Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Inductive probability wikipedia , lookup
Degrees of freedom (statistics) wikipedia , lookup
Foundations of statistics wikipedia , lookup
Secretary problem wikipedia , lookup
History of statistics wikipedia , lookup
Confidence interval wikipedia , lookup
Bootstrapping (statistics) wikipedia , lookup
Taylor's law wikipedia , lookup
Law of large numbers wikipedia , lookup
German tank problem wikipedia , lookup
Misuse of statistics wikipedia , lookup
Probability Theory
Review of essential concepts
Probability
P(A B) = P(A) + P(B) – P(A B)
0 ≤ P(A) ≤ 1
P(Ω)=1
Problem 1
Given that P(A)=0.6 and P(B)=0.7, which of
the following cannot be true?
P(A
P(A
P(A
P(A
P(A
B)
B)
B)
B)
B)
=
=
=
=
=
0.5
0.9
0.2
0.4
0.7
= or
= and
Conditional Probability
A and B are called independent if
P(A B) = P(A) * P(B)
P(A | B) = P(A B)/P(B)
P(A | B) = доля A в B
A and B are independent
P(A|B)=P(A)
Complete Probability
P(A) =
P(A|H1)P(H1) +
P(A|H2)P(H2) + …
P(A|Hn)P(Hn)
H1, H2, … Hn – complete disjoint system of events
H1
Hn
A
H2
Bayes Formula
P(B|A) - prior probability
P(A|B) – posterior probability
Problem 2
Suppose a certain drug test is 99% sensitive and
99% specific, that is, the test will correctly identify a
drug user as testing positive 99% of the time, and
will correctly identify a non-user as testing negative
98% of the time. Let's assume a corporation decides
to test its employees for opium use, and 0.5% of the
employees use the drug. What is the probability that,
given a positive drug test, an employee is actually a
drug user?
Problem 3
We are presented with three doors - red, green, and
blue - one of which has a prize. We choose the red
door, which is not opened until the presenter performs
an action. The presenter who knows what door the
prize is behind, and who must open a door, but is not
permitted to open the door we have picked or the door
with the prize, opens the blue door and reveals that
there is no prize behind it and subsequently asks if we
wish to change our mind about our initial selection of
red. What is the probability that the prize is behind
each of the green and red doors?
Random Variables
Discrete (Uniform, Binomial, Poisson,
Geometric, Hypergeometric, Negative
Binomial,…)
Continuous (Uniform, Normal, Exponential,
Gamma, Chi-square, Student, Fisher,
Dirchilet,…)
Discrete Distributions
Poisson
Continuous Distributions
Beta distribution
Binomial Distribution
Binomial random number = the number of
successes in n independent trials; p=probability
of success in one trial
0.6
0.35
0.5
0.3
0.3
0.25
0.25
0.4
0.35
0.2
0.2
0.15
0.15
0.3
0.2
0.1
0.1
0.1
0.05
0.05
0
0
0
1
2
3
p=0.1
4
5
6
0
0
1
2
3
p=0.3
4
5
6
0
1
2
3
p=0.5
4
5
6
Problem 4
The probability that a certain machine will
produce a defective item is 0.20. If a random
sample of 6 items is taken from the output of
this machine, what is the probability that
there will be 5 or more defectives in the
sample?
Problem 5
There are 10 patients on the Neo-Natal Ward of
a local hospital who are monitored by 2 staff
members. If the probability (at any one time) of a
patient requiring emergency attention by a staff
member is 0.3, assuming the patients to be
behave independently, what is the probability at
any one time that there will not be sufficient staff
to attend all emergencies?
Cumulative Probability
X = random variable
F(x) = P(X ≤ x)
Most of the data
analysis tools
have a built-in
function
for the cumulative
binomial
probability
Poisson Distribution
Poisson random number = the number of
rare events per unit of time or space
0.4
0.2
0.35
0.18
0.16
0.3
0.14
0.25
0.12
0.2
0.1
0.15
0.08
0.06
0.1
0.04
0.05
0.02
0
0
0
1
2
3
4
5
6
7
λ=1.5
8
9
10
11
12
13
0
1
2
3
4
5
6
λ=5
7
8
9
10
11
12
13
Problem 6
The marketing manager of a company has
noted that she usually receives 10 complaint
calls during a week (consisting of five working
days), and that the calls occur at random. Find
the probability that she gets five such calls in
one day.
Problem 7
The rate at which a particular defect occurs in
lengths of plastic film being produced by a stable
manufacturing process is 4.2 defects per 75 meter
length. A random sample of the film is selected and
it was found that the length of the film in the
sample was 25 meters. What is the probability that
there will be at most 2 defects found in the
sample?
Normal Distribution
Cumulative Probability
Standard Normal Distribution
Other Normal Distributions
Z = N(0,1)
X = N(μ, σ)
Mean = 0
Variance = 1
Mean = μ
Variance = σ2
Z = (X- μ)/σ
Problem 8
The diameters of steel disks produced in a plant are
normally distributed with a mean of 2.5 cm and
standard deviation of 0.02 cm. What is the probability
that a disk picked at random has a diameter greater
than 2.54 cm?
