Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Artificial gene synthesis wikipedia , lookup
Multi-state modeling of biomolecules wikipedia , lookup
Genetic code wikipedia , lookup
Gene expression wikipedia , lookup
Ribosomally synthesized and post-translationally modified peptides wikipedia , lookup
Magnesium transporter wikipedia , lookup
Point mutation wikipedia , lookup
Expression vector wikipedia , lookup
Drug design wikipedia , lookup
G protein–coupled receptor wikipedia , lookup
Biochemistry wikipedia , lookup
Ancestral sequence reconstruction wikipedia , lookup
Interactome wikipedia , lookup
Western blot wikipedia , lookup
Protein purification wikipedia , lookup
Proteolysis wikipedia , lookup
Protein–protein interaction wikipedia , lookup
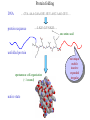
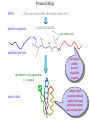
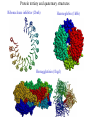
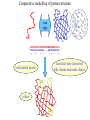
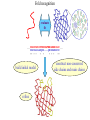
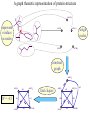
Protein Structure Prediction Ram Samudrala University of Washington Rationale for understanding protein structure and function Protein sequence -large numbers of sequences, including whole genomes ? Protein function - rational drug design and treatment of disease - protein and genetic engineering - build networks to model cellular pathways - study organismal function and evolution structure determination structure prediction Protein structure - three dimensional - complicated - mediates function homology rational mutagenesis biochemical analysis model studies Protein folding …-CUA-AAA-GAA-GGU-GUU-AGC-AAG-GUU-… DNA protein sequence …-L-K-E-G-V-S-K-D-… one amino acid unfolded protein spontaneous self-organisation (~1 second) native state not unique mobile inactive expanded irregular Protein folding …-CUA-AAA-GAA-GGU-GUU-AGC-AAG-GUU-… DNA protein sequence …-L-K-E-G-V-S-K-D-… one amino acid unfolded protein spontaneous self-organisation (~1 second) native state not unique mobile inactive expanded irregular unique shape precisely ordered stable/functional globular/compact helices and sheets Protein folding landscape Large multi-dimensional space of changing conformations J=10-3 s free energy unfolded molten globule barrier height DG* native J=10-8 s folding reaction Protein primary structure twenty types of amino acids two amino acids join by forming a peptide bond R R H H OH N H Cα O H C N C N O H H H Cα Cα C H OH O R each residue in the amino acid main chain has two degrees of freedom (f and y) R f N H H c N Cα y H R C f H O y Cα c f C N H O R H c Cα y H N C f H y Cα c O R the amino acid side chains can have up to four degrees of freedom (c1-4) O C Protein secondary structure many f,y combinations are not possible b sheet (anti-parallel) +180 b L f0 a -180 -180 C 0y a helix +180 N b sheet (parallel) C N Protein tertiary and quaternary structures Ribonuclease inhibitor (2bnh) Haemoglobin (1hbh) Hemagglutinin (1hgd) Methods for determining protein structure Protein sequence -large numbers of sequences, including whole genomes ? Protein function - rational drug design and treatment of disease - protein and genetic engineering - build networks to model cellular pathways - study organismal function and evolution X-ray crystallography NMR spectroscopy Protein structure - three dimensional - complicated - mediates function homology rational mutagenesis biochemical analysis model studies X-ray crystallography- concept • X-rays interact with electrons in protein molecules arranged in a crystal to produce diffraction patterns • The diffraction patterns of the x-rays can be used to determine the three-dimensional structure of proteins • Provides a “static” picture From <http://info.bio.cmu.edu/courses/03231/LecF01/Lec25/lec25.html> X-ray crystallography- details • Prepare protein crystals where the proteins are organised in a precise crystal lattice • Shine x-rays on crystals which diffract off of electrons of atoms in the crystals; the intensities of the individual reflections are measured • Phases are usually obtained indirectly by ismorphous replacement, from the way one or a few heavy atoms incorporated into the same isomorphous crystal lattice affect the diffraction patern • Intensities and phases of all reflections are combined in a Fourier transform to provide maps of electron density • Interpret the map by fitting the polypeptide chain to the contours • Refine the model by minimising the distance between the observed amplitudes and the calculated amplitudes NMR spectroscopy - concept • The magnetic-spin properties of atomic nuclei within a molecule are used to obtain a list of distance constraints between atoms in the molecule, from which a three-dimensional structure of the protein molecule can be obtained • Provides a “dynamic” picture NK-lysin (1nkl) S1 RNA binding domain (1sro) NMR spectroscopy - details • Protein molecules placed in a strong magnetic field have their hydrogen atoms aligned to the field; the alignment can be excited by applying radio frequency (RF) pulses • Possible to obtain unique signal (chemical shift) for