Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Data Mining in GEO and Beyond
Steven Chen
Pengcheng Lu
Andrew Yi
Outline
General introduction of GEO database and basic search
functions (Steven)
Introduction of a powerful search engine for GEO
database and real example illustration (Pengcheng)
Bioinformatics meta analysis tool introduction (Andrew)
Gene Expression Omnibus (GEO):
Gene Expression and Molecular Abundance Data Repository
A public repository for the archiving and distribution of
gene expression data submitted by the scientific
community.
MIAME compliant data.
Minimum Information About a Microarray Experiment
http://www.mged.org/Workgroups/MIAME/miame.html
Convenient for deposition of gene expression data, as
required by funding agencies and journals.
Curated, online resource for gene expression data
browsing, query, analysis and retrieval.
GEO Architecture
GEO has four kinds of data records
Platform (GPL) = the technology used and the features detected.
Sample (GSM) = preparation and description of the sample.
Series (GSE) defines a set of samples and how they are related.
DataSets (GDS) sample data collections assembled by GEO staff.
Submitters may provide raw data
Original microarray scans
Raw quantification data
GEO Architecture
Submitted by
Manufacturer*
GPL
Platform
descriptions
Submitted by
Experimentalists
GSM
GSE
Grouping of
Raw/processed
slide/chip data
spot intensities
from a single “a single experiment”
slide/chip
Curated by
NCBI
GDS
Grouping of
experiments
Data Relationship at GEO
Platform[GPL]
Sample [GSM GSM GSM GSM ... GSM]
Submitted
Series[GSE]
Dataset[GDS]
Gene Profiles
Curated
GEO Home Page
Simple interface to:
show status
find documentation
query data
browse data
submit data Basic Search: Repository Browser
Selecting the total public data or Repository Browser links on the GEO
home page, takes you to the Repository Browser, listing:
number of each type of submitted file, both public and unreleased
the total number of each technology type under Platforms
the total number of each Sample type
Basic Search: Browse Platforms
All GEO submissions need to be associated with a platform file. These
describe the features on a given platform, required to understand the data.
A platform file must be submitted if one is not already present in GEO.
Commercial array platform files are submitted to GEO by the manufacturer.
Basic Search: Browse Platforms
The table can be sorted on any field except organism by clicking on the header.
Specific platform files can be found using the ‘Find Platform’ option.
Accession:
Title:
Samples:
GEO ID brief description number of samples
of platform
in GEO associated
with platform ID
Contact: Technology:
submitter platform
type
Release date:
when file is
publicly
accessible
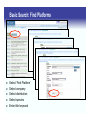
Basic Search: Find Platforms
Select ‘Find Platform’
Select company
Select distribution
Select species
Enter title keyword
Basic Search: Find Platforms (continued)
Start the platform search
Select the accession for the U133 plus 2.0 array
Scroll down to find data table information
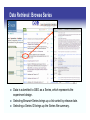
Data Retrieval: Browse Series
Data is submitted to GEO as a Series, which represents the
experiment design.
Selecting Browse>Series brings up a list sorted by release date.
Selecting a Series ID brings up the Series file summary.
Data Retrieval: Series Accession Page
Biological sample
summary
Design summary
Publication
information
Platform (total)
Samples (total)
Data Retrieval: Sample File Summary
Sample
preparation
Hybridization
and data
processing
Platform
Series
Data Retrieval: Sample File Data Table
Data table field
descriptions
Truncated data table
from Quick view
Total data rows and
file size
Supplementary raw
data file
Querying GEO with IDs from Papers
A common way to access GEO data is through accessions from papers.
Online journals include hyperlinks to the GEO accession page.
Or, at the GEO home page enter the accession into the Query>GEO
accession text box
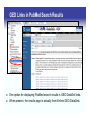
GEO Links in PubMed Search Results
One option for displaying PubMed search results is GEO DataSet links.
When present, the results page is actually from Entrez GEO DataSets.
Advanced Searches
GEO data can be queried as:
Datasets: experiment-centric view using Entrez GEO DataSets
Gene profiles: gene-centric view using Entrez GEO Profiles
Selecting either takes you to a similar Entrez introduction page
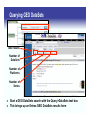
Querying GEO DataSets
Total results
Number of
DataSets
Number of
Platforms
Number of
Series
Start a GEO DataSets search with the Query>DataSets text box
This brings up an Entrez GEO DataSets results form
DataSet Search Result
DataSet ID
Description
Platform
Reference Series
Supplementary
files
Number of
Samples and
truncated list
Cluster image
Select the DataSet ID or click on the cluster image to go to the DataSet record.
