Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
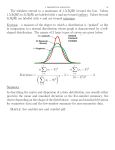
Chapter 1 Introduction • Individual: objects described by a set of data (people, animals, or things) • Variable: Characteristic of an individual. It can take on different values for different individuals. Examples: age, height, gender, favorite class, speed, moisture, etc. Types of Variables • Quantitative: numerical values, can be added, subtracted, averaged, etc. – ________: takes on values which are spaced. That is, for two values of a discrete variable that are adjacent, there is no value that goes between them. – ________: values are all numbers in a given interval. That is, for two values of a continuous variable that are adjacent, there is another value that can go between the two. • Categorical: An individual is placed into one of several groups or categories. These groups or categories are not usually numerical. Types of Variables Examples: Variable Length Hours Enrolled Major Zip Code Numeric Discrete Continuous Categorical Distribution of a Variable • The distribution of a variable tells us the possible values for the variable and the probability that the variable takes these values. • Two ways to describe a distribution – Numerically – Graphically Categorical Variables • Suppose we poll 46 people on an issue. How can we exhibit their response? • Numerically: – Counts – Proportions – Percentages • Graphically: – Frequency Tables – Bar Charts – Pie Charts Categorical Variables • Suppose we poll 46 people on an issue. How can we exhibit their response? – Frequency Tables: • counts (14 agree) • proportions (14/46 = .304 agree) • percents (30.4% agree) VOTE Valid agree disagree undecid. Total Frequency 14 23 9 46 Percent 30.4 50.0 19.6 100.0 Valid Percent 30.4 50.0 19.6 100.0 Cumulative Percent 30.4 80.4 100.0 Categorical Variables • Suppose we poll 46 people on an issue. How can we exhibit their response? – Bar Chart: 30 can have counts, percents or proportions on vertical axis 20 Count 10 0 agree VOTE disagree undecid. Categorical Variables • Suppose we poll 46 people on an issue. How can we exhibit their response? – Pie Chart: undecid. agree disagree Examining a Distribution • To describe a distribution we need 3 items: – Shape: modes, symmetric, skewed – Center: mean, median – Spread: range, standard deviation, IQR • Look for the overall pattern and for striking deviations – Outlier-individual value that falls outside the overall pattern Numeric Variable Distributions Shape: Modes: Major peaks in the distribution Symmetric: The values smaller and larger than the midpoint are mirror images of each other Skewed to the right: Right tail is much longer than the left tail Skewed to the left: Left tail is much longer than the right tail Center: Mean: The arithmetic average. Add up the numbers and divide by the number of observations. Median: List the data from smallest to largest. If there are an odd number of data values, the median is the middle one in the list. If there are an even number of data values, average the middle two in the list Numeric Variable Distributions Spread: Range: The difference in the largest and smallest value. (Max – Min) Standard Deviation: Measures spread by looking at how far observations are from their mean. The computational formula for the standard deviation is s 1 2 ( x x ) i n 1 Interquartile Range (IQR): Distance between the first quartile (Q1) and the third quartile (Q3). IQR = Q3 – Q1 Q1 – 25% of the observations are less than Q1 and 75% are greater than Q1. Q3 – 75% of the observations are less than Q3 and 25% are greater than Q3. Numeric Variable Distributions • Example 1.5 on page 11 of the book shows how much 50 consecutive shoppers spent in a store. The data appear as follows: $3.11 $18.30 $24.50 $36.30 $50.30 $8.88 $18.40 $25.10 $38.60 $52.70 $9.26 $19.20 $26.20 $39.10 $54.80 $10.80 $19.50 $26.20 $41.00 $59.00 $12.60 $19.50 $27.60 $42.90 $61.20 $13.70 $20.10 $28.00 $44.00 $70.30 $15.20 $20.50 $28.00 $44.60 $82.70 $15.60 $22.20 $28.30 $45.40 $85.70 $17.00 $23.00 $32.00 $46.60 $86.30 $17.30 $24.40 $34.90 $48.60 $93.30 Numerical Variables • How can we describe the distribution of these 50 numbers? – Numerically • Center: Mean or Median • Spread: Quartiles, Range, IQR, or Standard deviation – Graphically • • • • • Frequency Table Histogram Boxplot Stem and Leaf Normal Quantile Plot Descriptive statistics The descriptives box from SPSS gives the mean, median, variance, standard deviation, minimum, maximum, range, and IQR. Descr iptives Mean 95% Confidence Interval for Mean 5% Trim m ed Mean Median Variance Std. Deviation Minim um Maxim um Range Interquarti le Range Skewness Kurtos is Lower Bound Upper Bound Statis tic 34.6550 28.4891 Std. Error 3.0682 40.8209 33.1929 27.8000 470.704 21.6957 3.11 93.3 90.2 26.7000 1.104 .711 .337 .662 Percentiles • 50th percentile is also called the median – the middle data value if ordered smallest to largest • 25th and 75th percentiles are also called the quartiles: Q1 and Q3 respectively – the middle data value of each half Percentiles 5 Weighted Average(Definition 1) Tukey's Hinges 9.0890 10 25 Percentiles 50 12.7100 19.0000 27.8000 45.7000 19.2000 27.8000 45.4000 75 90 95 69.3900 85.9700 Frequency Table – Notice the amount spent is broken into categories or groups – Recall, frequency tables can be used for categorical variables as well Category Count or Frequency Percent 0 - 10 3 6.00% 10 - 20 12 24.00% 20 - 30 13 26.00% 30 - 40 5 10.00% 40 - 50 7 14.00% 50 - 60 4 8.00% 60 - 70 1 2.00% 70 - 80 1 2.00% 80 - 90 3 6.00% 90 - 100 1 2.00% Histogram – Breaks the range of values of a variable into intervals (midpoint is displayed here) – Displays only the count or percent of the observations that fall into each interval 14 12 10 8 6 4 2 0 5 15 25 35 45 55 65 75 85 95 Box Plot Minimum, Q1, Median, Q3, and Maximum 100 50 These five numbers 80 are called the ____________________ 60 49 48 40 What are these points? 20 0 -20 N= 50 Stem and Leaf Plot • Works best for smaller data sets – Example 1.4 on pg 10 • Here are the numbers of homeruns that Babe Ruth hit in each of his 15 years with the New York Yankees from 1920-1934: – 54, 59, 35, 41, 46, 25, 47, 60, 54, 46, 49, 46, 41, 34, 22 Normal Quantile Plot – Normal Quantile Plot (This compares the distribution of the sample to the Normal Normal Q-Q Plot of Distribution): 100 the straight line Expected Normal Value is normal, compare dots to the line If dots fall close to the normal line then the data comes from a normal distribution. 80 60 40 20 0 -20 -20 0 Observed Value 20 40 60 80 100 Describing Numeric Variable Distributions • Now, we examine the appearance of other data: – Modes are major peaks in the distribution The histogram below has two modes-bimodal The histogram below has one mode-unimodal 20 14 12 10 8 10 6 4 Std. Dev = 1. Std. Dev = 2.67 2 Mean = 5.1 Mean = 5.4 N = 59.00 0 1.0 DATA 2.0 3.0 4.0 5.0 6.0 7.0 8.0 9.0 N = 60.00 0 1.0 DATA 2.0 3.0 4.0 5.0 6.0 7.0 8.0 9.0 Describing Numeric Variable Distributions • Now, we examine the appearance of other data: – This example is called right skewed since the distribution has a long right tail. This is an example of a boxplot that is skewed to the _______. 20 40 12 39 10 Count 35 8 31 0 4 0 4.00 8.00 12.00 data 16.00 -10 N= 46 DATA Describing Numeric Variable Distributions • ________: observations that are unusually far from the bulk of the data. • What are some possible explanations for outliers? – The data point was recorded wrong. – The data point wasn’t actually a member of the population we were trying to sample. – We just happened to get an extreme value in our sample. • The 1.5 x IQR Criterion for Outliers: Designate an observation a suspected outlier if it falls more than 1.5 x IQR below the first quartile or above the third quartile. 1.5*IQR Criterion Example • Suppose you had the following data set: -2, 15, 3, 7, 10, 21, 1, 5, 12, 8, 1, 35, 10 List data from smallest to largest: Find Q1, Median, Q3, Min, and Max: IQR = Q3 – Q1 = ______ 1.5*IQR = _______ Q1 – 1.5*IQR = ________If less than this number, then outlier Q3 + 1.5*IQR = ________If more than this number, then outlier Are there any outliers in this data set? Describing Numeric Variable Distributions • Symmetry versus Skewness: 14 15 6 12 Count Count 10 4 8 10 6 2 5 4 Std. Dev = 3.68 2 Mean = 8.4 0 4.00 8.00 12.00 N = 41.00 0 16.00 2.0 4.0 6.0 8.0 10.0 12.0 14.0 16.0 18.0 data 0 0.00 __________ 20 5.00 10.00 _________ 20 ___________ 20 17 16 10 10 10 0 0 0 -10 N= -10 48 DATA N= 15.00 data DATA -10 41 DATA N= 73 DATA Mean versus Median: • For a skewed distribution, the mean is farther out in the longer tail than is the median. 14 15 12 6 Count 10 Count 8 4 10 6 5 4 2 Std. Dev = 3.68 2 Mean = 8.4 N = 41.00 0 2.0 4.0 6.0 8.0 10.0 12.0 14.0 16.0 18.0 0 4.00 8.00 12.00 16.00 0 0.00 DATA 5.00 10.00 15.00 data data Symmetric Left Skewed Right Skewed 20 20 20 17 16 10 10 10 0 0 0 -10 N = -10 N = 41 DATA 48 DATA N = 73 DATA mean<median To describe distributions use: Median and IQR -10 mean=median Mean and standard deviation mean>median Median and IQR Strategy for Exploring Data on a Single Quantitative Variable 1) Always plot your data: make a graph usually a stem and leaf or histogram 2) Look for overall pattern and for outliers 3) Calculate an appropriate numerical summary to briefly describe center and spread 4) Sometimes the overall pattern of a large number of observations is so regular that it can be described by a smooth curve Introducing the Normal Distribution It is customary to describe a normal distribution in the following way: N m ,s Properties of the Normal Distribution: 1) Symmetric, bell-shaped 2) Mean, μ and standard deviation, σ 3) Area under the curve is 1 s m 2 The Normal Distribution Normal distributions can