Problem 9
The height of an adult male is known to be normally
distributed with a mean of 69 inches and a standard
deviation of 2.5 inches. What is the height of the
doorway such that 96 percent of the adult males can
pass through it without having to bend?
Problem 10
The longevity of people living in a certain locality has
a standard deviation of 14 years. What is the mean
longevity if 30% of the people live longer than 75
years? Assume a normal distribution for life spans.
Normal Approximation to Binomial
X = Binom(n,p)
n = number of trials
p = probability of a single success
X = N(μ, σ)
μ = np
σ2 = np(1-p)
n>40
np>5
n(1-p)>5
Problem 11
The unemployment rate in a certain city is
8.5% . A random sample of 100 people from
the labor force is drawn. Find the approximate
probability that the sample contains at least
ten unemployed people.
Continuity correction
Normal approximation is still an approximation
Problem 12
Companies are interested in the demographics
of those who listen to the radio programs they
sponsor. A radio station has determined that
only 20% of listeners phoning in to a morning
talk program are male. During a particular
week, 200 calls are received by this program.
What is the approximate probability that at least
50 of the callers are male?
Poisson Approximation to Bionomial
X = Binom(n,p)
n = number of trials
p = probability of a single success
X = Poisson(λ)
λ = np
n→∞
p→0
np=λ=const
Problem 13
A certain genetic characteristic will
express itself in 0.001 of the population.
In a sample of n=3000 subjects, k=7 are
observed to display the characteristic,
whereas only three are expected to
display the characteristic. How likely is it
that a rate this great or greater could
occur by mere chance?
Expected Value
x
x1
x2
…
…
xn
p
p1
p2
…
…
pn
E(X) = Σ xi pi = not a random number
x
0
1
y
0
1
X+Y
0
1
2
P
1/2
1/2
P
1/3
2/3
P
1/6
1/2
1/3
E(X) =0*1/2+1*1/2=1/2
E(Y) =0*1/3+1*2/3=2/3
E(X+Y) =1*1/2+2*1/3=
= E(X)+E(Y)
X and Y are independent X=a and Y=b are independent events
Variance
Var(X) = E[ (X-E(X))2 ] = E(X2)-(E (X))2
x
0
1
x-E(X)
-2/3
1/3
(x-E(X))2
4/9
1/9
p
1/3
2/3
p
1/3
2/3
p
1/3
2/3
E(X)=2/3
E(X-E(X)) =-2/9+2/9 = 0
x2
0
1
P
1/3
2/3
E(X2)=2/3
Var(X)=4/9*1/3+1/9*2/3=2/9
Var(X)=E(X2)-E2(X)=2/3 – 4/9 = 2/9
Expected Value and Variance
X = random variable
E(X+Y) = E(X) + E(Y)
E(cX) = cE(X)
E(c) = c
If X and Y are independent then E(XY) = E(X)E(Y)
Var(X)=E(X2)-E2(X)
Var(cX)=c2Var(X)
If X and Y are independent then Var(X+Y) = Var(X)+Var(Y)
For arbitrary X and Y, Var(X+Y) = Var(X) + Var(Y) + 2Cov(X,Y)
Exercises
Using properties of E(X) prove that
Var(X) = E[ (X-E(X))2 ] = E(X2)-(E (X))2
Var(X+Y) = Var(X) + Var(Y) + 2Cov(X,Y)
where:
Cov(X,Y)=E[ (X-E(X))*(Y-E(Y)) ]
Cov(X,Y)=E(XY) - E(X)*E(Y)
Find X and Y such that X and Y are
dependent but Cov(X,Y)=0
Problem 14
The Attila Barbell Company makes bars for weight lifting. The
weights of the bars are independent and are normally
distributed with a mean of 720 ounces (45 pounds) and a
standard deviation of 4 ounces. The bars are shipped 10 in a
box to the retailers. The weights of the empty boxes are
normally distributed with a mean of 320 ounces and a standard
deviation of 8 ounces. The weights of the boxes filled with 10
bars are expected to be normally distributed with a mean of
7,520 ounces. What is the standard deviation?
