Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
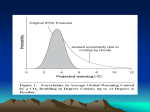
Handout 2: Data Exploration Reading Assignment: Sections 1.3, 1.4, 1.5, 1.6, and Chapter 3 We previously looked at methods of sampling and the measurement levels of data. Suppose that you are a project development manager for an energy project. Your company, a new wind power energy company in Michigan, wants to help minimize emissions while producing optimal energy levels and wishes compare their emissions with the rest of the nation as well as in Michigan. Now we will begin to discuss analyzing data; however, before doing in-depth analyses, it is important to summarize what information is present in your data. Please note that we will be using data from the annual U.S. Electric Power Industry Estimated Emissions Report for this handout. Below is a sample of ten of the 16156 observations. From the sample of data, we see that there are seven variables Year, State, Type of Producer, Energy Source, CO2, SO2, and NOX but by just looking at the sample of the data, we do not get all the information. It is known that the data is collected from all 50 states between the years of 1990 and 2009. Also, the carbon dioxide, sulfur dioxide, and nitrogen oxide measurements (all in metric tons) are taken from all eight different energy sources with all seven types of producers (Knowing this information, can you speculate whether the entire dataset is a sample or a population?) Looking at the sample of the data and the variable descriptions, state what the levels of measurement for each variable are in the table below. Also, are the numerical variables continuous, taking on any value in an interval (e.g. height, blood pressure), or discrete, taking on only one of a countable list of distinct values (e.g. number of roommates living with you)? Variable Description Year State Type of Producer Energy Source CO2 SO2 NOX 1 Categorical Data Recall that categorical data consists of groups or category names and that they may or may not have a logical ordering to them. In order to summarize categorical variables we need to count how many subjects fall within each possible category. Typically, percentages are used rather than counts because they usually are more informative than counts. This method can also be used for summarizing two or more categorical variables, which we will discuss at a later time. A relative frequency table is a listing of all possible categories along with their relative frequencies, typically given as a proportion or percent. Both counts and percentages are commonly given together (see the figure below). Relative Relative Energy Source Frequency Frequency Percentage Natural Gas 4322 0.27 27% Petroleum 4090 0.25 25% Coal 2695 0.17 17% Other 1786 0.11 11% Other Biomass 1415 0.09 9% Wood & Wood Derived Fuels 1066 0.07 7% Other Gases 675 0.04 4% Geothermal 107 0.01 1% Grand Total 16156 1.00 100% Relative Frequency Table of Energy Source A bar chart is useful for summarizing one (see figure below) or two categorical variables. These can be very helpful when comparing two categorical variables, as will be shown later. 30%# 25%# 20%# 15%# 10%# 5%# Bar Chart of Energy Source 2 # he rm al es # Ge ot he r#G as Fu el s# Ot s# W oo d# &# W oo d# De riv ed # m as he r# he r#B io Ot Ot # al Co le um # Pe tro Na t ur al #G as # 0%# A pie chart is another useful for summarizing a single categorical variable (if there are not too many categories). See the figure below. Wood'&'Wood' Derived'Fuels' 6%' Other'Gases' 4%' Geothermal' 1%' Other'Biomass' 9%' Natural'Gas' 27%' Other' 11%' Petroleum' 25%' Coal' 17%' Pie Chart of Energy Source All three figures for categorical data show the same story, just in different ways. What do you notice in the data? Completely describe what the data is showing. Which method for presenting categorical data do you like best? 3 Numerical Data Recall that numerical data measures a quantity of something. Looking a long list of disorganized values that seem unrelated can be daunting and in order to make the data more informative, we need to organize it using visual displays and numerical summaries. Ways in which we can describe visual displays of numerical data are to focus on the distribution, the overall pattern of the data. There are three summary characteristics that tend to be of interest location, spread, and shape. Also, we are interested in whether there are any outliers, unusual data values when compared to the rest of the data. We will discuss these characteristics in more depth later in this handout. We will be using data from the Emissions Report, but only data on Michigan’s CO2 emissions from other energy sources. A stem-and-leaf plot is a quick way to summarize small data sets and is also useful for ordering data from lowest to highest. The basic design of the plot is that the row ‘stem’ contains all but the last digit of a number and the ‘leaf’ within the row stem is the last digit of the number, regardless of whether it falls before or after a decimal point. Sometimes data values are truncated, or rounded, to make work easier. The example data was rounded to the ten-thousand place and the stem units are the hundred-thousand place. Stem–and–Leaf Display of Michigan’s CO2 Emmissions (Metric Tons) for Other Energy Sources (stem=100,000’s) Since these plots can be a bit difficult with larger datasets and since Excel and your calculators do not easily create stem-and-leaf plots (if at all in the case of your calculator), you will not be required to construct these. However, it is important to be able to interpret them. More information about stem-and-leaf plots can be found in the course pack. When interpreting the data above, note that the stems are split into the ‘bottom’ and ‘top’ halves for each hundred-thousand (split