each hydrogen atom in a protein molecule • Structural information arises primarily from the Nuclear Overhauser Effect (NOE), which gives information about distances between atoms in a molecule • A pair of protons give a detectable NOE cross-peak if they are within 5.0 Å of each other in space • After obtaining NOE data for protons througout the structure, a number of independent structures can be generated that are consistent with the distance constraints Computer representation of protein structure • Structures are stored in the protein data bank (PDB), a repository of mostly experimental models based on X-ray crystallographic and NMR studies • <http://www.rcsb.org> • Atoms are defined by their Cartesian coordinates: ATOM ATOM ATOM ATOM ATOM ATOM ATOM ATOM ATOM ATOM ATOM 1 2 3 4 5 6 7 8 9 10 11 N CA C O CB CG CD OE1 OE2 N CA GLU GLU GLU GLU GLU GLU GLU GLU GLU PHE PHE 1 1 1 1 1 1 1 1 1 2 2 18.222 17.706 17.368 16.780 16.552 16.952 15.881 16.012 14.701 17.762 17.509 18.496 17.982 16.466 16.073 18.744 20.118 21.145 22.316 20.768 15.746 14.262 -16.203 -14.905 -15.121 -16.175 -14.351 -13.803 -13.597 -13.292 -13.799 -14.052 -14.184 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 21.95 16.74 15.45 18.81 17.35 24.48 31.51 29.12 35.19 15.83 13.24 • These structures provide the basis for most of theoretical work in protein folding and protein structure prediction Comparison of protein structures • Need ways to determine if two protein structures are related and to compare predicted models to experimental structures • Commonly used measure is the root mean square deviation (RMSD) of the Cartesian atoms between two structures after optimal superposition (McLachlan, 1979): N 2 2 2 dx dy dz i i i i 1 N • Usually use Ca atoms 3.6 Å NK-lysin (1nkl) 2.9 Å Bacteriocin T102/as48 (1e68) • Other measures include contact maps and torsion angle RMSDs T102 best model Methods for predicting protein structure Protein sequence -large numbers of sequences, including whole genomes ? Protein function - rational drug design and treatment of disease - protein and genetic engineering - build networks to model cellular pathways - study organismal function and evolution comparative modelling fold recognition ab initio prediction Protein structure - three dimensional - complicated - mediates function homology rational mutagenesis biochemical analysis model studies Comparative modelling of protein structure • Proteins that have similar sequences (i.e., related by evolution) have similar three-dimensional structures • A model of a protein whose structure is not known can be constructed if the structure of a related protein has been determined by experimental methods • Similarity must be obvious and significant for good models to be built • Need ways to build regions that are not similar between the two related proteins • Need ways to move model closer to the native structure Comparative modelling of protein structure scan align … KDHPFGFAVPTKNPDGTMNLMNWECAIP KDPPAGIGAPQDN----QNIMLWNAVIP ** * * * * * * * ** build initial model refine … construct non-conserved side chains and main chains Fold recognition • The number of possible protein structures/folds is limited (large number of sequences but few folds) • Proteins that do not have similar sequences sometimes have similar three-dimensional structures 3.6 Å 5% ID NK-lysin (1nkl) Bacteriocin T102/as48 (1e68) • A sequence whose structure is not known is fitted directly (or “threaded”) onto a known structure and the “goodness of fit” is evaluated using a discriminatory function • Need ways to move model closer to the native structure Fold recognition evaluate fit … KDHPFGFAVPTKNPDGTMNLMNWECAIP KDPPAGIGAPQDN----QNIMLWNAVIP ** * * * * * * * ** build initial model refine … construct non-conserved side chains and main chains Ab initio prediction of protein structure – concept • Go from sequence to structure by sampling the conformational space in a reasonable manner and select a native-like conformation using a good discrimination function • Problems: conformational space is astronomical, and it is hard to design functions that are not fooled by non-native conformations (or “decoys”) Ab initio prediction of protein structure sample conformational space such that native-like conformations are found select hard to design functions that are not fooled by non-native conformations (“decoys”) astronomically large number of conformations 5 states/100 residues = 5100 = 1070 Sampling conformational space – continuous approaches • Most work in the field - Molecular dynamics - Continuous energy minimisation (follow a valley) - Monte Carlo simulation - Genetic Algorithms • Like real polypeptide folding process • Cannot be sure if native-like conformations are sampled energy Molecular dynamics • Force = -dU/dx (slope of potential U); acceleration, m a(t) = force • All atoms are moving so forces between atoms are complicated functions of time • Analytical solution for x(t) and v(t) is impossible; numerical solution is trivial • Atoms move for very short times of 10-15 seconds or 0.001 picoseconds (ps) old