Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
SPARSITY-BASED LIVER METASTASES DETECTION USING
LEARNED DICTIONARIES
Avi Ben-Cohen1, Eyal Klang2, Michal Amitai2, Hayit Greenspan1
1
Tel Aviv University, Faculty of Engineering, Department of Biomedical Engineering, Medical Image
Processing Laboratory, Tel Aviv 69978, Israel
2
Sheba Medical Center, Diagnostic Imaging Department, Abdominal Imaging Unit, Tel Hashomer
52621, Israel
ABSTRACT
In this work we explore sparsity-based approaches for the
task of liver metastases detection in liver computedtomography (CT) examinations. Sparse signal representation
has proven to be a very powerful tool for robustly acquiring,
representing, and compressing high-dimensional signals that
can be accurately constructed from a compact, fixed set
basis. We explore different sparsity based classification
techniques and compare them to state of the art
classification schemes. These methods were tested on CT
examinations from 20 patients taken in different times, with
overall 68 lesions. Best performance was achieved using the
label consistent K-SVD (LC-KSVD) method, with detection
rate of 91%, 0.9 false positive (FP) rate and classification
accuracy (ACC) of 96%. The detection rates as well as the
classification results are promising. Future work entails
expanding the method to 3D analysis as well as testing it on
a larger database.
Index Terms— Sparsity,
Metastases, CT, super-pixels.
Classification,
Liver-
1. INTRODUCTION
Liver cancer is among the most frequent types of cancerous
diseases, responsible for the deaths of 745,000 patients
worldwide in 2012 alone [1]. The liver is one of the most
common organs to develop metastases and CT is one of the
most common modalities used for detection, diagnosis and
follow-up of liver lesions [2]. The images are acquired
before and after intravenous injection of a contrast agent
with optimal detection of lesions on the portal phase (60-80
seconds post injection) images. These procedures require
information about size, shape and precise location of the
lesions. Manual detection and segmentation is a timeconsuming task requiring the radiologist to search through a
3D CT scan which may include multiple lesions. The
difficulty of this task highlights the need for computerized
analysis to assist clinicians in the detection and evaluation
of the size of liver metastases in CT examinations.
Automatic detection and segmentation is a very challenging
task due to different contrast enhancement behavior of liver
978-1-4799-2349-6/16/$31.00 ©2016 IEEE
lesions and parenchyma. Moreover, the image contrast
between these tissues can be low due to individual
differences in perfusion and scan time. In addition, lesion
shape, texture, and size vary considerably from patient to
patient. This research problem has attracted a great deal of
attention in recent years. The MICCAI 2008 Grand
Challenge [3] provided a good overview of possible
methods. The winner of the challenge [4] used the AdaBoost
technique to separate liver lesions from normal liver based
on several local image features. In more recent works we
see a variety of additional methods trying to deal with
detection and segmentation of liver lesions [5, 6].
Sparse signal representation has proven to be a very
powerful tool for robustly acquiring, representing, and
compressing high-dimensional signals that can be accurately
constructed from a compact, fixed basis set. Liu et al. [7]
proposed a sparsity based classification framework, in
which dictionary learning was used for training and sparse
coding for testing, for computer-aided diagnosis (CAD)
problems. Their method was validated in two CAD systems
of colorectal polyp and lung nodule detection, using large
scale, representative clinical datasets and achieved
approximately 90% sensitivity with a 2.6 FP rate. Liu et al.
[7] used the general sparse representation for building a
dictionary. Other works focus on discriminative sparse
representation methods [8-10]. In the current work, we use
the label consistent K-SVD (LC-KSVD) method [9] and
compare it to the general sparse representation [7] for both
the dictionary construction and the classification task. To
the best of our knowledge, this is the first work that uses a
sparse representation for liver lesions detection.
2. METHODS
2.1. Framework
Fig. 1 illustrates the general framework of the proposed
methodology. We start with a given liver segmentation
mask – focusing on the liver region. The current work is in
2D and the analysis is conducted per CT slice (axial plane).
Ground truth segmentation mask of the lesions was obtained
by the radiologists for the entire data. A liver segmentation
mask was also given by the radiologists for some cases and
by us for the rest to narrow the search area to the liver itself.
1195
For each liver region, we generate a superpixels map. Each
superpixel is then represented by a feature vector as
described in Section 2.2. Feature vectors extracted from the
super-pixels are fed into K-SVD to generate an initial
dictionary for the discriminative learning step. Details of the
discriminative sparse model with the LC-KSVD will be
discussed in section 2.3.
