Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
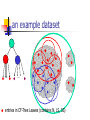
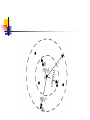
A Summary to Current Clustering Methods and OPTICS: Ordering Points To Identify the Clustering Structure Presented by Ho Wai Shing Overview Introduction Current Clustering Techniques OPTICS Discussions Introduction What is clustering? Given: a dataset with N points in a d dimensional space Task: find a natural partitioning of the points into a number (k ) of closely related groups (clusters) and noise Introduction Example Application To find similar electronic parts from their design blue-prints: use Fourier transform to transform contours of parts into coefficients do clustering on the coefficients discuss this later in the talk Introduction What are the main concerns? Efficiency Effectiveness Scalability Interactivity Current Techniques can be classified into groups hierarchical vs partitioning bottom-up merging vs flat partitioning centroid-based vs density-based 1 or more representative points for a cluster Several Clustering Algorithms k -mean BIRCH DBSCAN CURE / C2P OPTICS k-mean partitions the space into k clusters each cluster is represented by the mean of the points belong to this cluster iteratively refines the k representative points until reaching a local minimal on total distances within clusters k-mean the clusters must be convex, and should have similar size (may not be the case in real data) need to scan the database many times (slow) easily disturbed by outliers (every point counts in calculating the mean) an example dataset BIRCH use CF-Tree to summarize the data points so that everything are in memory points will be merged to a leaf entry of the CF-Tree if they are similar points will be stored in an “extension” if no similar leaves can be found build clusters over those leaves instead of the original data points an example dataset entries in CF-Tree Leaves (contains N, LS, SS) an example dataset … … entries in CF-Tree Leaves (contains N, LS, SS) BIRCH basically hierarchical one of the fastest algorithm available scan the data only once can remove some outliers can be used as a pre-clustering step the result depends on inserting order DBSCAN the first density-based algorithm without grid clusters = collections of densityconnected points definitions: directly density-reachable density-reachable density-connected r is directly density-reachable from q DBSCAN start with an arbitrary point, perform k-NN (k-nearest-neighbor) search for that point if it is dense then we grow that point into a cluster find another point until we exhaust all the points DBSCAN good: can find arbitrary shaped clusters intuitive definition of clusters reasonable complexity if index is available for kNN search bad: difficult to determine input parameters Eps and MinPts suffers from “Chaining Effect” The Chaining Problem chain CURE instead of using all points in calculating the distance between a point and a cluster like DBSCAN, CURE uses a set of representative points within a cluster this could reduce the chaining effect CURE diagram: no longer chains actual points points are close, but representatives ain’t C2P much better than CURE in terms of efficiency (O(n2lgn) to O(nlgn + m2lgm)) accomplished by a O(nlgn) pre-clustering phase add links between all the points and their nearest neighbours condense each connected graph into a single point repeat until m points remains OPTICS Ordering Points To Identify the Clustering Structure in SIGMOD 99 by Ankerst et al. A generalization of DBSCAN + a visualization technique OPTICS Motivation: input parameters (e.g., Eps) are difficult to be determined one global parameter setting may not fit all the clusters it’s good to allow users to have flexibility in selecting clusters OPTICS definitions core-distance of a point p the distance between the point p and its MinPts’th neighbour reachability-distance of a point p w.r.t. another point o the distance between o and p, with a lower bound of core-dist(o) OPTICS start from an arbitrary point, sorts the points according to the reachability-distance this sorting can be used to produce densitybased clusters with 0 < Eps < Epsinput Reachability plot can be used to provide a good visualization tool for analyzing clusters OPTICS reachability plot OPTICS 16-d reachability plot Discussions All the methods described above fail at high-dimensional cases “The curse of dimensionality” distances between all the points are nearly the same grids are usually not dense (O(2d) grids vs O(n) points)), clusters tend to be divided by grids no efficient indices for k-NN search Discussions key observation: not all dimensions are meaningful in clustering some clusters may exist under a subset of dimensions while the others exist under another subset of dimensions leads to: feature selection subspace clustering / projected clustering References M Ankerst, M M Breunig and H-P Kriegel, J Sander, OPTICS: Ordering Points To Identify the Clustering Structure, SIGMOD’99 T Zhang, R Ramakrishnan and M Livny, BIRCH: An Efficient Data Clustering Method for Very Large Databases, SIGMOD’96 S Guha, R Rastogi and K Shim, CURE: An Efficent Clustering Algorithm for Large Databases SIGMOD’98 C C Aggarwal and P S Yu, Finding Generalized Projected Clusters in High Dimensional Spaces, SIGMOD’00 R Agrawal, J Gehrke, D Gunopulos and P Raghavan, Automatic Subspace Clustering of High Dimensional Data for Data Mining Applications, SIGMOD’98 M Ester, H-P Kriegel, J Sander and X Xu, A Density-Based Algorithm for Discovering Clusters in Large Spatial Database with Noise, KDD’96 A Nanopoulos, Y Theodoridis and Y Manolopoulos, C2P: Clustering based on Closest Pairs, VLDB’01 Questions?