Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Unix security wikipedia , lookup
Copland (operating system) wikipedia , lookup
Distributed operating system wikipedia , lookup
Spring (operating system) wikipedia , lookup
Security-focused operating system wikipedia , lookup
Burroughs MCP wikipedia , lookup
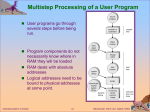
Process Scheduling
CPU scheduling: user and kernel tasks, kernel task can be in
process context and interrupt context
SMP (each run queue)
Affinity (cache)
Load balancing
As of 2.5, new scheduling algorithm – preemptive, priority-based
Real-time range: 0-99
nice value: 100-139 (-20 to 19) (dynamic)
Normal tasks: priority and timeslice recalculated when timeslice
exhausted before moving to expired array
Scheduling algorithm run in constant time O(1) regardless of
number of tasks
Operating System Concepts
FIFO and RR (static)
21.1
Silberschatz, Galvin and Gagne ©2005
List of Tasks Indexed by Priority
Operating System Concepts
21.2
Silberschatz, Galvin and Gagne ©2005
LINUX Process Scheduling
Linux uses two process-scheduling algorithms:
time-sharing (dynamic): 100-139 (19 to -20)
real-time algorithm(FIFO/RR) with absolute priorities (static): 0-99
FIFO run till Exit or Block, RR run with time slice
For time-sharing tasks
Initial base priority based on nice value (-20 to 19 with default 0)
High priority with longer timeslices
I/O bound: elevated dynamic priority, processor bound with lower
dynamic priority (sleepavg value)
Operating System Concepts
21.3
Silberschatz, Galvin and Gagne ©2005
Process Scheduling (Cont.)
Process Timeslices
Low priority (less interactive)
Min (5 ms)
Normal
default (100 ms)
High priority
Max (800 ms)
A process does not have to use all its timeslice at once. A process with
100ms timeslice can run on 5 different reschedules for 20ms each
A large time slice benefits interactive tasks: no need for large timeslice
at once, remain runnable for as long as possible
Timesllice runs out -> expired -> not eligible to run till all exhausted ->
timeslices recalculated based on task static priority
(note timeslice recalculated is actually before moving to expired array
Scheduling algorithm summary (kernel/sched.c)
O(1) regardless of number of running tasks: (Swap active with expired)
SMP scalability: cpu runqueue (each process on only one queue) and
lock, affinity (cache hot), load balacing
Interactive performance, fairness
Operating System Concepts
21.4
Silberschatz, Galvin and Gagne ©2005
Process Scheduling (Cont.)
Scheduling Macros
cpu_rq(cpu)
// point to run queue of the cpu
this rq()
// point to run queue of current cpu
task_rq(task)
// point to run queue for this task queued
task_rq_lock(task,…)
// lock run queue for this task
task_rq_unlock(task…)
rq = this_rq_lock()
// lock current run queue
rq_unlock(rq)
Locking multiple runqueues
To avoid deadlock: when locking multiple runqueues, we need to
obtain lock in the same order: by ascending runqueue addresses
as follows:
double_rq_lock(rq1, rq2)
double_rq_unlock(rq1, rq2)
Operating System Concepts
21.5
Silberschatz, Galvin and Gagne ©2005
Process Scheduling (Cont.)
The Priority Arrays
Each run queue has an active array and an expired array
Priority arrays data structures provide O(1) scheduiling
Has runnable processes for each priority and has a priority
bitmap used to efficiently discover highest runnable task
Struct prio_array {
int
r_active
unsigned long
// no. tasks in queue
bitmap[BITMAP_SIZE]
struct list_head queue[MAX_PRIO]
// 140 bits
// 140 priority queues
}
Finding highest priority task: find 1st bit set in bitmap with fast
instruction (number of priority is static, so time is constant in search
regardless of number of running processes in system)
Operating System Concepts
21.6
Silberschatz, Galvin and Gagne ©2005
Process Scheduling (Cont.)
Re-calculating timeslices
Traditional: for each task {Recalculate priority and timeslice} - O(n)
Now: when each task timeslice=0, recalculate before moving to
expired array. Finally swapping two arrays via pointers
Scheduling() function determines the next task to run:
active priority array is searched to find 1st set boit
schedule a task on the list at that priority
prev=current
array=rq->active
idx=sched_find_first_bit(array->bitmap)
queue=array->queue + idx
next=list_entry(queue->next, ...)
Operating System Concepts
21.7
Silberschatz, Galvin and Gagne ©2005
Process Scheduling Cont.
Context switching (in kernel/sched.c)
Called by schedule()
switch_mm (asm/context.h): switch virtual memory map
switch_to() (asm/system.h>: saving/restoring stack and regs
Before Sched() - need_resched flag of current must be set
For example:
When timeslice runs out (schedule_tick() ), need_resched set
When a high priority task is awakened (try_to_wake_up() )
usually I/O completion, or high priority task->ready
Operating System Concepts
21.8
Silberschatz, Galvin and Gagne ©2005
Process Scheduling (Cont.)
User Preemption (Kernel is about to return to user, but need_resched on)
User code running: syscall or interrupt (timeclice, I/O done)
Before return to user, preempt user task
Should be safe at this time (since it will return to user anyway)
Kernel Preemption (kernel running and preempted)
When it is (SMP) safe to reschedule?
if lock is not held and code is reentrant. How to determine it?
preempt_count (in thread_info): Add/Substract : lock/unlock
When prempt_count=0& need_resched=on, kernel is preemptive
IH exits, before return to kernel (check the condition)
when kernel release lock (check again)
Kernel explicitly call sched()
Kernel task blocks and call sched()
Operating System Concepts
21.9
Silberschatz, Galvin and Gagne ©2005
Process Scheduling (Cont.)
