Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
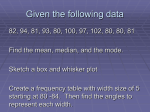
Looking at Data - Distributions Displaying Distributions with Graphs IPS Chapter 1.1 © 2009 W.H. Freeman and Company Objectives (IPS Chapter 1.1) Displaying distributions with graphs Variables Types of variables Graphs for categorical variables Bar graphs Pie charts Graphs for quantitative variables Histograms Stemplots Stemplots versus histograms Interpreting histograms Time plots Key things to focus on: Categorical v.s. Quantitative variables Types of graphs used for categorical as opposed to quantitative variables. Histograms How they are created / choosing appropriate bin size Commonly encountered histogram shapes How to interpret them Variables In a study, we collect information—data—from individuals. Individuals can be people, animals, plants, or any object of interest. A variable is any characteristic of an individual. A variable varies among individuals. Example: age, height, blood pressure, ethnicity, leaf length, first language * The distribution of a variable tells us what values the variable takes and how often it takes these values. Two types of variables Variables can be either quantitative… Something that takes numerical values for which arithmetic operations, such as adding and averaging, make sense. Example: How tall you are, your age, your blood cholesterol level, the number of credit cards you own. … or categorical. Something that falls into one of several categories. What can be counted is the count or proportion of individuals in each category. Example: Your blood type (A, B, AB, O), your hair color, your ethnicity, whether you paid income tax last tax year or not. How do you know if a variable is categorical or quantitative? Ask: What are the n individuals/units in the sample (of size “n”)? What is being recorded about those n individuals/units? Is that a number ( quantitative) or a statement ( categorical)? Categorical Quantitative Each individual is assigned to one of several categories. Each individual is attributed a numerical value. Individuals in sample DIAGNOSIS AGE AT DEATH Patient A Heart disease 56 Patient B Stroke 70 Patient C Stroke 75 Patient D Lung cancer 60 Patient E Heart disease 80 Patient F Accident 73 Patient G Diabetes 69 Charting – It’s all about the data… The purpose of a graph or chart is to try and provide a ‘visual’ description of the data. The type of chart chosen, the scales used, the labels, the description, summary lines, etc are all tools whose ultimate purpose is to give the most accurate understanding of the data. By the same token, it is possible to create graphs that give a thoroughly misleading picture of the data! This is disappointingly common. So, whether you choose a pie chart, bar chart, histogram, scatterplot, etc, the question you must always be asking yourself is: Does this chart give the most accurate understanding of the data? Ways to chart categorical data Because the variable is categorical, the data in the graph can be ordered any way we want (alphabetical, by increasing value, by year, by personal preference, etc.) Bar graphs Each category is represented by a bar. Pie charts The slices must represent the parts of one whole. Perhaps the greatest benefit of the pie chart is the ability to emphasize each category’s relation to the whole. Example: Top 10 causes of death in the United States 2001 Rank Causes of death Counts % of top 10s % of total deaths 1 Heart disease 700,142 37% 29% 2 Cancer 553,768 29% 23% 3 Cerebrovascular 163,538 9% 7% 4 Chronic respiratory 123,013 6% 5% 5 Accidents 101,537 5% 4% 6 Diabetes mellitus 71,372 4% 3% 7 Flu and pneumonia 62,034 3% 3% 8 Alzheimer’s disease 53,852 3% 2% 9 Kidney disorders 39,480 2% 2% 32,238 2% 1% 10 Septicemia All other causes 629,967 26% For each individual who died in the United States in 2001, we record what was the cause of death. The table above is a summary of that information. Example: Top 10 causes of death in the United States 2001 Rank Causes of death Counts % of top 10s % of total deaths 1 Heart disease 700,142 37% 29% 2 Cancer 553,768 29% 23% 3 Cerebrovascular 163,538 9% 7% 4 Chronic respiratory 123,013 6% 5% 5 Accidents 101,537 5% 4% 6 Diabetes mellitus 71,372 4% 3% 7 Flu and pneumonia 62,034 3% 3% 8 Alzheimer’s disease 53,852 3% 2% 9 Kidney disorders 39,480 2% 2% Septicemia 32,238 2% 1% 10 All other causes 629,967 26% • Pie chart or Bar chart? • How would you order the data? • alphabetically? • size? • ickiness of the disease? • REMEMBER: The purpose of a chart/graph is to provide the best picture of the data! ise as es 800 700 600 500 400 300 200 100 0 Ca nc Ce er re s br ov Ch as cu ro ni la c r re sp ira to ry Ac ci Di de ab nt s et es m el Fl litu u & s pn eu Al zh m on ei m ia er 's di se Ki as dn e ey di so rd er s Se pt ice m ia He ar td Counts (x1000) zh ei m er 's di de nt s se as e Ac ci Ca nc Ce er s re br ov Ch as cu ro la ni r c re sp ira Di to ab ry et es m el Fl litu u s & pn eu m on He ia ar td ise as Ki dn es ey di so rd er s Se pt ice m ia Al Counts (x1000) 800 700 600 500 400 300 200 100 0 Sorted alphabetically Bar graph sorted by rank Much easier to analyze Bar graphs Top 10 causes of deaths in the United States 2001 The number of individuals who died of an accident in 2001 is approximately 100,000. Ca nc Ce er re s br ov Ch as cu ro ni la c r re sp ira to ry Ac ci Di de ab nt s et es m el Fl litu u & s pn eu Al zh m on ei m ia er 's di se Ki as dn e ey di so rd er s Se pt ice m ia ise as es 800 700 600 500 400 300 200 100 0 He ar td Counts (x1000) Each category is represented by one bar. The bar’s height shows the count (or sometimes the percentage) for that particular category. Pie charts Each slice represents a piece of one whole. The size of a slice depends on what percent of the whole this category represents. Percent of people dying from top 10 causes of death in the United States in 2000 Pie charts • A pie chart makes it easy to analyze in terms of the relative proportions of each category. • Notice here that we have changed from the numbers of people dying to the percent of people dying • To make a pie chart, typically use percentages, and they have to add up to 100% or you won’t have the whole pie. • That is why pie charts typically have an “other”. • This chart doesn’t have an ‘other’ since we’re talking only about the top 10 diseases, not all diseases. Make sure your labels match the data. Make sure all percents add up to 100. Percent of deaths from top 10 causes Percent of deaths from all causes • The top pie chart is the one we have just been looking at. • In the bottom one I have