Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
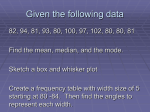
Chapter 4 Statistics Remember!!! The Nature of Random Error All measurements contain random error. (☞ Results always have some uncertainty) - Results in a scatter of results centered on the true value for repeated measurements on a single sample. - This type of error is always present and can never be totally eliminated - Equal chance of being positive or negative Statistics gives us tools to accept conclusions that have a high probability of being correct and reject conclusions that do not. Statistics deals only with random error—not determinate error. Systematic(determinate) error can be minimize and eliminated by using 1) certified standards and 2) different methods 3)……(See Chapter 3). Ex) Is My Red Blood Cell Count High Today? 4-1 Gaussian Distribution The Nature of Random Error ⇒ Random, or indeterminate, errors exist in every measurement. ⇒ can never be totally eliminate. ⇒ are often the major sources of uncertainty in a determination. ⇒ caused by uncontrollable variables ⇒ 원인을 확실하게 찾아내기 힘 듬 ⇒ Uncertainties의 원인을 확실하게 찾을 수 있을 경우에도, 대부분 너무 작아 개별적인 검출이 어려움 ⇒ 그러나 개개 uncertainties의 축적(accumulation)된 효과는 반복되 는 측정값을 평균주위에 random 하게 분포하게 함 Statistical Treatment of Random Error ⇒ Random error들은 statistical method로 평가 할 수 있음 ⇒ 분석 결과를 통계적으로 분석할 경우, random error들은 Gaussian or normal distribution을 한다는 가정에 근거 함 ⇒ Analytical data can follow distribution other than the Gaussian distribution 예) • 성공하거나 실패한 실험 모두 binomial distribution을 따름 • Radioactive or photon-counting 실험들은 Poisson distribution을 나타냄 • 그러나, 이들 distribution 들을 approximation 하기 위해 Gaussian distribution을 자주 사용함 • 많은 수의 실험에서는 approximation이 더 좋다. • 따라서, 여기서의 논의는 전적으로 normally distributed random error 들에 근거함. 4-1 Gaussian Distribution 1) Distribution of random errors highest frequency (Error=0) (4 random uncertainties: ±U1, ±U2, ±U3, ±U4) 참고 2) Distribution of results with only random error : Lifetime of 4768 electric light bulb in each 20-h interval. y 1 2 2 2 e ( x ) / 2 High population about mean value Mean For a series of experimental results with only random error: A large number of experiments done under identical conditions will yield a distribution of results. Distribution of results is described by a Gaussian Curve or Normal Error Curve Standard deviation low population far from correct value Means and Standard Deviation - A Gaussian distribution characterized by a mean and a standard deviation. - The mean is the center of the distribution and the standard deviation measures the width of the distribution. 1) Mean - μ : population (true) mean - x : sample mean (the mean of a limited sample drawn from a population of data) Population where , x x i i N (4-1) Sample x x x1 x 2 x 3 ..... x n i i i n i # As the number of measurements increase, x approaches μ, if there is no systematic error 2) Standard deviation - σ : population standard deviation - s : sample standard deviation Population 2 x i i N Sample s x i x i n 1 2 (4-2) degree of freedom ☞ Standard Deviation(σ or s): how closely the data are clustered about the mean. ⇒ Standard deviation relate to the precision (not accuracy) Smaller the standard deviation is, more precise the measurement is. 3) Other Terms Used to Describe a Data Set Variance(분산): Related to the standard deviation - Used to describe how “wide” or precise a distribution of results is variance = (s)2 (where: s = standard deviation) Relative standard deviation (RSD) or Coefficient of variation (CV) RSD s x or %RSD s x 100 Range: difference in the highest and lowest values in a set of data Ex. measurements of 4 light bulb lifetimes; 821, 783, 834, 855 High Value = 855 hours Low Value = 783 hours ∴ Range = High Value – Low Value = 855 – 783 = 72 hours Median: The value in a set of data which has an equal number of data values above it and below it - For odd number of data points, the median is actually the middle value - For even number of data points, the median is the value halfway between the two middle values Ex. Data Set: 1.19, 1.23, 1.25, 1.45 ,1.51 (odd number of data points) Median value Data Set: 1.19, 1.23, 1.25, 1.45 median = (1.23+1.25)/2=1.24 (even number of data points) Example Mean and Standard Deviation Find average( x ), standard deviation(s), and CV for 821, 783, 934, and 855 Solution x 821 783 834 855 823.2 4 (821 823.2)2 (783 823.2)2 (834 823.2)2 (855 823.2)2 s 30.3 (4 1) CV 100 s x 100 30.3 3.7% 823.2 # To avoid accumulating round-off errors, normally retain one more digit for the mean and SD calculation!!! Standard Deviation and Probability Formula for a Gaussian curve y 1 2 ( x )2 / 2 2 (4-3) e or y 1 2 e z 2 / 2 z where e = base of natural logarithm (2.71828…) μ ≈ x (mean) σ ≈ s (standard deviation) x μ x x σ s (4-4) 참고 z x xx s Summary Characteristics of Gaussian Curve - Max at z = 0 Symmetric Decaying exponentially Probability; area under the curve y 1 2 2 x μ x x e z / 2 z σ True value (mean) Entire area under curve is normalized to one (In population) ± Standard deviation (In sample) Range Probability (area) Range Probability (area) μ±1σ 68.3% x±1s 68.3% μ±2σ 95.5% x±2s 95.5% μ±3σ 99.7% x±3s 99.7% μ±4σ 99.9% x±4s 99.9% Ex) 68.3% of the area of a Gaussian curve occurs between the values μ±1σ (or x ±1s). ⇒ Thus, any new result has a 68.3% chance of falling within this range. ⇒ Thus, any new result has a 31.7% chance of outside of this range. - The precision of many analytical measurements is expressed as: x 2s ⇒ There is only a ~5% chance (1 out of 20) that any given measurement on the sample will be outside of this range s y x μ z σ xx s 1 2 ( x )2 e 2 2 1 2 e z2 2 Total ½ area is 0.5. - Area under curve from mean value and result. - Total ½ area is 0.5. - Remaining area is 0.5 – Area. Ex) z = 1.3area from mean to 1.3 is 0.4032 area from infinity to 1.3 is 0.5 – 0.4032 = 0.0968 Standard Deviation of the Mean Standard Deviation of the Mean of sets of n values: n n (4-5) σ: SD of one at a time n: number of measurements : Uncertainty in proportion to 1/√n (increase n ⇒ decrease σn (more precise) Ex) 4 times measurement(n=4): 1/√4 = 1/2 ⇒ decrease uncertainty by a factor 2 4-2 Confidence Intervals A) Finding the confidence Intervals(CI) when σ is known or s is a good estimate of σ ⇒ z value z x • For a single measurement (x) xlower = μ – zσ and xhigher = μ + zσ CI x zσ • For a the experimental mean ( x ) with n measurements zσ CI x n 참고 - when σ Is Known or s Is a Good Estimate of σ 예) (a) 면적의 50% : -0.67σ ∼ +0.67σ (b) 면적의 80% : -1.28σ ∼ +1.28σ (c) 면적의 90% : -1.64σ ∼ +1.64σ 예) 결과값 x와 표준편차 σ를 갖는 data (from Fig. c) →100번 중 90번의 확률로 x±1.64 σ 범 위에 true mean μ이 존재 →confidence level = 90% →confidence interval = -1.64σ ∼ +1.64σ B) Finding the confidence intervals(CI) when σ is unknown (for sample) ⇒ t value, degree of freedom x t • For a single measurement x xlower = μ – ts and xhigher = μ + ts CI x ts s • For a the experimental mean ( x ) with n measurements CI x ts n (4-6) (t : student’s t, degree of freedom=n-1) Note: As n increases, the confidence interval becomes smaller (μ becomes more precisely known) ☞ To determine the “true” mean need to collect an infinite number of data points. - obviously not possible ⇒ Confidence interval tells us the probability that the range of numbers contains the “true” mean. From number of n measurements (n-1) ? Example Calculating Confidence Intervals - Carbohydrate content (n=5); 12.5, 11.9, 13.0, 12.7, 12.5 wt% ⇒ Find 50% and 90% CI for carbohydrate content Solution CI for x ts n x 12.5 4 s 0.4 0 deg ree of freedom 5 1 4 50% CI 12.5 4 (0.741)(0.4 0 ) 90% CI 12.5 4 (2.132)(0.4 0 ) 5 12.5 4 0.13 wt % 5 12.5 4 0.3 8 wt % 50% CI 90% CI The Meaning of a Confidence Interval For population mean(μ)=10000 and population standard deviation(σ)=1000 50% of data sets do not contain true mean(10000) μ 10% of data sets do not contain true mean(10000) μ # CI tells us the probability that the range of numbers contains the “true” mean. Standard Deviation and Confidence Interval as Estimate of Experimental Uncertainty ( x 6.3746 ) (s 0.00018 ) (n 6) CI for x ts n - For 5 measurements (CI ts / n (2.776)(0. 001 8 )/ 5 0.002 5 ) Increase measurements - For 21 measurements Decrease uncertainty (CI ts / n (2.086)(0. 