Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
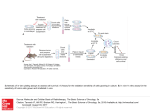
From structural data to in vivo toxicity prediction: a challenge for machine learning Ingrid Grenet, Jean-Paul Comet, David Rouquie 21.06.2017 Introduction Toxicology studies To assess the risk of a compound of being toxic by performing studies on laboratory animals Mandatory for the marketing of chemical compounds Highly regulated by authorities Concerns Ethical (animal consuming) Economical (time consuming and expensive) Need for alternative solutions to assess chemical toxicity as early as possible COMPUTATIONAL METHODS ! 2 Introduction Different types of data available for a chemical compound: Compound structure In vitro assays In vivo studies Compound structure: information about molecular structure, allows to compute physico-chemical properties In vitro assays: tests performed cell based or cell free In vivo studies: performed on laboratory animals, from some days up to 2 years 3 Objective Compound structure In vitro assays In vivo studies ?! Use of machine learning methods to predict in vivo toxicity from the different types of data available Proposal: a two-stages approach linking structure to in vivo through in vitro data ; specific to an in vivo outcome 4 Machine learning principle Training Descriptors Learning algorithm Training set Output variable Prediction Test set 5 Descriptors Predictor Output prediction A two-stages approach for in vivo toxicity prediction from chemical structure Structure In vitro data In vivo data Assay 1 Assay 2 Assay 3 Assay k … Assay k’ Assay N SDF file Outcome of interest Prediction Correlation tests / selection filter Mol 1 Mol 2 … Mol 1 Mol n Mol 2 … Mol 1 Mol nMol 2 … Mol n Subset of assays Assay 2 Assay k … Assay k’ A1 A2 Ax 2 Model input Learning Assays Model B 1 Machine learning (LDA) Prediction QSAR (RF / Bayesian) New molecule Through Models A1, A2, ..., Ax 3 Prediction P1 Prediction P2 … Prediction Px Alert for the outcome Through Model B 4 6 Stage 1: prediction of in vivo outcomes from in vitro data 7 Stage 1: prediction of in vivo outcomes from in vitro data Selection of data related to the outcome of interest Selection of in vitro assays linked to an in vivo outcome Machine learning Based on Liu et al. (2015), Martin et al. (2011), Sipes et al. (2011) 8 Stage 1: prediction of in vivo outcomes from in vitro data Selection of data related to the outcome of interest Building of a n*m complete matrix (n molecules and m assays) Quality consideration In vitro – continuous variables Binary variable 9 Compound ID In vivo outcome Assay 1 Assay 2 … Assay m Cpd 1 0 … … … … Cpd 2 1 … … … … … … … … … … Cpd n 0 … … … … Stage 1: prediction of in vivo outcomes from in vitro data Selection of in vitro assays linked to an in vivo outcome Univariate feature selection - each assay is compared to the in vivo outcome using: Linear Pearson correlation test Student T-test Chi-square test (dichotomous) P-value Assay aggregation according to biological knowledge Compute new value for each group *Cutoff filter: if at least one of the 3 p-values is below a defined cutoff (5-10%) 10 < cutoff ? Yes Significant assay Aggregation No Non significant assay Stage 1: prediction of in vivo outcomes from in vitro data Machine learning 11 Input descriptors: results of in vitro assays previously selected (continuous) Output variable: in vivo outcome (binary) Learning algorithms: Linear discriminant analysis (LDA) Bayesian Performance metrics after crossvalidation: Sensitivity Specificity Balanced accuracy ROC score Model B Stage 2: prediction of in vitro activity from chemical structure 12 Stage 2: prediction of in vitro activity from chemical structure Descriptors generation and selection Machine learning approach – QSAR 13 Stage 2: prediction of in vitro activity from chemical structure Descriptors generation and selection Structure Data Files (SDF): chemical-file format with connectivity matrix Compute around 160 physico-chemical 1D and 2D features (e.g: molecular weight, number of atoms, number of bonds, etc) – continuous variable Removal of non-informative descriptors: 14 Variance close to 0 Highly correlated descriptors Stage 2: prediction of in vitro activity from chemical structure Machine learning approach - QSAR 15 One model / in vitro assay (group) Input descriptors: physico-chemical properties (continuous) Output variable: activity measured in the assay (binary) Learning algorithms: Random Forest Model A1 Bayesian Performance metrics after cross-validation: Sensitivity Specificity Balanced accuracy ROC score Model A2 Model A… Model Ax Connection of the two previous stages 16 Connection of previous stages 1) Prediction of in vitro bioactivities from molecular structure 2) Prediction of outcome (alert / flag) from predicted in vitro bioativities 17 A two-stages approach for in vivo toxicity prediction from chemical structure Structure In vitro data In vivo data Assay 1 Assay 2 Assay 3 Assay k … Assay k’ Assay N SDF file Outcome of interest Prediction Correlation tests / selection filter Mol 1 Mol 2 … Mol 1 Mol n Mol 2 … Mol 1 Mol nMol 2 … Mol n Subset of assays Assay 2 Assay k … Assay k’ A1 A2 Ax 2 Model input Learning Assays Model B 1 Machine learning (LDA) Prediction QSAR (RF / Bayesian) New molecule Through Models A1, A2, ..., Ax 3 Prediction P1 Prediction P2 … Prediction Px Alert for the outcome Through Model B 4 18 Conclusion Proposition of a two stages global approach to predict in vivo ouctome from structural descriptors Controlled by the in vivo outcome of interest Compound structure In vitro assays Impossible to develop a general model 19 In vivo studies Ongoing work and next steps Focus on specific outcomes: liver and endocrine related organs in the rat Public data gathering and preparation Implementation of model B (stage 1) Physico-chemical descriptors generated and selected (stage 2) Challenges: 20 Risk of lack of data in the first stage Choice of appropriate cutoff Assays aggregation Method evaluation and refinement Thank you for your attention 21 Bayesian classification principle Principle: for each sample 𝑋 having 𝑛 features 𝑥𝑘 and each class 𝐶𝑖 , the classifier computes the probability of the sample to belong to a class 𝑃(𝐶𝑖|𝑋).The sample is affected to the class with the highest probability. Hypothesis: descriptors are supposed to be independant According to Bayes’ theorem : 𝑃 𝑋|𝐶𝑖 𝑃 𝐶𝑖 𝑃 𝑋 𝑃(𝐶𝑖|𝑋) = With : 𝑃 𝐶𝑖 = freq(𝐶𝑖 ) 𝑃 𝑋 = 𝑛1 𝑃(𝑥𝑘) #𝑥𝑘 𝑖𝑛 𝐶𝑖 𝑛 𝑃 𝑋|𝐶𝑖 = 1 𝑃(𝑥𝑘|𝐶𝑖) and 𝑃(𝑥𝑘|𝐶𝑖) = #𝐶𝑖 22 Performance metrics • AUC ROC (Receiver Operator Characteristic) curve 𝑅𝑂𝐶 𝑠𝑐𝑜𝑟𝑒 = 𝐴𝑈𝐶 (𝑠𝑒𝑛𝑠𝑖𝑡𝑖𝑣𝑖𝑡𝑦 = 𝑓(1 − 𝑠𝑝𝑒𝑐𝑖𝑓𝑖𝑐𝑖𝑡𝑦) Each point on the ROC curve • corresponds to a ratio between true positives and false positives according to a discrimination threshold ROC AUC is the probability that a classifier rank a positive higher than a negative Used even when imbalanced classes Good for visualization and model comparison 23 Performance metrics (2) • Sensitivity : true positive rate or recall; proportion of positives correctly predicted among actual positives • 𝑆𝑒𝑛𝑠𝑖𝑡𝑖𝑣𝑖𝑡𝑦 = 𝑇𝑃 𝑇𝑃+𝐹𝑁 • Specificity : true negative rate; proportion of negatives correctly predicted among actual negatives • 𝑆𝑝𝑒𝑐𝑖𝑓𝑖𝑐𝑖𝑡𝑦 = 𝑇𝑁 𝑇𝑁+𝐹𝑃 • Balanced accuracy : average of sensitivity and specificity • 𝐵𝑎𝑙𝑎𝑛𝑐𝑒𝑑 𝑎𝑐𝑐𝑢𝑟𝑎𝑐𝑦 = 𝑆𝑒𝑛𝑠𝑖𝑡𝑖𝑣𝑖𝑡𝑦+𝑆𝑝𝑒𝑐𝑖𝑓𝑖𝑐𝑖𝑡𝑦 2 • Accuracy : proportion of true results among all the observations • 𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 = 𝑇𝑃+𝑇𝑁 𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁 24 Performance metrics (3) • Precision : positive predictive value ; proportion of positives correctly predicted among all the positives predicted • 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑇𝑃 𝑇𝑃+𝐹𝑃 • Negative predictive value (NPV) : proportion of negatives correctly predicted among all the negatives predicted • 𝑁𝑃𝑉 = 𝑇𝑁 𝑇𝑁+𝐹𝑁 • F-score: F-measure, F1 score ; harmonic mean of precision and recall (sensitivity) 2(𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛∗𝑆𝑒𝑛𝑠𝑖𝑡𝑖𝑣𝑖𝑡𝑦) 2𝑇𝑃 • 𝐹𝑠𝑐𝑜𝑟𝑒 = = 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛+𝑆𝑒𝑛𝑠𝑖𝑡𝑖𝑣𝑖𝑡𝑦 2𝑇𝑃+𝐹𝑃+𝐹𝑁 Often criticized because do not take TN into account 25 Performance metrics (4) • Matthew’s correlation coefficient (MCC): • 𝑀𝐶𝐶 = 𝑇𝑃∗𝑇𝑁 −𝐹𝑃∗𝐹𝑁 (𝑇𝑃+𝐹𝑃)(𝑇𝑃+𝐹𝑁)(𝑇𝑁+𝐹𝑃)(𝑇𝑁+𝐹𝑁) Measure of the quality of binary classifications, Correlation coefficient between observed an predicted classifications and Returns a value between -1 and 1: 0,5 means that 75% of cases are correctly predicted Used even if the classes are of very different sizes (imbalanced data) 26