Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
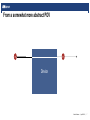
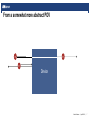
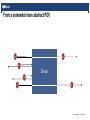
Using Today’s Fastest Chips to Design the Chips of Tomorrow Mauro Calderara, Sascha Brück, Mathieu Luisier | | Overview What we want to do How we do it Mauro Calderara | Apr 08 2016 | 2 Overview What we want to do → Quantum Transport: electrons and structures How we do it → How GPUs saved the day Mauro Calderara | Apr 08 2016 | 3 Probably you’re familiar with this Mauro Calderara | Apr 08 2016 | 4 Zooming in Mauro Calderara | Apr 08 2016 | 5 The future? (link to video: http://iis.ee.ethz.ch/~mauro/movie_SC15.avi) Mauro Calderara | Apr 08 2016 | 6 From a somewhat more abstract POV Device Mauro Calderara | Apr 08 2016 | 7 From a somewhat more abstract POV e ? Device Mauro Calderara | Apr 08 2016 | 7 From a somewhat more abstract POV e ? e Device Mauro Calderara | Apr 08 2016 | 7 From a somewhat more abstract POV ? e e e Device Mauro Calderara | Apr 08 2016 | 7 From a somewhat more abstract POV ? e e e Device e e e Mauro Calderara | Apr 08 2016 | 7 This is what we’re ultimately interested in! How do electrons behave w.r.t the device? Device Mauro Calderara | Apr 08 2016 | 8 This is what we’re ultimately interested in! How do electrons behave w.r.t the device? Device Change in parameters → change in behavior? Mauro Calderara | Apr 08 2016 | 8 This is what we’re ultimately interested in! How do electrons behave w.r.t the device? e e e e e Change in parameters → change in behavior? Device e Mauro Calderara | Apr 08 2016 | 8 This is what we’re ultimately interested in! How do electrons behave w.r.t the device? Gate voltage e e e e e Change in parameters → change in behavior? Device e Mauro Calderara | Apr 08 2016 | 8 This is what we’re ultimately interested in! Gate voltage e Material properties e e e Change in parameters → change in behavior? Device e How do electrons behave w.r.t the device? e Dimensions Mauro Calderara | Apr 08 2016 | 8 This is what we’re ultimately interested in! Gate voltage e Material properties e e e Change in parameters → change in behavior? Device e How do electrons behave w.r.t the device? e Dimensions Applies not just to transistors Batteries Storage devices ... Mauro Calderara | Apr 08 2016 | 8 How would we do that? The ‘‘easy’’ case: Mauro Calderara | Apr 08 2016 | 9 How would we do that? The ‘‘easy’’ case: → device behaves like bulk material Mauro Calderara | Apr 08 2016 | 9 How would we do that? The ‘‘difficult’’ case: Mauro Calderara | Apr 08 2016 | 10 How would we do that? The ‘‘difficult’’ case: → device behaves like atomic structure Mauro Calderara | Apr 08 2016 | 10 The cost of going small Why is this ‘‘easy’’ ... ... and this ‘‘difficult’’? Mauro Calderara | Apr 08 2016 | 11 The cost of going small Can assume is ‘‘infinite’’ and use semi empirical model. Very finite! Need to do it from first principles. Mauro Calderara | Apr 08 2016 | 12 The cost of going small Can assume is ‘‘infinite’’ and use semi empirical model. Very finite! Need to do it from first principles. Mauro Calderara | Apr 08 2016 | 12 The cost of going small Can assume is ‘‘infinite’’ and use semi empirical model. Very finite! Need to do it from first principles. Mauro Calderara | Apr 08 2016 | 12 The cost of going small Can assume is ‘‘infinite’’ and use semi empirical model. Very finite! Need to do it from first principles. Mauro Calderara | Apr 08 2016 | 12 The cost of going small Can assume is ‘‘infinite’’ and use semi empirical model. Very finite! Need to do it from first principles. Mauro Calderara | Apr 08 2016 | 12 The cost of going small Can assume is ‘‘infinite’’ and use semi empirical model. Very finite! Need to do it from first principles. Mauro Calderara | Apr 08 2016 | 12 Can assume is ‘‘infinite’’ and use semi empirical model. runtime runtime The cost of going small Very finite! Need to do it from first principles. Mauro Calderara | Apr 08 2016 | 12 Semi-empirical → O(Hours) runtime runtime The cost of going small First principles → O(Months) Mauro Calderara | Apr 08 2016 | 13 Semi-empirical → O(Hours) runtime runtime The cost of going small First principles → O(Months) Mauro Calderara | Apr 08 2016 | 13 Semi-empirical → O(Hours) runtime runtime The cost of going small First principles → O(Months) Mauro Calderara | Apr 08 2016 | 13 Overview What we want to do → Quantum Transport: electrons and structures How we do it → How GPUs saved the day Mauro Calderara | Apr 08 2016 | 14 runtime Where does all that time go? ~ 40x Mauro Calderara | Apr 08 2016 | 15 runtime Where does all that time go? ~ 40x Solve an eigenvalue problem (not discussed here). Mauro Calderara | Apr 08 2016 | 15 runtime Where does all that time go? ~ 40x Invert the matrix from before (selectively!) using a recursive algorithm. Solve an eigenvalue problem (not discussed here). Mauro Calderara | Apr 08 2016 | 15 Avoiding the inversion, use a sparse solver instead runtime Instead of trying to invert selectively, solve system using generic sparse solver package ~ 40x Mauro Calderara | Apr 08 2016 | 16 runtime Avoiding the inversion, use a sparse solver instead ~ 40x Instead of trying to invert selectively, solve system using generic sparse solver package Gain: speed, parallelism, capacity for somewhat larger systems Mauro Calderara | Apr 08 2016 | 16 runtime Avoiding the inversion, use a sparse solver instead ~ 40x Instead of trying to invert selectively, solve system using generic sparse solver package Gain: speed, parallelism, capacity for somewhat larger systems Cost: code now mem-bw bound And: not such a good fit for GPUs ... Mauro Calderara | Apr 08 2016 | 16 runtime Avoiding the inversion, use a sparse solver instead ~ 40x Instead of trying to invert selectively, solve system using generic sparse solver package Gain: speed, parallelism, capacity for somewhat larger systems Cost: code now mem-bw bound And: not such a good fit for GPUs ... Mauro Calderara | Apr 08 2016 | 16 runtime runtime Tackling the eigenvalue problem ~ 200x We’ve been able to solve that one Mauro Calderara | Apr 08 2016 | 17 Good speedup so far (now: O(Days), still not quite there...) runtime Now what? ~ 70x overall Mauro Calderara | Apr 08 2016 | 18 Good speedup so far (now: O(Days), still not quite there...) runtime Now what? ~ 70x overall But Mauro Calderara | Apr 08 2016 | 18 Good speedup so far (now: O(Days), still not quite there...) But runtime Now what? ~ 70x overall ? Mem-BW bound by sparse solver Mauro Calderara | Apr 08 2016 | 18 Good speedup so far (now: O(Days), still not quite there...) But runtime Now what? ~ 70x overall ? Mem-BW bound by sparse solver Mauro Calderara | Apr 08 2016 | 18 Good speedup so far (now: O(Days), still not quite there...) runtime Now what? ~ 70x overall But Mem-BW bound by sparse solver Mauro Calderara | Apr 08 2016 | 18 Good speedup so far (now: O(Days), still not quite there...) runtime Now what? ~ 70x overall Advisor But PhD student ? Mem-BW bound by sparse solver Mauro Calderara | Apr 08 2016 | 18 A Sparse Solver for Transport Problems running on GPUs Inverting sparse system not feasible -1 = Mauro Calderara | Apr 08 2016 | 19 A Sparse Solver for Transport Problems running on GPUs Inverting sparse system not feasible In our case: also not neccessary -1 = Mauro Calderara | Apr 08 2016 | 19 A Sparse Solver for Transport Problems running on GPUs Inverting sparse system not feasible In our case: also not neccessary -1 = Need first and last block rows only Mauro Calderara | Apr 08 2016 | 19 A Sparse Solver for Transport Problems running on GPUs Inverting sparse system not feasible In our case: also not neccessary -1 = Need first and last block rows only If we can compute this fast, we can interleave the solving step with the BC computation obtain the full solution very efficiently Mauro Calderara | Apr 08 2016 | 19 Obtaining the first and last block columns of the inverse for i = N:1 𝑋𝑖 ← (𝐴𝑖,𝑖 − 𝐴𝑖,𝑖+1 𝑋𝑖+1 ) \ 𝐴𝑖,𝑖−1 Recursive algorithm based on the Schwinger-Dyson equation for i = 2:N 𝑄𝑖 ← −𝑋𝑖 𝑄𝑖−1 Mauro Calderara | Apr 08 2016 | 20 Obtaining the first and last block columns of the inverse for i = N:1 𝑋𝑖 ← (𝐴𝑖,𝑖 − 𝐴𝑖,𝑖+1 𝑋𝑖+1 ) \ 𝐴𝑖,𝑖−1 Recursive algorithm based on the Schwinger-Dyson equation for i = 2:N 𝑄𝑖 ← −𝑋𝑖 𝑄𝑖−1 Mauro Calderara | Apr 08 2016 | 20 Obtaining the first and last block columns of the inverse Recursive algorithm based on the Schwinger-Dyson equation for i = N:1 𝑋𝑖 ← (𝐴𝑖,𝑖 − 𝐴𝑖,𝑖+1 𝑋𝑖+1 ) \ 𝐴𝑖,𝑖−1 for i = 2:N 𝑄𝑖 ← −𝑋𝑖 𝑄𝑖−1 N-2 N-1 N N+1 𝐴 𝑋 Mauro Calderara | Apr 08 2016 | 20 Obtaining the first and last block columns of the inverse Recursive algorithm based on the Schwinger-Dyson equation for i = N:1 𝑋𝑖 ← (𝐴𝑖,𝑖 − 𝐴𝑖,𝑖+1 𝑋𝑖+1 ) \ 𝐴𝑖,𝑖−1 for i = 2:N 𝑄𝑖 ← −𝑋𝑖 𝑄𝑖−1 N-2 N-1 N N+1 𝐴 𝑋 Mauro Calderara | Apr 08 2016 | 20 Obtaining the first and last block columns of the inverse for i = N:1 𝑋𝑖 ← (𝐴𝑖,𝑖 − 𝐴𝑖,𝑖+1 𝑋𝑖+1 ) \ 𝐴𝑖,𝑖−1 Recursive algorithm based on the Schwinger-Dyson equation for i = 2:N 𝑄𝑖 ← −𝑋𝑖 𝑄𝑖−1 xGEMM + xGESV + xGEMM N-2 N-1 N N+1 𝐴 𝑋 Mauro Calderara | Apr 08 2016 | 20 Obtaining the first and last block columns of the inverse for i = N:1 𝑋𝑖 ← (𝐴𝑖,𝑖 − 𝐴𝑖,𝑖+1 𝑋𝑖+1 ) \ 𝐴𝑖,𝑖−1 Recursive algorithm based on the Schwinger-Dyson equation for i = 2:N 𝑄𝑖 ← −𝑋𝑖 𝑄𝑖−1 xGEMM + xGESV + xGEMM Very fast on accelerators N-2 N-1 N N+1 𝐴 𝑋 Mauro Calderara | Apr 08 2016 | 20 Obtaining the first and last block columns of the