Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
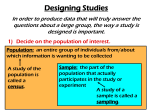
Soci708 – Statistics for Sociologists Module 5 – Producing Data: Statistical Issues in Research Design1 François Nielsen University of North Carolina Chapel Hill Fall 2007 1 Adapted from slides for the course Quantitative Methods in Sociology (Sociology 6Z3) taught at McMaster University by Robert Andersen (now at University of Toronto) 1 / 60 Goals of This Module É É Discuss various ways of collecting data and their implications for statistical analysis Observational studies É É É Probability versus nonprobability samples Experimental studies Missing data É É Types of missing data and their problems Strategies for coping with missing data 2 / 60 Science of Sampling While the individual man is an absolute puzzle, in the aggregate he becomes a mathematical certainty. You can never foretell what any one man will do, but you can say with precision what an average number will be up to. Individuals vary, but averages remain constant. — Sir Arthur Conan Doyle2 Source: Worcester, R. 1991. British Public Opinion. London: Basil Blackwell, p.151. 2 Author of the Sherlock Holmes series 3 / 60 Adolphe Quetelet (1796 – 1874) Inventor of l’homme moyen (Average Man) Concept É Born in Ghent, died in Brussels É Essai de physique sociale (1835) É Invents notion of average person central to social statistics É Invents body-mass index (BMI): BMI = weight (Kg) height2 (m2 ) É Normal BMI range: 18.5–25 É Corresponds with Florence Nightingale (1820 – 1910) 4 / 60 What is Sampling? É Process of selecting a small number of cases (sample) in a way that it will accurately represent a larger number of cases (population) É To provide useful descriptions of a population, the sample must contain essentially the same variations as the population É If all members of society were identical in all respects, we would not need to sample Two Major Types of Samples: É É É Non Probability Probability or Random 5 / 60 General Sampling Terms (1) É Population: This is the group of study elements about which we want to make generalizations É É Finite population: E.g., all eligible voters in Canada Infinite population: Resulting from a process: e.g., computer chips made by a certain assembly line; members of species mus musculus É Sampling Frame: List of cases in the population. Should include all elements once and only once: No duplications or omissions. É Sampling Pool: List of numbers to choose from in random digit dialing É Sampling Element: Each case that is being sampled from the population 6 / 60 General Sampling Terms (2) É Sampling Ratio: Percentage of population that is in the sample É Sampling ratio = sample/population, e.g., sample size = 1000 population = 1, 000, 000 Sampling Ratio = 1000/1, 000, 000 = 0.001 or 0.1% É Population Parameter: True value of a feature (e.g. percentage, mean) in the whole population É Statistic: Value of the feature in the sample data. Statistics are often used to estimate an unknown population parameter 7 / 60 Validity & Sampling Bias É External validity: The degree to which the conclusions of a study would hold for other persons in other places and at other times. Does our sample represent the population? É Sampling Bias: Those selected for the sample are not “typical” or “representative” of the population. Two types of sampling bias: É Noncoverage: Some groups in the population are systematically left out of the process of choosing the sample É É E.g., homeless people with no telephone Nonresponse: Associated with survey research – when an individual chosen for the sample canŠt be reached or refuses to cooperate É E.g., Current Population Survey (CPS) has low nonresponse rate (3%–4%); polls by opinion polling firms may be as high as 50%–60% 8 / 60 Non-probability Samples É Haphazard samples (convenience samples; voluntary response samples) É No plan – usually not representative Quota samples É É Match proportion of selected groups to population Acceptable in exploratory research Purposive samples (judgmental samples) É Acceptable for difficult to locate, special populations (e.g., homeless people) Snowball samples (network samples) É Used in special situations when it is difficult to obtain a list of the population, but people know one another 9 / 60 Development of Scientific Sampling (1) Early Modern Polling (1920-1932) É Using convenience samples Literary Digest correctly predicted all US elections from 1920 to 1932 É