2.2. Super-pixels representation
Each image was clustered into 500 super-pixels using the
well-known SLIC algorithm [11]. The SLIC algorithm is
known to preserve strong edges. As Figure 2 illustrates, this
ensures that the superpixels align to preserve the overall
liver boundary and the lesions boundaries. Non-liver super
pixels were not included in the classification. Each superpixel was represented by a 125 length feature vector.
Features include histogram statistics and various textural
features such as Gabor filters, LBP (local binary patterns)
and acutance [12] around the super-pixel boundary. These
features hold information of the super-pixel’s gray levels
distribution, texture patterns, edges behavior and contrast
around the super-pixel’s boundary. A super-pixel was
defined as a lesion if most of it is inside the lesion
segmentation mask given by the expert.
Fig. 1. Algorithm general framework
2.3. LC- KSVD
The LC-KSVD method [9] aims to leverage the supervised
information (i.e., labels) of input signals to learn a
reconstructive and discriminative dictionary. Each
dictionary item is chosen so that it represents a subset of the
training signals ideally from a single class, such that each
dictionary item 𝑑𝑘 can be associated with a particular label.
Hence, there is an explicit correspondence between
dictionary items and the labels. This is done by adding a
label consistency regularization term and a joint
classification error and label consistency regularization term
into the objective function for learning a dictionary with
more balanced reconstructive and discriminative power. In
the following we provide a short overview: Let 𝑌 be a set of
𝑛-dimensional 𝑁 input vectors, i.e, 𝑌 = [𝑦1 , … 𝑦𝑁 ] ∈ ℝn×N
This method solves the following objective function:
< 𝐷, 𝑊, 𝐴, 𝑋 > = arg min ‖𝑌 − 𝐷𝑋‖22
𝐷,𝑊,𝐴,𝑋
+ 𝛼‖𝑄 − 𝐴𝑋‖22
(1)
+ 𝛽‖𝐻 − 𝑊𝑋‖22
𝑠. 𝑡 ∀𝑖 ‖𝑥𝑖 ‖0 ≤ 𝑇
where ‖𝑌 − 𝐷𝑋‖22 denotes the reconstruction error and 𝐷 =
[𝑑1 , … , 𝑑𝑘 ] ∈ ℝn×K is the learned dictionary, 𝑋 =
[𝑥1 , … , 𝑥𝑁 ] ∈ ℝK×N are the sparse codes of input signals 𝑌,
and 𝑇 is a sparsity constraint factor. The relative
contribution between reconstruction and label consistency
regularization is controlled by parameter α and Q =
[q1 , … , qN ] ∈ ℝK×N are the “discriminative” sparse codes of
Fig. 2. SLIC super-pixels (white) on liver CT image
t
input signals Y for classification. qi = [q1i , … qKi ] =
[0, … 1,1, … ,0]t ∈ ℝK is a “discriminative” sparse code
corresponding to an input signal yi if the nonzero values of
qi occur at those indices where the input signal yi and the
dictionary item dk share the same label. A is a linear
transformation matrix, which transforms the original sparse
codes x to be most discriminative in sparse feature space
ℝK .
The term ‖Q − AX‖22 represents the discriminative sparse
code error, which enforces that the transformed sparse codes
AX approximate the discriminative sparse codes Q. It forces
the signals from the same class to have very similar sparse
representations.
The term ‖H − WX‖22 represents the classification error. W
denotes the linear classifier parameters (f(x, W) = Wx).
H = [h1 , … , hN ] ∈ ℝm×N are the class labels of input
signals Y . hi = [0,0, … ,1, … ,0,0]t ∈ ℝm is a label vector
corresponding to an input signal yi , where the nonzero
position indicates the class of yi . β is a scalar controlling the
relative contribution of this term.
1196
2.3. General classification using learned dictionaries
We compare the proposed scheme to the general sparse
classification techniques shown in [7]: Given that the
training samples are in the form of 𝐿 ≥ 2 categories,
(𝑙)
(𝑙)
{𝑌 (𝑙) ∈ ℝ𝑛×𝑁𝑙 : 𝑙 = 1, … , 𝐿}, where
𝑌 (𝑙) = (𝑦1 , … , 𝑦𝑁𝑙 )
consists of 𝑁𝑙 training samples labeled by 𝑙. K-SVD is
applied as shown in [13], obtaining the dictionary 𝐷 (𝑙) for
each = 1, … , 𝐿 . Now 𝐷 (𝑙) consists of the main atoms or
features of the 𝑙-th category, and all the samples belonging
to this category can be sparsely represented by 𝐷 (𝑙) .
Moreover, we can concatenate all 𝐷 (𝑙) to construct the
global dictionary 𝐷 as follows
(2)
𝐷 = (𝐷 (1) , 𝐷 (2) , … , 𝐷 (𝐿) ) ∈ ℝ𝑛×𝑁
Here 𝑁 = ∑𝑙 𝑁𝑙 .