included deaths from all other causes in addition to the top 10. • Adding this additional category changes the percentages on the original 10. • Heart disease was 37% of total before, now is a smaller percent, 29%, because we are looking at all deaths. Child poverty before and after government intervention—UNICEF What does this chart tell you? •The United States has the highest rate of child poverty among developed nations (22% of under 18). •Its government does the least—through taxes and subsidies—to remedy the problem (size of orange bars and percent difference between orange/blue bars). Could you transform this bar graph to fit in 1 pie chart? In two pie charts? Why? The poverty line is defined as 50% of national median income. Quick Review: Categorical data: The variables do not have a quantity to them. Rather, each variable is placed in a group, and we are comparing the size of the different groups. Eg: Top causes of death in the USA: We have several categories (diseases) and we compare these diseases. Pie charts and bar charts are frequently good choices for charting categorical data. Quantitative data: Variables that have a numerical value to them, such as the percentage of Hispanic people per capita in each state, or the average corn-crop yield by county in Indiana. We typically use different kinds of graphs such as histograms, scatterplots, stem-and-leaf charts to graph quantitative data. Ways to chart quantitative (as opposed to categorical) data Histograms and stemplots These are summary graphs for a single variable. They are very useful to understand the pattern of variability in the data. Single variable as opposed to comparing two variables. More on this later. Important topic: We will discuss variability over the next 1-2 lectures. Line graphs: time plots Use when there is a meaningful sequence, like time. Including a line connecting the points sometimes helps emphasize any change over time. Remember: Every decision you make such as whether or not to include a summary line affects the “picture” told by your graph. ** Histograms The range of values that a variable can take is divided into equal size intervals. The histogram shows the number of individual data points that fall in each interval. The first column represents all states with a Hispanic percent in their population between 0% and 4.99%. The height of the column shows how many states (27) have a percent in this range. The last column represents all states with a Hispanic percent in their population between 40% and 44.99%. There is only one such state: New Mexico, at 42.1% Hispanics. Stem plots Another way of graphing quantitative data. Below is a list of people’s ages taken from a single row at a play. We will graph these ages using a ‘stem plot’ 9, 9, 22, 32, 33, 39, 39, 42, 49, 52, 58, 70 Stem plots 9, 9, 22, 32, 33, 39, 39, 42, 49, 52, 58, 70 How to make a stemplot: 1) Separate each observation into a stem, consisting of all but the final (rightmost) digit, and a leaf, which is that remaining final digit. Stems may have as many digits as needed, but each leaf contains only a single digit. 2) Write the stems in a vertical column with the smallest value at the top, and draw a vertical line at the right of this column. 3) Write each leaf in the row to the right of its stem, in increasing order out from the stem. STEM LEAVES State Percent Alabama Alaska Arizona Arkansas California Colorado Connecticut Delaware Florida Georgia Hawaii Idaho Illinois Indiana Iowa Kansas Kentucky Louisiana Maine Maryland Massachusetts Michigan Minnesota Mississippi Missouri Montana Nebraska Nevada NewHampshire NewJersey NewMexico NewYork NorthCarolina NorthDakota Ohio Oklahoma Oregon Pennsylvania RhodeIsland SouthCarolina SouthDakota Tennessee Texas Utah Vermont Virginia W ashington W estVirginia W isconsin W yoming 1.5 4.1 25.3 2.8 32.4 17.1 9.4 4.8 16.8 5.3 7.2 7.9 10.7 3.5 2.8 7 1.5 2.4 0.7 4.3 6.8 3.3 2.9 1.3 2.1 2 5.5 19.7 1.7 13.3 42.1 15.1 4.7 1.2 1.9 5.2 8 3.2 8.7 2.4 1.4 2 32 9 0.9 4.7 7.2 0.7 3.6 6.4 Step 1: Sort the data State Percent Maine W estVirginia Vermont NorthDakota Mississippi SouthDakota Alabama Kentucky NewHampshire Ohio Montana Tennessee Missouri Louisiana SouthCarolina Arkansas Iowa Minnesota Pennsylvania Michigan Indiana W isconsin Alaska Maryland NorthCarolina Virginia Delaware Oklahoma Georgia Nebraska W yoming Massachusetts Kansas Hawaii W ashington Idaho Oregon RhodeIsland Utah Connecticut Illinois NewJersey NewYork Florida Colorado Nevada Arizona Texas California NewMexico 0.7 0.7 0.9 1.2 1.3 1.4 1.5 1.5 1.7 1.9 2 2 2.1 2.4 2.4 2.8 2.8 2.9 3.2 3.3 3.5 3.6 4.1 4.3 4.7 4.7 4.8 5.2 5.3 5.5 6.4 6.8 7 7.2 7.2 7.9 8 8.7 9 9.4 10.7 13.3 15.1 16.8 17.1 19.7 25.3 32 32.4 42.1 Percent of Hispanic residents in each of the 50 states Step 2: Assign the values to stems and leaves Stem Plot To compare two related distributions, a back-to-back stem plot with common stems is useful. Stem plots do not work well for large datasets(tedious / impractical). When the observed values have too many digits, trim the numbers before making a stem plot. When plotting a moderate number of observations, you can split each stem. Stemplots versus histograms Stemplots are quick and dirty histograms that can easily be done by hand, and therefore are very convenient for back of the envelope calculations. However, they are rarely found in scientific or layperson publications. Interpreting histograms When describing the distribution of a quantitative variable, we look for the overall pattern and for striking deviations from that pattern. We can describe the overall pattern of a histogram by its shape, center, and spread. Histogram with a line connecting each column too detailed Histogram with a smoothed curve highlighting the overall pattern of the distribution ** Distributions: Most common shapes Symmetric distribution A distribution is symmetric if the right and left sides of the histogram are approximately mirror images of each other. A distribution is skewed to the right if the right side of the histogram (side with larger values) extends much farther out than the left side. It is skewed to the left if the left side of the histogram Skewed distribution extends much farther out than the right side. Complex, multimodal distribution Not all distributions have a simple overall shape, especially when there are few observations. ** Outliers An important kind of deviation is an outlier. Outliers are observations that lie outside the overall pattern of a distribution. Always look for outliers and try to explain them. The overall pattern is fairly symmetrical except for 2 states that clearly do not belong