason not to
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
When to Set your own Affinities
Two (or more) threads share data-structures
in memory
map to same core so that can share cache
Real-time threads:
Example: a thread running
a robot controller:
must not be context switched,
or else robot can go unstable
dedicate an entire core just to this thread
Copyright © 2010
Cavium University
Program
1-8
Source: Sensable.com
KICS, UET
Kernel Scheduler API
#include <sched.h>
int sched_getaffinity(pid_t pid,
unsigned int len, unsigned long * mask);
Retrieves the current affinity mask of process
‘pid’ and stores it into space pointed to by
‘mask’.
‘len’ is the system word size: sizeof(unsigned
int long)
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Kernel Scheduler API
#include <sched.h>
int sched_setaffinity(pid_t pid,
unsigned int len, unsigned long * mask);
Sets the current affinity mask of process ‘pid’ to
*mask
‘len’ is the system word size: sizeof(unsigned int
long)
To query affinity of a running process:
$ taskset -p 3935
Copyright ©pid
20103935's current affinity mask: f
Cavium University
Program
1-8
KICS, UET
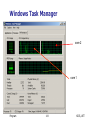
Windows Task Manager
core 2
core 1
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Summary
Reasons for multi-core based systems:
Background of using multi-core systems:
Processor technology trends
Architecture trends and diminishing returns
Application trends
Traditional parallel architectures
Experience with parallelization
Transition to multi-core is happening
Challenge: programming the multi-core
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Programming Paradigms
Traditional as well as new additions
Programming Paradigms
In the context of multi-core systems
Traditional paradigms and their use for parallelization
Architecture is similar to SMPs
SAS programming works
However, message-passing is also possible
Explicit message passing (MP)
Shared address space (SAS)
Multi-threading as a parallel computing model
New realizations of traditional paradigms
Multi-threading on Sony Playstation 3
MapReduce
CUDA
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Traditional Programming Models
David E. Culler and Jaswinder Pal
Singh, Parallel Computer Architecture:
A Hardware/Software Approach,
Morgan Kaufmann, 1998
Parallel Programming Models
Message passing
Each process uses its private address space
Access to non-local address space through explicit
message passing
Full control of low level data movement
Data parallel programming
Extension of message passing
Parallelism based on data decomposition and
assignment
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Parallel Programming Models (2)
Shared memory programming
Multi-threading
Single address space (SAS)
Hardware manages low level data movement
Primary issue is coherence
An extension of SAS
Commonly used on SMP as well as UP systems
Libraries and building blocks
Often specific to architectures
Help reduce the development effort
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Message Passing
Message passing operations
Point-to-point unicast
Collective communication
Efficient collective communication can greatly enhance
performance
Characteristics of message-passing:
Programmer’s control over interactions
Customizable to leverage hardware features
Tunable to enhance performance
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Distributed Memory Issues
Load balancing
Data locality
High performance depends on keeping processor busy
Required data should be kept locally (decomposition and
assignment)
Data distribution
Programmer has explicit control over load balancing
Data distribution affects the computation-to-communication
ratio
Low level data movement and process control
Data movement result from algorithmic structure
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Data Movement and Process Control
Types of low level data
movements
Process control involves
Replication
Reduction
Scatter/gather
Parallel prefix,
segmented scan
Permutation
Data movement results
in communication
Copyright © 2010
Cavium University
Program
1-8
Barrier synchronization
Global conditionals
High performance
depends on efficient data
movement
Overhead results due to
processes waiting for
data
KICS, UET
Message Passing Libraries
Motivation
Portability: application need not be reprogrammed
on a new platform
Heterogeneity
Modularity
Performance
Implementations
PVM, Express, P4, PICL, MPICH, etc.
MPI has become a de facto API standard
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Data Parallel Programming
This is an extension of message passing
based programming
Instead of explicit message passing,
parallelism is implemented implicitly in
languages
Parallelism comes from distributing data structures
and control
Implemented through hints for compilers
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Data Parallel Programming (2)
Motivations
Explicit message passing programs are difficult to
write and debug
Data distribution results in computation on local
data
Useful for massively parallel distributed-memory
as well as cluster of workstations
Developed as extensions to existing
languages
Fortran, C/C++, Ada, etc.
