
Kidney Disease and Protein
... Good quality protein is in animal products, such as: Meat, chicken, fish, eggs, cheese and milk Smaller amounts of lower quality protein are in: Bread, cereal, pasta, rice and vegetables Your body needs both kinds of protein food at the same time to be healthy. What does my body do with protein? ...
... Good quality protein is in animal products, such as: Meat, chicken, fish, eggs, cheese and milk Smaller amounts of lower quality protein are in: Bread, cereal, pasta, rice and vegetables Your body needs both kinds of protein food at the same time to be healthy. What does my body do with protein? ...


Basic Structure of Proteins
... • Another way of saying this is that peptide bonds are formed by a condensation reaction between the amine group of one amino acid and the carboxyl group of another resulting in an amide group. The elements of water are removed as a by product of this reaction. Water (HOH) forms from the -OH of the ...
... • Another way of saying this is that peptide bonds are formed by a condensation reaction between the amine group of one amino acid and the carboxyl group of another resulting in an amide group. The elements of water are removed as a by product of this reaction. Water (HOH) forms from the -OH of the ...

Click Here to download this tutorial as a PDF
... Interactive version available at http://cbm.msoe.edu/teachingResources/jmol/jmolTraining/structures.html ...
... Interactive version available at http://cbm.msoe.edu/teachingResources/jmol/jmolTraining/structures.html ...

The Amino Acid Sequence of Chlorella fusca Plastocyanin
... Katoh et al. (1961) suggested that the thiol groups of plastocyanin contributed to the binding of the copper. The proposed sequence contains only a single cysteine residue (position 83), clustered around by several aromatic residues. In the bacterial azurins, which are copper proteins that are belie ...
... Katoh et al. (1961) suggested that the thiol groups of plastocyanin contributed to the binding of the copper. The proposed sequence contains only a single cysteine residue (position 83), clustered around by several aromatic residues. In the bacterial azurins, which are copper proteins that are belie ...

RNA - Richsingiser.com
... • mRNA and tRNA worked out in the 1960s • Purification of RNA lead to 23S, 16S, and 4S species and accounted for 85% of all RNA • tRNA accounted for about 15% of all RNA • Hybridization experiments did not match DNA • mRNA accounts for only 1-4% of RNA ...
... • mRNA and tRNA worked out in the 1960s • Purification of RNA lead to 23S, 16S, and 4S species and accounted for 85% of all RNA • tRNA accounted for about 15% of all RNA • Hybridization experiments did not match DNA • mRNA accounts for only 1-4% of RNA ...

LecturesPart07
... SimilarNuc (Search(I),Sequence(J)) could return 0.5 since chances are 1 out of 2 that a purine is adenine ...
... SimilarNuc (Search(I),Sequence(J)) could return 0.5 since chances are 1 out of 2 that a purine is adenine ...
![[] Protein Splicing i) inteins and ext...,](http://s1.studyres.com/store/data/008277893_1-250b6a85b20526696d229e05c4a3b4d7-300x300.png)
[] Protein Splicing i) inteins and ext...,
... Hirata R, Ohsumk Y, Nakano A, Kawasaki H, Suzuki K, Anraku Y. ...
... Hirata R, Ohsumk Y, Nakano A, Kawasaki H, Suzuki K, Anraku Y. ...

Starch Blocker - Genomics Help
... 4) These amylase inhibitors have been shown to slow the uptake of glucose into the blood after a starch-rich meal. This may be beneficial to people with Type II diabetes (effectively reduces the glycemic index). How might this work? 5) Beans are well known to cause “gastric distress” for some people ...
... 4) These amylase inhibitors have been shown to slow the uptake of glucose into the blood after a starch-rich meal. This may be beneficial to people with Type II diabetes (effectively reduces the glycemic index). How might this work? 5) Beans are well known to cause “gastric distress” for some people ...

Dictionary of Interfaces in Proteins (DIP). Data Bank of
... of proteins, several databases are interrelating the databases of sequences and structures: the homology derived structures of proteins (HSSP, Sander & Schneider, 1991), those of Pascarella & Argos (1992), SESAM (Huysmans et al., 1991) and the families of structurally similar proteins (FSSP, Holm et ...
... of proteins, several databases are interrelating the databases of sequences and structures: the homology derived structures of proteins (HSSP, Sander & Schneider, 1991), those of Pascarella & Argos (1992), SESAM (Huysmans et al., 1991) and the families of structurally similar proteins (FSSP, Holm et ...