Statistics
Part I: Sampling distribution
Sampling Distribution
Sample X1, X2, … , Xn
Xi are random numbers
Population = heights of adult males
X1
X2
X3
176 181 190
181 190 176
190 176 181
…
…
…
All Xi are:
from the same distribution
are independent
Sample Mean
X 1 X 2 ... X n
X
n
All Xi are:
from the same distribution, i.e,
E(Xi)=μ, Var(Xi) = σ2
are independent random numbers
X X 1 ... X n
E ( X ) E 1
n
1
1
E ( X 1 ) E ( X 2 ) ... E ( X n )
...
n
n
n times
The Law of Large Numbers
X 1 X 2 ... X n
n
X
X X 1 ... X n
Var ( X ) Var 1
n
2
1
1 2
2
2
2 Var ( X 1 ) Var ( X 2 ) ... Var ( X n ) 2
...
n
n
n
n times
Var ( X ) Var ( X ) / n
(X )
(X )
n
Illustrative example
Population = {1,2,3}, sample size n=2
X1
X2
X
1
1
1
1
2
1.5
1
3
2
2
1
1.5
2
2
2
2
3
2.5
3
1
2
3
2
2.5
3
3
3
3.5
3
2.5
2
1.5
1
0.5
0
1
2
3
3.5
3
2.5
2
1.5
1
0.5
0
1
1.5
2
2.5
3
Central Limit Theorem
The sum of a sufficiently large number of
identically distributed independent random
variables is approximately normally
distributed regardless of the population
distribution
Normal Approximation to Binomial
X = number of
successes in n trials
X=X1+X2+…+Xn
0, if no success
Xi
1, if success
E ( X ) np
( X ) np (1 p)
Problem 18
There are two games involving flipping a coin. In
the first game you win a prize if you can throw
between 45% and 55% of heads. In the second
game you win if you can throw more than 80%
heads. For each game would you rather flip the coin
30 times or 300 times?
Sampling distribution
X is approximately normal when n>40
X is approximately normal
regardless of the original distribution
Problem 15
The average outstanding bill for delinquent customer
accounts for a national department store chain is
$187.50 with a standard deviation of $54.50. In a
simple random sample of 50 delinquent accounts,
what is the probability that the mean outstanding bill
is over $200?
Problem 16
The average number of daily emergency room
admissions at a hospital is 85 with standard
deviation of 37. In a simple random sample of 30
days, what is the probability that the mean
number of daily emergency admissions is
between 75 and 95?
Problem 17
A summer resort rents rowboats to customers but does not
allow more than four people to a boat. Each boat is designed
to hold no more than 800 pounds. Suppose the distribution
of adult males who rent boats, including their clothes and
gear, is normal with a mean of 190 pounds and standard
deviation of 10 pounds. If the weights of individual
passengers are independent, what is the probability that a
group of four adult male passengers will exceed the
acceptable weight limit of 800 pounds?
Statistics
Part II: Hypothesis testing
Hypothesis testing
H0 – null hypothesis
HA – alternative hypothesis
In a court:
H0: the person is not guilty
HA: the person is guilty
Doctor’s appointment:
H0: patient is sick
HA: patient is not sick
Type I/II error
Type I error (α)
It is the error of rejecting a null
hypothesis when it is actually true.
Type II error (β)
It is the error of failing to reject a null
hypothesis when it is in fact false.
Decision rule
Assume we get many samples
We set up a decision rule which rejects or accepts the hull
hypothesis for each sample
Sometimes we will commit Type I error
Sometimes we will commit Type II error
(Of course many times we will be correct!)
Decision rule comes separately
from the set of hypotheses
Type I/II error
Actual condition
Infected
Not infected
Test shows
"infected"
True Positive
False Positive (i.e. infection
reported but not present)
Type I error
Test shows
"not infected"
False Negative (i.e.
infection not detected)
Type II error
True Negative
Problem 19
A patient claims that he consumes only 2000 calories
per day, but a dietician suspects that the actual figure
is higher. The dietician plans to check his food intake
for 30 days and will reject the patient's claim if the
30-day-mean is more than 2100 calories. If the
standard deviation (in calories per day) is 350, what
is the probability that the dietician will mistakenly
reject a patient's true claim?
Problem 20
City planners wish to test the claim that shoppers park for
an average of only 47 minutes in the downtown area. The
planners have decided to tabulate parking durations for
225 shoppers and to reject the claim if the sample mean
exceeds 50 minutes. If the claim is wrong and the true
mean is 51 minutes, what is the probability that the
random sample will lead to a mistaken failure to reject the
claim? Assume that the standard deviation in parking
durations is 27 minutes.
P-value
P-value is the probability of obtaining a result
at least as extreme as the one that was
actually observed, given that the null
hypothesis is true.
Если бы то, что мы предполагаем в
нулевой гипотезе было верно, то какова
была бы вероятность видеть то, что мы
видим в выборке (это, или еще «хуже»)
Hypothesis testing
P-value is a function of sample
α is a function of decision rule
Reject H0 if p-value< α
Small p-value indicates that you see
something very unusual if H0 were true
Problem 21
A service station advertises that its mechanics can
change a muffler in only 15 minutes. A consumers
group doubts this claim and runs a hypothesis test
using 49 cars needing new mufflers. In this sample
the mean changing time is 16.25 minutes with a
standard deviation of 3.5 minutes. Is this a strong
evidence against the 15 minute claim?