GEO DataSet Record
Experiment design
and DataSet
information.
Sample and analysis
information.
Data retrieval.
Selecting analysis
takes you to the data
clustering interface.
Selecting the cluster
image takes you to
the clustering page
GEO Gene Profiles
GEO DataSet ID
Platform ID,
Platform Feature
ID
Gene description
Target sequence
accession
Expression profile
GEO Gene Profiles use gene IDs from Platform files to show the
expression of a gene across DataSets.
Entering a gene ID into the Query>Gene profiles text box takes you
to the Entrez results page.
Advanced Search outside of GEO
GEOmetadb applications
Web-based query engine, supported by a MySQL database backend.
GEOmetadb was developed in an attempt to make querying the
GEO metadata both easier and more powerful.
All GEO metadata records as well as the relationships between
them are parsed and stored in a local MySQL database
URL: http://gbnci.abcc.ncifcrf.gov/geo/
BioConductor packages:
GEOquery
GEOmetadb
Live Demo at GEOmetadb
Live Demo at GEOmetadb
BioConductor Packages
GEOquery package
GEOquery effectively establishes a bridge between GEO
microarray data and BioConductor and R facilities
GEOquery is used when GEO accession number is known and
data manipulation can be done in R to create expression data
and experimental design files in the same format as other
BioConductor packages can further work on
An Example of Using GEOquery
R Script:
library("GEOquery")
gse5325<-getGEO( "GSE5325" , GSEMatrix=FALSE )
gene<- Table(GPLList(gse5325)[[1]])$GeneSymbol
gse5325.matrix<- do.call("cbind", lapply(GSMList(gse5325)[1:105],
function(x) { tab <- Table(x)[,2] return(tab)}))
data<-data.frame(gene,gse5325.matrix)
data2<-data[data$gene%in%"MYC"|data$gene%in%"PTEN",]
data2[, 1:6]
> data2[, 1:6]
gene GSM120468
6168 MYC -1.635421
7166 PTEN
NA
8763 PTEN 1.297435
13327 PTEN
NA
18409 PTEN
NA
21865 PTEN
NA
24305 MYC -1.809964
24532 MYC -1.048360
GSM120469 GSM120470 GSM120475 GSM120477 GSM120478
0.80790556 -3.100395
-1.0790637 -1.107209
-1.580962
NA
NA
NA
NA
NA
-0.09709502 1.065820
0.9462094
1.536822
1.180152
NA
NA
NA
NA
NA
NA
NA
NA
NA
NA
NA
NA
NA
NA
NA
0.62828170
-4.038665
-1.2147221
-1.202033
-1.672025
0.75648633
-3.485740
-1.2723427
-1.145341
-1.751741
BioConductor Packages(Cont.)
GEOmetadb package
GEOmetadb BioConductor package is simply a thin wrapper
around the GEOmetadb SQLite database.
The RSQLite package(James, 2008) includes an embedded
SQLite database engine and can interact with any SQLite
database.
The function getSQLiteFile is the standard method for
downloading and unzipping the most recent GEOmetadb SQLite
file from server.
