
Dynamic Programming for Partially Observable Stochastic Games
... some of the challenges involved in solving the infinitehorizon case are discussed at the end of the paper. At each stage, all agents simultaneously select an action and receive a reward and observation. The objective, for each agent, is to maximize the expected sum of rewards it receives during the ...
... some of the challenges involved in solving the infinitehorizon case are discussed at the end of the paper. At each stage, all agents simultaneously select an action and receive a reward and observation. The objective, for each agent, is to maximize the expected sum of rewards it receives during the ...

Combining satisfiability techniques from AI and OR
... complete depth-first backtracking method, when attempting to solve even a satisfiable problem P , will of necessity spend the bulk of its time working on subproblems of P that are in fact unsatisfiable. After all, if the overall goal is to assign values to n variables, and the machine only backtrack ...
... complete depth-first backtracking method, when attempting to solve even a satisfiable problem P , will of necessity spend the bulk of its time working on subproblems of P that are in fact unsatisfiable. After all, if the overall goal is to assign values to n variables, and the machine only backtrack ...

Ten Challenges Redux: Recent Progress in Propositional
... graph that has all decision variables on one side, called the reason side, and false as well as at least one conflict literal on the other side, called the conflict side. All nodes on the reason side that have at least one edge going to the conflict side form a cause of the conflict. The negations o ...
... graph that has all decision variables on one side, called the reason side, and false as well as at least one conflict literal on the other side, called the conflict side. All nodes on the reason side that have at least one edge going to the conflict side form a cause of the conflict. The negations o ...

Lecture Slides (PowerPoint)
... Random-restart Hill-Climbing • Series of HC searches from randomly generated initial states until goal is found • Trivially complete • E[# restarts]=1/p where p is probability of a successful HC given a random initial state • For 8-queens instances with no sideways moves, p≈0.14, so it takes ≈7 ite ...
... Random-restart Hill-Climbing • Series of HC searches from randomly generated initial states until goal is found • Trivially complete • E[# restarts]=1/p where p is probability of a successful HC given a random initial state • For 8-queens instances with no sideways moves, p≈0.14, so it takes ≈7 ite ...

agent function
... static: state, a description of the current world rules, a set of condition-action rules action, the most recent action state <- Update-State (state, action, percept) rule <- Rule-Match (state, rules) action <- Rule-Action (rule) return action • To handle partial observability, agent keeps track of ...
... static: state, a description of the current world rules, a set of condition-action rules action, the most recent action state <- Update-State (state, action, percept) rule <- Rule-Match (state, rules) action <- Rule-Action (rule) return action • To handle partial observability, agent keeps track of ...

External Memory Value Iteration
... Guided exploration in deterministic state spaces is very effective in domain-dependent [KF07] and domain-independent search [BG01, Hof03]. There have been various attempts trying to integrate the success of heuristic search to more general search models. AO*, for example, extends A* over acyclic AND ...
... Guided exploration in deterministic state spaces is very effective in domain-dependent [KF07] and domain-independent search [BG01, Hof03]. There have been various attempts trying to integrate the success of heuristic search to more general search models. AO*, for example, extends A* over acyclic AND ...


Guided Cost Learning: Deep Inverse Optimal Control via Policy
... IOC is fundamentally underdefined in that many costs induce the same behavior. Most practical algorithms therefore require carefully designed features to impose structure on the learned cost. Second, many standard IRL and IOC methods require solving the forward problem (finding an optimal policy giv ...
... IOC is fundamentally underdefined in that many costs induce the same behavior. Most practical algorithms therefore require carefully designed features to impose structure on the learned cost. Second, many standard IRL and IOC methods require solving the forward problem (finding an optimal policy giv ...

pdf
... functions and the 0-1 loss function. They introduce the notion of well calibrated loss functions, meaning that the excess risk of a predictor h (over the Bayes optimal) with respect to the 0-1 loss can be bounded using the excess risk of the predictor with respect to the surrogate loss. It follows t ...
... functions and the 0-1 loss function. They introduce the notion of well calibrated loss functions, meaning that the excess risk of a predictor h (over the Bayes optimal) with respect to the 0-1 loss can be bounded using the excess risk of the predictor with respect to the surrogate loss. It follows t ...

