
An Empirical Analysis of Value Function-Based
... policy when p = 0.1. (d) Optimal action values from each state. (e) Subset of cells with RBFs (χ = 0.25) (f ) ρ constructed with these features for some w, and (g) Resulting policy. (h) ρ corresponding to optimal policy. bility p and it moves east (north) with probability 1−p. The variable p, which ...
... policy when p = 0.1. (d) Optimal action values from each state. (e) Subset of cells with RBFs (χ = 0.25) (f ) ρ constructed with these features for some w, and (g) Resulting policy. (h) ρ corresponding to optimal policy. bility p and it moves east (north) with probability 1−p. The variable p, which ...

Making Reinforcement Learning Work on Real Robots
... for real robots. We are particularly interested in domains with continuous sensory inputs and continuous actions, and require that learning take place online from a relatively small amount of experience. Motivation: In order to deploy robots in a wide variety of applications, from household to milit ...
... for real robots. We are particularly interested in domains with continuous sensory inputs and continuous actions, and require that learning take place online from a relatively small amount of experience. Motivation: In order to deploy robots in a wide variety of applications, from household to milit ...



Informed Initial Policies for Learning in Dec
... QP OM DP heuristic used in (Szer, Charpillet, and Zilberstein 2005) which finds an upper-bound for a Dec-POMDP by mapping the problem into a POMDP where the action set is the set of all joint actions and the observation set is the set of all joint observations. In a policy found by QP OM DP , an age ...
... QP OM DP heuristic used in (Szer, Charpillet, and Zilberstein 2005) which finds an upper-bound for a Dec-POMDP by mapping the problem into a POMDP where the action set is the set of all joint actions and the observation set is the set of all joint observations. In a policy found by QP OM DP , an age ...

CMPS 470, Spring 2008 Syllabus
... In this course the student will be presented with an overview of the Machine Learning. We will introduce the topic and study a selection of techniques. The class will be presented using a both a mix of theory, exercises and programming. Machine Learning is an interesting topic, and our book covers a ...
... In this course the student will be presented with an overview of the Machine Learning. We will introduce the topic and study a selection of techniques. The class will be presented using a both a mix of theory, exercises and programming. Machine Learning is an interesting topic, and our book covers a ...

The Lisbon Strategy as policy co-ordination
... The growth shortfall: undermines progress Confusion in: – Objectives (too many) – Responsibilities (everyone = no-one) ...
... The growth shortfall: undermines progress Confusion in: – Objectives (too many) – Responsibilities (everyone = no-one) ...





Call for Papers Special Issue of Applied Artificial Intelligence
... Georg Dorffner, Medical University of Vienna, and Austrian Research Institute for Artificial Intelligence Jon Garibaldi, University of Nottingham Davide Anguita, University of Genoa Papers are solicited that deal with true adaptivity of models, such as - Online adaptation to environmental changes - ...
... Georg Dorffner, Medical University of Vienna, and Austrian Research Institute for Artificial Intelligence Jon Garibaldi, University of Nottingham Davide Anguita, University of Genoa Papers are solicited that deal with true adaptivity of models, such as - Online adaptation to environmental changes - ...


Privacy Preserving Bayes-Adaptive MDPs
... [2] Sutton, R. S., and Barto, A. G., Reinforcement Learning: An Introduction, MIT Press, 1998 [3] Kaelbling, L. P., Littman, M. L., and Cassandra, A. R., Planning and acting in partially observable stochastic domains, Journal of Artificial Intelligence, 1998 [4] Duff, M., Design for an Optimal Probe ...
... [2] Sutton, R. S., and Barto, A. G., Reinforcement Learning: An Introduction, MIT Press, 1998 [3] Kaelbling, L. P., Littman, M. L., and Cassandra, A. R., Planning and acting in partially observable stochastic domains, Journal of Artificial Intelligence, 1998 [4] Duff, M., Design for an Optimal Probe ...

Reinforcement Learning in Real
... Securing / occupying a certain area Staying in certain group formations Destroying all enemy units ...
... Securing / occupying a certain area Staying in certain group formations Destroying all enemy units ...

Satinder Singh University of Michigan
... recent success of Deep Learning, there is renewed hope and interest in Reinforcement Learning (RL) from the wider applications communities. Indeed, there is a recent burst of new and exciting progress in both theory and practice of RL. I will describe some results from my own group on a simple new c ...
... recent success of Deep Learning, there is renewed hope and interest in Reinforcement Learning (RL) from the wider applications communities. Indeed, there is a recent burst of new and exciting progress in both theory and practice of RL. I will describe some results from my own group on a simple new c ...
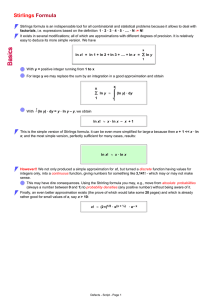
Stirlings Formula
... However!! We not only produced a simple approximation for x!, but turned a discrete function having values for integers only, into a continuous function, giving numbers for something like 3,141! - which may or may not make sense. This may have dire consequences. Using the Strirling formula you may, ...
... However!! We not only produced a simple approximation for x!, but turned a discrete function having values for integers only, into a continuous function, giving numbers for something like 3,141! - which may or may not make sense. This may have dire consequences. Using the Strirling formula you may, ...

Perspectives on Stochastic Optimization Over Time
... function is practically impossible to compute, value function approximations become useful, potentially leading to near-optimal performance. Such approximations can be developed in an ad hoc manner or through suitable approximate dynamic programming methods. The latter approach has opened up a vast ...
... function is practically impossible to compute, value function approximations become useful, potentially leading to near-optimal performance. Such approximations can be developed in an ad hoc manner or through suitable approximate dynamic programming methods. The latter approach has opened up a vast ...