An Example of Using GEOmetadb
R Script:
library(GEOmetadb)
getSQLiteFile()
con<-dbConnect(SQLite(),"GEOmetadb.sqlite")
sql<-paste("SELECT DISTINCT gse.gse, gse.pubmed_id, gse.title", "FROM", " gsm
JOIN gse_gsm ON gsm.gsm=gse_gsm.gsm", " JOIN gse ON gse_gsm.gse=gse.gse", "
JOIN gse_gpl ON gse_gpl.gse=gse.gse", " JOIN gpl ON gse_gpl.gpl=gpl.gpl",
"WHERE", " gse.summary LIKE '%lung%cancer%' AND", " gpl.organism LIKE '%Homo
sapiens%'", sep = " ")
rs<-dbGetQuery(con, sql)
print(rs[,1])
> rs[,1]
[1] "GSE10025" "GSE10072" "GSE10089" "GSE10096" "GSE10309" "GSE1037"
[7] "GSE10431" "GSE10445" "GSE10799" "GSE1081" "GSE10841" "GSE10847"
[13] "GSE10957" "GSE11078" "GSE11117" "GSE11559" "GSE11969" "GSE12027"
[19] "GSE12236" "GSE12280" "GSE1650" "GSE2052" "GSE2189" "GSE3202"
[25] "GSE3268" "GSE3521" "GSE3598" "GSE3707" "GSE3708" "GSE3754"
[31] "GSE4115" "GSE4127" "GSE4705" "GSE4716" "GSE4869" "GSE4882"
[37] "GSE5056" "GSE5057" "GSE5058" "GSE5059" "GSE5123" "GSE5816"
[43] "GSE5843" "GSE6013" "GSE6044" "GSE6253" "GSE6400" "GSE6413"
[49] "GSE6474" "GSE6695" "GSE6883" "GSE6960" "GSE6962" "GSE7339"
[55] "GSE7670" "GSE7878" "GSE7880" "GSE7930" "GSE8045" "GSE8332"
[61] "GSE8569" "GSE8837" "GSE8894" "GSE8987" "GSE9008" "GSE9212"
[67] "GSE9315" "GSE9994" "GSE9995"
Layers of Microarray Data Sets
A typical experiment design: A (Normal) group vs B (Tumor) group
Image
Microarray Core
Raw data
Normalized data: comparable N vs T
Signature, profile, or set
GEO
Significant differential gene list: e.g. MYC, PTEN
Essential pieces of information: N vs T, sigGene-Direction-Confidence
Definition - a set of statistically significant differentially expressed
genes and their expression directions.
EXALT
GEO Online Functionalities
Data set level:
Good Data set management in raw, GSE, and GDS
Search for data sets by gene, sample, and experiment key word
Browsing, download,
Within a data set:
clustering analysis, gene searching,
two group comparison by t-test in real time, slow, signature profile among all samples
Across data sets:
support only a single gene search
show gene expression levels within a data set
NEITHER a data set comparison NOR a signature search among
GEO data sets can be performed
Limited in the number of cancer related data sets
Signature Encoding Format in EXALT
Prostate Cancer
PR Studies
Stanford_Pollack_CaP_PNAS_V101_P811
PR Datasets
Normal
group
N Samples
VS
Signature name: normal prostate samples vs primary prostate tumors
PRCa
PR Samples
A PRca signature in triplets
(MYC-U-62, PTEN-D-38, …)
GEO
SigDB
HuCa
SigDB
Triplets format: Gene-DirCode-Score
EXALT SigDB Statistics
EXALT Daily Web Statistics
The number of EXALT page hits: 74,591
Total number of EXALT users: 1,611
Signature Database (08212008) Statistics
EXALT
Datasets Signatures Arrays
Geo
1,445
Human Cancer 446
25,613
28,862
2,069
37,644
EXALT Online Features
• Data set browsing and search
• Query data set uploading and comparison
• Signature search
• Signature comparison
Upload a Query Data set
Signature Based Dataset Searching
Example: identify a cluster of gene expression signatures related
to a query data set of prostate cancer (Pollack PNAS 2004).
The QUERY dataset has generated 3 signatures
PNAS 101(3):811-6. 2004
Normal, Cancer, Metastasis
EXALT Search in Human Cancer Signature Database ...
Total SEVEN matched Subject Data Sets
GDS2545 NCBI_Geo_GDS2545 has 3 hit (100%) with
Average pValue=1.29E-9
Analysis of metastatic prostate tumors and primary prostate tumors
J Clin Oncol 2004 Jul 15;22(14):2790-9.
Multiple Search Entries
A
B
Homologous Signatures
Search and select a query signature, and then launch a homology analysis
Launch a QUERY by selecting a signature from studies of
estrogen receptor status (ER- vs ER+, Herschkowitz et al., 2008)
Co-expression Analysis
Input: MYC, PTEN
EXALT Online Distinctive Features
http://seq.mc.vanderbilt.edu/exalt/
•
Two big signature databases that have collections of >27,000 signatures,
•
The signature annotations are integrated with the NCBI GEO and the PubMed,
•
The multiple mining strategies allow directly access and analysis,
•
The interfaces are friendly to biologists
•
All signatures are pre-computed and directly meaningful to research scientists.
Acknowledgements
Andrew Yi
Steven Chen and Pengcheng Lu
Mentors: Yu Shyr, Matusik, Al George
Posdoc: QingChao Qiu
Developers: Guangzu Zhang
Thank Yu Shyr, Ming Li, Heidi Chen
and Aixiang Jiang for suggestions.
Collaborators: Wu Jun, Xie Lu at SBIT
Funding
NCI, IG, VICTR, VICC biostatistics