A1979HZ35700001
... importance of a piece of work. All three authors have at least 10 other papers to their credit which they would list above this one in importance. And what this paper is quoted for is not its intrinsic point (which had some importance), but the fact that it contains a paragraph describing the method ...
... importance of a piece of work. All three authors have at least 10 other papers to their credit which they would list above this one in importance. And what this paper is quoted for is not its intrinsic point (which had some importance), but the fact that it contains a paragraph describing the method ...

Serum Protein Electrophoresis – What is it
... When not to order serum protein electrophoresis: Although serum protein electrophoresis can show different patterns in many diseases including liver disease, chronic inflammation, acute infections, autoimmune diseases etc. this test modality should not be used to diagnose or follow these. TIPS- do’s ...
... When not to order serum protein electrophoresis: Although serum protein electrophoresis can show different patterns in many diseases including liver disease, chronic inflammation, acute infections, autoimmune diseases etc. this test modality should not be used to diagnose or follow these. TIPS- do’s ...

Structure-Function Analysis of the UDP-N-acetyl-D
... residues may be involved in different aspects of the catalytic process. First, glycosyltransferases (including ppGaNTases) that retain the anomeric configuration of the sugar-nucleotide bond are thought to work via a double displacement mechanism, which would require two carboxylic acid side chains ...
... residues may be involved in different aspects of the catalytic process. First, glycosyltransferases (including ppGaNTases) that retain the anomeric configuration of the sugar-nucleotide bond are thought to work via a double displacement mechanism, which would require two carboxylic acid side chains ...

Downloadable Full Text - DSpace@MIT
... Overall Architecture of WbpE: WbpE crystallized in the orthorhombic space group P21212, with two molecules in the asymmetric unit and approximate unit cell dimensions of 75 Å x 150 Å x 50 Å (Figure 3). The overall scaffold of WbpE is similar to that of other members in the Fold Type 1 aminotransfer ...
... Overall Architecture of WbpE: WbpE crystallized in the orthorhombic space group P21212, with two molecules in the asymmetric unit and approximate unit cell dimensions of 75 Å x 150 Å x 50 Å (Figure 3). The overall scaffold of WbpE is similar to that of other members in the Fold Type 1 aminotransfer ...

FTIR Analysis of Protein Structure
... magnetic resonance spectroscopy (NMR). While X-ray crystallography and NMR spectroscopy provide the greatest level of detail about a protein’s structure, there are many situations where these techniques cannot be applied. Other techniques, such as FTIR, may not provide the same level of structural d ...
... magnetic resonance spectroscopy (NMR). While X-ray crystallography and NMR spectroscopy provide the greatest level of detail about a protein’s structure, there are many situations where these techniques cannot be applied. Other techniques, such as FTIR, may not provide the same level of structural d ...

Ms Gentry`s Proteins powerpoint File
... •Give the functions of some proteins. •Describe the structure of an amino acid. •Explain what is meant by ‘essential’ and ‘non essential’ amino acids. •Describe the formation and breakage of peptide bonds in the synthesis and hydrolysis of dipeptides and polypeptides. ...
... •Give the functions of some proteins. •Describe the structure of an amino acid. •Explain what is meant by ‘essential’ and ‘non essential’ amino acids. •Describe the formation and breakage of peptide bonds in the synthesis and hydrolysis of dipeptides and polypeptides. ...

GTPase domains ofras p21 oncogene protein and elongation factor
... quence alignment may reflect an actual evolutionary pathway, yet the structure may have shifted by a few residues in response to altered intraprotein interactions. Definition of a Conserved Structural Core. Earlier definitions of structural core are in terms of conserved secondary structure elements ...
... quence alignment may reflect an actual evolutionary pathway, yet the structure may have shifted by a few residues in response to altered intraprotein interactions. Definition of a Conserved Structural Core. Earlier definitions of structural core are in terms of conserved secondary structure elements ...


SAbDab: the structural antibody database | Nucleic Acids Research
... non-antibody. The process is applied recursively to sequences to identify each variable region of the chain and thus enable the identification of single-chain Fvs (scFvs) that have not been split into separate chains. Those non-antibody chains that belong to a PDB entry containing an unequal number o ...
... non-antibody. The process is applied recursively to sequences to identify each variable region of the chain and thus enable the identification of single-chain Fvs (scFvs) that have not been split into separate chains. Those non-antibody chains that belong to a PDB entry containing an unequal number o ...

