Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
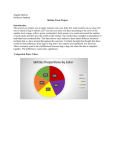
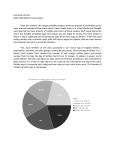
Nathan Schafer Math 1040 E-porfolio post 4-27-2015 During this semester we conducted a project based on skittles. Each student purchased a small bag of skittles. We then counted each candy by color and compiled the data as a class. Based on these numbers we used this data to learn different concepts during the semester. Part 1 of the project was collecting the data. Part 2 (Individual) 1. Write a paragraph discussing your findings about the variable “Total candies in each bag”. Address the following in your writing: What is the shape of the distribution? Do the graphs reflect what you expected to see? Does the overall data collected by the whole class agree with your own data from a single bag of candies? Include the number of candies from your own bag and the total number of bags in the class sample in your discussion. The total candies in each bag surprised me. When I looked at the graph’s I didn’t expect to see it skewed left. I expected to see a more systematic distribution. The overall class data is pretty close to my individual bag. My bag contained 63 candies while the median for the class was 60, and the Mean was 59. 2. In a half page, explain the difference between categorical and quantitative data. Address the following in your writing: What types of graphs make sense and what types of graphs do not make sense for categorical data? For quantitative data? Explain why. What types of calculations make sense and what types of calculations do not make sense for categorical data? For quantitative data? Explain why. Categorical data is something that can be observed but not measured, for example the colors on a painting. While quantitative data is a data set of numbers that can be counted, for example the height of our class or their weight. Bar graphs and pie charts are the best graphs to use for Categorical date, because the show how large a category is in comparison to the whole or population of observation. Histograms, stem plots, and box plots are great for quantitate data because it will give a frequency of the data report. Part 2 (Group) Math 1040 Class Skittles Proportions Color Count Proportion of Total Red Skittles Orange Skittles Green Skittles Purple Skittles Yellow Skittles Total Number of Skittles in the class 564 0.199 564 0.199 566 0.199 559 0.197 586 0.206 2839 1.000 Does the Class data represent a random sample? Yes, the class data does represent a random sample. Although each student was asked to buy their own bag of skittles and not every bag of skittles in the region had an equal chance of being selected, the distribution of skittles from the central plant/warehouse was most likely random. The skittles company most likely does not count colors as they load the bags and simply loads by weight, and assuming students did not make any biased decisions about which bag to grab off the shelf every bag produced had an equal chance of being shipped to any location in the country and being selected at random by a student in the class. What would the population be? In this study, the sample is the class data. Since not everyone in the class is currently living in the same state, the population would be all 2.17 ounce skittles bags in the United States. There are currently different manufacturing plants operating overseas, therefore the population can only reasonably be expanded to include the United States distribution circuit. Part 3 (individual) These charts compare the total count of skittles for the entire class against the total of my individual bag. In my initial observation of my bag I expected to see more uniformity among the different colors. I thought the colors might be off by one or two. I didn’t expect to see a five candy difference. After seeing the totals for the class, I was completely shocked. I expected a wide variation in the class totals because of what I saw in the individual bag. The distribution for the class seems closer than the individual bag, which is not what I expected at all. Part 3 (Group) 1. Using the total number of candies in each bag in our class sample, compute the following measures for the variable “Total candies in each b (a) mean number of candies per bag The mean number of candies per bag is 59.1 candies. (b)standard deviation of the number of candies per bag The standard deviation per bag is 6.4 candies. (c)5-number summary for the number of candies per bag The 5-number summary is 3458-60-62-71. Part 4 (Individual) The purpose of using a confidence interval is to get an interval of numbers in which the mean of an experiment will end up after many repeated experiments. For example if we take 100 responses from 250,000 people we will get a mean. If we take another 100 responses we will get a slightly different mean, and so on for each experiment. We use a confidence interval to estimate the range of the population mean. The confidence interval is an estimate of the population parameter. Part 4 (Group) 99% Confidence Interval estimate for the population proportion of yellow candies X= 586 n= 2839 Z-value for 95% CI = 2.576 p= 586/2839 = 0.206 0.206 +/- 2.576 * (0.007596) 0.206 +/- 0.01957 99% Confidence Interval Estimate: (0.186, 0.226) Confidence Intervals estimated from a population proportion are used to determine, with the specified degree of confidence, the proportion of a characteristic found within a population. In relation to the skittles, we are 99% confident that the proportion of yellow skittles in any bag of skittles falls between 0.186 and 0.226. 95% Confidence Interval estimate for the population mean number of skittles per bag n= 49 Sx = 6.38 Sample mean= 59.15 Standard error of the mean = 0.9114 To find the t-value, a t-table was consulted using a degree of freedom of 50. The t-value is 2.009. 59.15 +/– t*(0.9114) 59.15 + 1.83 = 60.98 59.15- 1.83 = 57.32 95% Confidence Interval Estimate: (57.32, 60.98) Confidence Interval estimates of the population mean use sample date to extrapolate an interval with the specified degree of confidence that the mean characteristic of a population should fall within. In this case, we are 95% confident that the mean number of skittles in any bag is between 57.32 and 60.98. 98% confidence interval estimate for the population standard deviation of the number of candies per bag n=49 s=6.37 8 S2=40.679 χ2 1-a/2 = 0.99 χ2 a/2 = 0.01 On the Chi square distribution chart, 50 degrees of freedom was used. The value for χ2 1-a/2 was 29.707. For χ2 a/2 it was 76.154. √[ s2(df)/Chi value] Lower bound: 5.06 Upper bound: 8.11 Confidence Interval estimates from the population standard deviation use the sample standard deviation in order to generate an interval that the population standard deviation of the number of candies should fall within, with the specified level of confidence. In this case, we are 98% confident that the population standard deviation is within 5.06 and 8.11 candies. The problem with confidence interval estimates taken from the sample standard deviation is that the sample standard deviation may be quite different from the actual population standard deviation. Reflection I never really understood how vital statistics were to the world. It was great to learn all of the different ways statistics are used in everyday life and science to help better our understanding of things. During the semester we did a project with each person buying a small bag of skittles. We then collected all the individual students’ candy counts by color and compiled the data into a chart. We then used this data for learning different types of statistical analysis. We made charts, graphs, and confidence intervals. This project really changed the way I think about information put out by market research firms and other groups that use statistical data. I learned information can be misrepresented by simply using the wrong medium to present it, for example using charts that represent size growth rather than a larger picture to show growth. Pictures will make it seem like larger growth has occurred than the data actually shows. One of the other things I enjoyed seeing was how starting the Y-axis of a chart is important for true representation of data. You can make the data show large or small differences if you choose the right starting point for the Y-axis of your chart. Once I learned this information it was amazing to see it in use in magazine ads for major companies trying to show why they are better at something than others, when they are all very similar. Company A just shows the data in a different way to make you think company A is so much better. This class has really changed the way I think about data. Not only the way it is represented but also how it is collected. There is so much room for bias in data collection and representation that you really have to pay attention or you can be very mislead in how you see the information being presented to you. I truly never knew how misleading data can be until I learned some of the concepts in this class. This new information will help me analyze things differently in the future, not just in math but everyday life.