to the main trend. Alaska and Florida have unusual representation of the elderly in their population. A large gap in the distribution is typically a sign of an outlier. Alaska Florida How to create a histogram Deciding on the appropriate bin size can be an iterative process – you may need to try a few times to decide on an optimal size. Ideally: Not too many bins with either 0 or 1 counts Not overly summarized that you lose all the information Not so detailed that it is no longer summary rule of thumb: start with 5 to 10 bins Look at the distribution and refine your bins (There isn’t a unique or “perfect” solution) Same data set Not summarized enough Too summarized Line graphs: time plots In a time plot, time always goes on the horizontal, x axis. We describe time series by looking for an overall pattern and for striking deviations from that pattern. In a time series: A trend is a rise or fall that persists over time, despite small irregularities. A pattern that repeats itself at regular intervals of time is called seasonal variation. Retail price of fresh oranges over time Time is on the horizontal, x axis. The variable of interest—here “retail price of fresh oranges”— goes on the vertical, y axis. This time plot shows a regular pattern of yearly variations. These are seasonal variations in fresh orange pricing most likely due to similar seasonal variations in the production of fresh oranges. There is also an overall upward trend in pricing over time. It could simply be reflecting inflation trends or a more fundamental change in this industry. A time plot can be used to compare two or more data sets covering the same time period. 1918 influenza epidemic # Cases # Deaths Date 1918 influenza epidemic 800 700 700 600 600 500 500 400 400 300 300 200 200 100 100 0 0 wek ee1 we k 1 wek ee3 we k 3 wek ee5 we k 5 wek ee7 we k 7 wek we ee9k ewk 9 ee11 we k 1 ewk 1 e1 we ek3 ewk 13 e1 we ek5 ewk 15 ee17 k 17 0 # deaths reported 800 10000 9000 10000 8000 9000 7000 8000 6000 7000 5000 6000 4000 5000 3000 4000 3000 2000 2000 1000 1000 0 we 0 0 130 552 738 414 198 90 56 50 71 137 178 194 290 310 149 Incidence 36 531 4233 8682 7164 2229 600 164 57 722 1517 1828 1539 2416 3148 3465 1440 # cases diagnosed week 1 week 2 week 3 week 4 week 5 week 6 week 7 week 8 week 9 week 10 week 11 week 12 week 13 week 14 week 15 week 16 week 17 1918 influenza epidemic # Cases # Cases # Deaths # Deaths The pattern over time for the number of flu diagnoses closely resembles that for the number of deaths from the flu, indicating that about 8% to 10% of the people diagnosed that year died shortly afterward, from complications of the flu. ** Scales matter Death rates from cancer (US, 1945-95) Death rates from cancer (US, 1945-95) Death rate (per thousand) 250 200 150 100 250 Death rate (per thousand) How you stretch the axes and choose your scales can give a different impression. 200 150 100 50 50 0 1940 1950 1960 1970 1980 1990 0 1940 2000 1960 1980 2000 Years Years Death rates from cancer (US, 1945-95) 250 Death rates from cancer (US, 1945-95) 220 Death rate (per thousand) Death rate (per thousand) 200 150 100 50 0 1940 1960 Years 1980 2000 A picture is worth a thousand words, 200 BUT 180 160 There is nothing like hard numbers. Look at the scales. 140 120 1940 1960 1980 Years 2000 Why does it matter? What's wrong with these graphs? Cornell’s tuition over time Careful reading reveals that: 1. The ranking graph covers an 11-year period, the tuition graph 35 years, yet they are shown comparatively on the cover and without a horizontal time scale. 2. Ranking and tuition have very different units, yet both graphs are placed on the same page without a vertical axis to show the units. Cornell’s ranking over time 3. The impression of a recent sharp “drop” in the ranking graph actually shows that Cornell’s rank has IMPROVED from 15th to 6th ... Look at your axis labels carefully!! Pay close attention to the labels on each axis Pay close attention to the units of those labels (e.g. kilograms, cost in 100s of dollars, average per million people,etc, etc) Sometimes you have to think about them for a few minutes before you can really understand them, or spot potential flaws. This is one of the most important points of this lecture. Looking at Data - Distributions Describing distributions with numbers IPS Chapter 1.2 © 2009 W.H. Freeman and Company Objectives (IPS Chapter 1.2) Describing distributions with numbers Measures of center: mean, median Mean versus median Measures of spread: quartiles, standard deviation Five-number summary and boxplot Choosing among summary statistics Changing the unit of measurement Measure of center: the mean The mean or arithmetic average To calculate the average, or mean, add all values, then divide by the number of individuals. It is the “center of mass.” Sum of heights is 1598.3 divided by 25 women = 63.9 inches Heights of 25 women in inches 58 .2 59 .5 60 .7 60 .9 61 .9 61 .9 62 .2 62 .2 62 .4 62 .9 63 .9 63 .1 63 .9 64 .0 64 .5 64 .1 64 .8 65 .2 65 .7 66 .2 66 .7 67 .1 67 .8 68 .9 69 .6 woman (i) height (x) woman (i) height (x) i=1 x1= 58.2 i = 14 x14= 64.0 i=2 x2= 59.5 i = 15 x15= 64.5 i=3 x3= 60.7 i = 16 x16= 64.1 i=4 x4= 60.9 i = 17 x17= 64.8 i=5 x5= 61.9 i = 18 x18= 65.2 i=6 x6= 61.9 i = 19 x19= 65.7 i=7 x7= 62.2 i = 20 x20= 66.2 i=8 x8= 62.2 i = 21 x21= 66.7 i=9 x9= 62.4 i = 22 x22= 67.1 i = 10 x10= 62.9 i = 23 x23= 67.8 i = 11 x11= 63.9 i = 24 x24= 68.9 i = 12 x12= 63.1 i = 25 x25= 69.6 i = 13 x13= 63.9 n=25 S=1598.3 Mathematical notation: x1 x2 ... xn x n 1 n x xi n i 1 Don’t get psyched out! 1598.3 x 63.9 25 Learn right away how to get the mean using your calculators. Another summation example Consider the following dataset: 3, -11, 6, 0, 22 Find the value of x given the following formula: ( n * 2) ( xi 3) Answer: Take each value in the dataset. Call the first value x1. Call the second value x2. Call the last value (the fifth number), x5. ‘n’ refers to the quantity of values in the dataset. So in this case, as there are 5 numbers in the dataset, n = 5. First do the summation: (3+3) + (-11+3) + (6+3) + (0+3) + (22+3) This gives you 35. Then multiply that by (n*2) which is 10. This gives you an answer of 350. ** Another measure of center: the median The median is the midpoint of a distribution—the number such that half of the observations are smaller and half are larger. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 1 2 3 4 5 6 7 8 9 10 11 12 1 2 3 4 5 6 7 8 9 10 11 0.6 1.2 1.6 1.9 1.5 2.1 2.3 2.3 2.5 2.8 2.9 3.3 3.4 3.6 3.7 3.8 3.9 4.1 4.2 4.5 4.7 4.9 5.3 5.6 25 12 6.1 1. Sort observations by size. n = number of observations ______________________________ 2.a. If n is odd, the median is observation (n+1)/2 down the list n = 25 (n+1)/2 = 26/2 = 13 Median = 3.4 2.b. If n is even, the median is the mean of the two middle observations. Survival years for Disease X n = 24 n/2 = 12 Median = (3.3+3.4) /2 = 3.35 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 1 2 3 4 5 6 7 8 9 10 11 1 2 3 4 5 6 7 8 9 10 11 0.6 1.2 1.6 1.9 1.5 2.1 2.3 2.3 2.5 2.8 2.9 3.3 3.4 3.6 3.7 3.8 3.9 4.1 4.2 4.5 4.7 4.9 5.3 5.6 Comparing the mean and the median • The mean and the median are the same only if the distribution is symmetrical. • The median is a measure of center that is resistant to skew and outliers. The mean is not. • Outliers “pull” the mean towards themselves. Mean and median for a symmetric distribution Mean Median Mean and median for skewed distributions Left skew Mean Median Mean Median Right skew One other measure: Mode It is the category that occurs most frequently. In a histogram, it’s the highest bin. A histogram that clusters around one general peak (even if it’s more than one single bar) is called ‘unimodal’. If there are two peaks, ‘bimodal’ More than that, we just say ‘multimodal’. In the dataset: 2, 3, 4, 4, 6 the mode would be 4 since it occurs the most frequently. However, the mode is only useful when you have reasonably large datasets. Even so, we will use it only to summarize a histogram as discussed above. Incidence of IBD in Denmark Mean and median of a distribution with outliers Percent of people dying x 3.4 x 4.2 Without the outliers With the outliers The mean is pulled to the The median, on the other hand, right a lot by the outliers is only slightly pulled to the right (from 3.4 to 4.2). by the outliers (from 3.4 to 3.6). Effect of outliers on the mean and median Percent of people dying x 3.4 x 4.2 Without the outliers With the outliers Note the presence of outliers – those two fortunate people who managed to live several years longer than the others. These two large values moved the mean up from 3.4 to 4.2 However, the median , the number of years it takes for half the people to die only went from 3.4 to 3.6. Note that this says that the median is fairly resistant, but not 100% resistant. The median is not sensitive to the size of the outlier, rather, iIt is sensitive to the number of outliers. This is typical behavior for the mean and median. The mean is sensitive to outliers, because when you add all the values up to get the mean the outliers are weighted disproportionately by their large size. However, when you get the median, they are just another two points to count –the actual size of those values does not affect things. Measures: Describe these two graphs. Which measure of center would you use for the top graph? For the bottom graph? Why? Answer: When you have a fairly symmetric distribution with few outliers or where the outliers are not very significant in terms of size, mean is often a good bet (e.g. top graph). If you have a few outliers and/oroutliers with very large values, they will probably throw off your mean. In that case, you’d probably want to go with median (bottom graph). *** Impact of skewed data Symmetric distribution… Disease X: x 3.4 M 3.4 Mean and median are the same. … and a right-skewed distribution Multiple myeloma: x 3.4 M 2.5 The mean is pulled toward the skew. ** Measures of variation Most people intuitively ‘get’ the benefit of knowing the center of a distribution (e.g. the ‘average’ salary of first-year doctors). However, a piece of data that is sadly neglected but is EVERY bit as important, is the variation of the data. Just as there are different ways of describing the center of a distribution (e.g. mean, median, mode), there are different techniques for describing the spread of a distribution. As with the center, you must know which description of the spread is the best of the most accurate tool for describing the spread. Common techniques for describing the variation in a dataset: Range: the highest and lowest values in the dataset. Important, but outliers can give people a highly inaccurate picture (imagine if you looked at the range of salaries). Quartiles – dividing the range into four Standard Deviation / Variance: this is one of the most effective means of describing the spread, and a tool that we will come back to constantly throughout this course. * Measure of spread: the quartiles The first quartile, Q1, is the value in the sample that has 25% of the observations (data points) at or below it. (It is the median of the lower half of the sorted data, excluding M). The third quartile, Q3, is the value in the sample that has 75% of the data at or below it. (It is the median of the upper half of the sorted data, excluding M). 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 1 2 3 4 5 6 7 1 2 3 4 5 1 2 3 4 5 6 7 1 2 3 4 5 0.6 1.2 1.6 1.9 1.5 2.1 2.3 2.3 2.5 2.8 2.9 3.3 3.4 3.6 3.7 3.8 3.9 4.1 4.2 4.5 4.7 4.9 5.3 5.6 6.1 Survival time (years) n=25 Q1= first quartile = 2.2 M = median = 3.4 Q3= third quartile = 4.35 5-Number Summary and Box Plot Once you have divided your dataset into quartiles, you now have one technique for creating a neat little summary. It is called the ‘5 Number Summary’ and is made up of: Lowest number First (lower) quartile Median (not the mean!) Third (upper) quartile Highest number Once you have this summary in hand, you can even ‘draw’ it using a simple (but very convenient) plot known as a box plot. ** Five-number summary and boxplot 6 5 4 3 2 1 6 5 4 3 2 1 6 5 4 3 2 1 6 5 4 3 2 1 6.1 5.6 5.3 4.9 4.7 4.5 4.2 4.1 3.9 3.8 3.7 3.6 3.4 3.3 2.9 2.8 2.5 2.3 2.3 2.1 1.5 1.9 1.6 1.2 0.6 Largest = max = 6.1 BOXPLOT 7 Q3= third quartile = 4.35 M = median = 3.4 6 Years until death 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 5 4 3 2 1 Q1= first quartile = 2.2 Smallest = min = 0.6 0 Disease X Five-number summary: min Q1 M Q3 max Boxplots for skewed data Years until death Comparing box plots for a normal and a right-skewed distribution 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 Boxplots remain true to the data and depict clearly symmetry or skew. Disease X Multiple Myeloma * OUTLIERS – “Suspected Outliers” Outliers are data points that require some thought. The first step is to decide whether a data point should indeed be labeled as an outlier. Once you have decided that it is an outlier, the next question is what you want to do with it. There are two options for dealing with outliers – you can include them in your analysis, or you can leave them out. Exclude outliers: Suppose you have a datapoint that is extremely high – and you think it was recorded in error. In this case, you would not want to include this value in your calculations since values like mean and standard deviation would be thrown off by this bad datapoint. However, if you choose to leave out a datapoint, you MUST include in your paper a discussion of your reasons for doing so. Include outliers: The other option, of course, is to include the outlier(s) in your calculations and analysis. Discussion question: Suppose we wanted to determine the average height of DePaul students and we use our class as a sample. However, that particular day, we are being visited by an incoming freshman who just hpapens to be the tallest person in the world. Would you include him/her in your analysis? * OUTLIERS – Identification of the Outlier At what point do we typically label a datapoint as an outlier? Here is one way: 1. Determine the distance from the suspicious data point to the nearest quartile (Q1 or Q3). 