001 8 )/ 21 0.0008 ) Replicate measurements improve reliability. Ex. Volume calibration (n=5) x = 6.3746 mL, s = 0.0018 mL - Reporting value = 6.3746 ± 0.0018 mL ⇒ 95% CI n=5: μ = 6.3746 ± 0.0025 mL n=21: μ = 6.3746 ± 0.0008 mL 4-3 Comparison of Means with Student’s t t test - Student’s t can be used to compare two set of measurements to decide whether they are “the same ”. - Null hypothesis the two means are not different. - 95% confidence 5% chance of wrong conclusion Null hypothesis 영점가설 (귀무가설) - 영점가설은 어떤 두개 이상의 집단간에 차이가 없을 것이라는 가정하는 것이고, 대립가설은 차이가 있을 것이라고 가정하는 것을 말한다. - 영점가설(null hypothesis)은 귀무가설이라 하기도 하는데 두 개 이상의 변수간의 관계에 차이가 없거나 또는 두 변수는 같다고 잠정적 결론을 내리 것을 말한다. - 실험 결과가 이론값(참값, 알려진 값)에 의해 예상된 결과와 정확히 일치하는 경우 는 거의 없음 - 숫자적 차이가 random error인지 systematic error 인지를 판단 - 이런 판단을 분명하게 하기 위해 statistical test 실시 Case 1: Comparing a measured result to a “known” value : Measure a quantity several times calculate average value & standard deviation ⇒ Compare average value & accepted(or known) value ⇒ Does measured answer agree with the accepted value? Standard reference material(SRM): μ = 3.19 wt% S; "true(or known)" value Ex) Using a new method ⇒ Measuring data (n=4); : 3.29, 3.22, 3.30, 3.23 wt% S x = 3.260, s = 0.041, n = 4, t = 3.182(at n-1, from table 4-2) Does your answer agree with the known value (95% CI)? Solution μx ts n 3.260 (3.182)(0.041 ) 4 3.260 0.065 (4-7) ⇒ 95% confidence interval: 3.195 – 3.325 wt% 95% CI Known value 3.19 3.20 3.25 3.30 ∴ The new method produces a value different from the known one. ⇒The chance that they are the “same” is < 5%. Case 2: Comparing Replicate Measurements : Measure a quantity multiple times by two different methods calculate two sets of average values & standard deviations ⇒ Compare t values for tcal and ttable ⇒ Do the two results agree with each other? t-test: If tcal > ttable ⇒ the difference is significant (degree of freedom = n1+n2-2) 1) s1=s2 (4-8) (4-9) Degree of freedom Ex) Two set of measurements of the density of nitrogen gas: Discovering the Ar ttable = 2.228~2.131 (95% CL, 자유도=13) ∴ tcal > ttable ⇒ the difference is significant : Gas from air is undoubtedly denser than N2 from chemical sources. 2) s1≠s2 (4-8a) (4-9a) Case 3: Paired t teat for Comparing Individual Difference : Single measurement on several different samples for two methods ⇒ Compare t values for tcal and ttable ⇒ Do the two methods agree with each other? Σd i d )2 sd n 1 d tcalc n sd (4-10) (4-11) t-test: If tcal > ttable ⇒ the difference is significant (-3.0- d )2 (4.8- d )2 ... (-11.6- d )2 sd 6.7 48 11 1 tc a l c 2.4 91 11 1.22 4 6.748 ttable = 2.228 (95% CL) ∴ t calc < ttable ⇒ Two results are not significantly different One-Tailed and Two-Tailed Significant Test Is My Blood Cell Count High Today? High Today? x=5.16 ¯ s=0.23 (n=5) μ x tcalc ts n t today's count x s (x μ) n s n 5.16 5.6 5 4.28 0.23 From Table 4-2 (number of freedom=4) ttable = 3.747 (98% CL) ttable = 4.604 (99% CL) At 98% CL, t calc > ttable ⇒ At 98% CL, today’s count lies in the upper tail of the curve containing less than 2% of the area of the curve ⇒ Today’s count is elevated 4-4 Comparison of Standard Deviations with the F Test : Compare two variances ⇒ Compare F values for Fcal and Ftable ⇒ Does the two standard deviations agree with each other? Fcalc>Ftable : the difference is significant Fcalculated s12 2 s2 (4-12) where, s1>s2 (degree of freedom=n-1) 4-6 Grubbs Teat for an Outlier Gcalc questionable value x (4-13) s Gcalc>Gtable : the difference is significant (rejection) Ex) Mass loss(%): 10.2, 10.8, 11.6, 9.9, 9.4, 7.8, 10.0, 9.2, 11.3, 9.5, 10.6, 11.6 Gcalc 7.8 10.16 1.11 2.13 ∴ Gcalc<Gtable : ⇒ the questionable date should be retained 참고 Q Test for Bad Data Qcalc>Qtable : the difference is significant (rejection) Qcalculated Gap Range gap = 0.11 Ex) 12.47 12.48 12.53 12.56 12.67 Questionable point Range = 0.20 Q Gap 0.11 0.55 Range 0.20 ∴ Qcalc<Qtable ⇒ the questionable date should be retained Before rejection of bad data, repeating experiments with questionable results are usually more helpful. 