Estimators
An estimator is a function of the
observable sample data that is used to
estimate an unknown population
parameter
is an estimator for μ
s is an estimator for σ
p̂ is an estimator for p
X
Unbiased effective estimators
Let be the unknown parameter
Let ˆn be an estimator
ˆn is unbiased if E (ˆn )
ˆn is effective if lim Var (ˆn ) 0
n
Unbiased vs. effective
Unbiased but ineffective
Effective but biased
We are looking for unbiased and effective estimators
Mean Squared Error
Bias:
bias (ˆn ) E(ˆn )
Variance:
2
ˆ
ˆ
ˆ
Var ( n ) E n E ( n )
Mean Squared Error
2
ˆ
ˆ
ˆ
MSE ( n ) Var( n ) bias ( n )
Problem ?
A box contains 70 black and 30 white balls. Ten balls
are chosen at random and two estimators of the
following form are considered
# of black balls
n
# of black balls 2
pˆ 2
n2
pˆ 1
where n=10. Which estimator is more effective? (i.e.,
has a smaller MSE?)
Standard error
Standard error = standard deviation of
the estimator
SE ( X )
SE ( pˆ )
n
p(1 p)
n
Problem 22
A local restaurant owner claims that only 15% of
visiting tourists stay for more than 2 days. A chamber
of commerce volunteer is sure that the real
percentage is higher. He plans to survey 100 tourists
and intends to speak up if at least 18 of the tourists
stay longer than 2 days. What is the probability of
mistakenly rejecting the restaurant owner's claim if it
is true?
Two-sample mean
Two independent samples, X1,…, Xn and
Y1,…,Ym have independent sample means
SE ( X Y )
X2
n
Y2
m
1
1
SE ( X Y )
if X Y
n m
Two-sample proportion
Two independent sample proportions
SE ( pˆ 1 pˆ 2 )
p1 (1 p1 ) p2 (1 p2 )
n
m
SE ( pˆ 1 pˆ 2 )
1 1
p(1 p )
if p1 p2
n m
Problem 23
A historian believes that the average height of
soldiers in World War II was greater than that of
soldiers in World War I. She examines a random
sample of records of 100 men in each war and
notes standard deviations of 2.5 and 2.3 inches in
World War I and World War II, respectively. If the
average height from the sample of World War II
soldiers is 1 inch greater than that from the
sample of World War I soldiers, what conclusion is
justified from a two-sample hypothesis test where
H0: μ1 = μ2 vs. HA: μ1< μ2?
Confidence intervals
Hypothesis testing: A coffee machine is supposed to
deliver 8 ounces of coffee in a cup, but in my sample
of 10 cups I get only 7.5 ounces. Is this ok?
Confidence intervals: My sample of 10 cups of coffee
contains on average 7.5 ounces of liquid. What is the
likely estimate for the mean amount of coffee per cup?
Hypothesis testing and construction of confidence
intervals are mutually inverse problems
Confidence intervals
Parameter = Estimate ± critical * SE,
SE = standard error
X Z / 2 SE ,
p pˆ Z / 2 SE ,
SE
SE
n
p(1 p )
n
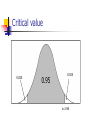
Critical value
0.025
0.95
0.025
z=1.96
Problem 19 revisited
A patient claims that he consumes only 2000 calories
per day, but a dietician suspects that the actual figure
is higher. The dietician checked his food intake for 30
days and found that the 30-day-mean is more than
2100 calories. What is the 95% confidence interval
for the number of calories in patient’s diet?
Assume standard deviation of 350 calories per day.
Problem 22 revisited
A chamber of commerce volunteer is interested in
the percentage of visiting tourists staying for more
than 2 days in a certain hotel. He surveyed 100
tourists and found that 18 of them stay longer than
2 days. What is the 99% confidence interval for the
percentage of visiting tourists who stay for more
than 2 days?
Problem 24
In a random sample of 300 high school students, 225
said they managed time effectively, while in a similar
sample of 270 college students, only 108 felt they
were effective time managers. What is a 99%
confidence interval estimate for the difference
between the proportions of high school and colleges
students who think they manage time effectively?
Problem 25
A medical researcher believes that taking 1000
milligrams of vitamin C per day will result in fewer
colds than a daily intake of 500 milligrams will. In a
group of 50 volunteers taking 1000 milligrams per day,
the numbers of colds per individual during a winter
season averaged 1.8 with a variance of 1.5. Similar
data from a group of 60 volunteers taking 500
milligrams per day showed an average of 2.4 with a
variance of 1.6. What was the P-value of this test?
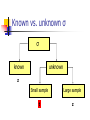
How do we get σ?