at each 50,000 metric tons)and that one number in the leafs represents a single observations this is not the only way to construct stem-and-leaf plots, it depends on the data. So, in the first half of the 300,000s we see that there are ten total observations with three 300,000 observations, three 320,000 observations, three 330,000 observations, and one 340,000 observation. We will come back to this plot to discuss the summary characteristics in a little while. A histogram is similar to a bar chart, but for numerical variables. It shows how many values are in various intervals of the data. Typically, when constructing histograms, we want to decide how many intervals we want, but we will just let out calculators and Excel chose these intervals for us. Once the numbers of intervals are decided, the range of the data needs to be divided into equally spaced widths and then the number of values within each interval need to be counted - Excel does this in a frequency table. You can use frequencies or relative frequencies when constructing the table and histogram. Both the frequency table and histogram are below. Note that there are not gaps between the bars, unless one of the intervals has a frequency of zero. 4 Frequency Table of Michigan’s CO2 Emissions (Metric Tons) for Other Energy Sources Histogram of Michigan’s CO2 Emissions (Metric Tons) for Other Energy Sources What are some of the similarities and difference between the stem-and-leaf plot and the histogram? A box–and–whisker plot is a simple way to picture the information in one or more five–number summaries. This plot is useful for comparing two or more groups and is also useful in identifying outliers. The five-number summary is comprised of five descriptive values from the data these being the lowest value; the cut-off points for 1/4, 1/2, and 3/4 of the data; and the highest value. The middle three values of the summary (the cut-off points) are called the lower quartile (Q1), median, and upper quartile (Q3), respectively. The ‘box’ spans from the first quartile to the third quartile with a line in the middle to represent the median and the ‘whiskers’, with the exception of possible outliers, extend from the box to the minimum and maximum. Possible outliers would be marked with an asterisk and are calculated by being far outside the box. We will discuss this idea in a bit and our calculators can do this automatically (Excel takes a little bit of work). 5 Five–Number Summary of Michigan’s CO2 Emissions (Metric Tons) for Other Energy Sources Box–and–Whisker Olot of Michigan’s CO2 Emissions (Metric Tons) for Other Energy Sources Looking at the box–and–whisker plot (and the five–number summary) you can instantly look at percentages of data, for instance, 25% of the other energy sources in Michigan emitted 214,039 metric tons or more of CO2. Things to Look for in Plots: A Summary of Graphical Features Location One of the first ideas to look for while summarizing numerical data is location or ‘center’ of the distributions of values. With this idea, we are looking at what a typical or average value of the data might be. For this class, we will be mainly looking at the average, or mean, which is the arithmetic average of the data values. This measure of center, however, does not accurately describe the CO2 data. The median is approximately the middle value in the data, every time. This measure is useful for skewed distributions (like Michigan’s CO2 emissions for other energy sources). The median is also a special type of percentile. In general, the k th percentile is a number that has k% of the data values at or below it and (100-k)% of the data values at or above it. Knowing the percentile. Recall that the definition of percentiles, we see that the median would be the Box-and-Whisker Plot uses the five-number summary to create the plot. Those five numbers are percentiles the 0th , 25th , 50th , 75th , and 100th that we label as quartiles. Other measures of center that are used are the following: Midrange → MR = Midhinge → MH = xmin + xmax 2 Q1 + Q2 2 Mode - most occurring value(s) – we will look more at this shortly. 6 Spread A large part of Statistics is studying variability, or spread, among individual measurements and the variability among different samples from the same population (we will discuss the later point in a couple of handouts). Spread helps us to look at how much variation exist in the values; if they are about the same, or if there is a grouping of values with a few unusual data values. If you recall the five-number summary, we can assess spread by looking at the range, the difference between the maximum and minimum values, or the interquartile range (IQR), the difference between the third and first quartile (the middle 50% of the data). The standard deviation is another important measure of spread which measures the average size of deviation, departure from the mean. As we see in the course pack, and below, the formula can appear daunting and difficult to calculate, but the important aspect of the standard deviation is its interpretation. For the most part, we will let the calculator and Excel handle the grunt work. Please note, that when these values had to be calculated by hand, the variance would need to be calculated first ( s2 ), then the square root of the variance would be taken to obtain the standard deviation. qP 2 (Xi −X) S= n−1 One last measurement of spread that we will look at is the coefficient of variation which is the standard deviation divided by the average ( ***Need Equation*** ). This measurement explains the percent of variation around the mean. Why is this measurement useful for comparing the variation among different variables (think of the units)? Shape The easier feature to tell from the visual display of numerical data is the shape of how