2. Determine the distance between Q1 and Q3, called the interquartile range, or IQR. 3. We call an observation a suspected outlier if it falls more than 1.5 times the size of the interquartile range (IQR) below the first quartile or above the third quartile. This technique is called the “1.5 * IQR rule for outliers.” 6 5 4 3 2 1 6 5 4 3 2 1 6 5 4 3 2 1 6 5 4 3 2 1 7.9 6.1 5.3 4.9 4.7 4.5 4.2 4.1 3.9 3.8 3.7 3.6 3.4 3.3 2.9 2.8 2.5 2.3 2.3 2.1 1.5 1.9 1.6 1.2 0.6 “Modified” Boxplot 8 7 Q3 = 4.35 6 Years until death 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 Distance to Q3 7.9 − 4.35 = 3.55 5 Interquartile range Q3 – Q 1 4.35 − 2.2 = 2.15 4 3 2 1 Q1 = 2.2 0 Disease X Individual #25 has a value of 7.9 years, which is 3.55 years above the third quartile. This is more than 3.225 years (i.e.1.5 * IQR). Thus, we can say that individual #25 is a suspected outlier. ** The “Five-Number Summary” A quick-and-dirty way to give a reasonable description of center and spread. It is made up of: 1. 2. 3. 4. 5. Minimum Q1 M Q3 Maximm For the previous slide, the five-number summary would be: 0.6 2.2 3.4 4.35 6.1 (If we exclude the outlier) Quick Reminder: • Boxplots are a very good way to visualize the spread around a median. • Boxplots can be used no matter what the distribution, (e.g. normal, skewed, random, etc). • Boxplots are a good way to contrast variables having different distributions with each other. Put one or more boxplots side by side. Standard Deviation and Z-Scores One of the most important concepts in the course… Another way of describing variation Recall that we usually describe a distribution in terms of its shape, center, and variation. One method of describing the variation has already been discussed: List the quartiles / 5-number summary. Another extremely important method of describing variation is the ‘variance’ or ‘standard deviation’. Variation In every set of values (“dataset”—know this term!) e.g. ages, heights, incomes, crop yields, spitball-distances, etc there will always be variation. The question is, how do we describe just how varied our data is? Are all the points closely clustered around some value or are they all over the map? Having a sense of how much the various datapoints are spread out around the center (mean or median) is an important piece of information. Consider employee pay at DePaul University: if we looked at every income from student workers to the Provost/President, we would see a tremendous variation around the center as some people make a great deal more than the center, and some make much less. However, if we focused only on student employees, we would find that the variation around the center is considerably less. Suppose we were looking at a widget used in the construction of a high-performance laser. Suppose this widget is intended to be exactly 2.3 inches in diameter. A manufacturer must make their parts extremely close to this diameter in order for them to fit properly. We would assume that the average diameter of, say, 10000 parts would indeed be very close to 2.3. However, the question from a manufacturing perspective would be: How much variation is there among the parts? The manufacturer would hope that the variation would be extremely small, that is, nearly all the parts are very close in size to the mean. If there is a large variation, it would mean that there are several parts that are inappropriately sized, and many of our very expensive lasers are going to be faulty. The most common statistic we used for measuring variability (spread) is called the standard deviation. SD (‘s’) is one way of describing the variation of a dataset. There are other ways. (e.g. Recall that there is more than one way to describe the center of a dataset). SD is a great choice because it allows us to easily draw lots of conclusions and answer various questions about our data. * However, SD is best used with data that has a symmetrical distribution (ie doesn’t work well with skewed data). This is because in order to calculate the SD, we need to use the mean of that data. Recall that mean is only a good choice for the center if your data is symmetric. The Standard Deviation measures variation by looking at how far the observations are from their mean. Variance and Standard Deviation are essentially the same thing Variance and Standard Deviation are essentially the same thing. The SD is simply the square root of the variance. Eg: If Variance is 25, then SD = 5. If SD = 7, then Variance = 49. Some people prefer to use variance when discussing spread, others prefer standard deviation. I hope it’s clear that either one can easily be converted to the other. For the time being, I’ll focus on standard deviation. Measure of spread: the standard deviation The standard deviation “s” is used to describe the variation around the mean. Like the mean, it is not resistant to skew or outliers. Remember that “resistance” is an important concept! 