Population standard deviation is usually unknown
If sample size is large (n>40) then we can assume
that the sample standard deviation (s) approximates
the population standard deviation (σ) well enough
If sample size is small then this assumption is no
longer valid, i.e., sampling error in the estimation of
σ cannot be ignored
Known vs. unknown σ
σ
known
unknown
z
Small sample
Large sample
t
z
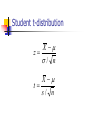
Student t-distribution
X
z
/ n
X
t
s/ n
Student t-distribution
Student t-distribution has one parameter called
degrees of freedom
When the number of degrees of freedom is
large, the t-distribution is close to z-distribution
t-distribution table
Degrees of freedom = sample size - 1
Problem 26
An article ("Undergraduate Marijuana use and Anger"
by Sue Stoner) in a 1988 issue of the Journal of
Psychology (Vol. 122, p. 33) reported that in a
sample of 17 marijuana users the mean and standard
deviation on an anger expression scale were 42.72
and 6.05, respectively. Test whether this result is
significantly greater than the established mean of
41.6 for nonusers. What assumptions are necessary
for the above test to be valid?
T-test assumptions
Random sampling (like in z-test)
Normal population (unlike z-test, where sample mean
is automatically normal regardless of the population
when sample size is large)
Degrees of freedom = number of independent
observations (actually, residuals)
Problem 27
A hospital exercise laboratory technician notes the
resting pulse rates of five joggers to be 60, 58, 59,
61, and 67, respectively, while the resting pulse rates
of seven non-exercisers are 83, 60, 75, 71, 91, 82,
and 84, respectively. Establish a 99% confidence
interval estimate for the difference in pulse rates
between joggers and non-exercisers.
(Means and standard deviations are: 61, 78, 3.54, and 10.23, respectively)
Equal variances assumption
Assume that both populations have the same
standard deviation (i.e., amount of exercise affects
mean of the population, not its standard deviation)
SE ( X Y )
X2
n
Y2
m
1
1
SE ( X Y )
if X Y
n m
ˆ s p
d.f. = min{n,m}-1
(n 1) sx2 (m 1) s y2
nm2
d.f. = n + m - 2
Problem 27 revisited
A hospital exercise laboratory technician notes the
resting pulse rates of five joggers to be 60, 58, 59,
61, and 67, respectively, while the resting pulse rates
of seven non-exercisers are 83, 60, 75, 71, 91, 82,
and 84, respectively. Establish a 99% confidence
interval estimate for the difference in pulse rates
between joggers and non-exercisers. Assume equal
variances.
(Means and standard deviations are: 61, 78, 3.54, and 10.23, respectively)
Problem 28
A researcher believes a new diet should improve
weight gain in laboratory mice. If ten control mice on
the old diet gain an average of 4 ounces with a
standard deviation of 0.3 ounces, while the average
gain for the ten mice on the new diet is 4.8 ounces
with a standard deviation of 0.2 ounces, what is the
p-value?
Dependent samples
Trace metals in drinking water wells affect the flavor of the
water and unusually high concentrations can pose a health
hazard. In the paper, “Trace Metals of South Indian River
Region” (Environmental Studies, 1982, 62-6), trace metal
concentrations (mg/L) on zinc were found from water drawn
from the bottom and the top of each of 6 wells.
Location
Bottom
Top
1
0.43
0.415
2
0.266
0.238
3
0.567
0.39
4
0.531
0.41
5
0.707
0.605
6
0.716
0.609
Dependent samples
Location
Bottom
Top
1
0.43
0.415
0.015
2
0.266
0.238
0.028
3
0.567
0.39
0.177
4
0.531
0.41
0.121
5
0.707
0.605
0.102
6
0.716
0.609
0.107
Mean
0.0916667
SD
0.0606883
One sample t-test
Bottom-Top
FAQs
Do I have to divide by square root of n?
Do I have to divide by square root of n in oneproportion or two-proportion tests?
Yes, if you are looking for P(X>100)
No, if you are looking for P(X>100)
No. If you use Standard Error, it already contains the square
root of n
When I compute standard deviation from the sample,
do I have to divide it by square root of n?
Yes, if your calculations involve sample mean.
Common misconception
Sample standard deviation is an estimator for
the population standard deviation
Standard deviation of the sampling
distribution is smaller than the population
standard deviation
Sample standard deviation is NOT an
estimator for the standard deviation of the
sampling distribution
Estimation of σ
z
t n 1
X
/ n
X
s/ n
n21
s 2 (n 1)
2
Chi-square table
Problem 29
A supplier of 100 ohm/cm silicon wafers claims that
his fabrication process can produce wafers with
sufficient consistency so that the standard deviation
of resistance for the lot does not exceed 10 ohm/cm.
A sample of 10 wafers taken from the lot has a
standard deviation of 13.97 ohm/cm. Is the suppliers
claim reasonable?
Problem 30
A container of oil is supposed to contain 1000 ml of
oil. We want to be sure that the standard deviation of
the oil container is less than 20 ml. We randomly
select 10 cans of oil with a mean of 997 ml and a
standard deviation of 32 ml. Using these sample
construct a 95% confidence interval for the true
value of sigma. Does the confidence interval suggest
that the variation in oil containers is at an acceptable
level?
Estimation of sample size
What is a minimum sample size needed to
estimate the population mean within 2 units?
What is a minimum sample size needed to
estimate the population proportion within 2
percent units?