the variables are distributed. By looking at the graphical representations we can tell if most of the values are clumped together with values tailing off at each end, if the values are more in one direction, or if there are two distinct groupings of values. When looking at shape, data is usually described as symmetric, similar on both sides of the center, or skewed, values are more spread out on one side of the center than the other. Symmetric data may be able to be described as bell-shaped while skewed data can be right (positively) or left (negatively) skewed. How would the data of Michigan’s CO2 emissions from other energy producers be described? Recall that the mode of a dataset is the most frequent value. The shape of a histogram can called unimodal when there is a single noticeable peak in a histogram, bimodal if there are two noticeable peaks, and so on. Some data can be described using a combination of these terms. 7 Other One last interesting feature to consider when analyzing data is to look whether any values are outliers, a data point that is not consistent with the majority of the data, or any other noticeable patterns (we will look more into patterns later in this course). Outliers can have a major influence on analyses and thus need special consideration because of the inaccurate conclusions if they are not. These inconsistent values can also cause complications in statistical procedures which cause some researchers to wrongly discard them rather than treating them as legitimate data. Outliers should never be disregarded unless there is proper justification to do so. Some possible reasons for outliers are that the outlier is: –a legitimate data value and represents natural variability for the group and variable(s) measured. –that a mistake was made while taking a measurement or entering the data. –that the individual belongs to a different group than the bulk of individuals measured. Recall that outliers can be represented with asterisk (or other marks) in box-and-whisker plots. The way they are calculated are if they are a distance greater than one and a half times the IQR greater (or less) than the third (or first) quartile. lower fence = Q1 − 1.5 ∗ IQR upper fence = Q3 + 1.5 ∗ IQR Are there any outliers present in the CO2 emissions for other energy sources in Michigan? Calculate the IQR and find the upper and lower ‘fences’. A resistant statistic is a numerical summary of the data that is not affected by extreme observations or the influence of outliers. In other words, an outlier is not likely to have a major influence on its numerical value. The summary measures that are resistant are the median, mode, midhinge, and IQR while the other summary measures discussed would be non-resistant, or affected by outliers (mean, midrange, standard deviation and variance, range, and coefficient of variation). iClicker Question Are there any outliers present in the CO2 emissions data for other energy sources in Michigan? Given: Xmin = 0, Q1 = 18013, Q2 = 94661, Q3 = 214039, Xmax = 389001 (a) Yes; since the upper fence is 508078 (b) Yes; since the lower fence is 276026 (c) No; since the upper fence is 508078 (d) No; since the lower fence is 276026 (e) No; since the upper fence is 276026 8 Numerical Descriptive Statistics The table below summarizes the CO2 emissions of other energy sources in Michigan. This table was obtained in Excel, but has also been edited to remove some of the statistics produced that are not discussed in this course as well as add some additional ones that are. Adding and Multiplying by a Constant Sometimes, it makes sense to add to or multiply by a constant to a list of data(think of switching between Celsius and Fahrenheit or adding a bonus points to an entire STAT 2160 class). There are rules that apply to these two situations, which follow. Rules for Adding a Constant Adding a constant, positive or negative, to a list of data will add the same constant to the mean, but the standard deviation will remain unchanged. Rules for Multiplying by a Constant If you multiply a list of data by a constant, positive or negative, the mean will be multiplied by the same constant while the standard deviation will be multiplied by the absolute value of the constant. Suppose the VP of sales of a mid-sized firm has decided to give a one-time bonus to her colleagues. Here are 9 associate monthly salaries in thousands of dollars: 1.2, 2.6, 3.5, 2.2, 1.4, 1.9, 4.4, 1.8, 3.8 (x = 2.5; s = 1.13) Suppose the VP decides to add $500 to each sales associate salary. What would the new mean and standard deviation be? What if the VP instead decided to add 10% to each sales associate. What would the new mean and standard deviation be? 9 iClicker Question If the data were symmetric, what would the relationship between the median and the mean be (where would they be located on the histogram)? (a) The median would be higher than the mean. (b) The median would be lower than the mean. (c) They would be relatively equal. (d) It is difficult to tell for this data. (e) There is not enough information to decide. Empirical Rule For bell-shaped data, once you know the mean and standard deviation you can determine approximate proportions of the data that will fall into any specified interval. We will discuss this more in depth later, but the ‘Empirical Rule’ gives some approximate benchmarks. 68% of the values fall within one standard deviation of the mean in either direction 95% of the values fall within two standard deviations of the mean in either direction 99.7% of the values fall within three standard deviations of the mean in either direction The Empirical Rule is also summarized in the figure below. Please note that population notation (Greek letters) is used. Source: http://www.paly.net/sfriedland/apstatnotes/chapter2/EmpiricalRule.png 10 .