É Literary Digest gained great prestige Disaster in 1936 election (Predicted Landon over FDR) É É É 2,000,000 of 10,000,000 questionnaires returned Biased sampling frame based on LD subscription list, car & telephone ownership Excluded poor & low response rate 10 / 60 Development of Scientific Sampling (2) Era of Quota Sampling (1936-1944) É Gallup used quota sampling in 1936, correctly predicting FDR’s win É É É Quotas on gender, urban/rural, education, race Other firms began using quotas Disaster in 1948 election – wrongly predicted Dewey victory; Truman won huge victory É É Quotas were not representative of population (they were based on 1940s census data which under-represented urban population) Stopped polling too soon 11 / 60 Probability or Random Sampling É É A probability or random sample (in general) is one chosen by chance, so that each possible sample has a known probability of being chosen Typically this condition is relaxed somewhat to mean: Each case has a known probability of being selected É É É Outcomes are predictable in the long run over many cases Selection of cases is “mechanical” and thus rules out bias or influence by the researcher in the selection process Random sampling forms the basis of inferential statistics, i.e. deriving conclusions on a population on the basis of a sample from that population 12 / 60 Types of Random Sampling (1) Simple Random Samples (SRS) É A simple random sample (SRS) is a probability sample chosen in such a way that each possible sample has the same probability of being chosen É É SRS requires a good sampling frame É É Informally, one in which each case has an equal chance of being selected It must be possible to reach all cases in the population to do it properly Seldom done in practice in social research (especially with respect to survey research) É É Often cannot get a population list It is not usually the most efficient method 13 / 60 Principle of Simple Random Sampling 14 / 60 Types of Random Sampling (2) Systematic Samples É Short-cut form of random sampling (results often nearly identical to SRS) 1. Obtain a list of the population. 2. Create a sampling interval Sampling interval = Population size Sample size 3. Count cases and select every kth case, where k is the size of the interval É Cannot be used when there is a pattern in the cases É Important to begin with a random start, rather than with the first case 15 / 60 Types of Random Sampling (3) Stratified Sampling É Stratified, Random Sample É É É É Divide people or cases into homogeneous groups Select a random sample from each group Add the samples together to create a complete sample of the population Stratified, Systematic Sample É É É Divide people or cases into homogeneous groups Put the groups together a continuous list Using a random start, select a systematic sample from the list 16 / 60 Types of Random Sampling (4) 17 / 60 Types of Random Sampling (5) Multistage Cluster Samples É É Used when cases are geographically distant or when population cannot be easily listed Steps: 1. Draw a sample from a collection of cases (clusters) É e.g., select a sample of high schools in the U.S. 2. Sample individual cases from the clusters É É É É É e.g., select samples of 36 students in 10th and 12th grades Probability Proportionate to Size (PPS) Used when clusters are of greatly differing sizes Each cluster is given a chance of selection that is proportionate to its size Caution: Multi-stage cluster samples are prone to high sampling error. Errors are compounded at each stage 18 / 60 Cluster Sampling Example (1) É Goal: A national election study. Want a sample of 3000. É Problem: No complete population list Solution: Multi-Stage Cluster Sample É 1. Start with a list of all parliamentary constituencies 2. Randomly select 30 constituencies 3. Randomly select 10 polling stations within each selected constituency 4. Randomly select 10 people from each selected polling station area 5. Add all the “clusters” together (N=3000) 19 / 60 Cluster Sampling Example (2) É Goal: Study the attitudes of Catholic women in England. Want a sample of 1000. É Problem: No population list Solution: Multi-Stage Cluster Sample É 1. 2. 3. 4. 