In order to classify a new sample, 𝑦, the following
minimization problem is solved
min‖𝑥‖0 , 𝑠𝑢𝑏𝑗𝑒𝑐𝑡 𝑡𝑜 ‖𝑦 − 𝐷𝑥‖2 ≤ 𝜖
(3)
𝑥
With the global dictionary 𝐷 using orthogonal matching
pursuit (OMP) [14]. Then 𝑦 is classified based on the
coefficient vector 𝑥. A label 𝑙 is assigned to 𝑦 if the solution
𝑥 = (𝑥 (1) ; … ; 𝑥 (𝐿) ) of (3) satisfies
(4)
‖𝑥 (𝑙) ‖0 = max {‖𝑥 (𝑚) ‖0 : 𝑚 = 1, … , 𝐿}
The 𝑙0 norm in (4) can be replaced by the 𝑙1 norm which can
retain the sparsity property and take the magnitudes of the
coefficients into account.
Another criterion for classification is to solve the percategory objective
min
‖𝑧 (𝑙) ‖0 , 𝑠𝑢𝑏𝑗𝑒𝑐𝑡 𝑡𝑜 ‖𝑦 − 𝐷 (𝑙) 𝑧 (𝑙) ‖2 ≤ 𝜖
(5)
(𝑙)
𝑧
for 𝑙 = 1, … , 𝐿 repectively, and obtain the coefficients 𝑧 (𝑙) ∈
ℝ𝑁𝑙 for all 𝑙 = 1, … , 𝐿. Then 𝑦 is classified to the 𝑙-th
category if 𝑦 appears to be “more” sparse with respect to
𝐷 (𝑙) , namely,
(6)
‖𝑧 (𝑙) ‖0 = min {‖𝑧 (𝑚) ‖0 : 𝑚 = 1, … , 𝐿}
This means that 𝐷 (𝑙) is more capable to extract the key
features, or components of 𝑦 than other dictionaries.
3. EXPERIMENTS AND RESULTS
3.1. Data
The data used in the current work includes CT scans from
Sheba Medical Center, taken during the period from 2009 to
2014. Different CT scanners were used with 0.7090–1.1719
mm pixel spacing and 1.25–5 mm slice thickness. The scans
were selected and marked by a radiologist. They include 20
patients with 1-3 CT examinations per patient and overall
68 lesion segmentation masks. The data includes various
liver metastatic lesions derived from different primary
cancers.
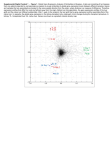
Fig. 3. Sample results: (a) Green: expert’s lesion mask;
(b) Red: Super-pixels classified by the alg. as lesion are
merged. Blue: liver boundary provided by expert; (c) Red:
super-pixels classified by the alg. as lesion. White: superpixels classified by the alg. as non-lesion (zoom in view).
3.2. Performance Evaluation
Two training methods for the dictionary construction were
tested: 1) The general dictionary construction (with 𝛽 = 0
and 𝛼 = 0); 2) LC-KSVD- the full method presented in
section 2.2. Three methods were also tested for the
classification task: 1) Linear classifier- using 𝑊, if it wasn’t
learned jointly than it was calculated based on the
initialization presented in [9]; 2) The most dominant atomusing equation (4) deciding the label based on the most
dominant dictionary atom, using 𝑙1 norm; 3) The more
sparse representation- using equation (6) deciding the label
based on the “more” sparse representation between both
dictionaries (lesion and no lesion) using 𝑙1 norm.
In the following we present the results obtained on a
superpixel level. We used accuracy (ACC) for performance
evaluation. A leave-one-patient-out cross validation was
used. Results are presented in Table 1. Best results (in bold)
were obtained using the LC-KSVD method with the linear
classifier learned during the discriminative dictionary
construction process.
Classify
Train
General
LC-KSVD
Linear
classifier
Most
dominant
atom
More sparse
representation
0.93
0.96
0.89
0.82
0.92
0.87
Table 1. Classification accuracy for sparsity based methods
1197
An interesting result is that the linear classifier performs
better than the two other methods mentioned here for
classification, even when 𝑊 is computed based on its
initialization value and not jointly learned in the dictionary
construction process. In contrary to the other classification
methods presented, the linear classifier gives a specific
weight to each atom in the dictionary targeted for
classification. We believe that this is the reason for the
improvement in performance.
For the following experiment the full LC-KSVD method
was used with dictionary size of 200 atoms and sparsity
threshold value of 20. These values were chosen after
parameters optimization on a subset of 6 patients randomly
chosen. We compared the classification results to Random
Forests (RF). The relevant parameters for this method were
also optimized. Table 2 shows that the LC-KSVD method
performed better than RF in its sensitivity and area under
ROC curves (AUC).
