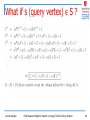Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Fast Nearest Neighbor Search
on Large Time-Evolving Graphs
Leman Akoglu
Rohit Khandekar
Deepak Rajan
Srinivasan Parthasarathy
Vibhore Kumar
Kun-Lung Wu
Graphs are everywhere…
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
3
…and LARGE and TIME-evolving!
n
1.32 billion monthly active users June 30, 2014
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
4
Proximity problem on graphs
also: NN-search, similarity, closeness, relevance
Q: Which nodes are “close” to A? I
1
J
1
A
1
1
1
H
BB
1
1
D
1 1 1
E
G
F
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
5
Application: Recommendations
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
6
Other applications
•
•
•
•
•
•
•
Finding communities (e.g. co-authorship
networks such as DBLP)
Anomaly detection (e.g. infected hosts,
potential suspects)
Link Prediction
Keyword search
Content-based Image Retrieval
Fighting spam
…
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
7
Proximity measures for graphs
n
n
Several metrics: shortest paths, commute time,
hitting time, SimRank, …
Prevalent (robust) metric: Personalized PageRank
I
1
J
1
A
1
1
H
1
1
B
1
D
PPR captures:
- many,
- short,
- heavy-weighted paths
1 1 1
E
G
F
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
8
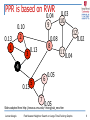
PPR is based on RWR
0.04
9
0.10
2
0.13
1
3
0.08
8
0.13
4
0.13
6
5
7
0.03
10
12
0.02
11
0.04
0.05
0.05
Slides adapted from http://www.cs.cmu.edu/~htong/pub_new.htm
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
9
Problem Definition
Maintain –
ing
A LARGE, time-‐vary
, edge-‐weighted graph G(t), so that we can answer the following query efficiently: Given a query node q in G(t) at Fme t, Find verFces in G(t) that are “close” to q (w.r.t. the Personalized PageRank score) Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
10
Road Map
n
n
n
n
Motivation
Problem Definition
Previous work
Our Approach
q
q
n
n
n
Graph clustering
Intra-Cluster & Inter-Cluster Random Walks
(baby steps & BIG steps)
Time-Varying Graphs
Experiments
Conclusions
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
11
Previous Work on PPR
n
n
n
n
n
n
n
n
D. Fogaras, B. Rcz, K. Csalogny, Tams Sarls. Towards scaling fully
personalized pagerank. In Internet Mathematics 2004.
Hanghang Tong, Christos Faloutsos, and Jia-Yu Pan. Fast Random Walk with
Restart and Its Applications. In ICDM 2006.
Soumen Chakrabarti. Dynamic personalized pagerank in entity-relation
graphs. In WWW 2007.
H. Tong, S. Papadimitriou, P. S. Yu and C. Faloutsos. Proximity Tracking on
Time-Evolving Bipartite Graphs. In SDM 2008.
P. Sarkar, A. W. Moore. Fast nearest-neighbor search in disk-resident graphs.
In KDD 2010.
Bahman Bahmani, Abdur Chowdhury, Ashish Goel: Fast Incremental and
Personalized PageRank. In PVLDB 2010.
Bahman Bahmani, Kaushik Chakrabarti, Dong Xin: Fast personalized
PageRank on MapReduce. In SIGMOD 2011.
P. A Lofgren, S. Banerjee, A. Goel, C. Seshadhri. FAST-PPR: Scaling
Personalized PageRank Estimation for Large Graphs. In KDD 2014.
We consider both large AND time-varying graphs!
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
12
Our Method – ClusterRank
1) Pre-computation
a. Graph clustering
b. Compute meta-info for each cluster
2) Query processing
a. Identify relevant clusters to consider
b. Combine their meta-info to compute
an answer
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
13
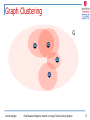
Graph Clustering
n
n
We work with large graphs (that do not fit in
main memory), thus cluster vertices such that
each cluster is “small enough”.
Need “good” clusters—many intra-cluster edges,
but few inter-cluster edges.
q
q
Random walks more likely to stay within cluster
Good cluster is already a good approximation of
“close” neighborhood of vertices in cluster
Note: For some cases, graph could be clustered
naturally (e.g. Web graph across many servers)
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
14
Graph Clustering
n
Many graph clustering algorithms, e.g. based on
community detection, spectral partitioning, etc.
Reid Andersen, Fan Chung, and Kevin Lang (ACL).
Local Graph Partitioning using PageRank Vectors.
FOCS, 2006.
n
Advantages:
n
q
q
q
Local algorithm–complexity depends on output
cluster size
Gives different size clusters which can be overlapping
Can do clustering while graph is on disk
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
15
What is “good” clustering?
ACL [FOCS06]’s measure is conductance:
ϵ [0, 1]
Φ = 3 / (4+3+4+4+2) = 0.17
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
16
Graph Clustering
G
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
17
Our Method – ClusterRank
1) Pre-computation
a. Graph clustering
b. Compute meta-info for each cluster
2) Query processing
a. Identify relevant clusters to consider
b. Combine their meta-info to compute
an answer
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
18
Compute meta-info for each cluster
C(u,v) : The expected number of times (Count) a RW
starting at node u in cluster S hits node v, before exiting S
(can exit by walking to another cluster or by restarting to q).
E(u,v) : Expected probability that a RW starting at node u in
cluster S Exits S to node v (out-bound node in B)
(assuming query (restart) vertex q is outside S).
