Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Protein (nutrient) wikipedia , lookup
Lipid bilayer wikipedia , lookup
Mechanosensitive channels wikipedia , lookup
P-type ATPase wikipedia , lookup
Membrane potential wikipedia , lookup
Protein phosphorylation wikipedia , lookup
Model lipid bilayer wikipedia , lookup
Protein moonlighting wikipedia , lookup
Magnesium transporter wikipedia , lookup
Theories of general anaesthetic action wikipedia , lookup
Nuclear magnetic resonance spectroscopy of proteins wikipedia , lookup
G protein–coupled receptor wikipedia , lookup
Signal transduction wikipedia , lookup
SNARE (protein) wikipedia , lookup
Intrinsically disordered proteins wikipedia , lookup
Protein structure prediction wikipedia , lookup
Cell membrane wikipedia , lookup
List of types of proteins wikipedia , lookup
Trimeric autotransporter adhesin wikipedia , lookup
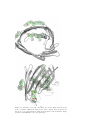
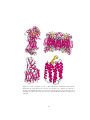
Theoretical studies of Membrane Proteins Properties, Prediction Methods and Genome-wide analysis PhD Thesis Erik Wallin Department of Biochemistry Stockholm University Sweden Email [email protected] October 21, 1999 Cover illustration The membrane protein complex bovine cytochrome c oxidase, forms a dimer in the crystal structure. The picture shows the membrane spanning helices ±10 Å from the center of the membrane, looking down through the membrane. Only the bonds between Cα backbone atoms are plotted. The color coding shows the amount of residue variability, calculated from alignment to other mammalian cytochrome c oxidase sequences. Conserved residues are red and variable residues blue. It is clear that the core residues are more conserved (red) and the residues facing the lipid environment more variable (blue). This is not unexpected since the lipid interactions are not as specific as the packing in the protein core. The author can be reached at [email protected] or http://www.biokemi.su.se/˜erikw ISBN 91-7265-012-5 Printed ISBN 91-7265-013-3 CD-ROM ISBN 91-7265-014-1 Online (PDF) at http://www.sub.su.se/diss/1999/91-7265014-1 2 Contents Abstract 7 Acknowledgements 8 List of publications 10 Abbreviations 12 1 Introduction 13 1.1 1.2 Classes of membrane proteins . . . . . . . . . . . . . . . . . . . . 13 1.1.1 Helix bundle integral membrane proteins . . . . . . . . . 14 1.1.2 Architectural overview of helix bundle membrane proteins 14 1.1.3 β barrel integral membrane proteins . . . . . . . . . . . . 14 Experimental studies of helix bundle membrane proteins . . . . . 15 1.2.1 Structural determination of membrane proteins . . . . . . 15 1.2.2 Mutational studies . . . . . . . . . . . . . . . . . . . . . . 15 1.2.3 Topology mapping . . . . . . . . . . . . . . . . . . . . . . 19 2 Prediction of membrane protein topology and structure 2.1 2.2 21 Predictable features . . . . . . . . . . . . . . . . . . . . . . . . . 21 2.1.1 Hydrophobicity scales . . . . . . . . . . . . . . . . . . . . 22 Overview methods for topology prediction . . . . . . . . . . . . . 22 2.2.1 TopPred . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22 2.2.2 TopPred Multi . . . . . . . . . . . . . . . . . . . . . . . . 24 2.2.3 PHDhtm . . . . . . . . . . . . . . . . . . . . . . . . . . . 25 2.2.4 TMAP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25 2.2.5 MEMSAT . . . . . . . . . . . . . . . . . . . . . . . . . . . 26 3 2.3 2.2.6 PRED-TMR . . . . . . . . . . . . . . . . . . . . . . . . . 26 2.2.7 TMHMM . . . . . . . . . . . . . . . . . . . . . . . . . . . 26 2.2.8 HMMTOP . . . . . . . . . . . . . . . . . . . . . . . . . . 26 2.2.9 The dense alignment surface method . . . . . . . . . . . . 27 Prediction of membrane protein structure . . . . . . . . . . . . . 27 3 Architecture of helix bundle membrane proteins 3.1 3.2 Intra- and extracellular loops . . . . . . . . . . . . . . . . . . . . 29 30 3.1.1 Arg and Lys content is biased towards the intracellular side 30 3.1.2 Amino acid bias in the N-terminal and the first loop . . . 31 3.1.3 Other amino acid biases . . . . . . . . . . . . . . . . . . . 31 3.1.4 Charge distribution within the loops . . . . . . . . . . . . 31 3.1.5 Loop length and translocation . . . . . . . . . . . . . . . 32 3.1.6 Loop length in general . . . . . . . . . . . . . . . . . . . . 32 3.1.7 A coil region near the membrane? . . . . . . . . . . . . . 33 Membrane spanning helices . . . . . . . . . . . . . . . . . . . . . 34 3.2.1 Length of transmembrane helices . . . . . . . . . . . . . . 34 3.2.2 Hydrophobicity and exposure to lipids . . . . . . . . . . . 35 3.2.3 Distribution of other residue types . . . . . . . . . . . . . 35 3.2.4 Helix breakers and charged residues . . . . . . . . . . . . 35 3.2.5 Correlation between residue variability and exposure . . . 36 3.2.6 Helix ends . . . . . . . . . . . . . . . . . . . . . . . . . . . 36 4 Genome wide studies of membrane proteins 39 4.1 Membrane protein content . . . . . . . . . . . . . . . . . . . . . . 39 4.2 Number of transmembrane segments . . . . . . . . . . . . . . . . 40 4.3 Size vs number of transmembrane segments . . . . . . . . . . . . 40 5 Summary 43 6 Papers 49 4 Till minne av Christina 5 6 Abstract Membrane proteins are a large and important class of proteins. They are responsible for several of the key functions in a living cell, e.g. transport of nutrients and ions, cell-cell signaling, and cell-cell adhesion. Despite their importance it has not been possible to study their structure and organization in much detail because of the difficulty to obtain 3D structures. In this thesis theoretical studies of membrane protein sequences and structures have been carried out by analyzing existing experimental data. The data comes from several sources including sequence databases, genome sequencing projects, and 3D structures. Prediction of the membrane spanning regions by hydrophobicity analysis is a key technique used in several of the studies. A novel method for this is also presented and compared to other methods. The primary questions addressed in the thesis are: What properties are common to all membrane proteins? What is the overall architecture of a membrane protein? What properties govern the integration into the membrane? How many membrane proteins are there and how are they distributed in different organisms? Several of the findings have now been backed up by experiments. An analysis of the large family of G-protein coupled receptors pinpoints differences in length and amino acid composition of loops between proteins with and without a signal peptide and also differences between extra- and intracellular loops. Known 3D structures of membrane proteins have been studied in terms of hydrophobicity, distribution of secondary structure and amino acid types, position specific residue variability, and differences between loops and membrane spanning regions. An analysis of several fully and partially sequenced genomes from eukaryotes, prokaryotes, and archaea has been carried out. Several differences in the membrane protein content between organisms were found, the most important being the total number of membrane proteins and the distribution of membrane proteins with a given number of transmembrane segments. Of the properties that were found to be similar in all organisms, the most obvious is the bias in the distribution of positive charges between the extra- and intracellular loops. Finally, an analysis of homologues to membrane proteins with known topology uncovered two related, multi-spanning proteins with opposite predicted orientations. The predicted topologies were verified experimentally, providing a first example of “divergent topology evolution”. 7 Acknowledgements Several other people have contributed to this project. I am grateful to all of them, listed in no particular order. Gunnar for the support and encouragement, and for getting me hooked on science. You were always there to answer questions (and had the answers). Gunnar is the most efficient person I know of, next to my father. Arne for interesting discussions, computers and being able to answer the questions when Gunnar was not around. And not the least for helping out to organize a good computer environment. Fredrik Hedman, who is also responsible for bringing me into science, and letting me run *the* computer. Stefan Nordlund, for letting me join the department and for being one of the best “VD” I’ve seen. My parents, Sven-Erik and Christina for giving me a good start, and for encouraging and recognizing my studies. Charbel, Max, John, and Matti, the oldest friends I have. Jens Lagergren and Joe DePierre for critical evaluation of my predissertation seminar and the selection of papers. Henrik Nielsen Alessandra Devoto for pushing me to finish my part of an interesting study and doing most of the hard work. Elisabeth Ekner and Helen Rabo for all the work behind the electronic publication. Ann, Kicki, Anki, Bogos och Eddie for making sure the important things work in the department. Christian Wettergren was the one I did my first scientific project with (my masters thesis). Donald Knuth, Leslie Lamport, and everyone else who has developed TeX into what it is today. They are responsible for the look and feel of this page. I’ve only written the text, TeX did the rest. Miklos, for an enthusiastic effort to keep moving forward. 