Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
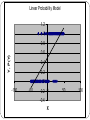
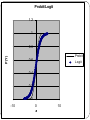
Logit and Probit Models with Discrete Dependent Variables Why Do We Need A Different Model Than Linear Regression? Appropriate estimation of relations between variables depends on selecting an appropriate statistical model. There are many different types of estimation problems in political science. Continuous variables where the experiment can be viewed as draws from a normal distribution. Continuous Variables where the experiment is draws from some other distribution. Continuous Variables where the distribution is truncated or censored. Discrete Variables - For example, we might model labor force participation, whether to vote for or against, purchase or not purchase, run for office or not run for office, etc. Models of this type are sometimes called qualitative response models, because the dependent variables are discrete, rather than continuous. There are several types of such models including the following. Type of Qualitative Response Models Qualitative dichotomy (e.g., vote/not vote type variables)- We equate "no" with zero and "yes" with 1. However, these are qualitative choices and the coding of 0-1 is arbitrary. We could equally well code "no" as 1 and "yes" as zero. Qualitative multichotomy (e.g., occupational choice by an individual)- Let 0 be a clerk, 1 an engineer, 2 an attorney, 3 a politician, 4 a college professor, and 5 other. Here the codings are mere categories and the numbers have no real meaning. Rankings (e.g., opinions about a politician's job performance)- Strongly approve (5), approve (4), don't know (3), disapprove (2), strongly disapprove (1). The values that are chosen are not quantitative, but merely an ordering of preferences or opinions. The difference between outcomes is not necessarily the same from 5 to 4 as it is from 2 to 1. Count outcomes. Dichotomous Dependent Variables There are various problems associated with estimating a dichotomous dependent variable under assumptions of a statistical experiment that draws from a normal distribution, i.e., using regression. Obviously the statistical experiment is not draws from a normal distribution, but from something called a Bernoulli distribution. Thus, estimation is likely to be inefficient. It is also theoretically inconsistent with the nature of the statistical experiment. The dependent variable is discrete and truncated on both ends at 0 and 1. This leads to a number of other serious problems. Consider first, a graph of the data in a typical sample of Bernoulli experiments. Linear Probability Model 1.2 1 0.8 Y, P(Y) 0.6 0.4 0.2 0 -100 -50 -0.2 0 -0.4 X 50 100 Note that a linear regression line through the actual data cuts through the data at the point of greatest concentration on each end. The residuals from this regression line will only be close to the regression line if the X variable is also Bernoulli distributed. This means that measures of fit or hypothesis tests involving the squared errors will be silly. The regression line will seldom lie near the data. Linear Probability Model 1.2 1 0.8 Y, P(Y) 0.6 0.4 0.2 0 -100 -50 -0.2 0 -0.4 X 50 100 Relatedly, this feature also means that the residuals from the linear model will be dichotomous and heteroskedastic, rather than normal, raising questions about hypothesis tests. When y=1, the residual will depend on X and be: When y=0, the residual will depend on X and be: This means that the residuals from the linear probability model will be heteroskedastic and have a dichotomous character. Note that the residuals change systematically with the values of X. This implies what it termed endogeneity. They are also not distributed normally. We could "fix" this problem by estimating the linear probability model using weighted least squares. However, the problem with this model runs deeper. We must be able to interpret results from this model as expected values of probabilities. However, the graph below suggests further problems. Observe that some of the probabilities lie above 1 and below zero. This is not consistent with the rules of probability. We could truncate the model at 0 and 1 to "fix" this problem. However, note that probability, according to this model, is alleged to change in linear fashion with changes in X. Yet, this may not be consistent with reality in many real world situations. For example, consider the probability of home ownership as a function of income. Suppose we have prospective buyers with income around 10k per year. If we change their income by 1k, how much does the probability that they will buy a home change? Suppose we have prospective buyers with income around 30k. If we change their income by 1k, how much does the probability that they will own a home change? Suppose we have prospective buyers with income around 80k. If we change their income by 1k, how much does the probability that they will own a home change? In practice, there are many situations where the probability of a yes outcome follows an S shaped distribution, rather than the linear distribution alleged by the linear probability model. Non-Linear Probability Models To begin, assume the appropriate statistical experiment. The statistical experiment is draws from a Bernoulli distribution. The probability model from the Bernoulli distribution is given: f ( y | p) p yi (1 p)1 yi where p is a parameter reflecting the probability that y=1. The issue then becomes how to specify the probability that y=1. We noted above that this probability often follows an S shaped distribution. In other words, the probability that y=1 remains small until some threshold is crossed, at which point it switches rapidly to remain large after the threshold. This suggests a cumulative density function. Two different cumulative density functions are commonly used in this situation: the cumulative standard normal distribution (probit) and the cumulative logistic distribution (logit). Probit- The cumulative standard normal density is given: t P(Y 1) 1 e 2 Z2 2 dt ( z ) z 1 2 X ki ... k X ki Logit- The cumulative logistic function for logit is grounded in the concept of an odds ratio. Let the log odds that y=1 be given: P ln 1 2 X ki ... k X ki z 1 P Then solving for the probability that y=1 we have: P ez 1 P P (1 P )e z e z Pe z P Pe z e z P (1 e z ) e z ez P 1 ez Probit/Logit 1.2 1 0.8 P(Y) Probit 0.6 Logit 0.4 0.2 0 -10 0 z 10 Choosing Between Logit/Probit- In the dichotomous case, there is no basis in statistical theory for preferring one over the other. In most applications it makes no difference which one uses. If we have a small sample the two distributions can differ significantly in their results, but they are quite similar in large samples. Various R2 measures have been devised for Logit and Probit. However, none is a measure of the closeness of observations to an expected value as in regression analysis. All are ad hoc. Hypothesis testing t or z test- We can test the significance of the individual coefficients simply using the point estimates and standard errors (square roots of the diagonal elements of the asymptotic covariance matrix of estimates). Form a z or t test by taking t N k ˆ k k 0 s ˆ k Confidence Intervals Interpretation Interpreting Dichotomous Logit and Probit Coefficients- The actual coefficients in a logit or probit analysis are limited in their immediate interpretability. The signs are meaningful, but the magnitudes may not be, particularly when the variables are in different metrics. Above all, note that you cannot interpret the coefficients directly in terms of units of change in y for a unit change in x, as in regression analysis. There are various approaches to imparting substantive meaning into logit and probit results, including: Probability Calculations Graphical methods First differences First Partial derivatives.