Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
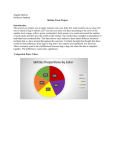
Abby White Into to Statistics Math 1040 Skittles Term Project This project is a way for the math 1040 students to use all of the concepts learned in class and apply them to practical data to practice their skills. Each student had their own personal bag of skittles in which they sorted into colors and counted the number of each skittle in the color categories Red, Green, Orange, purple, and Yellow. The data from both statistics classes were then compiled into a spread sheet. The students then used this data to determine the proportion of each color within the sample. This was achieved by making a Pie Chart and a Pareto Chart for the number of candies in each color. The students will then observe the data and reflect on the comparisons of the two graphs. Students will then organize and display quantitative data. Students will calculate the mean, standard deviation, and 5-number summary. Then using the results of their calculations the students will create a frequency histogram and a boxplot. Next, they will determine the shape or the data. The next part of the project is about confidence intervals and hypothesis tests. First students with explain the general purpose and meaning of a confidence interval and then solve three problems. Dealing with proportion, mean, and standard deviation. The second part of this section students will explain the purpose and meaning of hypothesis tests, then solve two different hypothesis test problems in which they will show their work and interpret the results. The last part of this section is the reflection, students will draw conclusions of the interval estimates and hypothesis tests for population proportions and discuss whether the samples meet the requirements. Also, students will reflect on possible errors that potentially could be made by using this data and improvements they see fit. Title: Title: Proportion of each color of skittles in the sample The number of skittles in each color category Key: 2:Green 3:Yellow 4:Purple 5:Orange 6:Red 700 648 629 612 607 600 18% 20% 21% 21% 20% Green 500 Yellow 400 Purple 300 Orange 200 Red 548 100 0 0 1 2 3 4 5 6 Comparing the two graphs they reflect what I excepted to see, for the most part the proportion of the different colors of skittles are very close to one another. The Pie chart does a good job of displaying that they are very close to each other and also displays the percentage which is very helpful. The Pareto chart is very easy to see what color of skittles has the most and what has the least as well as comparing all the colors to each other. The distribution of the skittles is what I would expect to see in a single bag of candies. In my personal bag of skittles the proportions of each color are quite similar to the sample proportions of each color of skittles. For example, the orange skittle proportion of the sample is .199 and the proportion of orange skittles in my individual bag is .175 fairly similar. In comparing some of the proportions to my own individual bag I found a significant difference to the sample proportion though. For example, the sample proportion of green skittles is .213 and the proportion from my bad is .143, which is a difference of 7% which is not a huge difference, but I expected them to be closer. Number of Red Number of Number of Number of Number of Candies Orange Candies Yellow Candies Green Candies Purple Candies 9 11 17 9 17 This is the data from my personal bag of skittles. The proportion of skittles from the sample is: Red=0.180 Orange=0.199 Yellow=0.207 Green=0.213 Purple=0.201 The proportion of skittles by color from my personal bag is: Red=0.143 Orange=0.175 Yellow=0.270 Green=0.143 Purple=0.270 Organizing and Displaying Quantitative Data Title: Title: Frequency of skittles per bag of candy Distribution of the number of skittles per bag The total number of bags in the sample was 50. The data has an outlier which is 86 skittles in one bag of candy, which skews the data slightly to the right. The graphs reflect what I was expecting, which was a high number of bags of skittles with 60-65 candies and a few bags of skittles with slightly higher and lower amounts. However the outlier is much higher than I expected it is nearly double the amount of skittles than the bag with the lowest amount which was 44. In my personal bag of skittles I had 63 candies which fits in to the 60-65 candies per bag range. For the sample of data: Mean= 60.88 Standard Deviation= 5.509 The 5-number Summary: Q1= 60 Median=61 Q3=63 Maximum=86 Reflection Categorical data consists of names or labels that are not representing counts or measurements. On the other hand, quantitative data consists of numbers representing counts and measurements. The types of graphs that make since for categorical data are Pie charts and Pareto Charts. Pie charts are good for categorical data because you can clearly distinguish and compare the different categories. Pareto charts allow one axis to represent categorical data and the other to represent frequency data. The types of graphs that makes since for quantitative data are histograms and boxplots. Histograms are for numerical data because both axes of the graph are numbers. Boxplots are also only dealing with a number line. The types of calculations that make since for categorical data are finding proportions. The types of data that makes since for quantitative data consist of finding the mean, standard deviation, and 5-Number summary. This is because you can quantitative data consists of numbers you can count where as you cannot count categorical data. Confidence Interval Estimates Confidence intervals are a range of values with a specified probability that the parameter is within that range. Confidence intervals are used in statistics to estimate the parameter, the range of value gives a margin of error, because we cannot be 100% certain. Also, how confident you want to be affects the error. For example, if you want to be 99% confident the range of number will be larger than if you only want to be 95% confident. For the first confidence interval constructed at a 95% confidence interval estimate for the true proportion of purple candies I found that 95% of all bags of Skittles will have between 18.68%-21.52% of purple candies. If I wanted to be even more certain of the proportion of purple candies in each bag of Skittles I could construct a 99% confidence interval and that would give me a wider range of proportion of purple Skittles per bag. This is shown in the next problem when I estimated the true mean number of candies