inverse for i = N:1 𝑋𝑖 ← (𝐴𝑖,𝑖 − 𝐴𝑖,𝑖+1 𝑋𝑖+1 ) \ 𝐴𝑖,𝑖−1 Recursive algorithm based on the Schwinger-Dyson equation for i = 2:N 𝑄𝑖 ← −𝑋𝑖 𝑄𝑖−1 xGEMM + xGESV + xGEMM Very fast on accelerators N-2 N-1 N N+1 𝐴 𝑋 Parallelizable Mauro Calderara | Apr 08 2016 | 20 A Sparse Solver for Transport Problems running on GPUs Runs on GPUs, compute bound Mauro Calderara | Apr 08 2016 | 21 A Sparse Solver for Transport Problems running on GPUs Runs on GPUs, compute bound Performance [log(FLOPS)] Arithmetic Intensity [log(FLOPS/Byte)] Mauro Calderara | Apr 08 2016 | 21 A Sparse Solver for Transport Problems running on GPUs Runs on GPUs, compute bound Performance [log(FLOPS)] Interleaves with EV computation Arithmetic Intensity [log(FLOPS/Byte)] Mauro Calderara | Apr 08 2016 | 21 A Sparse Solver for Transport Problems running on GPUs Runs on GPUs, compute bound Performance [log(FLOPS)] Interleaves with EV computation Memory efficient Arithmetic Intensity [log(FLOPS/Byte)] Mauro Calderara | Apr 08 2016 | 21 A Sparse Solver for Transport Problems running on GPUs Runs on GPUs, compute bound Performance [log(FLOPS)] Interleaves with EV computation Memory efficient Much faster than sparse solvers Arithmetic Intensity [log(FLOPS/Byte)] Mauro Calderara | Apr 08 2016 | 21 A Sparse Solver for Transport Problems running on GPUs Runs on GPUs, compute bound Performance [log(FLOPS)] Interleaves with EV computation Memory efficient Much faster than sparse solvers Arithmetic Intensity [log(FLOPS/Byte)] Whole simulation: O(Hours) Mauro Calderara | Apr 08 2016 | 21 A Sparse Solver for Transport Problems running on GPUs Runs on GPUs, compute bound Performance [log(FLOPS)] Interleaves with EV computation Memory efficient ~ 10x / 80x Much faster than sparse solvers Arithmetic Intensity [log(FLOPS/Byte)] Whole simulation: O(Hours) Mauro Calderara | Apr 08 2016 | 21 Summary Mauro Calderara | Apr 08 2016 | 22 Summary Transforming a sparse problem to a dense one can be a good thing Mauro Calderara | Apr 08 2016 | 22 Summary Transforming a sparse problem to a dense one can be a good thing Large speedup over state of the art (15x - 150x) Mauro Calderara | Apr 08 2016 | 22 Summary Transforming a sparse problem to a dense one can be a good thing Large speedup over state of the art (15x - 150x) Significant increase in capacity (100’000 atoms → 10x - 100x) Mauro Calderara | Apr 08 2016 | 22 Summary Transforming a sparse problem to a dense one can be a good thing Large speedup over state of the art (15x - 150x) Significant increase in capacity (100’000 atoms → 10x - 100x) Uses hybrid ressources very efficiently (15 PF sustained) Mauro Calderara | Apr 08 2016 | 22 Summary Transforming a sparse problem to a dense one can be a good thing Large speedup over state of the art (15x - 150x) Significant increase in capacity (100’000 atoms → 10x - 100x) Uses hybrid ressources very efficiently (15 PF sustained) Made ballistic ab-initio QT simulations for realistic structures a reality Mauro Calderara | Apr 08 2016 | 22 (link to video: http://iis.ee.ethz.ch/~mauro/movie_Ag_Switch.avi) Mauro Calderara | Apr 08 2016 | 23 Questions? Mauro Calderara | Apr 08 2016 | 24