8 Joacim Halen, Abelsson & Sussman for teaching me how to *really* write computer programs. Arne Sandin, Leif Paulsson, Lars Svensson, Hillevi Gavel for doing a good job in my basic teaching. I wish every teacher could be like them. Bertil Andersson, for building a very good department. Bo Lundgren for fixing computers that I couldn’t, and discussing problems with. Peter Nemeth, Niklas Wretman, Jonas Källström, and Johan Arvidsson for reminding me about what I could do (and what I could earn) if I ever finish school, and lots of fun moments, mostly involving beers and talking about computers. Peter Hammarlund for all those computer assignments we did at the KTH, and all the great parties we’ve been to. Marie, Guro, Ismael, Paul, IngMarie, Susana, Magnus, Susanne, Annika, Hans, Thomas, (and Rosie), Jan-Willem, Helena A., Chen-ni and everyone else who has been in Gunnars group. It’s always been a very fun and social place to be. Lennart Nilsson, who showed me how to look at structures and for all the interesting computer discussions. Erik Lundgren for keeping the computers in good shape during my time at Novum. The people at PDC, Johan, Assar, Erik A., Gert och Brita. BG, for setting up my workstation at the KTH. I guess I still owe him a “semla”. Lars Arvestad, for all the discussions about algorithms. The organizers of the workshop on Patterns in Biological Sequences at the Aspen Center for physics, which provided me with a very good start in my bioinformatic studies. The results on TopPred Multi partly originated there. Robert, Olof, Mats, Jakob, Amin, Juma, Jeanette, Anders L., Daniel, Pål and all the short term guests in Arne’s and Gunnar’s groups. Zhang for taking over my computer responsibilities. The Journal club. The Cake club. Everyone at the department of Biochemistry. Helena, my sister. My grandparents who have given me lots of encouragement through the years and given me an opportunity to take my mind off science a few weeks every summer. Keng-Ling, my everything, the best thing that happened to me. Anyone that I’ve forgotten to mention is purely unintentional. Thanks! 9 List of publications This thesis is based on the following articles, which are included in chapter 6. They will be referred to in the text by Roman numerals. I. E. Wallin and G. von Heijne. Properties of N-terminal tails in G-protein coupled receptors - a statistical study. Protein Engineer, 8(7):693–698, 1995, Medline, WWW. II. M. Cserzö, E. Wallin, I. Simon, G. von Heijne, and A. Elofsson. Prediction of transmembrane α-helices in prokaryotic membrane proteins: the dense alignment surface method. Protein Engineer, 10(6):673–676, 1997, Medline, WWW. III. E. Wallin, T. Tsukihara, S. Yoshikawa, G. von Heijne, and A. Elofsson. Architecture of helix bundle membrane proteins: An analysis of cytochrome c oxidase from bovine mitochondria. Protein Sci, 6(4):808–815, 1997, Medline, WWW. IV. K. Seshadri, R. Garemyr, E. Wallin, G. von Heijne, and A. Elofsson. Architecture of β-barrel membrane proteins: Analysis of trimeric porins. Protein Sci, 7(9):2026–2032, 1998, Medline, WWW. V. E. Wallin and G. von Heijne. Genome-wide analysis of integral membrane proteins from eubacterial, archaean, and eukaryotic organisms. Protein Sci, 7(4):1029–1038, 1998, Medline, WWW. VI. A. Sääf, M. Johansson, E. Wallin, and G. von Heijne. Divergent evolution of membrane protein topology: The Escherichia coli RnfA and RnfE homologues. Proc Natl Acad Sci USA, 96(15):8540–8544, 1999, Medline, WWW. Other publications The following publications were also produced in the course of my Ph.D. studies, but are not included in this thesis. 10 • E. Wallin, C. Wettergren, F. Hedman, and G. von Heijne. Fast NeedlemanWunsch scanning of sequence databanks on a massively parallel computer. CABIOS, 9(1):117–118, 1993, Medline. • J.F. Tomb, O. White, A.R. Kerlavage, R.A. Clayton, G.G. Sutton, R.D. Fleischmann, K.A. Ketchum, H.P. Klenk, S. Gill, B.A. Dougherty, K. Nelson, J. Quackenbush, L. Zhou, E.F. Kirkness, S. Peterson, B. Loftus, D. Richardson, R. Dodson, H.G. Khalak, A. Glodek, K. McKenney, L.M. Fitzegerald, N. Lee, M.D. Adams, E.K. Hickey, D.E. Berg, J.D. Gocayne, T.R. Utterback, J.D. Peterson, J.M. Kelley, M.D. Cotton, J.M. Weidman, C. Fuji, C. Bowman, L. Watthey, E. Wallin, W.S. Hayes, M. Borodovsky, P.D. Karp, H.O. Smith, C.M. Fraser, and J.C. Venter. The complete genome sequence of the gastric pathogen Helicobacter pylori. Nature, 388:539–47, 1997, Medline, WWW, PDF. • G. Schneider, S. Sjöling, E. Wallin, P. Wrede, E. Glaser, and G. von Heijne. Feature-extraction from endopeptidase cleavage sites in mitochondrial targeting peptides. Proteins, 30(1):49–60, 1998, Medline, WWW. • A. Sääf, E. Wallin, and G. von Heijne. Stop-transfer function of pseudorandom amino acid segments during translocation across prokaryotic and eukaryotic membranes. Eur J Biochem, 251(3):821–829, 1998, Medline, WWW. • A. Devoto, P. Piffanelli, IM. Nilsson, E. Wallin, R. Panstruga, G. von Heijne, P. Schulze-Lefert. Topology, subcellular localization and sequence diversity of the Mlo family in plants. J Biol Chem, in press, 1999. 11 Abbreviations 3D three dimension A adenine aa amino acid Ala alanine Arg arginine Asn asparagine C cytosine DAS dense alignment surface G guanine GPCR G-protein coupled receptor Gln glutamine Gly glycine K arginine Leu leucine Lys lysine NH nitrogen-hydrogen amino group NMR nuclear magnetic resonance OMPLA name of a gene ORF open reading frame Ompa name of a gene Phe phenylalanine PhoA name of a gene Pro proline R lysine RnfA name of a gene RnfE name of a gene SDS-PAGE sodium dodecyl sulfate- polyacrylamide gel electrophoresis T thymine TM transmembrane Trp trptophan Tyr tyrosine WWW world wide web YrbG name of a gene Å Ångström 12 Chapter 1 Introduction The stage for this thesis is set in the membrane of living cells. These membranes are composed of a lipid bilayer which serves to separate different compartments of the cell, or in the case of lower organisms, the cell from its environment. Membranes are impermeable to polar molecules (soluble in water) and ions. Their function is to localize reactions and keep the cell’s molecular machinery and supply of nutrients from escaping. Membranes are built up from lipids which are hydrocarbon chains attached pairwise to a phosphate headgroup. The hydrocarbon chains are hydrophobic (not soluble in water), and the headgroups charged and polar (water soluble). The name bilayer comes from the fact that the hydrocarbon chains of two monolayers of lipids are fused together and forms a single sheet with phosphate headgroups on both sides - a bi-layer. This effectively makes the membrane soluble, but not permeable. From this description one might get the impression that the membrane is simply a dull monotonous layer, an inactive component of a cell. On the contrary, it is full of protein molecules that perform many of the important functions that the cell needs. Several studies (including [paper V] in this thesis) suggest that around 25 % of all protein types in a cell are membrane proteins. 1.1 Classes of membrane proteins The first distinction to make in studying membranes is between integral membrane proteins and membrane associated proteins. The latter consist of proteins which are only anchored to the surface of the membrane, but where the bulk of the protein consists of a globular (soluble) domain. This class will not be discussed further in this thesis. Integral membrane proteins span the bilayer. The focus here will be on one of its two subclasses, the helix bundle integral membrane proteins. 13 1.1.1 Helix bundle integral membrane proteins Helix bundle membrane proteins are the class that has been studied most in this thesis. These proteins are present in the plasma membrane of prokaryotes and in all membranes of eukaryotic cells. In the rest of this thesis they will be referred to simply as membrane proteins. A helix bundle integral membrane protein is built up from α-helices that span the lipid bilayer, connected by loop regions that extend into the cyto- or periplasm. These are normally referred to as membrane spanning regions and loops. The loops may very well fold into secondary structures, not to be mistaken for coil regions in globular proteins which are sometimes also referred to as loops. These proteins are responsible for a wide range of functions, such as photosynthesis, transport of ions and molecules across the membrane, attachment points for skeletal structures of the cell, and secretion of proteins. 1.1.2 Architectural overview of helix bundle membrane proteins As 3D structures of membrane proteins are rare, most membrane proteins can so far only be described by their topology. The membrane spanning segments and loops are identified and drawn in a cartoon of a membrane, [paper I,fig 1]. The membrane spanning helices can also be drawn with the horizontal position of each amino acid corresponding to its rotational angle in the helix (a helical net representation). This enables identification of residues that are on the same face of the helix but in different turns. These topology cartoons are often used to illustrate results of topology predictions and experimental topology mappings. 1.1.3 β barrel integral membrane proteins In addition to the helix bundle membrane proteins, another class of integral membrane proteins exists, where the membrane spanning segments consist of β-strands organized in a barrel. The so-called porins belong to this class. They consist of β-barrels with 1618 βstrands spanning the membrane, usually connected by short loops. The residues in the strands alternate between pointing towards the lipid bilayer and the interior of the protein. This interior forms a pore with a polar environment. The side chains of the strand residues are thus alternately polar and hydrophobic. Porins are found in the outer membranes of Gram negative prokaryotes and in the outer mitochondrial membrane of eukaryotic cells. They are responsible for diffusional transport of molecules through these membranes. Structures of a few porins have been successfully determined. In this thesis they have been analyzed in [paper IV], figure 1.2. 