5. Start with a list of all Catholic churches Randomly select 10 geographic regions Randomly select 10 churches from each region Randomly select 10 women from congregation lists Add all the “clusters” together (N=1000) 20 / 60 Telephone Sampling É É Most commonly used sampling technique for national surveys in Canada We must consider the sampling pool É É É The entire set of numbers used to get the desired number of completions We always need to select far more numbers to call than we need because of nonresponse and non-usable numbers The sampling pool can be determined using list sampling or random digit dialing 21 / 60 Random Digit Dialing (1) É A group of probability sampling techniques É Does not give equal chance of selection, however É É Some households have more than one phone, but post-weighting can adjust for this Limits noncoverage error É Overcomes problem of unlisted phone numbers when using directories É Approx 1/3 are unlisted (Highest in urban areas) 22 / 60 Random digit dialing (2) Steps to generating a sampling pool 1. Gather telephone prefixes É Not always straightforward since areas of interest may not correspond to prefix boundaries 2. Determine number of lines per prefix and stratify the final sample by prefix É Some prefixes have more residential lines 3. Identify non-eligible banks of suffixes É Reduces interviewer costs 4. Randomly generate a list of numbers É Computer generated numbers; table of random numbers; added-digits techniques 23 / 60 Random digit dialing (3) Determining the Sampling Pool size É Size of Sampling Pool = FSS (HR)(1 − REC)(1 − LE) where: É É É É FSS = Final Sample Size; HR = Hit Rate (estimate of proportion of numbers not working residential lines); REC = Respondent Exclusion Criteria (estimate of proportion who are not part of target population); LE=Loss of Eligibles (likely nonresponse rate) 24 / 60 Sampling Pool Size An example É FSS: We want to interview 1000 women É HR: Estimate that .5 of phones are residential (based on previous research) É REC: Estimate that there will be no woman in about .25 of households É LE: Estimate the nonresponse rate to be about .3 with 8 callbacks Size of SP = = = FSS (HR)(1 − REC)(1 − LE) 1000 (.5)(1 − .25)(1 − .3) 1000 .2625 = 3800 25 / 60 Telephone sampling: Selecting within households 1. Uncontrolled selection 1.1 Interviewing the first person who answers the phone É É Will not give a representative sample Telephone answers are not randomly distributed within the household unit 1.2 Allowing interviewers to select respondents within the household É É Typically they will simply choose those who are home Increases selection bias 26 / 60 Telephone sampling: Selecting within households 2. Controlled selection 2.1 Youngest man/youngest woman at home 2.2 Random selection from listing of household members É É All eligible respondents are identified and ordered according to some criteria (such as age and gender) Selection table guides choice of respondent 2.3 ‘Next birthday’ methods É In theory should provide a random selection within the household Callbacks and Substitution: É If the requested respondent is not home, many callback attempts should be made – there should be no substitution 27 / 60 Sample Weighting 1. Over-sampling small populations É É Used in stratified samples to ensure representation of a small group Before data analysis, correct for the over sampling by weighting it downwards 2. Known demographic attributes É É É Information exists on some demographic variables of interest, but you canŠt sample them directly Compare sample to the population along the demographic lines for which you have information Post-weight people in the sample upward or downward in the appropriate direction 28 / 60 Determining Sample Size How much sampling error are you willing to accept? É Sample size needed given desired confidence level & margin of error 95% Confidence level 90% Margin of error 5% Population size Required sample size 100 1,000 10,000 100,000 1,000,000 79 278 370 383 384 3% 92 521 982 1,077 1,088 5% 73 216 268 275 275 3% 88 434 711 760 765 29 / 60 Review of the Sampling Process 1. Decide on the population that you want to study 2. Determine the appropriate sampling method É É Probability samples best (SRS best, Cluster samples for national surveys) Nonprobability samples used in special circumstances (exploratory research, hard to reach populations) 3. Obtain a sampling frame 4. Pick your sample from the sampling frame É Over-sampling? Stratification? 