Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Supercomputer architecture wikipedia , lookup
Computer cluster wikipedia , lookup
Error detection and correction wikipedia , lookup
Abstraction (computer science) wikipedia , lookup
K-nearest neighbors algorithm wikipedia , lookup
Reactive programming wikipedia , lookup
Stream processing wikipedia , lookup
CSCI5570 Large Scale Data
Processing Systems
Distributed Data Analytics Systems
James Cheng
CSE, CUHK
Slide Ack.: modified based on the slides from Matei Zaharia
Resilient Distributed Datasets: A Fault-Tolerant
Abstraction for In-Memory Cluster Computing
Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur
Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
Scott Shenker, and Ion Stoica
NSDI 2012
2
Motivation
• MapReduce greatly simplified “big data”
analysis on large, unreliable clusters
• But as soon as it got popular, users wanted
more:
– More complex, multi-stage applications
(e.g. iterative machine learning & graph processing)
– More interactive ad-hoc queries
Response: specialized frameworks for some of
these apps (e.g. Pregel for graph processing)
3
Motivation
• Complex apps and interactive queries require reuse
of intermediate results across multiple computations
(common in iterative ML, DM, and graph algorithms)
• Thus, need efficient primitives for data sharing
MapReduce lacks abstraction for leveraging
distributed memory
The only way to share data across jobs is stable
storage slow!
4
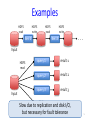
Examples
HDFS
read
HDFS
write
HDFS
read
iter. 1
HDFS
write
. . .
iter. 2
Input
HDFS
read
Input
query 1
result 1
query 2
result 2
query 3
result 3
. . .
Slow due to replication and disk I/O,
but necessary for fault tolerance
5
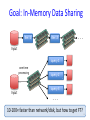
Goal: In-Memory Data Sharing
iter. 1
iter. 2
. . .
Input
query 1
one-time
processing
Input
query 2
query 3
. . .
10-100× faster than network/disk, but how to get FT? 6
Challenge
How to design a distributed memory abstraction
that is both fault-tolerant and efficient?
7
Challenge
• Existing storage abstractions have interfaces
based on fine-grained updates to mutable
state
– RAMCloud, databases, distributed mem, Piccolo
• Requires replicating data or logs across nodes
for fault tolerance
– Costly for data-intensive apps
– 10-100x slower than memory write
8
Solution: Resilient Distributed
Datasets (RDDs)
• Restricted form of distributed shared memory
– Immutable, partitioned collections of records
– Can only be built through coarse-grained deterministic
transformations (map, filter, join, …)
• Efficient fault recovery using lineage
– Log transformations used to build a dataset (i.e., its
lineage) rather than the actual data
– If a partition of an RDD is lost, the RDD has enough
info about how it was derived from other RDDs in
order to recompute the partition
9
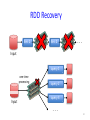
RDD Recovery
iter. 1
iter. 2
. . .
Input
query 1
one-time
processing
Input
query 2
query 3
. . .
10
Generality of RDDs
• Despite their restrictions, RDDs can express
surprisingly many parallel algorithms
– These naturally apply the same operation to many
items
• Unify many current programming models
– Data flow models: MapReduce, Dryad, SQL, …
– Specialized models for iterative apps: BSP (Pregel),
iterative MapReduce (Haloop), bulk incremental, …
• Support new apps that these models don’t
11
What RDDs are good and not good for
• Good for:
– batch applications that apply the same operation
to all elements of a dataset
– RDDs can efficiently remember each
transformation as one step in a lineage graph
– recovery of lost partitions w/o having to log large
amounts of data
• Not good for:
– applications that need asynchronous fine-grained
updates to shared state
12
Tradeoff Space
Network
bandwidth
Fine
Granularity
of Updates
Memory
bandwidth
Best for
transactional
workloads
K-V
stores,
databases,
RAMCloud
Best for batch
workloads
HDFS
RDDs
Coarse
Low
Write Throughput
High
13
How to represent RDDs
• Need to track lineage across a wide range of
transformations
• A graph-based representation
• A common interface w/:
– a set of partitions: atomic pieces of the dataset
– a set of dependencies on parent RDDs
– a function for computing the dataset based on its
parents
– metadata about its partitioning scheme and data
placement
14
RDD Dependencies
• Narrow dependencies: each partition of the
parent RDD is used by at most one partition of
the child RDD
Good for pipelined execution
on one cluster node, e.g.,
apply a map followed by a
filter on an element-byelement basis.
Efficient recovery as only the
lost parent partitions need to
be recomputed (in parallel on
different nodes).
15
RDD Dependencies
• Wide dependencies: each partition of the
parent RDD is used by multiple child partitions
Require data from all parent
partitions to be available and
to be shuffled across the
nodes using a MapReducelike operation.
Expensive recovery, as a
complete re-execution is
needed.