Problem 31
An electrical firm which manufactures a certain type
of bulb wants to estimate its mean life. Assuming
that the life of the light bulb is normally distributed
and that the standard deviation is known to be 40
hours, how many bulbs should be tested so that we
can be 90 percent confident that the estimate of the
mean will not differ from the true mean life by more
than 10 hours?
Problem 32
A quality control engineer wants to estimate the
fraction of defective bulbs in a large lot of light bulbs.
From past experience, he feels that the actual
fraction of defective bulbs should be somewhere
around 0.2 . How large a sample should be taken if
he wants to estimate the true fraction within .02
using a 95% confidence interval?
Problem 33
Many television viewers express doubts about the
validity of certain commercials. Let p represent the
true proportion of consumers who believe what is
shown in Timex television commercials. If Timex has
no prior information regarding the true value of p,
how many consumers should be included in their
sample so that they will be 85% confident that their
estimate is within 0.03 of the true value of p?
Statistics
Part III: Contingency tables
Non-parametric hypotheses
H0: features are independent
HA: features are dependent
A restaurant owner surveys a random sample of 385 customers to
determine whether customer satisfaction is related to gender and
age.
Young
male
Young
female
Older
male
Older
Female
Satisfied
25
30
135
112
Not
satisfied
8
16
22
37
Assumption of independence
Young
male
Young
female
Older
male
Older
Female
TOTAL
Satisfied
25
30
135
112
302
Not
satisfied
8
16
22
37
83
TOTAL
33
46
157
149
385
If gender/age and satisfaction were independent then
P(satisfied and young male) = P(satisfied)*P(young male)
P(satisfied) = 302/385
P(young male) = 33/385
P(satisfied and young male) = 302*33/3852
Expected number of satisfied young males = 302*33/385
Observed and Expected
Observed
Young male
Young female
Older male
Older Female
TOTAL
25
30
135
112
302
8
16
22
37
83
33
46
157
149
385
TOTAL
Satisfied
Not satisfied
TOTAL
Expected
Satisfied
Not satisfied
TOTAL
Young male
Young female
Older male
Older Female
25.9
36.1
123.1
116.9
302
7.1
9.9
33.9
32.1
83
33
46
157
149
385
Chi-square test for independence
2
(
O
E
)
2
E
(25 25.9) 2 (30 36.1) 2
2
... 11.1
25.9
36.1
d.f. = (n-1)x(m-1)
Problem 34
A sociologist conducts a test whether there is a
relationship between cheating on exams and
socioeconomic status. A random sample of 750 high
school students yields the following results:
Cheat
Don't cheat
High status
118
282
Low status
82
268
What is the conclusion about cheating and
socioeconomic status at the 5% significance level?
Chi-square goodness of fit
A grocery store manager wishes to determine
whether a certain product will sell equally well in any
of the five locations in the store. Five displays are set
up, one for each location, and the resulting numbers
of the product sold are noted
# sold
1
2
3
4
5
43
29
52
34
48
Is there enough evidence to claim a difference?
Chi-square goodness of fit
# sold
1
2
3
4
5
43
29
52
34
48
Total = 43+29+…+48=206
We expect 206/5=41.2 units sold in each location
H0: The distribution is uniform
HA: The distribution is not uniform
(O E ) 2 (43 41.2) 2
(48 41.2) 2
...
8.9
E
41.2
41.2
2
d.f. = n-1
Problem 35
A geneticist claims that four species of fruit flies
should appear in the ratio of 1:3:3:9. Suppose that a
sample of 4000 fruit flies contained 226, 764, 733,
and 2277 flies of each species, respectively. At the
10% significance level, is there sufficient evidence to
reject the geneticist’s hypothesis?
Chi-square test: warning
Chi-square test is applicable only if the
expected value in each cell is greater than 5
(Compare to Binomial Distribution)
If this doesn’t hold, you might find Fisher
exact test more useful
Problem 36
A sample of teenagers might be divided into male and female
on the one hand, and those that are and are not currently
dieting on the other. We hypothesize, perhaps, that the
proportion of dieting individuals is higher among the women
than among the men, and we want to test whether any
difference of proportions that we observe is significant.
men women total
dieting
1
9
10
not dieting 11
3
14
totals
12
24
12
Expected < 5
Fisher exact test
men women total
men
women total
1
9
10
dieting
a
b
a+b
not dieting 11
3
14
not dieting c
d
c+d
totals
12
24
totals
b+d n
dieting
12
Hypergeometric Distribution
a+c
Statistics
Part IV: Regression and ANOVA
The least squares line
A simple data set consists of data pairs
(xi, yi), i = 1, ..., n,
where xi is an independent variable and yi is a
dependent variable
The model function has the form
y = a + bx
We wish to find a and b for which the model "best"
fits the data.
Residuals
The least squares method defines "best" as
when S = Σ ri2 is at minimum.