5. Perform statistical analyses, post-weighting the sample if necessary 30 / 60 Finding Evidence of Causation Does eating hot peppers prevent the flu? É I eat hot peppers and didn’t get the flu É My friend eats hot peppers and didn’t get the flu É Another friend doesn’t eat hot peppers and got the flu É Last year none of my family ate hot peppers and we all got the flu; this year we all ate hot peppers and none of us got the flu É 80% of the population who didn’t eat hot peppers got the flu; Only 40% of those who did eat hot peppers got the flu – Now we can talk about a relationship, but not causation! É To be confident we’ve found a causal relationship, we need before and after measurements and controls – we need to do an experiment! 31 / 60 What is an Experiment? É Key features are manipulation and control É É More specifically, a change in the explanatory variable is imposed on subjects Classical experiments meet the three criteria for causation: 1. Empirical relationship 2. Cause precedes effect in time 3. Elimination of rival explanations (i.e., no confounding variables) É Three types of Experiments in the Social Sciences: É Natural Experiments, Field Experiments, Classical Experiments 32 / 60 Natural Experiments É A change in environment occurs naturally É Before and after measures of DV are taken É Rare, but can be instructive É Problem: no control group to compare to Examples É 1. A study assessing the impact of television on violent behaviour compares the level of violent crime in a particular society before and after the establishment of television 2. Impact of a new electoral system on social cleavage voting is assessed by comparing voting patterns before and after the change 33 / 60 Field Experiments É É A change in environment is introduced in a natural setting No before measures on the same people, but rather measure of how people generally react without the intervention É É e.g., Garfinkel’s breeching experiments Problems: É É No control group to compare to – we don’t often know what would happen if the intervention wasn’t introduced Also difficult to conduct for ethical and practical reasons 34 / 60 Classical Experiment (1) (Clinical trials or laboratory experiments) É É Strongest method for showing causation because it easily meets the requirements for causation Steps: 1. Randomization of subjects into groups: É Experimental group, and control group 2. Pre-test É Measure dependent variable 3. Treatment É Independent variable 4. Post-test É Re-measure dependent variable 5. Test for change in dependent variable 35 / 60 Classical Experiment (2) Random Assignment É É Most experiments have multiple groups Subjects are placed into the experimental or control groups using a true random process É É Each case has an equal chance of ending up in any group (e.g., subjects’ names are put into a hat and pulled out randomly) It is a purely a mechanical process – the researcher has no control over placement 36 / 60 Classical Experiment (3) Overall Structure of a Classical Experimental Design Randomization Pretest Experimental Group Treatment Posttest Treatment Compare Differences in DV Random Allocation Control Group No treatment 37 / 60 Classical Experiments (4) E.g., Impact of TV violence on attitudes 1. Select a sample of children 2. Randomly divide the children into experimental and control groups 3. Measure their attitudes at the start 4. Show the children TV programs É One group gets violent content, the other nonviolent programs 5. Re-test attitudes and examine for changes 6. Changes in attitude, even if temporary, can probably be attributed to the program (i.e., violent TV –> violent attitudes) 38 / 60 Classical Experiment (5) Other considerations É Ethics: É É Population: É É Must clearly define the eligible population Use of a Placebo: É É Often necessary to deceive people Prevents people from knowing which group they are in (avoids Hawthorne effect) Measurement: É É Standardized outcome measures (y) of known reliability and validity Double blind: Measurement by staff who do not know who is in which group 39 / 60 Assessing Validity E.g., New teaching method and grades É We want to improve grades in methods courses 1. We decide extra tutorial consulting with tutors may make a difference 2. On a test beforehand both the experiment and control group average 60% 3. I give extra teaching tutorial classes to my class, another instructor does not 4. We measure performance again: my class has an average of 55%, the other class has an average of 65% É Can we conclude that the added tutorials had a detrimental effect? 40 / 60 Issues of Internal Validity (1) Was the treatment the true cause of a change in the dependent variable? 