Scheduler-Related System Calls
Manipulation of priorities (nice system call)
Manipulation of scheduling policy
sched_setscheduler(), sched_set_priority_mac(0, etc.
Processor Affinity: hard, “cpus_allowed” mask in task_struct,
default set all: sched_setaffinity()
Inherits from parent. If change, migration thread is used. Load
balancer
Process yielding: sched_yield()
Operating System Concepts
21.10
Silberschatz, Galvin and Gagne ©2005
Scheduling - Calculating Priority
Process Initial Priority=nice value (-20 to 19 with default 0)
static priority = static_prio // in task_struct
dynamic priority = function of (static priority+ task interactivity)
effective_prio() {
begins with nice value;
computes a bonus/penalty between -5 to +5 based on interactivity
}
Algorithm:
sleep_avg += how long it slept (after wakeup)
sleep_avg -- (for each tick)
Bonus/Penalty is based on sleep_avg
Operating System Concepts
21.11
// 0 to MAX i.e. 10msec
Silberschatz, Galvin and Gagne ©2005
Scheduling – Calculating Timeslice
Based on static priority (nice value) when it is exhausted
Type of Tasks
Nice Value
Timeslice assigned
initially created
parent’s
half of parent’s
Min
+19
MIN (5msec)
Default
0
100msec
MAX
-20
MAX (800msec)
Operating System Concepts
21.12
Silberschatz, Galvin and Gagne ©2005
Scheduling – Very Interactive Tasks
Will not be inserted into expired array
Back into active array with same priority – round robin
task=current;
rq = this _rq();
if (! (-- (task ->timeslice) ) ) {
if (! TASK_INTERACTIVE (task) || EXPIRED_STARVING(rq))
enque_task(task, rq->expired);
else enque_task(task,rq->active);
}
Operating System Concepts
21.13
Silberschatz, Galvin and Gagne ©2005
Scheduling – Sleeping
Sleeping when waiting for: timeout, I/O, event, semaphore
TASK_INTERRUPTIBLE (wakeup prematurely and respond to signal) and
TASK_UNTERRUPTIBLE (ignore signals)
Sleeping Algorithm:
add_wait_queue (…)
while (!condition) {
set state to TASK_INTERRUPTIBLE
// or UNINTERRUPTIBLE
if signal&&TASK_INTERRUPTIBLE, wake process (spurious wakeup), handle signal
if (condition is not true) { // no need to sleep
call schedule()
// deactivate task, remove from runqueue
continue;
// When task awakens, go back to check condition again
}
}
Now condition is true, set to TASK_RUNNING state, remove_wait_queue()
Operating System Concepts
21.14
Silberschatz, Galvin and Gagne ©2005
Scheduling – Waking Up
The code that causes the event to occur typically calls wake_up()
Algorithm
wake_up()
// will wake up all in wait queue
-> try_to_wake_up( // set to TASK_RUNNING
->activate_task()
// add task to run queue, set need_resched if
// awakened task’s priority is higher than
// the current task
if (need_reschedd) schedule() // calls remove_wait_queue to
// remove awakened task from wait queue
Operating System Concepts
21.15
Silberschatz, Galvin and Gagne ©2005
Scheduling – Load Balancer
Ensure run queues balanced
Called by scheduler() when current runqueue is empty
Called by timer (1msec if idle, 200msec otherwise)
Current runqueue will be locked with interrupts disabled
Algorithm:
Find busiest_queue() (25% more than current queue)
Decides which to pull: expired, highest priority
Check each task: not running, not preventing migration (affinity)
and not cache hot
Operating System Concepts
21.16
Silberschatz, Galvin and Gagne ©2005
Scheduling Summary
Real-time: Soft, FIFO, RR, Fixed Priorities 0-99
TS (normal): low, dynamic 100-139, large time slice for high priority
Run Queue: per CPU, hard affinity (default to all, cache)
Load Balancing: Select highest priority from expired array
current run queue is empty or timer (1/200msec) 25% more moved
Lock both run queues in sequence to prevent deadlock
Run Queue Data Structures: Active and Expired arrays
prio_array { r_active, bitmap[140], queue[140] }
Priority Change: sleep_avg (sleeptime/ticks) with 0-10 (-5 to 5)
Timeslice reset to its static one
Very Interactive (no move) vs expired array starvation (move)
Search run queue bitmap, exchange active/expired arrays O(1)
Operating System Concepts
21.17
Silberschatz, Galvin and Gagne ©2005
Interrupts and Interrupt handlers (Ch. 6)
Interrupts
Devices ->Interrupt Controllers->CPU-->Interrupt Handlers
Device has unique value for each interrupt = IRQ
On PC, IRQ 0 is timer interrupt, IRQ 1 is keyboard interrupt
Exceptions
Synchronous interrupts
Programming error, abnormal operation (page fault), syscall
Interrupt Handlers
Part of device driver
In Linux, it is normal C functions and run in interrupt context
Top Half (run quickly and exit quickly)
ACK to hardware, copy data to memory, ready dev. for more data
Bottom Half (detailed Processing)
Operating System Concepts
21.18
Silberschatz, Galvin and Gagne ©2005
Top Halves and Bottom Halves
Top Half
Interrupt Handler (line disabled, local interrupts disabled)
Run immediately
ACK receipt of interrupt or resetting the hardware
Bottom Half
Interrupt enabled
Detailed work
Example of Network Card
Top half: alert the kernel to optimize network throughput,