C matrix for S
is 5x5 (|S| x |S|)
E matrix is
5x3 (|S| x 2|B|+|q|)
S
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
19
Compute meta-info for each cluster
Intra-cluster random-walks à baby steps
S3
S2
q
S4
Leman Akoglu
S1
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
20
Compute meta-info for each cluster
Recursive definition for C
T(u, v) :
N(u) :
(1 − α) :
S:
Leman Akoglu
transition probability from u to v
neighbor nodes set of node u
restart probability
set of nodes in given cluster
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
21
Compute meta-info for each cluster
Closed-form formulae for C and E
Similarly,
: |S| x |S| transition matrix
: |S| x (|B|+1) matrix with exit prob.s
to nodes in B U {q}
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
22
Our Method – ClusterRank
1) Pre-computation
OFFLINE
a. Graph clustering
b. Compute meta-info for each cluster
ONLINE
2) Query processing
a. Identify relevant clusters to consider
b. Combine their meta-info to compute
an answer
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
23
Query processing
Update meta-info for q’s cluster
Cq (C given q) :
Eq (E given q) : Cq
K : |S|x|S| 0s matrix with column q all 1s (rank 1!)
à Fast Sherman-Morrison matrix inverse update
Recall:
Leman Akoglu
Closed-form formulae for C and E
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
24
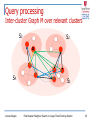
Query processing
Inter-cluster Graph M over relevant clusters
S3
S2
q
S4
Leman Akoglu
S1
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
25
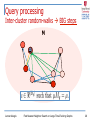
Query processing
Inter-cluster random-walks à BIG steps
M
q
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
26
Query processing
Combine intra- and inter- cluster meta-info
to compute final answer (“lift” C matrices)
S3
S4
Leman Akoglu
S2
S1
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
27
Query processing
Combine intra- and inter- cluster meta-info
to compute final answer (“lift” C matrices)
S3
S4
Theorem:
Leman Akoglu
S2
S1
ClusterRank gives exact PPR scores.
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
28
Road Map
n
n
n
n
Motivation
Problem Definition
Previous work
Our Approach
q
q
n
n
n
Graph clustering
Intra-Cluster & Inter-Cluster Random Walks
(baby steps & BIG steps)
Time-Varying Graphs
Experiments
Conclusions
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
29
Time-varying ClusterRank
n
n
WLOG: assume single edge (u,v) added
Observation: changes in &
low-rank
à compute new C & E by SM formula
n
4 cases studied in paper:
q
q
q
q
Both u and v new vertices
Either u or v is a new vertex
u and v in same cluster
u and v in different clusters
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
30
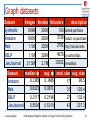
Graph datasets
Dataset
#edges #nodes #clusters
description
Synthetic
909K
300K
Amazon
900K
262K
100 Planted partitions
3739 Product co-purchase
Web
1.1M
325K
2793 http://nd.edu links
DBLP
1.1M
329K
4670 Co-authorships
21.5M
2.7M
LiveJournal
Dataset
median Φ
0.1385
Amazon
15252 Friendships
avg. Φ med. size avg. size
0.1486
98.5
17
Web
0.0625
0.0871
31
129.4
DBLP
0.2117
0.2196
27
102.4
LiveJournal
0.5500
0.5319
43
237.3
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
31
Pre-computation
Pre-computation time depends on 1) graph size,
2) #clusters, 3) parallelization
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
32
Query Processing: set up
n
n
n
n
Instead of all clusters, focus on a subset of
relevant clusters (small neighborhoods
around query vertex) (1,2-hop away).
Allow for maximum of B boundary vertices
Sparsify inter-cluster matrix: zero-out
entries close to zero
100 randomly chosen query vertices
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
33
Evaluation criterion
n
n
We report accuracy and running time
for k nearest neighbor (kNN) queries.
Accuracy = Relative Average Goodness (RAG)
score @k
total true score of output
RAG(@k) =
total true score of “optimum”
Note: precision, i.e. “overlap with optimum”, is *not* a good
measure (due to ties/near-ties).
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
34
Synthetic graphs
SYNTHETIC
2-HOP
1-HOP
Average RAG (50) score (100 runs)
B = 5K
0.9986
0.9865
B = 1K
0.9892
0.9865
ClusterRank
Average Response Time (sec.)
B = 5K
5.12
2.18
B = 1K
2.86
2.12
Brute-Force
Leman Akoglu
5.16 sec.s
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
35
Real graphs
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
36
Dynamic updates
n
500K edge DBLP graph + 1K new edges Avg: 42.12 seconds
Avg: 2.78 clusters
Note: load/store time of C, E matrices included
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
37
Dynamic updates
DBLP
1959-2001
+1K edges
in time
+500K edges
in time
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
38
Summary
n ClusterRank:
k Nearest Neighbor queries
based on Personalized Pagerank scores
Works with large and time-evolving graphs
q Fast query time: sub-linear computation on
pre-computed meta-info
q Efficient dynamic updates by low-rank matrices
q Disk-based: query processing and dynamic
updates only on relevant subset of clusters
q
n
Future directions
q
q
Cluster tracking and localized re-clustering
Extension to hitting / commute time
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
39
Thank You!
[email protected]
http://www.cs.stonybrook.edu/~leman
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
40
Back-up Slides
Recursive definition for E
T(u, v) :
N(u) :
(1 − α) :
S:
Leman Akoglu
transition probability from u to v
neighbor nodes set of node u
restart probability
set of nodes in given cluster
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
42
Closed formulations for C and E
C1 is an identity matrix of |S|x|S|
Similary,
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
43
What if s (query vertex) ϵ S ?
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
44
At query time, given the query vertex s, those two
matrices in which s resides in is updated only.
K is rank 1! Therefore, we will use the
Sherman-Morrison Lemma to update C.
Complexity: Multiplication of |S|x1 and 1x|S| vectors
Note that we do not need to run SVD as K is rank-1 only!
Leman Akoglu
Fast Nearest Neighbor Search on Large Time-Evolving Graphs
45