14 Other types of β-barrel integral membrane proteins have been found, for example OmpA (Pautsch and Schulz, 1998) and OMPLA (Snijder et al., 1999), see figure 1.1. They contain fewer transmembrane spanning strands and do not form pores in the membrane. 1.2 Experimental studies of helix bundle membrane proteins Despite the difficulties of obtaining structural information (see section 1.2.1), membrane proteins have been extensively studied. Largely these studies have focused on the biological functions of particular membrane protein families. These functions cover many important areas, such as transport of nutrients, ions and electrons, protein secretion, receptors for the immune system, hormones and drugs, and even photosynthesis, which takes place in specialized membranes of plants. Fewer groups have been working on the architecture and properties of the membrane proteins themselves. What is required for a protein to form a stable structure in the membrane? How does it get integrated and folded there? 1.2.1 Structural determination of membrane proteins Unfortunately there are very few 3D structures determined of membrane proteins. There are several reasons for this. First, membrane proteins are hard to overexpress. They are often toxic to the organism that overexpresses them and they often form inclusion bodies - large aggregates of protein - in the cell. The inclusion bodies have to be denatured in order to solubilize the protein, which then has to be refolded. Second, membrane proteins are difficult to purify in an active form, and need to be solubilized in detergents. The third reason is that they are hard to crystallize, because of their hydrophobic nature and the detergent micelles present around the hydrophobic regions. Unfortunately studies using NMR is not very promising either. Micelles formed around the hydrophobic part of the protein increases the size. Since NMR has a limit on the size of the molecule that can be studied, only small membrane proteins are possible to study, even if they can be successfully overexpressed and purified. Despite the above, there are a handful of structures available. The structure of these are shown in figure 1.3. 1.2.2 Mutational studies Many interesting results on the architecture of membrane proteins have been obtained by mutational studies. So far, such studies have mainly focused on problems related to membrane protein topology and assembly. Several detection systems have been used. Antibodies against the loop regions 15 Figure 1.1: Structure of a non pore forming β barrel membrane protein, OmpA. Image generated with [Halaska et al., in preparation] 16 17 Figure 1.2: Structure of a porin. Top image is a view looking down the membrane of a trimer. This is the native form of the complex. Bottom picture is a side view of one porin subunit, looking along the plane of the membrane. Image generated with [Halaska et al., in preparation] Figure 1.3: Cartoon image of some of the structurally determined helix bundle membrane proteins. From the top left, cytochrome bc1 complex, cytochrome c oxidase, photisynthetic reaction center, bacteriorhopdopsin. Note the regions of irregular secondary structure between the transmembrane helixes and the polar domains. 18 is one way of determining if a loop has been translocated across the membrane. Proteolytic enzymes can be used to cut loop regions on the outside of the membrane, leaving the regions protected by the membrane still intact. Such a cut can be seen as a size-shift when the protein is analyzed by SDS-PAGE. Another common method is fusion of globular proteins/domains to loop regions. The location of these intra- or extracellular domains can then be detected by various biochemical assays. 1.2.3 Topology mapping Even if it is not possible to determine the exact structure of a membrane protein without crystals, one can still determine the topology using ordinary experimental studies. Many such mapping studies have been performed, and they are the basis for the evaluation and development of topology prediction methods. Mapping a topology can be done in several ways. The most common method today is based on fusion proteins. A protein domain that can be detected when it is translocated across the membrane is fused to the (predicted) loop regions, one at a time. Each of the fusion proteins are expressed in a cell line. The cells are then analyzed with the assay for detection of the fusion domain. One such system is the PhoA fusion. PhoA is an enzyme that obtains the correct structure only if translocated to the periplasm, where the appropriate disulphide bridges are formed. Active PhoA can be detected by a colorimetric assay. PhoA fusions were used in [paper VI] to map two related proteins that turn out to have opposite topology. 19 20 Chapter 2 Prediction of membrane protein topology and structure As noted above, integral membrane proteins have so far only been found in two fold classes - helix bundle and β-barrel. This chapter will focus on the helix bundle class. A single chain of a membrane protein spans at least three different compartments at the same time, the intracellular and extracellular spaces, and the interior of the membrane. Not only do the environment in these compartments vary, but the protein has to be able to insert correctly into them during synthesis. Furthermore, the constraints imposed by the membrane strongly reduces the number of possible conformations of a membrane protein. Because of the strict constraints, there are large similarities between membrane proteins of different function and size, even if they come from different organisms or are localized to different types of membranes. These similarities are strong enough to be used for prediction of important structural features from the amino acid sequence alone. 2.1 Predictable features The most obvious feature of a membrane protein that can be predicted is the number of membrane spanning segments and their (approximate) location in the sequence. Since the interior of the lipid bilayer is highly hydrophobic, the membrane spanning segments have to have hydrophobic side chains interfacing the lipids. As with globular proteins, the packed interior of the helix bundle is also hydrophobic, and thus the entire length of each membrane spanning segment is hydrophobic. Several other features are known to be common to all membrane proteins and 21 can be used for prediction. The positive inside rule (von Heijne, 1992), see sections 3.1.1 and 2.2.1, is the second most useful feature. Unfortunately the bias is not in general strong enough to determine the location of individual loops. Instead the prediction has to be based on the average of all loops on each side of the membrane. Prediction of the orientation of a membrane protein is thus generally dependent on the correct prediction of the number of transmembrane segments, but the two predictions can be combined to give an even better result as described in section 2.2.1. Other predictable features involve structural information and have been discovered primarily by studying the few structures available. As described in sections 3.2.2 and 3.2.5, the membrane spanning helices, especially the ones facing the lipid environment, differ in hydrophobicity and residue variability between the side buried in the helix bundle and the side facing the lipids. This can be used to predict the lipid facing side of helices from the sequence. 2.1.1 Hydrophobicity scales Amino acids can be classified in several ways according to their chemical and physical properties. Their preference to be in contact with polar or non-polar environments is referred to as their hydrophobicity (hydro-phobia - fear of water). A high hydrophobicity value indicates a preference to be in a non-polar environment, such as the membrane. Such scales can be derived in several ways. Directly measuring the chemical preferences (Karplus, 1997; Nozaki and Tanford, 1971; Damodaran and Song, 1986; Fauchere and Pliska, 1983; Radzicka and Wolfenden, 1988) is one way. Analysis of known protein structures for the preference of each amino acid to be on the surface (exposed to polar environment) or in the core is another. In [paper III], known structures of membrane proteins were analyzed to determine the preferences for each amino acid to be in the membrane or the loop regions. The correlation to hydrophobicity scales derived with different methods is good, but with some notable exceptions: Met and Val are more preferred to be in the membrane than would be expected from their hydrophobicity as measured by other scales. 