latency and avoid timeout. ACK hardware, copy packets to
memory and ready network card for more packets
The rest will be left to bottom half
Operating System Concepts
21.19
Silberschatz, Galvin and Gagne ©2005
Interrupts and Interrupt Handlers (Ch. 6)
Registering an Interrupt Handler (by Dev Driver)
int request_irq (irq, *handler, irqflags, *devname, *dev_id)
Irq: interrupt number to allocate, hard-coded or probed
irqflag:
SA_INTERRUPT: all interrupts disabled on local CPU (default - enabled,
except the interrupt line of any running handlers, masked out all CPUs)
SA_SHIRQ: line shared by multiple handlers,
devname: text name for device - or driver name
devid: id used for shared interrupt lines (null Is not shared)
The request_irq() function can sleep (kmalloc can sleep) – can’t be called
from interrupt context or other situation that can’t block
free_irq (…) unregister handler, if not shared, remove handler and disable
the line
Operating System Concepts
21.20
Silberschatz, Galvin and Gagne ©2005
Interrupts and Interrupt Handlers (Ch. 6)
Writing an Interrupt Handlers
static irqreturn_t intr_handler(irq, *dev_id, *regs)
// [declaration]
dev_id: unique when devices sharing/using same handler
regs: point to structure containing CPU registers and state before interrupt
(Return Value = IRQ_NONE
// spurious interrupt
or IRQ_HANDLED)
Handlers need not be reentrant
Handler executing, this interrupt line masked out on all CPUs
Same handler never invoked concurrently to service a nested
interrupt – simplifies coding of handler
Shared Handler can mix usage of SA_INTERRUPT, but must all
declare SA_SHIRQ. When kernel receives interrupt, it invokes
sequentially each registered handler on the line (which dev found)
Operating System Concepts
21.21
Silberschatz, Galvin and Gagne ©2005
Interrupts and Interrupt Handlers (Ch. 6)
Interrupt Context
Interrupt handler or (some/normal) bottom half
Not associated with a process. “Current” macro not relevant
Without a backing process, it can not sleep (because it can not be
rescheduled). Can not call function that sleeps. So it limits functions that
one can call from an interrupt handler
Time critical, code should be quick and simple
Interrupt stack (historically shared with process it interrupted)
Now own stack with small size (1page) per processor
Operating System Concepts
21.22
Silberschatz, Galvin and Gagne ©2005
Interrupts and Interrupt Handlers (Ch. 6)
Implementation of Interrupt Handling
Device sends signal to interrupt controller:
If interrupt line enabled (not Masked Out), Controller interrupt CPU via pin (unless CPU
interrupts disabled).
CPU stops, DISABLE the INTERRUPT SYSTEM- local interrupts, branch to IH ENTRY
Kernel ENTRY point saves IRQ number and stores register values (belong to
interrupted task) on stack, call do_IRQ() – C code starts
do_IRQ (regs)
irq = regs.orig_eax & 0xff to calculate interrupt line
Ack receipt of interrupt and disables interrupt delivery on the line (mask_and_ack_8259A())
Ensures a valid handler registered and enabled, not executing
Calls handle_IRQ_event to run the installed all IHs one by one for the line
Return to do_IRQ back to kernel ENTRY, jump to ret_from_intr()
Check need_resched (may be turned on by IH)
(User) schedule(). (Kernel) also check preempt_count (lock held)
Operating System Concepts
21.23
Silberschatz, Galvin and Gagne ©2005
Interrupts and Interrupt Handlers (Ch. 6)
Interrupt Control
Disabling interrupt only for current CPU, need spinlock (SMP)
local_irq_disable
// cli instruction
local_irq_enable
//sti instruction
local_irq_save(flags)
// save prev. state and disable; If disable twice
local_irq_restore(flags)// restored to prev. interrupt state
Disabling interrupt line (to all CPUs)
disable_irq(irq)
// not returned till current handler completes (wait for)
disable_irq_nosync(irq)// does not wait (immediately)
enable_irq(irq)
All can be called from interrupt/process context – do not sleep
Status of the interrupt system:
in_interrupt (kernel in interrupyt context)
in_irq (kernel is executing IH)
irqs_disabled (local interrupts disabled?)
Operating System Concepts
21.24
Silberschatz, Galvin and Gagne ©2005
Bottom Halves and Deferring Work (Ch7)
Top Half – Interrupt Handler
Current interrupt line disabled; all local interrupts disabled
(if SA_INTERRUPT set)
Not in process context, can not block
Time critical, hardware, Ack, copy data from hardware
Operating System Concepts
21.25
Silberschatz, Galvin and Gagne ©2005
Bottom Halves and Deferring Work (Ch7)
Bottom Half
Deferring vast amount of work with interrupts enabled
Softirqs – 32 statically defined bottom halves, only 6 defined
(kernelsrc/include/linux/interrupt.h, kernelrc/kernel/softirq.c)
HI_SOFTIRQ
0
// high Priority tasklets
TIMER_SOFTIRQ
1
NET_TX_SOFTIRQ
2
NET_RX_SOFTIRQ
3
SCSI_SOFTIRQ
4
TASKLET_SOFTIRQ
5
// tasklets
Can run concurrently on any CPU (even two of same type)
Highly threaded with per-cpu data, time-critical, high-frequency uses (Net)
Registered statically at compile-time.