1. Unexpected causes É An unexpected event occurs during the experiment that could affect the DV É e.g., New computers make the course easier 2. Selection Bias É Groups of subjects are not equivalent and there could be pre-existing differences among them with regard to the dependent variable É e.g., Perhaps students chose to take the course from one instructor over the other 41 / 60 Issues of Internal Validity (2) 3. Participant Attrition É É People drop out of the experiment Those who leave may differ from those remaining with regard to the dependent variable É e.g., Maybe those who drop out do not like tutorials 4. Instrumentation & Testing É Pre- and post measurements may not be comparable É e.g., The two tests measure different things 42 / 60 Issues of Internal Validity (3) 5. Diffusion of Treatment É É Contamination Subjects in the different groups communicate with each other É e.g., control group works harder or control instructor feels sorry for control group so gives extra office hours to compensate 6. Experimenter Expectancy É É Researcher may want a result, and unintentionally relay this message to subjects. Subjects then want to please the researcher. Double-blind experiments prevent this 43 / 60 Issues of External Validity The ability to generalize results to outside of the experimental conditions 1. Experimental Realism É Can’t always reproduce natural setting É e.g., Can an experimental study on tactical voting taking place when there is not an election to tell us how people will really vote? 2. Participant Reactivity É Subjects behave differently simply because they know they are being watched É e.g., Hawthorne Effect 44 / 60 Non-experimental Panel Studies É É Explicitly causal aims – the effects of a particular event over time Repeat measures on same subjects É Advantages É É É Repeat measures enables one to look at change rather than difference Removes danger of recall bias, and gives genuine “before” and “after” measures Disadvantages É É É É Attrition Conditioning Birth cohort may lack generalizability Financial and time costs 45 / 60 Missing Data É Types of missing data 1. Missing completely at random (MCAR) É Probability of response y does not depend on either x(s) or y 2. Missing at random (MAR) É Probability of response y is related to x(s) 3. Not missing at random (NMAR) É É É “Informative” missingness Probability of (non-)response to y is related to y or to other variables that were not studied Statistical inference is unaffected if MAR but less reliable when the data are MAR or NMAR 46 / 60 Methods for Handling Missing Data 1. Do nothing 2. Perform a Complete Case Analysis É Listwise deletion: Use only cases with valid values for all variables 3. Use a Weighting Adjustment method (e.g., compare respondents to census data) 4. Imputation Methods (incorporate known auxillary data) É É É É Mean imputation Nearest neighbor (especially for panel data) Regression imputation Multiple imputation 47 / 60 Multiple Imputation (1) How is it done? 1. Note: To use Multiple Imputation, the data must be MAR or MCAR 2. Impute missing values using a model that incorporates random variation 3. Do this k times (perhaps 5–10 times), producing k new data sets that are complete 4. Perform statistical modeling on each data set using standard complete – data methods 5. Average the values of the parameter estimates across the k samples to produce a point estimate 6. Standard errors can also be calculated using a more complex formula 48 / 60 Statistical Inference Parameter & Sample É From before (repeat): É É Population Parameter: True value of a feature (e.g. percentage, mean) in the whole population – usually unknown Statistic: Value of the feature in the sample data. Statistics are often used to estimate an unknown population parameter É Sampling variability: the value of a statistic varies in repeated random samples É The one central idea of statistical inference: to see how trustworthy a procedure is, ask what would happen if we repeated it many times 49 / 60 Sampling Distribution (1) Sampling Variability É Suppose that the proportion of people who agree that “The President is doing a good job with the economy” is p = .6 É If we take a sample of 2500 we might find p̂ = .609 É If we take another sample of 2500 we might have p̂ = .625 . . . É This is sampling variability É If we were to sample “many times” with n = 2500 the resulting distribution of the values of p̂ is called the sampling distribution of p̂ É We could describe this distribution with a graph (e.g., a