take on many different means and standard deviations. Only the general bell shape must remain the same. Here are some examples of normal distributions: m=0 s1 m=3 s2 0 3 N 0,1 N 3,2 2 m = -2 s 0.5 -2 N 2,0.52 Distribution Properties • Introducing: The Standard Normal Distribution Properties: 1. _________________ 2. _________________ 3. _________________ Distribution Properties • Empirical Rule (The 68-95-99.7 Rule): If the distribution is normal, then – Approximately 68% of the data falls within one standard deviation of the mean – Approximately 95% of the data falls within two standard deviations of the mean – Approximately 99.7% of the data falls within three standard deviations of the mean Distribution Properties Empirical Rule Percentiles of a Standard Normal Curve Empirical Rule Example • If the grades on an exam are normally distributed with a mean of 68 and a variance of 16, what grade do you have to make to be in the top 15% of the class? Distribution Properties • Shift Changes: adding or subtracting a number from the each of the values. mean mean + c mean - c Distribution Properties • The mean, median, Q1, Q3, minimum, and maximum all shift when there is a shift change. The shift change, say c, is added or subtracted to each of the statistics accordingly. • The measures of spread (standard deviation, variance, IQR, and range) do not change when there is a shift change. Distribution Properties • Scale Changes: multiplying or dividing each of the values by a number. mean Distribution Properties • Scale Changes: multiplying or dividing each of the values by a number. mean*c Distribution Properties • Scale Changes: multiplying or dividing each of the values by a number. mean/c Distribution Properties • The mean, median, Q1, Q3, minimum, and maximum all change when there is a scale change unless they are zero. Each is multiplied or divided by the scale change c. • The measures of spread (standard deviation, variance, IQR, and range) always change when there is a scale change. The standard deviation, IQR, and range are multiplied or divided by the scale change c. The variance is multiplied or divided by c2. Shift Change Example • Suppose we measure the weight of everyone on a football team and obtain the following statistics for a team report: – – – – – Mean: 230 lbs. Std. Dev.: 50 lbs. Variance: 2500 sq. lbs. Min.: 170 lbs. Max.: 350 lbs. Median: 240 lbs. Q1: 200 lbs., Q3: 280 lbs. IQR: 80 lbs Range: 180 lbs. Shift Change Example • Now suppose we found out the scale was 10 lbs. under so we need to add 10 lbs. to every weight. What would happen to each of the following statistics? Original Mean: 230 lbs. Median: 240 lbs. s: 50 lbs. Q1: 200 lbs. Q3: 280 lbs. After Shift Change Mean:________ Median:_________ s:_______ Q1:________ Q3:________ Shift Change Example • Now suppose we found out the scale was 10 lbs. under so we need to add 10 lbs. to every weight. What would happen to each of the following statistics? Original Variance: 2500 sq. lbs. IQR: 80 lbs. Min: 170 lbs. Max: 350 lbs. Range: 180 lbs. After Shift Change Variance: ________ IQR: _________ Min: _________ Max: _________ Range: _________ Shift and Scale Change Example • Further, suppose we found out that we are supposed to report the weights and statistics in kilograms, not lbs (Remember, 1 lb = 0.6 kilograms). What would happen to each of the following statistics? After Shift Change Mean: 240 lbs. Median: 250 lbs. s: 50 lbs. Q1: 210 lbs. Q3: 290 lbs. After Shift and Scale Change Mean: ______________ Median: ______________ s: _____________ Q1: _____________ Q3: _____________ Shift and Scale Change Example • Further, suppose we found out that we are supposed to report the weights and statistics in kilograms, not lbs (Remember, 1 lb = 0.6 kilograms). What would happen to each of the following statistics? After Shift Change Variance: 2500 sq. lbs. IQR: 80 lbs. Min: 180 lbs. Max: 360 lbs. Range: 180 lbs. After Shift and Scale Change Variance: _______________ IQR: _______________ Min: _______________ Max: ________________ Range: _________________ x Linear Transformations If you are given a mean, x (or m), and a standard deviation, s (or s), and want to convert your data so you have a new mean, xnew (or mnew), and new standard deviation, snew (or snew), all you need is to remember what shift and scales changes affect. • In our linear transformation formula: xnew a bx • – a is the shift change – b is the scale change • Standard deviation are only affected by scale changes, but means are affected by both shift and scales changes. snew scale * s xnew shift scale * x Linear Transformation Example • For example: x = 12 and s = 7 but we want xnew = 25 and snew = 10. snew = scale*s 10 = scale*7 scale = 10/7 scale = 1.43 • substituting in: xnew = shift + scale* x 25 = shift + 1.43*12 shift = 25 1.43*12 shift = 7.84 • So our linear transformation equation is: x new = 7.84 + 1.43*x