Tasklets – Simple and easy-to-use softirq, Two of same type can not run
concurrently. Simpler, dynamically registered, More common form
Work queues – process context, can sleep/schedule, but higher overhead
(kernel threads/context switching), most easy to use
Operating System Concepts
21.26
Silberschatz, Galvin and Gagne ©2005
Bottom Halves - Softirq (Ch7)
Implementation of Softirqs (rarely used, tasklets more common)
32-entry (only six) array of structure (kernelsrc/kernel/softirq.c)
struct softirq_action
softirq_vec[32]
{ *action (struct softirq_action *)
void *data
}
// func to run
// data to pass to function
Softirq Handler
my_softirq->action (my_softirq)
// actually get data from this struct
Handlers run with local interrupts enabled and can not sleep (interrupt context)
A softirq never preempts another softirq, but can run on another CPU (same type)
Executing Softirqs (raising softirq i.e. Marked by IH first)
Checked/executed when - return from IH, in ksoftirqd kernel thread, any code (Net)
return from syscall. Check/execute pending softirqs
do_softirq() invoked
Operating System Concepts
21.27
Silberschatz, Galvin and Gagne ©2005
Bottom Half – Softirqs (Ch7 Cont.)
Using Softirqs
Reserved for most timing-critical and important processing
Declare softirqs statically at compile-time
HI_SOFTIRQ(0) and TASKLET_SOFTIRQ(5): tasklets
TIMER, NET_TX, NET_RX, SCSI (1, 2, 3, 4)
Registering Softirq Handler (run time)
open_softirq (NET_TX_SOFTIRQ, net_tx_action, NULL)
It runs with interrupts enabled and can not sleep (run in interrupt context)
While it runs, softirqs on current CPU are disabled (Can run on other CPU)
After registration, it is ready to run. To mark pending, IH will
raise_softirq(NET_TX_SOFTIRQ)
Operating System Concepts
// first disable interrupt, raise, then restore
21.28
Silberschatz, Galvin and Gagne ©2005
Bottom Half – Softirqs (Ch7 Cont.)
Simplified Do_softirq Algorithm (kernelsrc/kernel/softirq.c)
U32 pending=softirq_pending(cpu);
// local interrupt disabled
if (pending) {
// 32bit pending mask
struct softirq_action *h = softirq_vec;
// softirq_vec[0]
softirq_pending(cpu)=0;
// end disabled
do {
if (pending & 1) h->action(h);
h++;
// next softirq_vec[] entry
pending >>= 1;
} while (pending);
}
// The above repeat MAX_RESTART = 10 as default
// if (pending) wakeup_softirqd();
Operating System Concepts
// schedule per cpu ksoftirqd nice with +19
21.29
Silberschatz, Galvin and Gagne ©2005
Bottom Half - Tasklets (Ch7)
Implementation of Tasklets
Simple interface, relaxed locking rules, much greater use
Represented by: HI_SOFTIRQ and TASKLET_SOFTIRQ
The Tasklet Structure (for each unique tasklet)
next
state
count
func
data
// linked list of tasklet structure
// 0, TASKLET_STATE_SCHED, TASKLET_STATE_RUN (SMP)
// reference counter, nonzero means disabled, can not run
// handler function
// argument to the function
Scheduled Tasklets (equiv. Raised softirq)
Stored in tasklet_vec and tasklet_hi_vec.(linked list of tasklet_struct) – per CPU
Scheduled by tasklet_schedule() (or tasklet_hi_scheule()) by IH
Check if TASKLET_STATE_SCHED (already scheduled), return
Save state, disable local interrupt (while manipulating tasklets)
Add tasklet to head of tasklet_vec linked list (unique to each cpu)
Raise TASKLET_SOFTIRQ (do_softirq will execute it later)
Restore interrupts to previous state
Operating System Concepts
21.30
Silberschatz, Galvin and Gagne ©2005
Bottom half – Tasklets (Ch7 Cont.)
Tasklets scheduled and run
When do_softirq run and check TASKLET_SOFTIRQ or HI_SOFTIRQ raised
The handlers tasklet_action will run (most likely IH return)
The algorithm of tasklet_action()
Disable local interrupts
Retrieve tasklet_vec (or tasklet_hi_vec) for this CPU
Clear the list for this cpu
Enable local interrupts
Loop each pending tasklet
if SMP, check TASKLET_STATE_RUN flag (skip if running on other CPU)
Set TASKLET_STATE_RUN (so that another cpu will not run it)
Check count=0 (enabled?) and then run this tasklet handler
Clear TASKLET_STATE_RUN
Repeat all on the list
Operating System Concepts
21.31
Silberschatz, Galvin and Gagne ©2005
Bottom Halves - Tasklets (Ch7 Cont.)