2.2 2.2.1 Overview methods for topology prediction TopPred TopPred (von Heijne, 1992) uses hydrophobicity analysis to identify potential transmembrane helices, by generating a hydrophobicity profile. The profile is smoothed by a hat shaped window and the highest peaks are identified as transmembrane segments. To be able to detect or rule out helices that have borderline hydrophobicity, peaks with a hydrophobicity value in a certain range are considered putative transmembrane helices. The region has been calibrated by selecting the least 22 Residue Phe Ile Leu Ala Trp Met Val Thr Gly Ser Tyr Cys His Pro Asn Asp Arg Lys Glu Gln Structural preference 1.30 0.86 0.86 0.56 0.52 0.44 0.33 0.18 0.16 0.16 -0.39 -0.41 -0.70 -1.30 -1.71 -2.05 -2.10 -2.69 -2.78 -3.00 EngelmanSteitz scale 3.7 3.1 2.8 1.6 1.2 3.4 2.6 1.2 1.0 0.6 -0.7 2.0 -3.0 -0.2 -4.8 -9.2 -12.3 -8.8 -8.2 -4.1 KyteDoolittle scale 2,8 4,5 3,8 1,8 -0,9 1,9 4,2 -0,7 -0,4 -0,8 -1,3 2,5 -3,2 -1,6 -3,5 -3,5 -4,5 -3,9 -3,5 -3,5 Table 2.1: Preference scale for an amino acid to be in the membrane as opposed to being in the polar regions. Comparison between the scale obtained in [paper III] and two traditional hydrophobicity scales; Engelman-Steitz (Engelman et al., 1986), and Kyte-Doolittle (Kyte and Doolittle, 1982) 23 hydrophobic segment from a collection of membrane proteins as the lower bound (in order not to miss any real transmembrane segments) and the most hydrophobic segment from a collection of globular proteins as the upper bound. The positive inside rule is then used both to determine the most probable of all possible topologies, with and without each putative transmembrane helix, by choosing the topology that has the highest bias of positive charges. The orientation of the protein is also identified at the same time. A WWW server and source code for TopPred is available at http://www.biokemi.su.se/˜server/toppred2. 2.2.2 TopPred Multi Several problems can be identified when running TopPred on single sequences. Charged residues sometimes occur in the hydrophobic transmembrane helices. With the result is that the segment is not properly detected by the hydrophobicity profile. Long loops are another problem. They make the orientation prediction harder since they “dilute” the effect of the positive inside rule. This affects both orientation prediction and the selection of which putative transmembrane segments to include through the positive inside rule. Short loops are also a problem. If they do not have charged or strongly polar residues, the hydrophobicity analysis will identify the two surrounding transmembrane segments as one. Unfortunately there is not enough experimental data available to incorporate changes based on the observations above without the risk of overfitting the model. There is one problem that is possible to address however. The identification of transmembrane spanning segments through the hydrophobicity profile is a critical step. One way improve this is to apply TopPred to an aligned family of membrane proteins. The hydrophobicity and charge at each residue is averaged and the resulting profiles are then used in the same way that a single sequence would be predicted. The advantage is that when a protein that belongs to a family has an extreme hydrophobicity, either in a transmembrane segment or a loop, the other members of the family may have a more normal value for the corresponding region. As discussed above in section 2.2.1 there is an overlap between the most hydrophobic segment in globular proteins and the least hydrophobic transmembrane segment. By averaging several sequences we can avoid the extremes of these distributions and increase the chance of being able to separate them correctly. Several issues have to be addressed when using families instead of a single sequence. Bad alignments and areas of low similarity may cause the prediction to fail on examples where the single sequence prediction is correct. Examples have also been found where homology searching pick up proteins with more or fewer membrane spanning segments than the target for the prediction. Predictions on families using TopPred Multi improve the results slightly [un24 published results]. However, the increase in the absolute number of correct predictions is small, and the statistical significance is questionable. An unexpected problem was revealed when evaluating TopPred Multi. RnfA, a membrane protein which has an experimentally determined topology and orientation showed homology to RnfE, a membrane protein that TopPred (on a single sequence) predicted to have the reversed orientation. This was discovered since TopPred Multi predicted the family containing the RnfA and RnfE proteins to have the wrong orientation compared to the experimental results from RnfA. In [paper VI] this divergent evolution of orientation for the two proteins was experimentally verified. Fortunately, a sequence analysis of the E. coli genome did not reveal any other examples. However, it was recently discovered that YrbG, an inner membrane protein with 10 predicted transmembrane segments is likely to be the result of a gene duplication, where the two halves of the protein have different orientations in the membrane and thus must have undergone divergent topology evolution. In summary, multiple sequence alignments can improve the prediction slightly, but also introduce new difficulties. 2.2.3 PHDhtm The PHDhtm (Rost et al., 1996) method uses multiple sequence alignments to do a consensus prediction of a target protein. A neural network is used to compute the preferences for each residue to be in a transmembrane segment or in a loop. This preference profile is then used to compute the most probable transmembrane segments using dynamic programming. In the last step PHDhtm uses the positive inside rule to compute the most probable orientation. A PHDhtm server is available at http://dodo.cpmc.columbia.edu/predictprotein. 2.2.4 TMAP The TMAP (Persson and Argos, 1994) method uses multiple sequence alignments to produce a preference profile for the consensus sequence. Preference scales, derived from statistical analysis of database annotations of membrane proteins, are used to calculate preferences for a residue to be in the hydrophobic core region of membrane spanning segments and the two cap regions. This profile is used to locate transmembrane segments, through a procedure that include steps to avoid the problem of single conserved charged or polar residues. It also includes a method for splitting long hydrophobic regions into pairs of transmembrane helices. Failure to split long hydrophobic segments is a common problem in other methods. TMAP is available as a WWW-service at http://www.mbb.ki.se/tmap. 25 2.2.5 MEMSAT MEMSAT (Jones et al., 1994) is similar to the preference profile method used in TMAP. It is more detailed in that it has separate preference scales for intraand extracellular loops and helix ends, in addition to the central helix region. It also uses different preferences for single and multispanning proteins. The sequence of the protein of interest is matched, using a dynamic programming method, to a model with the highest preferences in each region. A PC version of MEMSAT is available from http://globin.bio.warwick.ac.uk/˜jones/memsat.html 2.2.6 PRED-TMR PRED-TMR (Pasquier et al., 1999) is a mixture of hydrophobicity analysis and a weight-matrix method. Transmembrane segments are identified using a hydrophobicity profile, but they are further discriminated by a propensity matrix for the helix ends. 2.2.7 TMHMM This method is based on a Hidden Markov Model. This is a common tool for modeling sequence data. It basically consists of matching a string against a set of states. Each state has probabilities for matching different letters. The states are connected with different transfer probabilities. Dynamic programming is commonly used to match a sequence against the model in order to find the most probable match. In TMHMM (Sonnhammer et al., 1998) a Hidden Markov Model is used to model the different regions of a membrane protein. The model is more detailed than the previously described approaches. Separate states with preference probabilities are defined for the helix core, helix end caps on either side of the membrane, and loop regions as described in 3.1.7. Globular regions on the cytoplasmic and extracellular side are defined differently, and on the extracellular side, long and short coil regions are encoded by different states. The parameters in TMHMM are fixed, and come from training on a set of proteins with known topology. Another larger set was used to test the method after training. TMHMM is available as a WWW-service at http://www.cbs.dtu.dk/services/TMHMM-1.0 2.2.8 HMMTOP As the name suggests HMMTOP (Tusnady and Simon, 1998) is another method based on a hidden Markov model. One difference to TMHMM is that only one 26 loop state is used on the cytoplasmic side. A different approach is used for training the HMM. HMMTOP trains the model on the protein being predicted. The idea is that it should fine tune the difference in composition between the various regions for each protein or protein family. The fine tuning/training procedure can be improved by including proteins homologous to the target of the prediction. 2.2.9 The dense alignment surface method DAS [paper II] is a method based on computing a dot plot between the query protein and one or several reference protein(s). The reference proteins should be known to be membrane proteins, but do not have to have known topology. A special comparison matrix is used in computing the dot plot. This matrix gives higher values when matching hydrophobic than polar pairs of residues. An average is then computed of the rows/columns in the dot plot. This returns a hydrophobicity profile that turns out to be somewhat better than those obtained with other methods. A WWW server for DAS is available at http://www.biokemi.su.se/ server/DAS. 2.3 Prediction of membrane protein structure No definite method for prediction of the structure or packing of transmembrane proteins exist today. The main obstacle is the difficulty to test different approaches, since so few experimentally determined structures are available. Several studies have pointed out the existence of useful predictors. The most important ones are the hydrophobic and variability moments, observed by several studies of both sequences and structures (Rees et al., 1989a; Donnelly et al., 1993; Eisenberg et al., 1984), [paper III]. In [paper III] data is presented that could be used to predict the interfaces between subunits in a complex. Similar results were also found in [paper IV], where porin structures were studied. Approaches to use these prediction parameters for the packing of helices have been made. In addition to traditional structure prediction methods, they use the hydrophobic- and variability moments to predict the lipid exposed residues of helices (Taylor et al., 1994; Alkorta and Du, 1994; Donnelly et al., 1993). 