ACC
Sensitivity
Specificity
AUC
LCKSVD
0.96
0.71
0.98
0.95
RF
0.96
0.66
0.99
0.93
[3] X. Deng and G. Du, “Editorial: 3D segmentation in the clinic: a
grand challenge ii-liver tumor segmentation,” in MICCAI
Workshop, 2008.
[4] A. Shimizu et al., “Ensemble segmentation using AdaBoost
with application to liver lesion extraction from a CT volume,” in
Proc. Medical Imaging Computing Computer Assisted Intervention
Workshop on 3D Segmentation in the Clinic: A Grand Challenge
II, New York , 2008.
[5] M. Schwier, J. H. Moltz, and H.-O. Peitgen, “Object-based
analysis of CT images for automatic detection and segmentation of
hypodense liver lesions,” Int. J. Comput. Assist. Radiol. Surg., vol.
6, no. 6, pp. 737–747, 2011.
[6] L. Ruskó, and Á. Perényi. "Automated liver lesion detection in
CT images based on multi-level geometric features." International
journal of computer assisted radiology and surgery, vol. 9, no. 4,
pp. 577-593, 2014.
[7] M. Liu, L. Lu, X. Ye, S. Yu. & M. Salganicoff, "Sparse
classification for computer aided diagnosis using learned
dictionaries." Medical Image Computing and Computer-Assisted
Intervention–MICCAI 2011. Springer Berlin Heidelberg., pp. 4148, 2011.
[8] S. Zhang, J. Huang, D. Metaxas, W. Wang & X. Huang.
"Discriminative sparse representations for cervigram image
segmentation." Biomedical Imaging: From Nano to Macro, 2010
IEEE International Symposium on. IEEE, 2010.
Table 2. Comparison between LC-KSVD and RF
We also explored the performance in the lesion level. A
correct detection of a lesion was defined as one or more
super-pixels detected inside a lesion. A FP was defined as
every super-pixel wrongly classified as a lesion.
A
detection rate of 91% was achieved using this method
meaning that 62 out of 68 lesions were detected with a 0.9
FP rate. Fig. 3. shows an example of the algorithm results.
To conclude, we showed automated sparse based method for
super-pixels classification of liver metastases in CT
examinations. Several approaches of dictionary construction
were tested as well as state of the art sparse dictionary
classification techniques and general classification
techniques. The results indicate that the LC-KSVD [9]
together with its learned linear classifier provide the best
results. The detection rate and the classification results are
promising. Note that no significant pre-processing or postprocessing was implemented in the suggested method.
Adding these steps may increase lesion detection accuracy
and enable accurate segmentation as well. Future work
entails expanding to 3D analysis on larger datasets.
5. REFERENCES
[9] Z. Jiang, Z. Lin, and L.S. Davis. "Learning a discriminative
dictionary for sparse coding via label consistent K-SVD."
Computer Vision and Pattern Recognition (CVPR), 2011 IEEE
Conference on. IEEE, 2011.
[10] A. Taalimi, S. Ensafi, H. Qi, S. Lu, A.A. Kassim, and C. Lim
Tan. "Multimodal Dictionary Learning and Joint Sparse
Representation for HEp-2 Cell Classification." In Medical Image
Computing and Computer-Assisted Intervention—MICCAI 2015,
Springer International Publishing, pp. 308-315, 2015.
[11] R. Achanta, A. Shaji, K. Smith, A. Lucchi, P. Fua & S.
Süsstrunk, “Slic superpixels”. No. EPFL-REPORT-149300. 2010.
[12] R.M. Rangayyan, N.M. El-Faramawy, J.E. Desautels, O.A.
Alim. "Measures of acutance and shape for classification of breast
tumors." IEEE Trans. Med. Imaging, vol. 16, no. 6, pp. 799-810,
1997.
[13] M. Aharon, M. Elad, A. Bruckstein, Y. Katz, “K-SVD: An
Algorithm for Designing of Overcomplete Dictionaries for Sparse
Representation”. IEEE Transactions on Signal Processing, vol. 54,
pp. 4311-4322, 2006.
[14] J. Tropp, “Greed is good: Algorithmic results for sparse
approximation”. IEEE Trans. Inf. Theory, vol. 50, pp. 2231-42,
2004.
[1] “The World Health Report,” World Health Organization, 2014.
[2] K. D. Hopper, K. Singapuri, and A. Finkel, “Body CT and
oncologic imaging 1,” Radiology, vol. 215, no.1, pp. 27–40, 2000.
1198