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
High Performance Fortran (HPF)
HPF defines language extensions to Fortran
To support data parallel programming
Compiler generates a message-passing program
Features include:
Data distribution and alignment
Purpose is to reduce inter-processor communication
DISTRIBUTE, ALIGN, and PROCESSORS directives
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
HPF (2)
Features (cont’d):
Parallel statements
Extended intrinsic functions and standard library
EXTRINSIC procedures
Provide ability to express parallelism
FORALL, INDEPENDENT, and PURE directives
Mechanism to use efficient machine-specific primitives
Limitations
Useful only for FORTRAN code
Not useful outside of HPCC domain
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Shared Memory Programming
Single address space view of the entire memory
Logical for the programmer
Easier to use
Parallelism comes from loops
Require loop level dependence analysis
Various iterations of a loop that are independent wrt index
can be scheduled on different processors
Fine grained parallelism
Requires hardware support for memory consistency to avoid
overhead
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Shared Memory Programming (2)
Performance tuning is non-trivial
Data locality is critical
Reduce the grain size by parallelizing the outer-most loop
Simplifies parallel programming
Require inter-procedural dependence analysis
Very few parallelizing compilers that can analyze and parallelize
even reasonable size of application codes
Sequential code is directly usable with compiler hints for
parallel loops
OpenMP standardizes the compiler directives for
shared memory parallel programming
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Libraries and Building Blocks
Pre-implemented parallel code that may work
as kernels of larger well-known parallel
applications
Several numerical methods are reusable in various
applications;
Example:
linear equation solver,
partial differential equations,
matrix based operations etc.
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Libraries and Building Blocks (2)
Low level operations, such as data
movement, can be used for efficient matrix
operations
Matrix transpose
Matrix multiply
LU decomposition
These building blocks can be implemented in
distributed-memory numerical libraries
Examples:
ScaLPACK: dense and banded matrices
Massively parallel LINPACK
Copyright © 2010 Cavium
University Program
1-8
KICS, UET
Summary: Traditional Paradigms
Message-passing based programming
Suitable for distributed memory multi-computers
Multiple message-passing libraries exist
MPI is a de facto standard
Shared address space programming
Suitable for SMPs
Based on low-granularity loop-level parallelism
Implemented through compiler directives
OpenMP is a de facto standard
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Threading as a parallel
programming model
Types of applications and threading
environments
Parallel Programming with Threads
Two types of applications:
Threads help in different ways
Compute-intensive applications HPCC systems
Throughput-intensive applications Distributed systems
By dividing data reduces work per thread
By distributing work enables concurrency
Programming languages that support threads
C/C++ or C#
Java
OpenMP directives for C/C++ code
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Virtual Environments
VMs and platforms
Runtime virtualization
System virtualization
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Systems with Virtual Machine Monitors
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Summary: Threading for Parallelization
Threads can exploit parallelism on multi-core
Shared memory programming realized through:
Scientific and engineering applications
High throughput applications
Pthread
OpenMP
Challenges of multi-threading:
Synchronization
Memory consistency is the dark side of shared memory
Copyright © 2010
Cavium University
Program
1-8
KICS, UET
Octeon Processor
Acrchitecture
Target system processor and system
architecture and programming
environment
Cavium Octeon Processor
MIPS64
architecture
Up to 16
cores
Shared L2
cache
Security
accelerator
Used in
network
security
gateways
Copyright © 2010
Cavium University
Program
source: http://www.caviumnetworks.com/OCTEON_CN38XX_CN36XX.html
1-8
KICS, UET
Key Takeaways for Today’s Session
Multi-core systems are here to stay
Programming is a challenge
Processor technology trends
Application performance requirements
No “free lunch”
Programmers need to parallelize
Extra effort to tune the performance
Programming paradigms
Message passing
Shared address space based programming
Multi-threading focus for this course
Copyright © 2010
Cavium University
Program
1-8
KICS, UET