27 28 Chapter 3 Architecture of helix bundle membrane proteins The overall architecture of a membrane protein consists of a number of helical regions spanning the membrane and loops that connect these helices on either side of the membrane. Loops have secondary structure elements [paper III, fig 1 and 2] in similar proportion as in globular proteins. A membrane protein can be viewed as two globular domains anchored together by a helix bundle. A major difference compared to a globular proteins is that the segments that build up the two globular domains are spread out in the sequence to a much greater extent than is normally found in the domains of a globular protein. The folding process of a membrane protein is of course also very different from globular proteins, since the transmembrane helices first have to be inserted into the membrane before the final structure can form. This puts extra constraints on the structure and possible configurations. Several features of the polypeptide chain, e.g. the positive inside rule, appear to be present mainly to guide insertion, and not to support the stability of the protein. Properties, common to all membrane proteins, can in many cases be detected by statistical analysis, even if they are not strong enough to be of use for prediction of structure or topology. Many of the results in this chapter are of this kind. They are still valuable since they provide a basis for further, experimental and theoretical studies. 29 3.1 3.1.1 Intra- and extracellular loops Arg and Lys content is biased towards the intracellular side The most well known property of loops in membrane proteins is the positive inside rule (von Heijne, 1992). Short loops are enriched in K and R residues on the inside and depleted on the outside. This has been studied in more detail in [paper I] and [paper V]. It was found that, while present in all organisms studied [paper V], the difference in K+R content is not equally strong in all of them. Eukaryotic cells have a normal K+R frequency of 10 % in extracellular loops, i.e. the same as for soluble proteins (von Heijne and Gavel, 1988), but about a twofold increase on the inside [paper I]. In prokaryotes on the other hand, the difference results from both depletion on the outside (5 %) and enrichment on the inside (20 %) (von Heijne and Gavel, 1988). The reason for enrichment in positive charges on the intracellular side is believed to be that translocation needs to be arrested so that the inside loop is not pulled through the membrane. Experimental studies have been performed that support this view. (Kuroiwa et al., 1991) The fact that all organisms seem to have this charge bias suggests that the same mechanism is involved. In addition the K and R content may of course be affected by other factors. One such example is the C. acetobutylicym, where only Lys residues are enriched [paper V,fig 4]. The reason for this is not known. It could be a result of environmental conditions for this organism or a bias in GC content since Lys is coded by AAG and AAA (no GC) and Arg by CGx, AGA and AGG (all contain G). Nucleotide frequencies in the C. acetobutylicym are 34 % A, 35 % T, 16 % C, 15 % G, compared to E. coli which has an even distribution nucleotides1 . The difference between organisms seen in [paper V] could partly be due to random fluctuations, and differences in the environment for the organisms. Lipid composition could also be one factor. Experiments show that translocation of loops with positive charges are affected by the amount of lipids with negatively charged headgroups (van Klompenburg et al., 1997; van Klompenburg and de Kruijff, 1998). Membrane potential has been shown to affect the translocation of positively charged loops and also the orientation of membrane proteins (Andersson and von Heijne, 1994; Schuenemann et al., 1999). Interestingly in (van de Vossenberg et al., 1998) it was found that in organisms with reversed membrane potential the positive inside rule is still valid. As seen in [paper I, fig 3], shorter loops on the intracellular side have a tendency to be more enriched in K+R than longer loops. This suggests that it is not so much the frequency, but rather the number of charges that produces the effect of arresting translocation. Short loops should also be more at risk of being pulled through along with their neighboring helices and thus be in need of a stronger 1 Nucleotide statistics for C. acetobutylicum (AE001438): 65548 A, 30229 C, 29117 G, 67106 T, and E. coli (U00096): 1142136 A, 1179433 C, 1176775 G, 1140877 T. 30 anchoring to the intracellular side. 3.1.2 Amino acid bias in the N-terminal and the first loop Earlier studies (Hartmann et al., 1989; Sipos and von Heijne, 1993) have reported that N-terminal tails have biased distributions of both positive and negative charges [paper I, fig 4]. These biases are anticorrelated and thus give a net charge bias over the first transmembrane segment. This is strongly pronounced in eukaryotic membrane proteins, but can not be observed with any statistical significance in prokaryotes. There is no obvious bias of negative charges in any of the other loops. An overall bias of negative charges can be seen in some genomes when looking at whole genome statistics. It is statistically significant only in C. elegans, H. sapiens, and C. acetobutylicum. [paper V] This could of course be the result from only a bias in the first segment. 3.1.3 Other amino acid biases Several studies also indicate that aromatic residues are enriched in extracellular loops. In [paper I] this is found in the G-protein coupled receptor family, and in (Nakashima and Nishikawa, 1992) in several eukaryotic proteins. This does however not seem to be a general property if one looks at the entire membrane protein content of genomes [paper V]. Such an enrichment could be specific to certain families of membrane proteins and be a result of the function of these families rather than a property common to all membrane proteins. 3.1.4 Charge distribution within the loops Charges are not only different between loops on either side of the membrane. In the GPCR family they are also unevenly distributed along the length of the intracellular loops. [paper I] The first charged residue in the loop, counting from the transmembrane segment, is often a positive charge. This was verified to be a statistically significant deviation by comparing the observed number of positive and negative charges to what would be expected from the overall frequencies in the intracellular loops. It has not been studied if this is the case in other membrane protein families or organisms, but experimental results on proteins with mutated loops support this (Andersson and von Heijne, 1991). One reason for having a positive charge close to the membrane spanning segment would be to arrest translocations in order not to pull any part of the loop through the membrane. It has been suggested that positive charges in intracellular loops interact with negative charges on the headgroups of the lipids. The need for positive charges to arrest translocation could possibly be dependent on the hydrophobicity of the transmembrane segment. The rationale would be that a strongly hydrophobic segment would stick in the membrane by itself. 31 A less hydrophobic segment (for example one embedded in the helix bundle, section 3.2.2) would need a positive charge close to its end to stop it from being pulled out into the extracellular domain. Such a correlation has been shown in (Kuroiwa et al., 1991). 3.1.5 Loop length and translocation In [paper I] a comparison between proteins from the same family (G-protein coupled receptors) with and without signal sequences was performed. The average length of the N-terminal tail was found to be strongly dependent on the presence or absence of a signal peptide. It was also shown that the K+R content in the N-terminal tail was lower for proteins without a signal peptide. This indicates that in order to be translocated across the membrane a long Ntail needs the help of a signal peptide. If it is short enough and contain few positive charges it can be translocated on its own. There is a “gray zone” where proteins with and without signal peptide has similar N-tail length [paper I, table I]. A closer look at these proteins revealed that short N-tails with many positive charges need a signal peptide. Similarly, long loops can be translocated without a signal peptide if they contain many negative charges. Recent studies on genome wide data combined with experiments [Sääf et al. in progress] suggest that there is a bias in loop length between the intra- and extracellular side. It appears that there is a strong correlation between the side with most positive charges and the longest average loop length.2 A similar selection and prediction to the one used in [paper V] was used. This seems to hold for all 12 organisms studied so far. See figure 3.1. 