16
Outline
Spark programming interface
Implementation
How people are using Spark
17
Outline
Spark programming interface
Implementation
How people are using Spark
18
Spark Programming Interface
• DryadLINQ-like API in the Scala language
• Used interactively from the Scala interpreter
• Provides:
– Resilient distributed datasets (RDDs)
– Operations on RDDs: transformations & actions
– Control of each RDD’s partitioning (layout across
nodes) and persistence (storage in RAM, on disk, etc)
19
Spark Programming Interface
• Transformations
– lazy operations that define new RDDs
• Actions
– launch a computation to return a value to the
program or write data to external storage
20
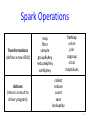
Spark Operations
Transformations
(define a new RDD)
Actions
(return a result to
driver program)
map
filter
sample
groupByKey
reduceByKey
sortByKey
flatMap
union
join
cogroup
cross
mapValues
collect
reduce
count
save
lookupKey
21
Spark Operations
22
Programming in Spark
• Programmers start by defining one or more
RDDs through transformations on data in stable
storage (e.g., map, filter)
• The RDDs can then be used in actions (e.g.,
count, collect, save)
• Spark computes RDDs (lazily) the first time they
are used in an action
23
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
BaseTransformed
RDD
RDD
results
errors = lines.filter(_.startsWith(“ERROR”))
messages = errors.map(_.split(‘\t’)(2))
messages.persist()
tasks
Master
Msgs. 1
Worker
Block 1
Action
messages.filter(_.contains(“foo”)).count
Msgs. 2
messages.filter(_.contains(“bar”)).count
Worker
Msgs. 3
Result:Result:
full-text
scaled
search
to 1ofTB
Wikipedia
data in 5-7
in <1
secsec (vs
(vs20
170
secsec
forfor
on-disk
on-disk
data)
data)
Worker
Block 2
Block 3
24
Fault Recovery
• RDDs track the graph of transformations that
built them (their lineage) to rebuild lost data
E.g.:
messages = textFile(...).filter(_.contains(“error”))
.map(_.split(‘\t’)(2))
HadoopRDD
HadoopRDD
FilteredRDD
FilteredRDD
path = hdfs://…
func = _.contains(...)
MappedRDD
MappedRDD
func = _.split(…)
25
Iteratrion time (s)
Fault Recovery Results
140
120
100
80
60
40
20
0
Failure happens
119
81
1
57
56
58
58
57
59
57
59
2
3
4
5
6
Iteration
7
8
9
10
26
Example: PageRank
1. Start each page with a rank of 1
2. On each iteration, update each page’s rank to
Σi∈neighbors ranki / |neighborsi|
links = // RDD of (url, neighbors) pairs
ranks = // RDD of (url, rank) pairs
for (i <- 1 to ITERATIONS) {
ranks = links.join(ranks).flatMap {
(url, (links, rank)) =>
links.map(dest => (dest, rank/links.size))
}.reduceByKey(_ + _)
}
27
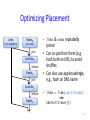
Optimizing Placement
Links
Ranks0
(url, neighbors)
(url, rank)
join
Contribs0
reduce
Ranks1
join
& ranks repeatedly
joined
• Can co-partition them (e.g.
hash both on URL) to avoid
shuffles
• Can also use app knowledge,
e.g., hash on DNS name
•
links
•
links = links.partitionBy(
new
URLPartitioner())
Contribs2
reduce
Ranks2
. . .
28
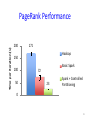
Time per iteration (s)
PageRank Performance
200
171
Hadoop
150
100
50
Basic Spark
72
23
Spark + Controlled
Partitioning
0
29
Behavior with Insufficient RAM
11.5
40
29.7
40.7
60
58.1
80
68.8
Iteration time (s)
100
20
0
0%
25%
50%
75%
Percent of working set in memory
100%
30
Scalability
87
106
121
150
157
200
143
250
Hadoop
HadoopBinMem
Spark
197
100
33
61
Iteration time (s)
300
3
50
6
15
50
80
100
76
62
116
184
Iteration time (s)
150
111
Hadoop
HadoopBinMem
Spark
250
200
K-Means
274
Logistic Regression
0
25
50
100
Number of machines
0
25
50
100
Number of machines
31
Outline
Spark programming interface
Implementation
How people are using Spark
32
Implementation
Runs on Mesos cluster
manager [NSDI 11] to share
clusters w/ Hadoop, MPI, etc.
Can read from any Hadoop
input source (HDFS, S3, …)
Spark
Hadoop
MPI
…
Mesos
Node
Node
Node
Node
33
Task Scheduler
Dryad-like DAGs
Pipelines functions
within a stage
Locality & data
reuse aware
Partitioning-aware
to avoid shuffles
B:
A:
G:
Stage 1
C:
groupBy
D:
F:
map
E:
Stage 2
join
union
Stage 3
= cached data partition
34
Programming Models Implemented
on Spark
• RDDs can express many existing parallel
models
– MapReduce, DryadLINQ
– Pregel graph processing [200 LOC]
– Iterative MapReduce [200 LOC]
– SQL: Hive on Spark (Shark)
All are based on
coarse-grained
operations
• Enables apps to efficiently intermix these
models
35
Outline
Spark programming interface
Implementation
How people are using Spark
36
Open Source Community
• User applications:
– Data mining 40x faster than Hadoop (Conviva)
– Exploratory log analysis (Foursquare)
– Traffic prediction via EM (Mobile Millennium)
– Twitter spam classification (Monarch)
– DNA sequence analysis (SNAP)
–...
37
Conclusion
• RDDs offer a simple and efficient programming
model for a broad range of applications
• Leverage the coarse-grained nature of many
parallel algorithms for low-overhead recovery
38