Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
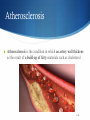
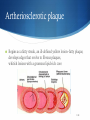
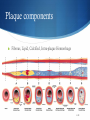
Datamining @ ARTreat Veljko Milutinović Zoran Babović Nenad Korolija Goran Rakočević Marko Novaković [email protected] [email protected] [email protected] [email protected] [email protected] Agenda ARTReat – the project Arteriosclerosis – the basics Plaque classification Hemodynamic analysis Data mining for the hemodynamic problem Data mining from patent records 2/28 ARTreat – the project ARTreat targets at providing a patient-specific computational model of the cardiovascular system, used to improve the quality of prediction for the atherosclerosis progression and propagation into life-threatening events. FP7 Large-scale Integrating Project (IP) 16 partners Funding: 10,000,000 € 3/28 Atherosclerosis Atherosclerosis is the condition in which an artery wall thickens as the result of a build-up of fatty materials such as cholesterol 4/28 Artheriosclerotic plaque Begins as a fatty streak, an ill-defined yellow lesion–fatty plaque, develops edges that evolve to fibrous plaques, whitish lesions with a grumous lipid-rich core 5/28 Plaque components Fibrous, Lipid, Calcified, Intra-plaque Hemorrhage 6/28 Plaque classification Different types of plaque pose different risks Manual plaque classification (done by doctors) is a difficult task, and is error prone Idea: develop an AI algorithm to distinguish between different types of plaque Visual data mining 7/28 Plaque classification (2) Developed by Foundation for Research and Technology Based on Support Vector Machines Looks at images produced by IVUS and MRI and are hand labeled by physicians Up to 90% accurate 8/28 Data mining task in Belgrade Two separate paths: Data mining from the results of hemodynamic simulations Data mining form medical patient records Goal: to provide input regarding the progression of the disease to be used for medical decision support 9/28 Hemodynamics – the basics Study of the flow of blood through the blood vessels Maximum Wall Shear Stress – an important parameter for plaque development prognoses 10/28 Hemodynamics - CFD Classical methods for hemodynamic calculations employ Computer Fluid Dynamics (CFD) methods Involves solving the Navier-Stokes equation: …but involves solving it millions of times! One simulation can take weeks 11/28 Data mining form hemodynamic simulations (first path) Idea: use results of previously done simulations Train a data mining AI system capable of regression analysis Use the system to estimate the desired values in a much shorter time 12/28 Neural Networks - background Systems that are inspired by the principle of operation of biological neural systems (brain) 13/28 Neural Networks – the basics A parallel, distributed information processing structure Each processing element has a single output which branches (“fans out”) into as many collateral connections as desired One input, one output and one or more hidden layers 14/28 Artificial neurons Each node (neuron) consists of two segments: Integration function Activation function Common activation function Sigmoid 15/28 Neural Networks - backpropagation A training method for neural networks Try to minimize the error function: by adjusting the weights Gradient descent: Calculate the “blame” of each input for the output error Adjust the weights by: (γ- the learning rate) 16/28 Input data set Carotid artery 11 geometric parameters and the MWSS value 17/28 The model One hidden layer Input layer: linear Hidden and output: sigmoid Learning rate 0.6 500K training cycles Decay and momentum 18/28 Current results Average error: 8.6% Maximum error 16,9% 19/28 The “dreaded” line 4 Line 4 of the original test set proved difficult to predict Error was over 30% Turned out to be an outlier Combination of parameters was such that it couldn’t But the CFD worked, NN worked Visually the geometry looked fine Goes to show how challenging the data preprocessing can be 20/28 Dataset analysis Two distinct areas of MWSS values: the subset with lower values of MWSS, where a similar clear pattern can be seen against all of the input variables, scattered cloud of values in the subset with higher MWSS values. Histogram shows the majority of values grouped in the lower half of the values in the set, with only a small number of points in the higher half. 21 MWSS value prediction Two approaches: Single model Two models: one for the low MWSS value data, one for higher values, classifier to choose the appropriate model Models based on Linear Regression and SVM 22 Results Model Root square mean error Correlation coef. Single model LR 19% 0.7 Single model SVM 17% 0.77 Low value model LR 11% 0.81 Low value model SVM 7% 0.91 High value model LR 42% 0.21 High value model SVM 31% 0.07 Classifier Correctly classified Kappa F measure SVM 93.2% 0.64 0.517 Poor results for higher values of MWSS – insufficient values to train a model 23 MWSS position A few outliers and “strange” values in the data set After elimination: Coordinate LR SVM RSME CC RSME CC X 0.2389 0.9721 0.277 0.9691 Y 0.1733 0.8953 0.1671 0.9136 Z 0.0736 0.8086 0.1221 0.8304 Further investigation needed into the data and the “outlier” values, although it is only a small number of them 24 Genetic data Single coronary angiography Blood chemistry Medications Single Nucleotide Polymorphism (SNP) data on selected DNA sequences 25/28 …and now for something completely different 26/28 Questions 27/28 Datamining @ ARTreat Project Veljko Milutinović Zoran Babović Nenad Korolija Goran Rakočević Marko Novaković [email protected] [email protected] [email protected] [email protected] [email protected]