3.1.6 Loop length in general Another finding is that the relative number of residues in helices and loops seem to be quite constant in the large membrane protein families. When plotting the protein length against the number of transmembrane segments for all membrane proteins in an organism [paper V, fig 3], the bulk of the proteins fall around an axis with 35 residues per transmembrane segment. Since transmembrane segments are on the order of 20-25 amino acids long, this makes the average loop 10-15 amino acids long. One explanation for this is that there may be strong restraints on the length of the loops. A loop has to be long enough to span the distance between the helices it is connecting. A short loop between two helices would have to be compensated by a long loop elsewhere unless all helices in the bundle are packed next to their sequential neighbor. Not only does the loop need to be long enough to connect the helices, when they are packed but also during insertion into the membrane. An upper bound, especially for the extracellular loops, would be that secondary structure may start to form before the loop has a chance to translocate to the 2 The side with most positive charges is very likely to be the intracellular side, but the investigation is done on proteins from whole genomes and thus no experimentally determined orientations. 32 Organism A. fulgidus B. subtilis B. burgdorferi B. taurus mitochondrion C. elegans C. acetobutylicum E. coli H. influenzae H. pylori H. sapiens M. thermoautotrophicum. M. jannaschii M. genitalium M. pneumoniae N. tabacum chloroplast S. cerevisiae Synechocystis Sp. Correlated 61 95 14 3 165 62 150 44 28 37 26 26 9 4 4 16 36 Total 61 97 14 3 169 63 152 44 28 43 26 29 9 4 4 18 40 Fraction correlated 1 0.98 1 1 0.98 0.98 0.99 1 1 0.86 1 0.90 1 1 1 0.89 0.90 Table 3.1: Number of proteins where the average loop length in the predicted topology is longer on the intracellular side (actually the side with more positive charges). The same prediction and selection scheme as in [paper Vtable 2, First selection] was used. outside, thus hindering translocation. 3.1.7 A coil region near the membrane? In cytochrome c oxidase there is a distinct region between the end of the helices and the globular part of the loops, 20-30 Å from the center of the membrane. [paper IIIfig 1] In this region there is very little secondary structure. Further out from the membrane, about 30 Å from the center, helices and β-strands are found in the same proportions as in globular proteins. This was not examined systematically in other structures, but the same phenomena can be seen by visual inspection of the photosynthetic reaction center and the cytochrome bc1 complex, figure 1.3. When seen from a projection in the plane of the membrane, these unstructured loop regions are quite striking. At least in cytochrome c oxidase they constitute a very distinct border between the three domains. If this is a general feature of membrane proteins, it would be worth examining further. It should help structure prediction if it is the case. This remains to be seen when more large membrane protein complexes are crystallized. 33 3.2 Membrane spanning helices In the previous section, results were mostly derived from statistical analysis of sequences. In the studies of this thesis, the results on transmembrane helices come from examining the structure of cytochrome c oxidase, the largest membrane protein complex structurally determined so far [paper III]. There are of course properties of helices that can be derived from sequence analysis alone, and a lot of work has already been done in this area. Currently only a few membrane proteins have been structurally determined. This limits the amount of analysis that can be performed based on structure. However, it seems that most membrane proteins are not that different in terms of general architecture. (Bowie, 1997) Analysis of the few structures available should therefore give information relevant to the whole class of membrane proteins. 3.2.1 Length of transmembrane helices The membrane spanning segments in cytochrome c oxidase [paper III] span the membrane in an entirely helical conformation. In only a few cases do they extend into the globular domain (the loop regions) of the protein. In the ±12 Å central region there is almost only helix conformation. This is also the most hydrophobic region of the transmembrane segments. The helices end 15-25 Å from the center of the membrane. The length of the hydrophobic stretch is also possible to examine from sequence analysis. It has therefore been known for quite a long time that the membrane spanning regions are on the order of 18-25 residues long. This does however not imply that the helices end at the membrane border. Such evidence can only be found from structure studies as [paper III] and (Yeates et al., 1987; Rees et al., 1989b; Bowie, 1997). Helices do not seem to extend into the globular domains. One reason for this could be that it should be possible for the helices in the membrane to form independently of secondary structures in the loop regions. It could also be important that when forming the helix bundle the helices are able to shift around during the integration into the membrane. This would be hindered if parts of the helices were sticking out of the membrane into the polar domains, where secondary structures have already packed into a rigid structure. Another hypothesis why most of the helices end at the membrane border is that the negatively charged headgroups of the lipids interact with the N-terminal end of the helices. Because of the helix dipole moment the N-terminus has a positive charge of about 0.5-0.7 units, and also contain NH groups that could assist in binding a phosphate group from the lipids. Phosphate binding to the N-terminal end of helixes is suggested in (Branden and Tooze, 1999, fig 2.3, page 16). 34 3.2.2 Hydrophobicity and exposure to lipids The distribution of hydrophobic residues is one of the most striking features of membrane proteins. It can be seen clearly from a simple sequence analysis that the transmembrane segments have hydrophobic sidechains. The same pattern with a central ±10 − 12 Å hydrophobic region can be seen [paper III, fig 8] in all the structures studied there. By classifying residues as buried in the helix bundle, intermediately exposed, or exposed to the lipid environment, one can get a more detailed picture. The exposed class has higher average hydrophobicity than the buried class, when looking at the central ±10 Å region. [paper III, fig 9]. A similar analysis was done earlier in (Rees et al., 1989a) by using Fourier methods to analyze the transmembrane helices in the photosynthetic reaction center. This is contrary to what one sees in soluble proteins, where the core is always more hydrophobic than the protein surface. Unfortunately the difference in membrane proteins is not very strong. It can not be used efficiently in structure prediction by itself. Using the same classification it seems from the analysis of cytochrome c oxidase that not all hydrophobic sidechains have the same preference for being in contact with the lipids. Leu and Ala are more common in exposed positions, whereas Phe, Trp, and Tyr are more common in buried positions. 3.2.3 Distribution of other residue types In addition to the central hydrophobic region, two flanking regions of the helices around ±12 − 15 Å are enriched in polar aromatic residues (Trp and Tyr) and amidated residues (Asn and Gln). Further out, around ±15 − 20 Å charged residues appear. Finally there is an increased concentration of Pro residues where the helices end around ±15−25 Å away from the membrane center [paper III, fig 4]. This data is again from cytochrome c oxidase. Similar results were also obtained for another large structure, the photosynthetic reaction center, in (Schiffer et al., 1992). The “aromatic belt” has also been observed before in porin structures (Weiss et al., 1991) and in sequence studies of helix bundle membrane proteins (von Heijne, 1994; Pawagi et al., 1994). It is believed to stabilize the helices in the membrane by interacting with the lipid headgroups. Recently experimental studies have also been performed on this subject (de Planque et al., 1999; Braun and von Heijne, 1999). 3.2.4 Helix breakers and charged residues Helix breakers (Gly and Pro) and charged residues are rare in the membrane, most likely because of the energetic disadvantage of breaking the helix or introducing a charged residue in the hydrophobic lipid environment. When they are present they are almost always facing the interior of the protein. [paper III] 35 Charged residues are a problem when predicting topology from sequence alone. (Pro and Gly are hydrophobic so it is not a problem from a prediction point.) At least one method has tried to overcome this. In TMAP (section 2.2.4) single occurrences of charged residues are allowed in a transmembrane segment if they are conserved throughout the protein family being predicted. 