4-7 The Method of Least Squares Procedures for Quantitative Analysis Step 1: Evaluation signals for known quantities of analyte (standard solution) to prepare calibration curve Calibration curve: graph showing the analytical response as a function of the known quantity of analyte (x axis=concentration, y-axis=signal) Generally desirable to graph data(calibration curve) to generate a straight line The Method of Least Squares Finding the “Best” Straight Line (y=mx+b) Step 2: Measurement signals for unknown quantities of analyte (call sample) Step 3: Calculation of unknown quantities of analyte from calibration curve Finding the Equation of the Line x = independent variable (Conc.) Method of Least Squares y = dependent variable (Siganl) (4-14) y = mx + b m = slope b = y-intercept Assumption - Errors are from the y values. - Uncertainties in all of the y values are similar. (4-15) Vertical deviation di = yi – (mxi + b), di2 = (yi – mxi - b)2 • Method of Linear Least Squares is used to determine the best values for “m” (slope) and “b” (y-intercept) given a set of x and y values - Minimize vertical deviation between points and line - Use square of the deviations deviation irrespective of sign • number of points :(x1, y1), (x2, y2),…..(xn, yn) y = mx + b m n ( x i y i ) x i y i b n ( x i )2 ( x i )2 D n( x ) i 2 n ( x i ) y i ( x i y i ) x i n ( x i )2 ( x i )2 ( x i )2 (di ) 2 The standard deviation of y values (sy): sy The standard deviation of the intercept (sb): s 2 b The standard deviation of the slope (sm ): y = 0.61538x + 1.34615 sm2 n2 s2y xi2 D s2yn D (4-20) (4-21) (4-22) y = 0.61538x + 1.34615 0.076923 0.038462 42 (0.038462)( 4) 0.0029586 s m 0.05439 52 sy 2 sm 2 sb 2 (0.038462)( 62) 0.045859 s b 0.21415 52 ∴ Slope(m) = 0.615 ± 0.054 Intercept(b) = 1.35 ± 0.21 (4-23) (4-24) y(±sy) = m±(sm)x + b(±sb) 95% CI for slope(m) = tsm = (4.303)(0.054)=0.23 (degree of freedom=n-2=2) 4-8 Calibration Curves Calibration curve: known quantity of analyte vs. signal - Standard solution: Solutions containing known concentration of analyte - Blank solution: Solution containing all reagents and solvent used in analysis without analyte blank Not calibration curve (∵ contain blank signal) Constructing a Calibration Curve Procedures for making a calibration curve Step 1 Prepare known samples of analyte (standard solution) covering convenient range of concentrations. ⇒ Measure the response of the standard solution. ⇒ Measure the response of the blank solution. Step 2 Subtract average response of blank (no analyte) to obtain corrected response. ☞ Corrected response = Observed response - Blank response Step 3 Make graph of corrected response(y-axis) vs. concentration(x-axis). ⇒ Determine best straight line using “The Method of Least Squares”. # y(response)= mx(concentration) + b Corrected absorbance: After subtracting average blank (Data used for calibration curve) (blank) Analyte (Standard) Absorbance of unknown Plot Conc. Vs. abs. Calibration curve Absorbance = m(μg of protein)+b y m=0.01630 b=0.0047 x ⇒ y=0.01630x + 0.0047 (4-25) Determination of Unknown 1) Measure the signal of unknown (y value) 2) Calculate x value (concentration of unknown) from linear equation Protein in unknown • Prefer calibration - A linear response - Analytical signal proportional to the quantity of analyte. - Sometimes, nonlinear calibration can be used (BOX 4-2). • Linear range : The analyte concentration range over which response is proportional to concentration. • Dynamic range : The concentration range over which is a measureable response to analyte, but the response is not linear. Additional analyte does not result in an increase in response Good Practice - Always make a graph of your data. - At least 4~6 calibration concentrations and three replicate measurements of unknown should be measured. Propagation of Uncertainty with a Calibration Curve • The standard deviation for results obtained from the calibration curve (sx): Uncertainty in x( s x ) sy m Number of replicate measurements of the unknown Ex) From Table 4-7 1 1 (y y )2 2 k n m (xi x)2 (4-27) Number of date points for the calibration line Absorbance (y) = mx(μg of protein) + b 0.302 = (0.01630)x(μg of protein) + 0.0047 ∴ x(μg of protein)=18.24 μg For single measurement of unknown: k=1 ⇒ sx = ±0.39 μg ∴ x=18.2 ±0.39 μg For 4 measurement of unknown : k=4 ⇒ sx = ±0.23 μg ∴ x=18.2 ±0.23 μg : Replicate measurement of unknown ⇒ reduce uncertainty of x value