histogram) or with numbers (mean, spread, . . . ) É The idea of the sampling distribution is the most important idea of statistics 50 / 60 Sampling Distribution (2) Computer Simulation of the Sampling Distribution É The sampling distribution of a statistic is the distribution of values taken by the statistic in all possible samples of the same size from the same population É One can approximate the sampling distribution of p̂ by simulating the drawing of many samples from a population where p = .6 É The next two slides demonstrate the sampling distributions of p̂ in 1000 SRS for p = .6 and n = 100 and n = 2500 É The three slides after that do the same thing in 500 SRS for p = .3 and n = 10, n = 100, and n = 2500 51 / 60 Sampling Distribution (3) Sampling Distribution for p = .6, n = 100 52 / 60 Sampling Distribution (4) Sampling Distribution for p = .6, n = 2500 53 / 60 Sampling Distribution (5) Sampling Distribution for p = .3, n = 10 (500 Samples) Histogram of survey10 3 2 1 0 Density 4 5 > survey10<-rbinom(500,10,0.3)/10 > survey10[1:5] [1] 0.4 0.3 0.0 0.2 0.3 > summary(survey10) Min. 1st Qu. Median 0.00 0.20 0.30 Mean 3rd Qu. Max. 0.29 0.40 0.70 > hist(survey10, probability=TRUE) > lines(density(survey10), col="red", lwd=3) 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 survey10 54 / 60 Sampling Distribution (6) Sampling Distribution for p = .3, n = 100 (500 Samples) Histogram of survey100 4 3 2 1 0 Density 5 6 7 > survey100<-rbinom(500,100,0.3)/100 > survey100[1:5] [1] 0.30 0.28 0.29 0.33 0.30 > summary(survey100) Min. 1st Qu. Median 0.1500 0.2700 0.3000 Mean 3rd Qu. Max. 0.3013 0.3300 0.4300 > hist(survey100, probability=TRUE) > lines(density(survey100), col="red", lwd=3) 0.15 0.20 0.25 0.30 0.35 0.40 0.45 survey100 55 / 60 Sampling Distribution (7) Sampling Distribution for p = .3, n = 2500 (500 Samples) Histogram of survey2500 0 10 Density 20 30 40 > survey2500<-rbinom(500,2500,0.3)/2500 > survey2500[1:5] [1] 0.3196 0.3056 0.2968 0.3052 0.2900 > summary(survey2500) Min. 1st Qu. Median 0.2732 0.2940 0.2996 Mean 3rd Qu. Max. 0.3002 0.3064 0.3268 > hist(survey2500, probability=TRUE) > lines(density(survey2500), col="red", lwd=3) 0.27 0.28 0.29 0.30 0.31 0.32 0.33 survey2500 56 / 60 Sampling Distribution (8) Properties of the Sampling Distribution: Shape, Center & Spread 1. Shape: histogram looks normal; one can confirm this impression with a normal quantile plot 2. Center: center of the distributions of p̂ tends to be close to p – mean is .29 for n = 10, .3013 for n = 100 and .3002 for n = 2500 É In technical terms one says that the p̂ has no bias as an estimator of p 3. Spread: values of p̂ tend to be less spread out, the larger n – IQR is .40 − .20 = .20 for n = 10, .330 − .270 = .06 for n = 100 and .3064 − .2940 = .0124 for n = 2500 57 / 60 Sampling Distribution (9) Properties of the Sampling Distribution: Bias & Variability É É Bias: concerns the center of the sampling distribution. A statistic used to estimate a parameter is unbiased if the mean of its sampling distribution is equal to the true value of the parameter being estimated Variability of a statistic – described by the spread of its sampling distribution: É É É this spread is determined by the sampling design and the sample size n statistics from larger probability samples have smaller spreads Controlling bias & variability: É É To reduce bias: use random sampling – statistic computed from a SRS is unbiased, neither consistently overestimating or underestimating the population parameter To reduce variability: use a larger sample – statistic computed from a larger sample has smaller spread 58 / 60 Sampling Distribution (10) Bias & Variability Illustrated in the Context of Target Shooting (Moore $ McCabe 2006) 59 / 60 Glimpses Ahead É The idea of sampling distribution applies to all kinds of statistics used as estimators of population parameters – proportion, mean, variance, regression coefficients, etc. É The next step if to develop principles of probability theory, and from them develop a mathematical description of the sampling distribution of a statistic É The standard deviation of the sampling distribution of the statistic is called the standard error of the statistic The standard error is then used to construct É É É confidence intervals for the parameter tests of hypothesis on the value of the parameter É Constructing confidence intervals & tests of hypothesis is called statistical inference É And that’s all there is to it! 60 / 60