3.2.5 Correlation between residue variability and exposure By aligning several sequences to a known structure a measure of the sequence variability in each position can be calculated. This was done in [paper III] with cytochrome c oxidase, and the information content (Schneider et al., 1986) was calculated and used as a measure. When looking at the central ±10 Å of the membrane domain it is clear that exposed residues display a higher degree of sequence variation (lower information content), whereas buried residues are more conserved. [paper III, fig 6] This has also been observed in studies of the photosynthetic reaction center and bacteriorhodopsin (Rees et al., 1989a). Cytochrome c oxidase is a large complex made up of a core formed by three mitochondrially encoded chains. In mammals, several small nuclear encoded subunits are attached to the core complex. This buries residues on the surface of the core subunits. These interface residues between small subunits and the core complex turn out to be more conserved than the lipid exposed residues. This is no surprise since they are involved in a specific interaction just as the core residues. Variability could thus be useful as a prediction tool for identifying putative protein-protein interface regions. The variability can also be calculated from sequence data. It is quite certain that transmembrane segments, which can be roughly predicted from sequence, are in helix conformation. One can therefore assign buried and exposed helix faces from variability calculations. This was done in (Rees et al., 1989a) in addition to the structural study, and it has been done in purely sequence based studies (Donnelly et al., 1993) 3.2.6 Helix ends Helix ends in membrane proteins have the same characteristics as in globular proteins. This is no surprise since they end outside the membrane environment. Pro residues are found on the N-terminal side and in the first two N-terminal positions of the helix (MacArthur and Thornton, 1991). Asp, Glu, Asn and Ser are often found in the first non-helix position on the N-terminal side, which is typical also for globular proteins (Richardson and Richardson, 1988; Doig and Baldwin, 1995). On the C-terminal side, Gly is enriched, also this a common preference in globular proteins (Richardson and Richardson, 1988; Aurora et al., 1994). [paper III] This result is promising since it means that similar methods as those used to predict helix ends in globular proteins can be used. This should be useful both for structure prediction, but also for topology prediction where a better 36 identification of helix ends would definitely help to distinguish between single long helices and closely spaced pairs of helices. 37 38 Chapter 4 Genome wide studies of membrane proteins Genome data open up an interesting new field to study the distribution of membrane proteins in different genomes. Thanks to the sequencing efforts of the genome projects, a large number of microbial genomes are available. The sequencing of a few higher organisms have been finished as well. However, when looking statistically at proteins one has to keep in mind that each individual cell or organism only uses a finite number of proteins. For example M. pneumoniae has only 300 ORFs and a predicted number of 50-80 membrane proteins. This suggests that we should not go into too much statistical detail, simply because there might not be enough data points to draw more than rough conclusions. An analysis that requires a hundred membrane proteins to be statistically significant will not be relevant if it is applied to a small genome as M. pneumoniae. 4.1 Membrane protein content A natural question to ask is how many different membrane proteins there are in a cell. Does this vary with the type of organism? These questions have been addressed in several studies, [paper V], (Jones, 1998; Boyd et al., 1998). The approach has been to use an algorithm to classify each protein in a genome as membrane or non-membrane. In [paper V] this was done using the method described in section 2.2.1. Membrane protein prediction is not 100 % accurate, especially not for proteins with very few transmembrane segments. In an attempt to put upper and lower bounds on the numbers, the assignment was done using three different parameter sets. The result of the analysis is plotted in [paper V, fig 1]. It indicates that organisms with smaller genomes require proportionally fewer membrane proteins. This proportionality was, however, not apparent in two other studies, which were done around the same time (Jones, 1998; Boyd et al., 1998). The method 39 used to identify membrane proteins, TopPred, is optimized for predicting the topology of membrane proteins, but not for discriminating between membrane proteins and soluble proteins. This could have resulted in incorrect assignments. This is especially a problem when looking at membrane proteins with few predicted membrane spanning segments, as these could easily have been picked up from hydrophobic segments from the core of a globular protein. A more recent study [Krogh et al, personal communication] however indicates that there is a difference, not between organisms of different size, but between single- and multicellular organisms. In particular, in the worm C. elegans Gprotein coupled receptors account for 5 % of the ORFs, thereby increasing the percentage of membrane proteins. The reason for this difference is suggested to be that multicellular organisms require communication and adhesion. They still have the same basic machinery for the internal working of the cell, and thus do not need to introduce so many new functions in terms of soluble proteins. It is also possible that higher organisms have a greater need to localize reactions to different compartments of the cell, and this requires more membrane proteins. 4.2 Number of transmembrane segments In [paper V] the number of transmembrane segments were predicted using TopPred, section 2.2.1, for each protein in a whole genome. The result was plotted in a histogram with the number of proteins of each type (2 TM, 3 TM, etc.). One can clearly discern important families of each genome. For example in lower organisms, 6 TM and 12 TM families are overrepresented. This corresponds to proteins that are necessary to transport nutrients and small molecules. In higher organisms on the other hand, 7 TM proteins (i.e. G-protein coupled receptors) are highly enriched, which shows the importance of communication to these cells. A similar study (Jones, 1998), agrees with these observations, even though a different prediction method was used. However, in (Arkin et al., 1997) the families are less visible. In this study a simpler method was used for prediction. Sharp peaks could therefore have been smoothed out by errors in the prediction. 4.3 Size vs number of transmembrane segments Another view of the data from section 4.2 is to build a height profile of the proteins with the height corresponding to the fraction of proteins with a particular number of transmembrane segments and size. A contour plot of this landscape shows where the important families are and also reveals another interesting feature: Most membrane proteins have the same number of residues per transmembrane segment. The peaks representing protein families are scattered along a line with about 35 residues per transmembrane segment. In addition there is a large collection of proteins with only a few predicted transmembrane segments. This is believed to be mostly false positive predictions, but also globular 40 proteins that are anchored to the membrane with one or two transmembrane segments. Recent studies [Larsson, et al, unpublished results] show that TopPred does have a higher rate of false positives than TMHMM. This would explain the large number of membrane proteins with few transmembrane segments and the disagreement with other studies of the number of membrane proteins per organism described in section 4.1. 41 42 Chapter 5 Summary In this thesis, membrane proteins have been studied by statistical and computational methods based on data from a collection of G-protein coupled receptors, complete genome sequences of several organisms, and structures of several multispanning integral membrane proteins. The positive inside rule was verified to hold in most of the studied organisms, but with differences in the degree of depletion of positive charges on the extracellular side between eukaryotes and prokaryotes. Short intracellular loops seem to be more enriched in positive charges than long ones. Statistical studies of G-protein coupled receptors with and without signal peptides suggested that long N-tails require a signal peptide to be translocated across the membrane. N-tails without a signal peptide are depleted in positive charges. A bias in negative charges towards the extracellular side was seen across the first transmembrane segment. Statistical studies of genome sequences were performed by predicting the topologies of all ORFs. It was found that the relative number of membrane protein differs between uni- and multicellular organisms, that 12TM proteins are particularly abundant in unicellular organisms and 7TM protein in multi-cellular organisms, and that most multi-spanning proteins have roughly 35 residues per transmembrane segment. A study of 3D structures from three helix bundle membrane proteins showed that the general architecture of these consist of a helical region extending +15-25 Å from the center of the membrane. The helices are connected to the globular domains by a coil region, without secondary structure elements, about +-20-30 Å from the membrane center. It was confirmed that the previously observed aromatic regions around 12-15 Å from the center of the membrane is a conserved feature of helix bundle membrane proteins. An example of divergent evolution of the topology of a membrane protein was found when evaluating a new method for topology prediction on aligned protein families. The RnfA protein in E. coli was found to have the opposite orientation to its homolog RnfE. This was experimentally verified by mapping the topology of both RnfA and RnfE. 43 44 References Alkorta, I. and Du, P. (1994). Sequence divergence analysis for the prediction of seven-helix membrane protein structures: II. A 3-D model of human rhodopsin. Protein Eng, 7(10):1231–1238, Medline. 