1. First calculate the variance s2. n 1 2 s2 ( x x ) i n 1 1 2. Then take the square root to get the standard deviation s. x Mean ± 1 s.d. 1 n 2 s ( x x ) i n 1 1 (see PPT note) 1 n 2 s ( x x ) i n 1 1 2 x Mean ± 1 s.d. Take difference of EACH datapoint from the mean and square it: 1. Calculate the mean 2. Do a summation of (every datapoint – mean) 3. Divide by by n-1 4. To get from variance to s, simply take the square root. Calculating standard deviation ‘s’ Women height (inches) i xi x (xi-x) (xi-x)2 1 59 63.4 -4.4 19.0 2 60 63.4 -3.4 11.3 3 61 63.4 -2.4 5.6 4 62 63.4 -1.4 1.8 5 62 63.4 -1.4 1.8 6 63 63.4 -0.4 0.1 7 63 63.4 -0.4 0.1 8 63 63.4 -0.4 0.1 9 64 63.4 0.6 0.4 10 64 63.4 0.6 0.4 11 65 63.4 1.6 2.7 Degrees freedom (df) = (n − 1) = 13 12 66 63.4 2.6 7.0 s2 = variance = 85.2/13 = 6.55 inches squared 13 67 63.4 3.6 13.3 14 68 63.4 4.6 21.6 Sum 0.0 Sum 85.2 n 1 2 s ( x x ) i (n 1) 1 Mean = 63.4 Sum of squared deviations from mean = 85.2 s = standard deviation = √6.55 = 2.56 inches Mean 63.4 Calculating these by hand can be tedious. We will do a couple of examples, but will quickly switch over to doing them using a computer. Properties of Standard Deviation s is a very useful tool for data analysis A few properties of s: s measures spread about the mean and should be used only when the mean is the measure of center. s = 0 only when all observations have the same value and there is no spread. Otherwise, s > 0. s is not resistant to outliers. s has the same units of measurement as the original observations (e.g. gpa, inches-tall, miles per hour, etc) Software output for summary statistics: Excel - From Menu: Tools/Data Analysis/ Descriptive Statistics Give common statistics of your sample data. Minitab (Choosing among summary statistics) Because the mean is not resistant to outliers or skew, it should probably only Height of 30 Women be used to describe distributions that are fairly symmetrical and that don’t have 68 Boxplot for symmetric data: Plot the 67 mean and use the standard deviation for 66 Boxplot for non-symmetric data: If there is skew or outliers are present, use Height in Inches outliers. error bars. 69 65 64 63 62 61 the median in the five number summary 60 (which you could plot as a boxplot). 59 However, if there is a skew, or you can 58 not use the mean, then you shold not use SD for your data analysis. So in this case you would use the quartiles for your bars. Box Plot Boxplot Mean ± +/-SD SD Mean (Changing the unit of measurement) Variables can be recorded in different units of measurement. Most commonly, one measurement unit is a “linear transformation” (later) of another measurement unit: xnew = a + bx. Temperatures can be expressed in degrees Fahrenheit or degrees Celsius. TemperatureFahrenheit = 32 + (9/5)* TemperatureCelsius a + bx. Key Point: Linear transformations (changing the unit) do NOTchange the basic shape of a distribution (skew, symmetry, multimodal). However, they do change the values for center and spread: Multiplying each observation by a positive number ‘b’ multiplies both measures of center (mean, median) and spread (IQR, s) by ‘b’. Adding some number ‘a’ (positive or negative) to each observation adds ‘a’ to measures of center and to quartiles but it does not change measures of spread (IQR, s). Looking at Data - Distributions ** Density Curves and Normal Distributions IPS Chapter 1.3 © 2009 W.H. Freeman and Company Objectives (IPS Chapter 1.3) Density curves and Normal distributions Density curves Measuring center and spread for density curves Normal distributions The 68-95-99.7 rule Standardizing observations Using the standard Normal Table Inverse Normal calculations Normal quantile plots * Density Curve Density curve: When applied to a histogram, a density curve is drawn as a smooth approximation to the irregular bars. One of the reasons we like density curves, is that by estimating the area under the curve, we can make various predictions and calculations about the population. For example, suppose we take our sample of 25 women’s heights, plot them on a histogram, and then create a density curve. Using this sample of 25 women, we could attempt to infer information about all women in the population such as: What percentage of women in our population would be more than 6’ tall? What percentage of women are between 5’0 and 5’5? What is the likelihood of encountering women sorter than 4’6? What is the height of the tallest 90th percetile of women? etc *** Area Under the Density Curve A density curve is a mathematical model of a distribution. The total area under the curve, by definition/convention, is equal to 1, that is, 100%. The area under the curve for a range of values (e.g. scores between 6.0 and 8.0) is the proportion of all observations for that range. Histogram of a sample with the smoothed, density curve describing theoretically the population. Area under the curve contd In the first graph, the areas under the shaded bars (showing students who score less than 6.0 on the exam) of the histogram is 30.3% of the total. When the software draws its density curve, the area under the curve for students scoring less than 6.0 is 29.3%. Note how close this is to the exact figure of 30.3%. In other words, an accurately drawn density curve is a pretty effective tool for summarizing the information the data.We could leave out the histogram and simply draw the curve and we’d still have a pretty acurate picture of what was going on. Density curves come in any imaginable shape. Some are well known mathematically and others aren’t. (Median and mean of a density curve) The median of a density curve is the equal-areas point: the point that divides the area under the curve in half. (Recall that area under the curve is a proportion). The mean of a density curve is the balance point, at which the curve would balance if it were made of solid material. Finding the mean by using a density curve You can ballpark where the mean would be if you have a density curve: Eyeball the curve and try to figure out where it would ‘balance’. Median and mean of a density curve The median and mean are the same for a symmetric density curve. The mean of a skewed curve is pulled in the direction of the long tail. A density curve is an idealized description of the data In this example, the DC is exactly symmetric, while the histogram is only approximately symmetric. It will become important to distinguish the mean/sd of the ‘idealized’ density curve from the mean/sd of the actual observations (see note). (IMP: See ppt note) * Normal Distribution Definition: A continuous (solid line) distribution of probabilities that, ideally, will give a good description of data that clusters about a mean. Examples of data that cluster around a mean: people’s heights SAT scores Annual yields of corn crops in Indiana However, do be aware that just because many things fall into a Normal distribution, many other things do not. For example, income distribution is not Normal. (It is typically rightskewed). “Normal” Curves Ie: The density curve that is drawn over the histogram of data that follows a Normal distribution. Normal curves have the following properties: Symmetric Unimodal Bell-shaped Curves like this are called ‘Normal curves’ and the data distributions they describe are called ‘Normal distributions’ Note that it is possible to have a symmetric, bell-shaped curve that is not Normal. The idea of a Normal curve does not imply that other kinds of curves are somehow abnormal! (Normal distributions) Normal – or Gaussian – distributions are a family of symmetrical, bellshaped density curves defined by a mean m (mu) and a standard deviation s (sigma) : N(m,s). 