Using Tasklets
•
Declare/Create tasklet
DECLARE_TASKLET (my_tasklet, handler, dev)
// statically, count=0, tasklet enabled
struct tasklet_struct my_tasklet={NULL, 0, ATOMIC_INIT(0), handletr, dev}
DECLARE_TASKLET_DISABLED(name, handler, data) // statically, count=1, tasklet disabled
tasklet_init (tasklet_struct t, handler, data)
// dynamically, t point to tasklet
•
Writing Tasklet Handler: tasklet_handler(unsigned long data)
As with softirqs, tasklet can not sleep (can not use semaphores and blocking function in it)
Run with interrupts enabled. Two of the same types of tasklets never run concurrently
•
Scheduling Tasklets
tasklet_schedule(&my_tasklet)
// mark it as pending
After marked, it runs once later in the future
If the same one is scheduled again before had chance to run, run only once, but
if it is already running (on other CPU), this one will be rescheduled and run again
•
Other calls tasklet_disable, tasklet_enable, tasklet_kill
Operating System Concepts
21.32
Silberschatz, Galvin and Gagne ©2005
Bottom Halves - Ksoftirqd (Ch 7)
Softirq (thus tasklets) aided by a set of per-CPU kernel threads
When the system is overwhelmed with softirqs
Per-processor Kernel Thread : ksoftirqd (lowest priority +19 nice value)
softirq can raise itself at high rates, reactivate themselves
Heavy softirq activity from starving user?, Not to handle reactivated
softirqs?
Compromise: Having a thread per cpu always able to service softirqs
ksoftirqd awakened when do_softirq detects an executed kernel thread
reactivating itself (MAX exceeded)
Operating System Concepts
21.33
Silberschatz, Galvin and Gagne ©2005
Bottom Halves - Ksoftirqd (Ch 7)
Ksoftirqd (per CPU) run in a tight loop after initialization, it can be
awakened when do_softirq run MAX_RESTART(=10) times
Algorithm:
for (;;) {
if (!softirq_pending(cpu))) schedule();
set_current_state(TASK_RUNNING); // this thread
while (softirq_pending(cpu) ) {
do_softirq();
if (need_resched() ) schedule();
}
set_current_state(TASK_INTERRUPTIBLE);
}
Operating System Concepts
21.34
Silberschatz, Galvin and Gagne ©2005
Bottom Halves – Work Queues (Ch7)
Defer work into a kernel thread (default events/n thread) – in process context
Work Queue threads are schedulable and can sleep
Allocate a lot of memory, obtain semaphore, perform blocking I/O
Creating kernel threads (worker threads) to handle work queued: default
(events/n or new one facon/n per CPU)
Data Structures Representing the Threads (type)
workerqueue_struct: {cpu_workqueue_struct[cpus], name, list }
cpu_workqueue_struct: { lock, worklist, thread }
Data Structures Representing the Work
work_struct: {pending, list of all work, handler, data, delayedtimer }
A linked list per type of queue on each CPU
All worker threads as normal kernel threads (nice = (-10))
When the work is queued, thread is awakened and process the work.
When there is no work left to process, it goes back to sleep.
Operating System Concepts
21.35
Silberschatz, Galvin and Gagne ©2005
Bottom Halves – Work Queues (Ch7)
Simplied Algorithm: worker_thread()
for (;;) {
// Thread mark self sleeping and add itself to wait queue
set_task_state(current, TASK_INTERRUPTIBLE);
add_wait_queue(&cwq->more_work, &wait);
// if waked up, check worklist, back to sleep if none
if (list_empty(&cwq->worklist)) schedule();
else set_task_state (current, TASK_RUNNING);
remove wait_queue(&cwq->more_work, &wait);
if (!list_empty(&cwq->worklist)) run_workqueue(cwq);
}
Operating System Concepts
21.36
Silberschatz, Galvin and Gagne ©2005
Bottom Halves – Work Queues (Ch7)
Simplified Algorithm: run_workqueue()
while (!list_empty(&cwq->worklist)) {
struct work_struct *work;
void (*f) (boid *);
void *data;
work=list_entry(cwq->worklist.next, struct work_struct, entry);
f = work->func;
data = work->data;
list_del_init (cwq->worklist.next);
clear_bit(0, &work->pending);
f(data);
}
Operating System Concepts
21.37
Silberschatz, Galvin and Gagne ©2005
Bottom Halves – Work Queues (Ch7 Cont.)
Creating Work to Defer
DECLARE_WORK (name, func, data) // create work_struct named name
INIT_WORK(work, func, data)
// init the work queue pointed by work
Work queue Handler: work_handler (*data)
The worker thread executes the func with inerrupts enabled and no lock
held (default), Locking is still needed with other part of kernel.
It can sleep (i.e. process context),
Despite it is in process context, it can not access user space (because no
associated user space memory map for kernel thread)
Only syscall has user space memory mapped in
Operating System Concepts
21.38
Silberschatz, Galvin and Gagne ©2005
Bottom Halves – Work Queues (Ch7)
Scheduling Work, Flushing Work, Cancel Delayed Work
schedule_work (&work);
// put work on worklist, run when event
// worker wakes up
schedule_delayed_work (work, delay); // delay in ticks
flush_scheduled_work(void);
// wait all entries in queue executed
// and then return
cancel_delayed_work (work)
Creating New Work Queues (in addition to “events” work queue)
struct workqueue_struct *keventd_wq;
// events worker example
keventd_wq = create_workqueue (“events”) // default event queue
queue_work (wq, work)
// schedule work on wq
queue_delayed_work (wq, work, delay)
// schedule delayed work on wq
Operating System Concepts
21.39
Silberschatz, Galvin and Gagne ©2005
Which Bottom Half to Use
Tasklets are built on softirqs; both are simular.