Description of possible cases (A-G as shown in Figure 1) The
... The detailed explanations of possibilities (A-G) as shown in Figure 1 are provided below. The long reads and short reads in these cases refer to read length 400 bp and < 400 bp, respectively. A: reads derived entirely from intergenic regions. Figure S3 shows that many reads in all simulated read d ...
... The detailed explanations of possibilities (A-G) as shown in Figure 1 are provided below. The long reads and short reads in these cases refer to read length 400 bp and < 400 bp, respectively. A: reads derived entirely from intergenic regions. Figure S3 shows that many reads in all simulated read d ...

The Structure and Topology of Protein Serine/Threonine
... numerous reviews [15, 16] and will not be discussed at length here, although the contrasting structural mechanism by which the conserved PP1 and PP2A catalytic subunits are able to form diverse holoenzyme structures will be discussed. In the case of PP1, it is known that the binding of targeting sub ...
... numerous reviews [15, 16] and will not be discussed at length here, although the contrasting structural mechanism by which the conserved PP1 and PP2A catalytic subunits are able to form diverse holoenzyme structures will be discussed. In the case of PP1, it is known that the binding of targeting sub ...
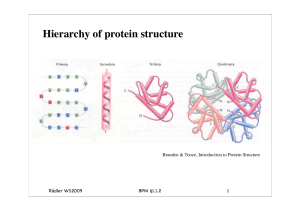
BPM§1.2_Protein Struktur.key
... This describes the overall shape of the domain structure as determined by the orientations of the secondary structures but ignores the connectivity between the secondary structures. ...
... This describes the overall shape of the domain structure as determined by the orientations of the secondary structures but ignores the connectivity between the secondary structures. ...

Document
... masses of raw data The challenge is to turn this raw data into biological knowledge A valuable tool for this challenge is an automated diagnostic pipe through which newly determined sequences can be streamlined ...
... masses of raw data The challenge is to turn this raw data into biological knowledge A valuable tool for this challenge is an automated diagnostic pipe through which newly determined sequences can be streamlined ...

The Druggable Genome - European Bioinformatics Institute
... • Based on current estimates, the overlap between smallmolecule druggable and disease-modifying targets may be relatively small • Therefore, other approaches may be necessary to target proteins that do not have ‘beautiful’ small molecule binding sites: • Inhibition of protein-protein interactions ...
... • Based on current estimates, the overlap between smallmolecule druggable and disease-modifying targets may be relatively small • Therefore, other approaches may be necessary to target proteins that do not have ‘beautiful’ small molecule binding sites: • Inhibition of protein-protein interactions ...

Protein Ubiquitination
... ER Capacity: The protein concentration in the ER lumen is 100 mg/ml, it is essential that protein chaperones facilitate protein folding by preventing aggregation of protein folding intermediates and by correcting misfolded proteins. BiP/GRP78 – uses the energy from ATP hydrolysis to facilitate foldi ...
... ER Capacity: The protein concentration in the ER lumen is 100 mg/ml, it is essential that protein chaperones facilitate protein folding by preventing aggregation of protein folding intermediates and by correcting misfolded proteins. BiP/GRP78 – uses the energy from ATP hydrolysis to facilitate foldi ...
Structural alignment

Structural alignment attempts to establish homology between two or more polymer structures based on their shape and three-dimensional conformation. This process is usually applied to protein tertiary structures but can also be used for large RNA molecules. In contrast to simple structural superposition, where at least some equivalent residues of the two structures are known, structural alignment requires no a priori knowledge of equivalent positions. Structural alignment is a valuable tool for the comparison of proteins with low sequence similarity, where evolutionary relationships between proteins cannot be easily detected by standard sequence alignment techniques. Structural alignment can therefore be used to imply evolutionary relationships between proteins that share very little common sequence. However, caution should be used in using the results as evidence for shared evolutionary ancestry because of the possible confounding effects of convergent evolution by which multiple unrelated amino acid sequences converge on a common tertiary structure.Structural alignments can compare two sequences or multiple sequences. Because these alignments rely on information about all the query sequences' three-dimensional conformations, the method can only be used on sequences where these structures are known. These are usually found by X-ray crystallography or NMR spectroscopy. It is possible to perform a structural alignment on structures produced by structure prediction methods. Indeed, evaluating such predictions often requires a structural alignment between the model and the true known structure to assess the model's quality. Structural alignments are especially useful in analyzing data from structural genomics and proteomics efforts, and they can be used as comparison points to evaluate alignments produced by purely sequence-based bioinformatics methods.The outputs of a structural alignment are a superposition of the atomic coordinate sets and a minimal root mean square deviation (RMSD) between the structures. The RMSD of two aligned structures indicates their divergence from one another. Structural alignment can be complicated by the existence of multiple protein domains within one or more of the input structures, because changes in relative orientation of the domains between two structures to be aligned can artificially inflate the RMSD.