1 f ( x) e 2 1 xm 2 s 2 x e = 2.71828… The base of the natural logarithm π = pi = 3.14159… (See PPT note) x A family of density curves Here, means are the same (m = 15) while standard deviations are different (s = 2, 4, and 6). 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 Here, means are different (m = 10, 15, and 20) while standard deviations are the same (s = 3) 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 ** Why do we care about Normal curves/distributions? Much of the data we examine in the real world turns out to have a normal distribution (exam scores, survival length for cancer patients, crop yields, SAT results, people’s heights, birth rate of rabbits, games of chance, etc, etc, etc) A great deal of study and research has gone into the properties of Normal distributions/curves. As a result there are many “tricks” / inferences / shortcuts that we can make when working with ‘Normal’ data. Determining the area under the curve A fairly straight-forward two step process: 1. Convert the value you are interested in (e.g. a Grade equivalent score of 7.2) into a zscore. 2. Look up your z-score in a z-table. • The value you find is the area under the curve to the left of your ‘x’. * A z-what? • A z-score measures the number of standard deviations that a data value x is from the mean m. • E.g. a z-score of 1 means your value lies exactly 1 sd above the mean. • E.g. a z-score of -0.5 means your value lies exactly one-half sd below the mean. • Know this definition! ** Calculating the z-score A z-score measures the number of standard deviations that a data value x is from the mean m. z (x m ) s • x the value under consideration • μ (mu) the mean of the population • σ (sigma) the standard deviation of the population Use the z-table Also known as the “standard Normal table” This table tells us the area under the curve to the left of the desired zscore. So if your calculated z-score is -1.42, the value you find on the ztable tells you the area under the curve to the left of -1.42. If your calculated z-score is 0.89, the value you find on the z-table tells you the area under the curve to the left of 0.89. The value is: 0.778 (or 77.8%) The value is: 0.8133 (or 81.33%) This is a widely used table. I guarantee your textbook will include a z-table There is a link to one at the top of the course web page Google z-table and you’ll find hundreds! Using the standard Normal table (z-table) Example: What is the area under the curve to the left of z = -2.40? .0082 is the area under the curve left of z = 2.40 .0080 is the area left of z = -2.41 0.0069 is the area left of z = -2.46 (…) The Worst Thing You Can Do: Is to keep plugging numbers into formulas until you find an answer that seems right. When answering these types of questions, it is VITAL that you make sure you understand the question being asked in terms of how it looks on the graph. In fact, truly understanding the question being asked should be your goal not just for Normal distribution / z-score type questions, but for nearly all statistical questions. Example Women’s heights follow the N(64.5,2.5) distribution. What percent of women are shorter than 67 inches tall (that’s 5’6”)? Note: N(64.5, 2.5) is a way of saying that this dataset: Follows a Normal distribution (“N”) With a mean of 64.5 With a standard deviation of 2.5 Example: The original versions of the SAT had a distribution of N(500,100) The distribution was Normal Mean of 500 SD of 100 ** Ex. Women heights N(µ, s) = N(64.5, 2.5) Women’s heights follow the N(64.5,2.5) distribution. What percent of women are Area= ??? shorter than 67 inches tall (that’s 5’6”)? mean µ = 64.5" standard deviation s = 2.5" x (height) = 67" Area = ??? m = 64.5” x = 67” z=0 z=1 Start by calculating the z-score. z (x m) s (67 64.5) 2.5 , z 1 1 SD' s above the mean 2.5 2.5 Use a z-table to find the area under the curve to the left of 1. The table tells us that the area under the Normal curve to the left of +1 SDs is 084 (or 84%). Conclusion: 84% of women are 67 inches tall or shorter. Percent of women shorter than 67” For z = 1.00, the value is 0.8413. This tells us that the area under the standard Normal curve to the left of z is 0.8413. N(µ, s) = N(64.5”, 2.5”) Area ≈ 0.84 Area ≈ 0.16 m = 64.5” x = 67” z=1 Tips on using Table A Because the Normal distribution is symmetrical, if you need to Area = 0.9901 determine the area to the right of a z-value, there are 2 ways that Area = 0.0099 you can go about it. z = -2.33 area right of z = area left of -z Review this figure!! area right of z = 1 - area left of z The National Collegiate Athletic Association (NCAA) requires Division I athletes to score at least 820 on the combined math and verbal SAT exam to compete in their first college year. The SAT scores of 2003 were approximately normal with mean 1026 and standard deviation 209. What proportion of all students would be NCAA qualifiers (SAT ≥ 820)? x 820 m 1026 s 209 (x m) z s (820 1026) 209 206 z 0.99 209 Table A : area under z the curve to the left of z - .99 is 0.1611 or approx. 16%. area right of 820 = = total area 1 - area left of 820 0.1611 ≈ 84% Note: The actual data may contain students who scored exactly 820 on the SAT. However, the proportion of scores exactly equal to 820 is 0 for a normal distribution is a consequence of the idealized smoothing of density curves. (See PPT note) The NCAA defines a “partial qualifier” eligible to practice and receive an athletic scholarship, but not to compete, with a combined SAT score of at least 720. What proportion of all students who take the SAT would be partial qualifiers? That is, what proportion have scores between 720 and 820? x 720 m 1026 s 209 (x m) z s (720 1026) 209 306 z 1.46 209 Table A : area under z area between 720 and 820 ≈ 9% = = area left of 820 0.1611 - area left of 720 0.0721 N(0,1) to the left of z - .99 is 0.0721 About 9% of all students who take the SAT have scores or approx. 