Work queue mechanism is built on kernel threads
Softirqs – least serialization constraints, allow more concurrency
Same type may run concurrently on different CPU.
For highly threaded code with per-CPU data; time critical and high frequency uses
Tasklets – are just softirqs that do not run concurrently (same type)
Not finely threaded, simpler interface, easier to implement (two tasklets of same
type might not run concurrently)
Dev. Driver developer should choose tasklets over softirqs (unless it prepares to
utilize per-cpu data or some way safe to run on SMP)
Work Queues – Process context (schedulable), sleep
Highest overhead (context switch)
If no need to sleep, softirqs and tasklets are better
Easiest to use (default event queue)
Operating System Concepts
21.40
Silberschatz, Galvin and Gagne ©2005
Locking Between Bottom Halves (Ch7)
Tasklets – serialized with respect to themselves:
Same tasklet will not run concurrently (no intra-task lock) even on two different CPU
Only inter-task locking (SMP) needed
Softirqs provides no serialization constraints (all can run)
Lock needed for shared data (All might run concurrently)
Process context (kernel) code and a bottom half (softirq etc.) sharing
Need to disable bottom half processing and obtain lock (SMP) for this process
If interrupt context code (top-half) and a bottom half sharing data
Need to disable interrupts and then obtain lock (SMP) for this bottom half
Any shared data in a work queue requires locking
no different from normal kernel code (work queue in process context)
Disabling (All) Bottom Halves including all softirqs and all tasklets
local_bh_disable(), local_bh_enable() // may nest, last enable release - preempt_count
Operating System Concepts
21.41
Silberschatz, Galvin and Gagne ©2005
Kernel Synchronization
Kernel has concurrency and need synchronization
Interrupts, softirqs/tasklets (kernel can raise these anytime and interrupt kernel code),
kernel preemption, kernel sleep (scheduler invoked), SMP
Code safe from concurrent access
Interrupt safe (from interrupt handler), SMP safe, Preempt safe (kernel preemption)
What to protect: Global data (NOT CODE)
Granularity of Locking (2.6 fine-grained for scalability)
i.e. scheduler run queues (per CPU)
Atomic Operations: atomicity vs. Ordering (barrier)
Atomic Integer Operations: atomic_t type
Typically implemented as inline functions with inline assembly (or macro)
Atomic Bitwise Operations (generic memory pointer and bit position)
Operating System Concepts
21.42
Silberschatz, Galvin and Gagne ©2005
Spin Locks
Spin locks: Lightweight, Not Recursive
short durations (less than two context switches), assembly
if recursive, will spin waiting to release lock – deadlock
Spin Locks can be used in interrupt handlers (not semaphore)
If lock is used in IH, must also disable local interrupts before obtaining this spin lock; otherwise it is
possible for an IH to interrupt kernel while lock is held and attempt to reacquire the lock. (doubleacquire-lock)
spin_lock_irqsave (save state, disable local interrupt, obtain lock) // save current state, local disable
spin_unlock_irqrestore (unlock, return to prev. state)
spin_lock_irq, spin_unlock_irq (if already know enabled) // local disable, obtain lock
Spin Locks and Bottom Halves
spin_lock_bh, spin_unlock_bh
// obtain given lock, disable all bottom halves
Bottom halves may preemp process context code:
Protect data in process context by both locking and disabling bottom halves.
Interrupt may preempt bottom half: Lock and disable interrupt
Operating System Concepts
21.43
Silberschatz, Galvin and Gagne ©2005
Spin Locks (Cont.)
Spin Locks and Bottom Halves: Tasklets
No need to protect data used only within a single type of tasklet since two tasklets of
same type do not run concurrently.
If data shared between two different tasklet, must obtain a spin lock;
A tasklet never preempts another running tasklet on the same CPU
So, disabling bottom halves is not needed
Spin Locks and Bottom Halves: Softirqs
Regardless same softirqs type or not, data shared by softirqs must be protected with a
spinlock lock (two of same type may run concurrently on SMP)
A softirq will never preempt another softirq running the same CPU
So, disabling bottom halves is not needed
Operating System Concepts
21.44
Silberschatz, Galvin and Gagne ©2005
Reader-Writer Spin Locks
Shared/Exclusive Locks
Reader-writer spin lock is initialized:
my_rwlock = RW_LOCK_UNLOCKED
Reader and Writer Path
read_lock(&my_rwlock)
write_lock(…)
CR
read_unlock(…)
CR
write_unlock(…)
Can not “upgrade” a read lock to write lock
read_lock() followed by write_lock()
// deadlock as write lock spins -> deadlock
Linux 2.6 favors readers over writers (starvation of writers)
Operating System Concepts
21.45
Silberschatz, Galvin and Gagne ©2005
Semaphores
Contending tasks sleep, semaphores for long wait
Because sleep, semaphores are only for process context (interrupt context
is not schedulable)
Can sleep while holding a semaphore (no deadlock)
Can not hold a spin lock while acquiring a semaphore (may sleep)
Unlike spin locks, semaphores do not disable kernel preemption – therefore
code holding semaphore can be preempted
Binary (mutex) and counting semaphores: P and V; down and up
Creating and Initializing Semaphores
static DECLARE_SEMAPHORE_GENERIC(name, count); or static DECLARE_MUTEX(name);
sema_init (sem, count); or init_MUTEX(sem);
// dynamically
Using Semaphores
down_interruptible(&mr_sem)
// acquired or sleep in INTERRUPTIBLE state (-EINTR)
// interruptible – more common
up(&mr_sem)
down_trylock()
Operating System Concepts
// try to acquire, if held – returns nonzero otherwise return 0 and acquired
21.46
Silberschatz, Galvin and Gagne ©2005
Reader-Writer Semaphore
Reader-Writer flavor of semaphores
Reader-Writer semaphores are created/initialized
static DECLARE_RWSEM (name)
// declared name of new semaphore
init_rwsem(struct rw_semaphore *sem);
// created and initialized dynamically
Reader-Writer Semaphores are mutexes (textbook: db semaphore)
Multiple readers and one writer
Reader-Writer Semaphores : locks use uninterruptible sleep
Only one version of down and up: down_read), up_read() etc.