A residual ri is defined as the difference
between the values of the dependent variable
and the predicted values from the estimated
model
ri =yi - (a + b xi)
Regression Line
Residuals are
shown by blue lines
Sum of squares of
the residuals is at
minimum
Residual plot
The sum of the residuals is always zero
A pattern in the residual plot indicates that a non-linear model should
be used
Influential scores and outliers
In regression, an outlier is a data point with large
residual
An influential score is the data point which
significantly influences the regression line
If an influential score is removed from the sample,
the regression line will change significantly
Problem 37
Which of the five points is an outlier, and
which is an influential score?
Solving the regression
Regression slope and intercept
( x x )( y y ) s
b
s
(x x)
i
i
xy
2
i
,
xx
where
1
( xi x )( yi y )
n 1
1
s xx
( xi x )( xi x )
n 1
s xy
a y bx
Correlation Coefficient
The correlation
coefficient
indicates the
degree of linear
dependence
Correlation and slope
r
s xy
s xx s yy
s xy
sx s y
r
1
s xy
( xi x )( yi y )
n 1
br
sy
sx
b b* r 2
Coefficient of determination
SSX
R r
SST
2
2
SST = total sum of squares
SSX = sum of squares explained by X
SSE = sum of squares of residuals
SST = SSX+SSE
The square of the sample correlation coefficient, which is also
known as the coefficient of determination, is the fraction of
the variance in y that is accounted for by a linear fit of x
Sums of squares
2
ˆ
ˆ
(n 1) s (Yi Y ) (Yi Yi Y Y )
2
Y
2
2
2
ˆ
ˆ
(Yi Yi ) (Y Y ) crossprodu ct term
SSX SSE
Yi
red
Yˆi
blue
SE of the regression slope
b
e2
N
(X
i 1
i
X )2
The regression line is a result of random sampling
Different samples produce different lines
There is a family of lines for the given population; you get just one
SE of the regression slope
b
e2
where σe is the standard deviation
of the regression error
N
2
(
X
X
)
i
i 1
̂ e
̂ b
SSE
MSE
n2
MSE
N
(X
i 1
i
X )2
Problem 38
1. What is the equation of the fitted line?
2. Find an approximate confidence interval for the regression slope?
3. Test the hypothesis that the slope is non-zero
Problem 39
Find the regression line and a 95% confidence interval for the regression slope.
Confidence vs. prediction intervals
Suppose I fuel my car 7 days a week, from Sunday to Sunday,
each day at a randomly chosen gas station. I get a sample of
gasoline prices for 7 days:
Confidence interval is for the average gasoline price on Monday
Prediction interval is for a gasoline price at a randomly chosen
gas station on Monday
Confidence vs. prediction intervals
Confidence interval
Yˆ0 X 0 (a bX 0 ) t n 2ˆ e
( X 0 X )2
1
n ( X i X )2
Prediction interval
Yˆ0 X 0 (a bX 0 ) t n 2ˆ e
( X 0 X )2
1
1
2
n (Xi X )
Problem 39 revisited
Find the a 95% prediction interval for the dive duration at 25 degrees Celsius
ANOVA: Analysis of Variance
A collection of models, in which the variance
of the observed set is partitioned into
components due to explanatory variables
Assumptions:
Independence of observations
The distributions in each of the groups are normal
Variance homogeneity, called homoscedasticity:
the variance of data in groups should be the
same.
One-way ANOVA
A manager wishes to determine whether the mean times
required to complete a certain task differ for the three levels of
employee training. He randomly selected 10 employees with
each of the three levels of training.
Level of Training
n
s2
Advanced
10 24.2
21.54
Intermediate
10 27.1
18.64
Beginner
10 30.2
17.76
Do the data provide sufficient evidence to indicate that the
mean times required to complete a certain task differ for at
least two of the three levels of training?
Steiner’s Theorem
xi
a
n
I ( x1 ,..., xn , a) ( xi a) 2
i 1
Момент инерции системы точек
относительно точки а
I ( x1 ,..., xn , a) I ( x1 ,..., xn , x ) n( x a)
2
Problem 40
Three different milling machines were being considered for purchase
by a manufacturer. Potentially, the company would be purchasing
hundreds of these machines, so it wanted to make sure it made the
best decision. Initially, five of each machine were borrowed, and each
was randomly assigned to one of 15 technicians (all technicians were
similar in skill). Each machine was put through a series of tasks and
rated using a standardized test. The higher the score on the test, the
better the performance of the machine. The data are:
Machine 1
Machine 2
Machine 3
24.5
28.4
26.1
23.5
34.2
28.3
26.4
29.5
24.3
27.1
32.2
26.2
29.9
30.1
27.8
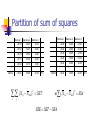
Partition of sum of squares
SST = SSA + SSE
SST = total sum of squares
SSA = sum of squares for factor A
SSE = sum of squares of errors
2
2
SST ( X ij X ) ( X ij X i ) m( X i X )
i 1 i 1
i j
( X ij X i ) 2 m ( X i X ) 2 SSE SSA
n
m
2
i
j
i
Partition of sum of squares
Machine 1
Machine 2
Machine 3
Machine 1
Machine 2
Machine 3
24.50
28.40
26.10
26.28
30.88
26.54
23.50
34.20
28.30
26.28
30.88
26.54
26.40
29.50
24.30
26.28
30.88
26.54
27.10
32.20
26.20
26.28
30.88
26.54
29.90
30.10
27.80
26.28
30.88
26.54
26.28
30.88
26.54
26.28
30.88
26.54
MEAN
27.9
2
(
X
X
)
ij SST
i
MEAN
27.9
m ( X i X ) 2 SSA
j
SSE SST SSA
i
The ANOVA table
SSA = Sum of squares Factor
SSE = Sum of squares Error
SS
df
MS
F
Factor
SSA
k-1
SSA/(k-1)
MSA/MSE
Error
SSE
N-k
SSE/(N-k)
.