FeUdal Networks for Hierarchical Reinforcement
... challenging, since the agent has to learn which parts of experience to store for later, using only a sparse reward signal. The framework we propose takes inspiration from feudal reinforcement learning (FRL) introduced by Dayan & Hinton (1993), where levels of hierarchy within an agent communicate vi ...
... challenging, since the agent has to learn which parts of experience to store for later, using only a sparse reward signal. The framework we propose takes inspiration from feudal reinforcement learning (FRL) introduced by Dayan & Hinton (1993), where levels of hierarchy within an agent communicate vi ...

Multi-agent MDP and POMDP Models for Coordination
... whether agents are coordinated or uncoordinated ...
... whether agents are coordinated or uncoordinated ...

Memory-Bounded Dynamic Programming for DEC
... that are good for a centralized belief state are often also good candidates for the decentralized policy. Obviously, a belief state that corresponds to the optimal joint policy is not available during the construction process. But fortunately, a set of belief states can be computed using multiple to ...
... that are good for a centralized belief state are often also good candidates for the decentralized policy. Obviously, a belief state that corresponds to the optimal joint policy is not available during the construction process. But fortunately, a set of belief states can be computed using multiple to ...


Improving Learning Performance Through Rational ... Jonathan Gratch*, Steve Chien+, and ...
... -parity- indices, the rational algorithm calculates the increase in confidence and the cost of allocating an additional example to each comparison. At each cycle through the main loop the algorithm allocates an example to the comparison with the highest marginal rate of return. This is the ratio of ...
... -parity- indices, the rational algorithm calculates the increase in confidence and the cost of allocating an additional example to each comparison. At each cycle through the main loop the algorithm allocates an example to the comparison with the highest marginal rate of return. This is the ratio of ...

Computational Intelligence Methods
... What function is to be learned and how will it be used by the performance system? For checkers, assume we are given a function for generating the legal moves for a given board position and want to decide the best move. I I ...
... What function is to be learned and how will it be used by the performance system? For checkers, assume we are given a function for generating the legal moves for a given board position and want to decide the best move. I I ...

Always Choose Second Best: Tracking a Moving Target on a Graph
... localization with radar [4] or sensor network management [5]. Even anomaly detection in cyberphysical systems has been approached as a problem of this form [6]. For many of these applications, sensing resources are limited, and the computational complexity of optimal policies presents a significant ...
... localization with radar [4] or sensor network management [5]. Even anomaly detection in cyberphysical systems has been approached as a problem of this form [6]. For many of these applications, sensing resources are limited, and the computational complexity of optimal policies presents a significant ...

Implicit Learning of Common Sense for Reasoning
... analysis of a combined system for learning and reasoning. Technically, our contribution is that we exhibit computationally efficient algorithms for reasoning under PACSemantics using both explicitly given rules and rules that are learned implicitly from partially obscured examples. As is typical for ...
... analysis of a combined system for learning and reasoning. Technically, our contribution is that we exhibit computationally efficient algorithms for reasoning under PACSemantics using both explicitly given rules and rules that are learned implicitly from partially obscured examples. As is typical for ...

Point-Based Policy Generation for Decentralized POMDPs
... decision-theoretic techniques that can cope with this complexity is thus an important challenge. The Markov decision process (MDP) and its partially observable counterpart (POMDP) have proved useful in planning and learning under uncertainty. A natural extension of these models to cooperative multi- ...
... decision-theoretic techniques that can cope with this complexity is thus an important challenge. The Markov decision process (MDP) and its partially observable counterpart (POMDP) have proved useful in planning and learning under uncertainty. A natural extension of these models to cooperative multi- ...