2.3 Andersson, H. and von Heijne, G. (1991). A 30-residue-long ”export initiation domain” adjacent to the signal sequence is critical for protein translocation across the inner membrane of Escherichia coli. Proc Natl Acad Sci USA, 88(21):9751–9754, Medline. 3.1.4 Andersson, H. and von Heijne, G. (1994). Membrane protein topology: effects of ∆µH+ on the translocation of charged residues explain the ’positive inside’ rule. EMBO J, 13(10):2267–2272, Medline. 1 Arkin, I., Brunger, A., and Engelman, D. (1997). Are there dominant membrane protein families with a given number of helices? Proteins, 28(4):465–466, Medline. 4.2 Aurora, R., Srinivasan, R., and Rose, G. (1994). Rules for alpha-helix termination by glycine. Science, 264(5162):1126–1130, Medline. 3.2.6 Bowie, J. (1997). Helix packing in membrane proteins. J Mol Biol, 272(5):780– 789, Medline, WWW. 3.2, 3.2.1 Boyd, D., Schierle, C., and Beckwith, J. (1998). How many membrane proteins are there? Protein Sci, 7(1):201–205, Medline. 4.1, 4.1 Branden, C. and Tooze, J. (1999). Introduction to Protein Structure. Garland, second edition, WWW. 3.2.1 Braun, P. and von Heijne, G. (1999). The aromatic residues Trp and Phe have different effects on the positioning of a transmembrane helix in the microsomal membrane. Biochemistry, 38(30):9778–9782, Medline. 3.2.3 Damodaran, S. and Song, K. (1986). The role of solvent polarity in the free energy of transfer of amino acid side chains from water to organic solvents. J Biol Chem, 261:7220–7222, Medline. 2.1.1 de Planque, M., Kruijtzer, J., Liskamp, R., Marsh, D., Greathouse, D., Koeppe, R. n., de Kruijff, B., and Killian, J. (1999). Different membrane anchoring positions of tryptophan and lysine in synthetic transmembrane alphahelical peptides. J Biol Chem, 274(30):20839–20846, Medline, WWW. 3.2.3 45 Doig, A. and Baldwin, R. (1995). N- and C-capping preferences for all 20 amino acids in alpha-helical peptides. Protein Sci, 4(7):1325–1336, Medline. 3.2.6 Donnelly, D., Overington, J., Ruffle, S., Nugent, J., and Blundell, T. (1993). Modeling alpha-helical transmembrane domains: the calculation and use of substitution tables for lipid-facing residues. Protein Sci, 2(1):55–70, Medline. 2.3, 2.3, 3.2.5 Eisenberg, D., Schwarz, E., Komaromy, M., and Wall, R. (1984). Analysis of membrane and surface protein sequences with the hydrophobic moment plot. J Mol Biol, 179(1):125–142, Medline. 2.3 Engelman, D., Steitz, T., and Goldman, A. (1986). Identifying nonpolar transbilayer helices in amino acid sequences of membrane proteins. Annu Rev Biophys Biophys Chem, 15:321–353, Medline. 2.1 Fauchere, J.-L. and Pliska, V. (1983). Hydrophobic parameters pi of amino acid side chains from the partitioning of N-acetyl-amino-acid amides. Eur J Med Chem, 18:369–375. 2.1.1 Hartmann, E., Rapoport, T., and Lodish, H. (1989). Predicting the orientation of eukaryotic membrane-spanning proteins. Proc Natl Acad Sci USA, 86(15):5786–5790, Medline. 3.1.2 Jones, D. (1998). Do transmembrane protein superfolds exist? 423(3):281–285, Medline. 4.1, 4.1, 4.2 FEBS Lett, Jones, D., Taylor, W., and Thornton, J. (1994). A model recognition approach to the prediction of all-helical membrane protein structure and topology. Biochemistry, 33(10):3038–3049, Medline. 2.2.5 Karplus, P. (1997). Hydrophobicity regained. Protein Sci, 6(6):1302–1307, Medline, WWW. 2.1.1 Kuroiwa, T., Sakaguchi, M., Mihara, K., and Omura, T. (1991). Systematic analysis of stop-transfer sequence for microsomal membrane. J Biol Chem, 266(14):9251–9255, Medline. 3.1.1, 3.1.4 Kyte, J. and Doolittle, R. (1982). A simple method for displaying the hydropathic character of a protein. J Mol Biol, 157(1):105–132, Medline. 2.1 MacArthur, M. and Thornton, J. (1991). Influence of proline residues on protein conformation. J Mol Biol, 218(2):397–412, Medline. 3.2.6 Nakashima, H. and Nishikawa, K. (1992). The amino acid composition is different between the cytoplasmic and extracellular sides in membrane proteins. FEBS Letters, 303(2,3):141–146. 3.1.3 Nozaki, Y. and Tanford, C. (1971). The solubility of amino acids and two glycine peptides in aqueous ethanol and dioxane solutions. J Biol Chem, 246:2211–2217, Medline. 2.1.1 Pasquier, C., Promponas, V., Palaios, G., Hamodrakas, J., and Hamodrakas, S. (1999). A novel method for predicting transmembrane segments in proteins based on a statistical analysis of the SwissProt database: the PRED-TMR algorithm. Protein Eng, 12(5):381–385, Medline. 2.2.6 46 Pautsch, A. and Schulz, G. (1998). Structure of the outer membrane protein A transmembrane domain. Nat Struct Biol, 5(11):1013–1017, Medline. 1.1.3 Pawagi, A., Wang, J., Silverman, M., Reithmeier, R., and Deber, C. (1994). Transmembrane aromatic amino acid distribution in P-glycoprotein. A functional role in broad substrate specificity. J Mol Biol, 235(2):554–564, Medline. 3.2.3 Persson, B. and Argos, P. (1994). Prediction of transmembrane segments in proteins utilising multiple sequence alignments. J Mol Biol, 237(2):182– 192, Medline. 2.2.4 Radzicka, A. and Wolfenden, R. (1988). Comparing the polarities of the amino acids: side-chain distribution coefficients between the vapor phase, cyclohexane, 1-octanol, and neutral aqueous solution. Biochemistry, 27:1664– 1670. 2.1.1 Rees, D., DeAntonio, L., and Eisenberg, D. (1989a). Hydrophobic organization of membrane proteins. Science, 245(4917):510–513, Medline. 2.3, 3.2.2, 3.2.5, 3.2.5 Rees, D., Komiya, H., Yeates, T., Allen, J., and Feher, G. (1989b). The bacterial photosynthetic reaction center as a model for membrane proteins. Annu Rev Biochem, 58:607–633, Medline. 3.2.1 Richardson, J. and Richardson, D. (1988). Amino acid preferences for specific locations at the ends of alpha helices. Science, 240(4859):1648–1652, Medline. 3.2.6, 3.2.6 Rost, B., Fariselli, P., and Casadio, R. (1996). Topology prediction for helical transmembrane proteins at 86% accuracy. Protein Sci, 5(8):1704–1718, Medline. 2.2.3 Schiffer, M., Chang, C., and Stevens, F. (1992). The functions of tryptophan residues in membrane proteins. Protein Eng, 5(3):213–214, Medline. 3.2.3 Schneider, T., Stormo, G., Gold, L., and Ehrenfeucht, A. (1986). Information content of binding sites on nucleotide sequences. J Mol Biol, 188(3):415– 431, Medline. 3.2.5 Schuenemann, T., Delgado-Nixon, V., and Dalbey, R. (1999). Direct evidence that the proton motive force inhibits membrane translocation of positively charged residues within membrane proteins. J Biol Chem, 274(11):6855– 6864, Medline. 1 Sipos, L. and von Heijne, G. (1993). Predicting the topology of eukaryotic membrane proteins. Eur J Biochem, 213(3):1333–1340, Medline. 3.1.2 Snijder, H. J., Ubarretxena-Belandia, I., Blaauw, M., Kalk, K. H., Verheij, H. M., Egmond, M. R., N., D., and W., D. B. (1999). Structural evidence for dimerization-regulated activation of an integral membrane phospholipase. Nature, 401:717–721, WWW. 1.1.3 47 Sonnhammer, E., von Heijne, G., and Krogh, A. (1998). A hidden Markov model for predicting transmembrane helices in protein sequences. Intell. Syst. Mol.Biol., 6:175–182, PDF. 2.2.7 Taylor, W., Jones, D., and Green, N. (1994). A method for α-helical integral membrane protein fold prediction. Proteins, 18(3):281–294, Medline. 2.3 Tusnady, G. and Simon, I. (1998). Principles governing amino acid composition of integral membrane proteins: application to topology prediction. J Mol Biol, 283(2):489–506, Medline. 2.2.8 van de Vossenberg, J., Albers, S., van der Does, C., Driessen, A., and van Klompenburg, W. (1998). The positive inside rule is not determined by the polarity of the delta psi. Mol Microbiol, 29(4):1125–1127, Medline, WWW. 1 van Klompenburg, W. and de Kruijff, B. (1998). The role of anionic lipids in protein insertion and translocation in bacterial membranes. J Membr Biol, 162(1):1–7, Medline, WWW. 1 van Klompenburg, W., Nilsson, I., von Heijne, G., and de Kruijff, B. (1997). Anionic phospholipids are determinants of membrane protein topology. EMBO J, 16(14):4261–4266, Medline, WWW. 1 von Heijne, G. (1992). Membrane protein structure prediction. Hydrophobicity analysis and the positive-inside rule. J Mol Biol, 225(2):487–494, Medline. 2.1, 2.2.1, 3.1.1 von Heijne, G. (1994). Membrane proteins: from sequence to structure. Annu Rev Biophys Biomol Struct, 23:167–192, Medline. 3.2.3 von Heijne, G. and Gavel, Y. (1988). Topogenic signals in integral membrane proteins. Eur J Biochem, 174(4):671–678, Medline. 3.1.1, 3.1.1 Weiss, M., Abele, U., Weckesser, J., Welte, W., Schiltz, E., and Schulz, G. (1991). Molecular architecture and electrostatic properties of a bacterial porin. Science, 254(5038):1627–1630, Medline. 3.2.3 Yeates, T., Komiya, H., Rees, D., Allen, J., and Feher, G. (1987). Structure of the reaction center from Rhodobacter sphaeroides R-26: membrane-protein interactions. Proc Natl Acad Sci USA, 84(18):6438–6442, Medline. 3.2.1 48 Chapter 6 Papers 49 I This article is unfortunately only available in the printed thesis. Look at the reference in section and follow the links from there. II III IV V VI This article is unfortunately only available in the printed thesis. Look at the reference in section and follow the links from there.