As with semaphores, the following are provided:
down_read_trylock() and down_write_trylock() // return nonzero if acquired, opposite of normal
Unique Methods from their spin lock cousins:
downgrade_writer()
// convert acquired write lock to read lock automatically
Init_rwsem, down_read. Down_write, down_read_trylock, down_write_trylock,
up_read, up_write
Operating System Concepts
21.47
Silberschatz, Galvin and Gagne ©2005
Spin Locks vs. Semaphores
•
Spin Locks
Low overhead
Short hold time
Need to lock from interrupt context
•
Semaphores
Long Lock hold time
Need to sleep while holding a lock
Operating System Concepts
21.48
Silberschatz, Galvin and Gagne ©2005
Completion variables
A task signals to other task that an event occurs
One task waits on the completion variable while other task performs work.
When it completes, it uses a completion variable to wake up the other task.
init_completion(struct completion *) or DECLARE_COMPLETION (mr_comp)
wait_for_completion (struct completion *)
complete (struct completion *)
Similar to semaphore
Just a simple solution otherwise semaphore
Examples
vfork uses completion variable to wake up the parent when child exec/exit
Operating System Concepts
21.49
Silberschatz, Galvin and Gagne ©2005
Seq Locks (2.6 kernel)
Simple mechanism for reading and writing shared data by
maintaining a sequence counter
write lock obtained seq# incr; unlock -> seq# incr.
Prior to and after read: the sequence number is read
If value is the same: a write did not begin in the middle of read
if value even: a write is not underway (grabbing write lock makes the value
odd, whereas releasing it makes it even because the lock starts at zero
Writer always succeed (if no other writers), Readers never block
Favors writers over readers
Readers does not affect writer’s locking (as those in reader-writer
spin locks or semaphores)
Seq locks provide very light weight and scalable lock for use with
many readers and a few writers
Operating System Concepts
21.50
Silberschatz, Galvin and Gagne ©2005
Seq Locks (Cont.)
Example:
(kernelsrc/include/linux/seqlock.h)
seqlock_t mr_seq_lock *s1
write_seq_lock (s1);
{ spin_lock(s1->lock); ++s1->sequence; SMP_wmb()}
/* write lock obtained */
write_sequnlock (s1); --> {SMP_wmb(); s1->sequence++; spin_unlock(s1->lock);}
do {
seq = read_seqbegin (s1) // {ret = s1->sequence; SMP_rmb(); return ret;}
/* read data */
} while (read_seqretry (s1, seq)); // {SMP_rmb(); return (seq&1) | (s1-sequence^seq
Pendiing writers continually cause read loop to repeat until there
are no longer any writers holding the lock
Writer always succeed if no other writers; Readers do not affect
writer’s lock; Readers never block
Operating System Concepts
21.51
Silberschatz, Galvin and Gagne ©2005
Preemption Disabling
Kernel preemption code normally uses spin lock as markers of non
preemption region (if spin lock held, no preemption)
Sometimes, we do not require a spin lock, but do need kernel
preemption disbled:
per-CPU data – no need to acquire lock, but need preemption disabled
preempt_disable() - this is nestable // do { preempt_count()++; barrier(); } while (0)
preempt_enable() // {do { preempt_enable_no_resched(); if preemtt_count=0 service pending}
// service any pending reschedules
preempt_count()
preempt_enable_no_resched()
// {barrier(0; dec_preempt_count();}
// not checking pending reschedules
As a cleaner solution to per-CPU data issues:
cpu = get_cpu();
// disable kernel preemption, set cpu to current cpu
/* manipulating per-CPU data */
put_cpu();
// re-enable kernel preemption, cpu can change
Operating System Concepts
21.52
Silberschatz, Galvin and Gagne ©2005
Ordering and Barriers
Both compiler and processor can reorder reads and writes for
performance/optimization purpose
Processors also provide machine instructions to enforce ordering
requirements. Also possible to instruct compiler not to reorder
instructions around a given point Barriers
Examples
a = 1; b = 2;
/* may allow CPU to store new value in b before store new value in a */
Memory and Compiler Barrier Methods
barrier()
// compiler barrier - load/store
smp_rmb(), wmb(), mb()
// only on smp, do rmb, wmb, mb - otherwise barrier()
read_barrier_depends()
// prevents dependent load - seen by compiler
smp_read_barrier_depends() // above only when it is on SMP - otherwise barrier()
Intel X86 processors do not ever reorder writes
Operating System Concepts
21.53
Silberschatz, Galvin and Gagne ©2005
Timers and Timer management
Kernel is timer driven (event-driven) – System Timer
System Timer, a programmable piece of hardware that issues interrupt at a
fixed frequency – timer interrupt
The time, i.e. period between two successive timer interrupts - tick
(Note: this is used to keep track of both wall time and system uptime)
Work performed periodically by timer interrupts:
Update: system uptime, time of day, resource usage, CPU time statistics
Run any dynamic timers that have expired
Check that if current process has exhausted timeslice and reschedule
On SMP, balancing runqueues (200msec)
Operating System Concepts
21.54
Silberschatz, Galvin and Gagne ©2005
Timers and Timer Management (Cont.)