Unconstrained Univariate Optimization
... second derivative is negative and as a result, the optimum is a maximum. The problem with these ideas is that we can only calculate the derivatives at a point. So looking for an optimum using these fundamental ideas would be infeasible since a very large number of points (theoretically all of the po ...
... second derivative is negative and as a result, the optimum is a maximum. The problem with these ideas is that we can only calculate the derivatives at a point. So looking for an optimum using these fundamental ideas would be infeasible since a very large number of points (theoretically all of the po ...

Satisficing and bounded optimality A position paper
... quality of behavior that is expected when these properties are achieved. One of the first approaches to satisficing has been heuristic search. In fact, Simonhas initially identified heuristic search with satisficing. It is important to distinguish in this context between two different ways in which ...
... quality of behavior that is expected when these properties are achieved. One of the first approaches to satisficing has been heuristic search. In fact, Simonhas initially identified heuristic search with satisficing. It is important to distinguish in this context between two different ways in which ...

Pedagogical Possibilities for the N-Puzzle Problem
... Further in the paper we shall illustrate some of these advantages of using Prolog for teaching search in AI. We have made available a number of Prolog programs that we have developed to accompany the AI course [4]. An introduction to Prolog can be found in [5]. Prolog implementations of major AI alg ...
... Further in the paper we shall illustrate some of these advantages of using Prolog for teaching search in AI. We have made available a number of Prolog programs that we have developed to accompany the AI course [4]. An introduction to Prolog can be found in [5]. Prolog implementations of major AI alg ...
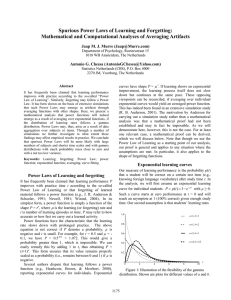
Spurious Power Laws of Learning and Forgetting:
... a characteristic of power functions. Increasing b increases the variance of the learning rate distribution. The opposite effect, decreasing the variance, will cause a narrower peak around the mean value. With very similar learning rates for all subjects, we would expect the averaged curve to also be ...
... a characteristic of power functions. Increasing b increases the variance of the learning rate distribution. The opposite effect, decreasing the variance, will cause a narrower peak around the mean value. With very similar learning rates for all subjects, we would expect the averaged curve to also be ...

Learning - TU Chemnitz
... agent can expect to accumulate over the future, starting from that state ! • rewards determine the immediate desirability of states, values indicate the long term desirability of states! • the most important component of almost all reinforcement learning algorithms is a method for efficiently esti ...
... agent can expect to accumulate over the future, starting from that state ! • rewards determine the immediate desirability of states, values indicate the long term desirability of states! • the most important component of almost all reinforcement learning algorithms is a method for efficiently esti ...

Synergies Between Symbolic and Sub
... the game of Go used multiple machine learning algorithms for training itself, and also used a sophisticated search procedure while playing the game. Another recent succesful example of integrating symbolic AI (reinforcement learning) and sub-symbolic AI (deep neural networks): Google DeepMind learni ...
... the game of Go used multiple machine learning algorithms for training itself, and also used a sophisticated search procedure while playing the game. Another recent succesful example of integrating symbolic AI (reinforcement learning) and sub-symbolic AI (deep neural networks): Google DeepMind learni ...

Fast Parameter Learning for Markov Logic Networks Using Bayes Nets
... (true relationship groundings). It can extended for conditional probabilities that involve non-existing relationships. The main problem in this case is computing sufficient database statistics (frequencies), which can be addressed with the dynamic programming algorithm of Khosravi et al. [21]. Exper ...
... (true relationship groundings). It can extended for conditional probabilities that involve non-existing relationships. The main problem in this case is computing sufficient database statistics (frequencies), which can be addressed with the dynamic programming algorithm of Khosravi et al. [21]. Exper ...