7%. between 720 and 820. The useful thing about working with normally distributed data is that we can manipulate it, and then find answers to questions that involve comparing seemingly non-comparable distributions. We do this by “standardizing” the data. All this involves is changing the scale so that the mean now = 0 and the standard deviation =1. If you do this to different distributions it makes them comparable. z (x m ) s N(0,1) SAT vs ACT Question: Suppose that student A scores 1140 on their SAT, and student B scores 18.2 on their ACT. You are an admissions counselor and you need to make a decision based exclusively on their test score. Can you use this data to decide? Answer: If you can convert these numbers to their corresponding zscores, then absolutely! To do so, you would, of course, need to know the mean and standard deviation of the two exams. This information is routinely provided by the testing services. Ex. Gestation time in malnourished mothers What is the effect of better maternal care on gestation time and preemies? The goal is to obtain pregnancies 240 days (8 months) or longer. What improvement did we get by adding better food? m 266 s15 m 250 s20 180 200 220 240 260 280 Gestation time (days) Vitamins only Vitamins and better food 300 320 Under each treatment, what percent of mothers failed to carry their babies at least 240 days? Vitamins Only m=250, s=20, x=240 x 240 m 250 s 20 z (x m) s (240 250) 20 170 10 z 0.5 20 (half a standard deviation) Table A : area under N(0,1) to z the left of z - 0.5 is 0.3085. 190 210 230 250 270 290 Gestation time (days) Vitamins only: 30.85% of women would be expected to have gestation times shorter than 240 days. (Or we could also say that about 70% of vitamin-only women have gestations >240 days). 310 Vitamins and better food m=266, s=15, x=240 x 240 m 266 s 15 z (x m) s (240 266) 15 26 206 z 1.73 15 (almost 2 sd from mean) Table A : area under N(0,1) to z the left of z - 1.73 is 0.0418. 221 236 251 266 281 296 311 Gestation time (days) Vitamins and better food: 4.18% of women would be expected to have gestation times shorter than 240 days. Compared to vitamin supplements alone, vitamins and better food resulted in a much smaller percentage of women with pregnancy terms below 8 months (4% vs. 31%). *** The 68-95-99.7% Rule for Normal Distributions This is essentially a “shortcut” for a mental ballpark of the areas under the normal curve. It is definitely worth memorizing. About 68% of all observations are contained between 1 standard deviation of the mean. About 95% of all observations are contained between 2SDs of the mean. About 99.7% observations are contained between 3 SDs of the mean. *** The 68-95-99.7% Rule for Normal Distributions About 68% of all women are Inflection point between 62 and 67 inches tall. About 95% of all women are between 59.5 and 69.5”. Almost all (99.7%) women are between 57 and 72”. mean µ = 64.5 standard deviation s = 2.5 N(µ, s) = N(64.5, 2.5) Reminder: µ (mu) is the mean of the idealized curve, while x¯ is the mean of a sample. s (sigma) is the standard deviation of the idealized curve, while s is the s.d. of a sample. (See PPT note) * The 68-95-99.7% Rule for Normal Distributions From the rule, we can also come up with some additional numbers: Inflection point If 68% of all women are between 62 and 67 inches tall, this means that 32% are outside of that range. In other words, 16% are shorter than 62 inches, and 16% are taller than 67. Similarly, if 95% of all women are between 59.5 and 69.5”, then 5% are outside of that range. In other words, 2.5% are shorter than 59.5 and 2.5% are taller than 69.5”. mean µ = 64.5 standard deviation s = 2.5 N(µ, s) = N(64.5, 2.5) * Going in the other direction… We may also want to find the observed range of values that correspond to a given proportion/ area under the curve. For that, we use Table A backward: we first find the desired area/ proportion in the body of the table, we then read the corresponding z-value from the left column and top row. For an area to the left of 1.25 % (0.0125), the z-value is -2.24 Vitamins and better food How long are the longest 75% of pregnancies when mothers with malnutrition are given vitamins and better food? m 266 s 15 upper area 75% lower area 25% x? Table A : z value for the lower area 25% under N(0,1) is about - 0.67. 206 (x m) z x m ( z *s ) s x 266 (0.67 *15) x 255.95 256 m=266, s=15, upper area 75% upper 75% 221 236 ? 251 266 281 296 Gestation time (days) Remember that Table A gives the area to the left of z. Thus, we need to search for the lower 25% in Table A in order to get z. The 75% longest pregnancies in this group are about 256 days or longer. 311 Tips on using Table A To calculate the area between two z- values, first get the area under each zvalue. Then simply subtract one from the other.. A common mistake made by students is to subtract both z values. But the Normal curve is not uniform. area between z1 and z2 = area left of z1 – area left of z2 ** Is the data Normal? Deciding whether data does indeed show a Normal (or, close to Normal) distribution is a very important question. All the examples we’ve been discussing above involving z-scores assume that the data is Normal. If the data was not Normal, all of our answers and calculations would be flawed. Recall that there are other types of distributions out there besides the Normal distribution. Binomial Poisson Etc Each type of distribution has its own characteristic formulas, calculations, inference techniques, etc. Again, one of the more common and useful distributions, and therefore the one we will spend lots fo time discussing, is the Normal distribution. A graphing technique for assessing if data is Normal: Normal quantile plots Simply eyeballing a curve to see if it is bell-shaped, symmetric, etc is not very accurate. One mathematical way of determining whether a distribution is indeed approximately normal is to plot the data on a normal quantile plot. The data points are ranked and the percentile ranks are converted to z-scores with Table A. The z-scores are then used for the x axis against which the data are plotted on the y axis of the normal quantile plot. If the distribution is indeed normal the plot will show a straight line, indicating a good match between the data and a normal distribution. Systematic deviations from a straight line indicate a non-normal distribution. Outliers appear as points that are far away from the overall pattern of the plot. Good fit to a straight line: the distribution of rainwater pH values is close to normal. Curved pattern: the data are not normally distributed. Instead, it shows a right skew: a few individuals have particularly long survival times. Normal quantile plots are complex to do by hand, but they are standard features in most statistical software. (The “standard Normal distribution”) Because all Normal distributions share the same properties, we can standardize our data to transform any Normal curve N(m,s) into the standard Normal curve N(0,1). N(64.5, 2.5) N(0,1) => x z Standardized height (no units) For each x we calculate a new value, z (called a z-score).