Total
SSA+SSE
N-1
.
MSA = Mean sum of squares Factor
MSE = Mean sum of squares Error
Fisher distribution
m
F (n, m)
n
2
n
2
m
Problem 40 solution
ANOVA
Source of Variation
SS
df
Between Groups
66.772
2
33.386
Within Groups
56.128 12
4.677333
Total
MS
F
P-value
F crit
7.137828
0.009073
3.885294
122.9 14
In EXCEL: Tools -> Data Analysis -> Single Factor ANOVA
Two-way ANOVA
Group A is given vodka, Group B is given gin, and Group C is
given a placebo. Groups are tested with a memory task. Oneway ANOVA
In an experiment testing the effects of expectations, subjects
are randomly assigned to four groups:
1.
expect vodka—receive vodka
2.
expect vodka—receive placebo
3.
expect placebo—receive vodka
4.
expect placebo—receive placebo
Each group is then tested on a memory task. Two-way
ANOVA
Partition of sum of squares
SST = SSA + SSB + SSE
SST = total sum of squares
SSA = sum of squares for factor A
SSB = sum of squares for factor B
SSE = sum of squares of errors
Partition of sum of squares
2
2
SST ( X ij X ) ( X ij X i ) m( X i X )
i 1 i 1
i j
( X ij X i ) 2 m ( X i X ) 2
n
m
2
i
j
i
( X ij X i X j X ) 2 n ( X j X ) 2 m ( X i X ) 2
i
j
j
SSE SSA SSB
i
Problem 41
Three different milling machines were being considered for purchase
by a manufacturer…. Machines are operated by 5 different crew
technicians:
Machine 1
Machine 2
Machine 3
Crew 1
24.5
28.4
26.1
Crew 2
23.5
34.2
28.3
Crew 3
26.4
29.5
24.3
Crew 4
27.1
32.2
26.2
Crew 5
29.9
30.1
27.8
What is the error term?
MEAN
MEAN
MEAN
24.5
28.4
26.1
26.33333
24.7133
29.3133
…
26.33
23.5
34.2
28.3
28.66667
27.0467
…
…
28.67
26.4
29.5
24.3
26.73333
…
…
…
26.73
27.1
32.2
26.2
28.5
…
28.5
29.9
30.1
27.8
29.26667
26.28
30.88
26.54
27.9
X ij 24.5
MEAN
…
…
…
29.27
26.28
30.88
26.54
27.9
X i X j X 24.7133
Two-way ANOVA table
Source of Variation
SS
df
MS
F
P-value
F crit
19.89333333
4
4.973333333
1.098027671
0.419936
3.837853
66.772
2
33.386
7.371062702
0.015312
4.45897
Error
36.23466667
8
4.529333333
Total
122.9
14
Rows
Columns
At 5% level:
• The variation across rows (crew technicians) is NOT significant
• The variation across columns (machines) is significant
Problem 42
Some varieties of nematodes feed on the roots of lawn
grasses and crops such as strawberries and tomatoes.
Four brands of nematocides are to be compared. Twelve
plots of land of comparable fertility that were suffering
from nematodes were planted with a crop. The yields of
each plot were recorded and part of the ANOVA table
appears below:
Source
df
SS
Nematocides
*
3.456
*
Error
8
1.2
*
Total
11 4.656
Find the value of F
MS F-value
*
THE END
Extra Problems
All bags entering a research facility are screened.
Ninety-seven percent of the bags that contain
forbidden material trigger an alarm. Fifteen percent
of the bags that do not contain forbidden material
also trigger the alarm. If 1 out of every 1,000 bags
entering the building contains forbidden material,
what is the probability that a bag that triggers the
alarm will actually contain forbidden material?
Extra problems
Pepper plants watered lightly every day for a month
show an average growth of 27 cm with the standard
deviation of 8.3 cm, while pepper plants watered
heavily once a week for a month show an average
growth of 29 cm with the standard deviation of 7.9
cm. In a sample of 60 plants, half of which were
given each of the water treatments, what is the
probability that the difference in average growth
between the two halves is between -3 and + 3 cm?