per bag. Since we cannot be 100% sure what the true mean number of candies are in a bag of Skittles because we only have a sample mean not a population mean. However, based on our sample we can be 99% sure that the true mean number of Skittles per bag is between 58.79-62.97. In the last confidence interval question we constructed a 98% confidence interval estimate for the standard deviation of the number of candies per bag. This means that we are 98% confident that the number of candies per bag varies by 4.419-7.075 candies. Hypothesis Tests A hypothesis test determines if the hypothesis, a claim or statistic about a population, is false or could be valid. You can never prove a hypothesis, you simply fail to reject it. There could always be lurking variables. For the first problem I used a 0.01 significance level to test the claim that 20% of all Skittles candies are green. After completing the problem the test statistic was not in the rejection region thus I failed to reject the null hypothesis that claimed that 20% of all Skittles candies are green. This does not mean that all Skittles candies are green there could be lurking variables, Hypothesis test never prove anything. The second problem I used a 0.05 significance level to test the claim that the mean number of candies in a bag of Skittles is 56. After doing the calculations my test statistic was within the rejection region. I rejected the null hypothesis that claims that the mean number of Skittles in a bag is 56. The mean number of Skittles per bag in our class sample was 61 candies. I think that if we tested the claim that the mean number of candies per bag was 61 then we would fail to reject the claim. Reflection For p For mean For Standard Deviation The sample must be a The sample must be a The sample must be a simple random sample simple random sample simple random sample The conditions for a The population is normally The population must have binomial distribution must distributed normal distributed values be met: fixed number of Or n>30 (even in large samples). trials, trials are independent, there are two categories of outcomes, and the probabilities remain constant for each trial. There are at least 5 successes and 5 failures I think our sample of Skittles is a simple random sample, because each bag was chosen by chance from a larger population and each bag has the same probability of being chosen. However, because all the students that bought a bag of Skittles lives in the same general area the skittles in the greater Salt Lake area have a much greater probability of being chosen than a bag of skittles in a different state of even a different part of Utah. So in that since this is not a simple random sample of all bags of skittles, just a simple random sample of bags of skittles in the greater Salt Lake area. The conditions for the binomial distribution are met, it is a fixed number of trails 50 trials, They are all independent of one another and the probabilities remain constant for each trial. Also, there are at least five successes and failures, and the population is greater than thirty. The conditions for standard deviation are both met. It is a simple random sample and the population is normally distributed. Possible errors for the data could be that some people got the wrong size of Skittles bag, either too small or too large. This would affect the mean number of Skittles in the bag, the proportion of each color of Skittles in each bag and the standard deviation. The sampling method could be improved by insuring that students only get 2.17 oz bags of Original Skittles rather than varying sizes of other flavors. Also, if there was a way to get a true simple random sample of Skittles form the factor that made them, before they are shipped all over the world the data would be a lot more accurate. In conclusion, the results show that 18.7%-21.5% of all Skittles are purple. That there are between 58.79-62.97 Skittles in each 2.17 ounce bag of Original flavored Skittles. Also, that the mean number of Skittles per bag varies from the mean by 4.419-7.075 Skittles Reflective Writing and e-Portfolio This project has been very educational. I feel that I have learned more about proportions, probability, graphs, confidence intervals, and hypothesis tests from participating in this project. Going to class and doing homework is helpful in learning new concepts, but when you use the concepts you learn and apply them to a real world situation it solidifies the new concepts and makes them easier to comprehend. Besides gaining a greater understanding of the statistical concepts we have learned in class I have also learned a very useful skill that will help me throughout the rest of my life in many ways other than math or homework assignments. Using excel and becoming more comfortable with the program is a very practical skill I have gained from this skittle project, I was not very comfortable with it before so being able to discover how to make different types of graphs and charts, summing, averaging, finding standard deviation of the different columns and rows will be useful for practical real life situations such as budgeting. The math skills that I applied to this project will impact the other classes I take during my school career in many ways. For instance, Microsoft Excel is a great program to become more confident in and will definitely aid me in other classes. Also, the critical thinking skills I needed for this project will be extremely useful. I learned how to compare and contrast data and different graphs, which I think is an important skill in the world of education to be able to compare information given in a research paper or in a scholarly journal. This skill will help me be better informed by distinguishing between deceptive graphs and information. Problem solving skills are essential to being a good student and really a good citizen. I feel that the problem solving and critical thinking skills I have learned in this class and by doing this project will be very beneficial in my other classes, as I continue onto nursing school, and then after graduation in many aspects of life. From budgeting, to working as a nurse, and many other ways. Real world math problems are things we deal with every day and many people don’t even realize it. They can be anything from determining how many mile per gallon of gas your car gets to deciding which product to buy at the store. A project such as this opens my mind of thinking about real world math problems and hopefully I will recognize next time I am using the different skills I used in this project and apply them to the real world.