Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Mutual Information and Channel
Capacity
Multimedia Security
Information
Source
Entropy
Source
symbols
A = {a 0 , a1 ,..., a M −1 }
Source
probability PA = {P0 , P1 ,..., PM −1 }
M −1
H ( A ) = − ∑ Pm log 2 Pm
(bits)
m =0
2
ai
Source
Encoder
E(.)
Ci = E (ai )
Ci ∈ B : codeword alphabet
li Δ length (Ci )
M −1
L Δ average codeword length = ∑ Pmlm
(bits )
m =0
In general L ≥ H ( A)
3
Information
Source A
observer A
Source
Encoder
E(.)
observer B
Mutual Information :
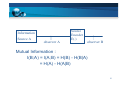
I(B;A) = I(A;B) = H(B) - H(B|A)
= H(A) - H(A|B)
4
Mutual Information
S’pose we represent the information source
and the encoder as “black boxes” and station
two perfect observes at the scene to watch
what happens.
The first observer observes the symbols
output from the source A, while the second
observer watches the code symbols output
from the encoder “E”.
5
We assume that the first observer has perfect
knowledge of source A and symbol
probabilities PA and the second observer has
equally perfect knowledge of code alphabet B
and codeword probabilities PB. Neither
observer, however, has any knowledge
whatsoever of the other observer’s black box.
6
Now s’pose each time observer B observes
a codeword he asks observer A what symbol
had been sent by the information source.
How much information does observer B
obtain from observer A?
If the answer to this is “None”, then all of the
information presented to the encoder passed
through it to reach observer B and the
encoder was information lossless.
7
On the other hand, if observer A’s report
occasionally surprises observer B, then some
information was lost in the encoding process.
A’s report then serves to decrease the
uncertainty observer B has concerning the
symbols being emitted by black box “E”.
The reduction in uncertainty about B conveyed
by the observation A is called the mutual
information, I(B;A).
8
The information presented to observer B by
his observation is merely the entropy H(B).
If the observer B observes symbol b (∈B)
and then learns from his partner that the
source symbol was a, observer A’s report
conveys information
H (B A = a ) = − ∑ Pb a log
b∈ B
2
Pb a
9
and, average over the source of all
observations, the average information
conveyed by A’s report will be
H (B A) = ∑ Pa H (B A = a ) = −∑∑ Pa Pb a log 2 Pb a
a∈ A
a∈ A b∈B
The amount by which B’s uncertainty is
therefore reduced is
I (B; A) = H (B ) − H (B A) = I ( A; B )
= ∑∑ Pb ,a log 2
b∈B a∈ A
Pb ,a
Pb ⋅ Pa
10
Since I(B;A) = H(B) - H(B|A)
and H(B|A)≧0
then I(B;A)≦H(B)
That is, the mutual information is upper
bounded by the entropy of the source encoder.
11
I(B;A) = H(B) iff H(B|A)=0
The conditional entropy is a measure of how
much information loss occurs in the encoding
process, and if it is equal to zero, then the
encoder is information lossless.
w.l.o.g., the encoder can be viewed as a
channel in which the Source alphabet is the
same as the codeword alphabet, and the
encoding function behaves like the symbol
transition map.
12
Ci
PC~
j
Ci
PC~
~
Cj
j
Ci
: transition probability of the channel
P0 0
0
P1 0
1
0
P0 1
P1 1
1
where P1 0 , P0 1 : bit-error probability.
13
Each time the source (transmitter) sends a
symbol, it is said to use the channel.
The channel capacity is the maximum
average information that can be sent per
channel use.
Notice that the mutual information is a
function of the probability distribution of A.
By changing Pa, we get different I(A;B).
14
For a fixed transition probability matrix, a
change in Pa also results in a different
output symbol distribution PB.
The maximum mutual information
achieved for a given transition probability
matrix [a fixed channel characteristics] is
the channel capacity C A = max I ( A; B )
Pa
15
• The relative entropy (or Kullback-Leibler distance)
between two probability mass function p(x) and q(x)
is defined as
⎡
p( x)
p( x) ⎤
= Exp ⎢log
D( p || q ) = ∑ p ( x) log
⎥
q
(
x
)
q
(
x
)
x
⎣
⎦
• The mutual information I(X;Y) is the relative entropy
between the joint distribution and the product
distribution:
⎡
p ( x, y )
p ( x, y ) ⎤
I ( X ; Y ) = ∑∑ p ( x, y ) log
= Exp ⎢log
⎥
p
(
x
)
p
(
y
)
p
(
x
)
p
(
y
)
x
y
⎦
⎣
16