The Tick Rate: HZ
Is programmed on system boot based on a static preprocessor defined HZ (value of
HZ differs for each architecture)
The tick rate has a frequency of HZ hertz and a period of 1/HZ seconds
i386 architecture: HZ=1000 (interrupts 1000 times per second)
High HZ Value Advantages
Timer with higher resolution; greater accuracy of timed events
System calls i.e. poll(), select() timeout value with improved precision
Measurements of resource usage or system uptime with fine resolution
Process preemption occurs more accurately
High HZ Value Downsides
More frequent timer interrupts and higher overheads
(less CPU time for other work, more frequent thrashing of CPU caches)
Operating System Concepts
21.55
Silberschatz, Galvin and Gagne ©2005
Timers and Time Management (Cont.)
Global Variable: Jiffies
Number of ticks since booting (0) and incremented for each interrupt
HZ timer interrupts/sec, System uptime =(jiffies/ HZ) seconds
Internal Representation of Jiffies (unsigned long)
Jiffies Wraparound
if (timeout > jiffies) ….
// will have problem – jiffies may already wrapped
if (time_before (jiffies, timeout)) …// kernel macro to correct it
Other macros: time_after(.), time_after_eq(..), time_before_eq(..)
User Space and HZ
Changing HZ can scale various exported values by some constant without user-space knowing
Defining USER_HZ
// HZ value that user-space expects
#define jiffies_to_clock_t (x)
( (x) / HZ / USER_HZ))
total_time = jiffies – start;
printk (“ it took %lu ticks\n”, jiffies_to_clock_t(total_time) // user expects USER_HZ
Operating System Concepts
21.56
Silberschatz, Galvin and Gagne ©2005
Hardware Clocks and Timers
Real-Time Clock
RTC nonvolatile device for storing system time with a small battery
On PC, RTC and CMOS integrated on a single battery keeps RTC running
and BIOS settings preserved
On boot, kernel reads RTC and uses it to initialize wall time (stored
in xtime). X86 periodically save current wall time back to RTC
System Timer
Provides a mechanism for driving an interrupt at a periodical rate. An
electronic clock that oscillates at a programmable frequency. Or system
provides a decrementer: a counter set to some initial value and decrements
at a fixed rate until counter reaches zero – interrupt is triggered
X86 System Timer – Programmable Interrupt Timer (PIT)
Kernel programs PIT on boot to drive system timer interrupt at HZ
frequency.
Operating System Concepts
21.57
Silberschatz, Galvin and Gagne ©2005
The Timer Interrupt Handler – Arch. Dep.
Registered as the (top-Half) interrupt handler for the system timer
and runs when timer interrupt occurs
Obtain xtime_lock (for jiffies_64, and xtime)
Acknowledge or reset system timer as required
Call Architecture Independent timer routine do_timer
Periodically save the updated wall time to the real time clock
Operating System Concepts
21.58
Silberschatz, Galvin and Gagne ©2005
Timer Interrup Handler – Arch. Indep.
Architecture-Independent Routine (do_timer)
Increment jiffies_64
Update p->utime (or stime)
// Based upon user_mode registers saved
run_local_timers();
// schedfule bottom-half - raise_softirq (TIMER_SOFTIRQ);
// handled by run_timer_softirq() – run all expired timers
// timers stored in linked list (in groups – expiration)
// END scheduling bottom-half
scheduler_tick();
// Decrement process timeslice,
// Set need_resched if needed,
// Balance run queue – (200ms)
update_times();
// ticks = jiffies – wall_jiffies (should be 1)
// wall_jiffies += ticks; update_wall_time(ticks)
// calc_load (ticks) update load average
do_timer() return to architecture-dependent IH
Cleanup; release xtime_lock, return // all this for every 1/HZ second
Operating System Concepts
21.59
Silberschatz, Galvin and Gagne ©2005
The Filesystem
To the user, Linux’s file system appears as a hierarchical directory
tree obeying UNIX semantics
Internally, the kernel hides implementation details and manages the
multiple different file systems via an abstraction layer, that is, the
virtual file system (VFS)
The Linux VFS is designed around object-oriented principles:
Write -> sys_write()
Then --> filesystem’s write method --> physical media
// VFS
VFS Objects
Primary: superblock, inode(cached), dentry (cached), and file objects
An operation object is contained within each primary object:
super_operations, inode_operation, dentry_operation, file_operations
Other VFS Objects: file_system_type, vfsmount, and three per-process
structures such as file_struct, fs_struct and namespace structures
Operating System Concepts
21.60
Silberschatz, Galvin and Gagne ©2005
File System and Device Drivers
User applications
Libraries
User mode
Kernel mode
File subsystem
Buffer/page cache
Character device driver
Block device driver
Hardware control
Operating System Concepts
21.61
Silberschatz, Galvin and Gagne ©2005
Virtual File System
Operating System Concepts
21.62
Silberschatz, Galvin and Gagne ©2005