position new position acceleration x(t+Dt) = x(t) + v(t)Dt + [4a(t) – a(t-Dt)] Dt2/6 old velocity new velocity old velocity acceleration v(t+Dt) = v(t) + [2a(t+Dt)+5a(t)-a(t-Dt)] Dt/6 Ukinetic = ½ Σ mivi(t)2 = ½ n KBT • Total energy (Upotential + Ukinetic) must not change with time n is number of coordinates (not atoms) Energy minimisation • For a given protein, the energy depends on thousands of x,y,z Cartesian atomic coordinates; reaching a deep minimum is not trivial starting conformation energy deep minimum number of steps • With convergence, we have an accurate equilibrium conformation and a well-defined energy value energy steepest descent give up conjugate gradient number of steps converge RMSD Monte Carlo simulation • Discrete moves in torsion or cartesian conformational space • Evaluate energy after every move and compare to previous energy (DE) • Accept conformation based on Boltzmann probability: ΔE P exp kT • Many variations, including simulated annealing (starting with a high temperature so more moves are accepted initially and then cooling) • If run for infinite time, simulation will produce a Boltzmman distribution Genetic Algorithms • Generate an initial pool of conformations • Perform crossover and mutation operations on this set to generate a much larger pool of conformations • Select a subset of the fittest conformations from this large pool • Repeat above two steps until convergence Sampling conformational space – exhaustive approaches enumerate all possible conformations view entire space (perfect partition function) select must use discrete state models to minimise number of conformations explored computationally intractable: 5 states/100 residues = 5100 = 1070 possible conformations Scoring/energy functions • Need a way to select native-like conformations from non-native ones • Physics-based functions: electrostatics, van der Waals, solvation, bond/angle terms • Knowledge-based scoring functions: derive information about atomic properties from a database of experimentally determined conformations; common parametres include pairwise atomic distances and amino acid burial/exposure. Requirements for sampling methods and scoring functions • Sampling methods must produce good decoy sets that are comprehensive and include several native-like structures • Scoring function scores must correlate well with RMSD of conformations (the better the score/energy, the lower the RMSD) Overview of CASP experiment • Three categories: comparative/homology modelling, fold recognition/threading, and ab initio prediction • Goal is to assess structure prediction methods in a blind and rigourous manner; blind prediction is necessary for accurate assessment of methods • Ask modellers to build models of structures as they are in the process of being solved experimentally • After prediction season is over, compare predicted models to the experimental structures • Discuss what went right, what went wrong, and why • Compare progress from CASP1 to CASP4 • Results published in special issues of Proteins: Structure, Function, Genetics 1995, 1997, 1999, 2002 Comparative modelling at CASP - methods • Alignment: PSI-BLAST, FASTA, CLUSTALW - multiple sequence alignments carefully hand-edited using secondary structure information • More successful side chain prediction methods include: backbone-dependent rotamer libraries (Bower & Dunbrack) segment matching followed by energy minimisation (Levitt) self-consistent mean field optimisation (Bates et al) graph-theory + knowledge-based functions (Samudrala et al) • More successful loop building methods include: satisfaction of spatial restraints (Sali) internal coordinate mechanics energy optimisation (Abagyan et al) graph-theory + knowledge-based functions (Samudrala et al) • Overall model building: there is no substitute for careful hand-constructed models (Sternberg et al, Venclovas) A graph theoretic representation of protein structure -0.6 (V1) represent residues as nodes -0.5 (I) -0.9 (V2) weigh nodes -0.7 (K) -1.0 (F) construct graph -0.6 (V1) -0.5 (I) W = -4.5 -0.1 -0.3 -1.0 (F) -0.9 (V2) -0.1 -0.2 -0.7 (K) find cliques -0.5 (I) -0.1 -0.3 -1.0 (F) -0.9 (V2) -0.1 -0.2 -0.7 (K) -0.2 Historical perspective on comparative modelling BC alignment side chain short loops longer loops excellent ~ 80% 1.0 Å 2.0 Å Historical perspective on comparative modelling alignment side chain short loops longer loops BC CASP1 excellent ~ 80% 1.0 Å 2.0 Å poor ~ 50% ~ 3.0 Å > 5.0 Å Prediction for CASP4 target T128/sodm Ca RMSD of 1.0 Å for 198 residues (PID 50%) Prediction for CASP4 target T111/eno Ca RMSD of 1.7 Å for 430 residues (PID 51%) Prediction for CASP4 target T122/trpa Ca RMSD of 2.9 Å for 241 residues (PID 33%) Prediction for CASP4 target T125/sp18 Ca RMSD of 4.4 Å for 137 residues (PID 24%) Prediction for CASP4 target T112/dhso Ca RMSD of 4.9 Å for 348 residues (PID 24%) Prediction for CASP4 target T92/yeco Ca RMSD of 5.6 Å for 104 residues (PID 12%) Comparative modelling at CASP - conclusions alignment side chain short loops longer loops BC CASP1 CASP2 CASP3 CASP4 excellent ~ 80% 1.0 Å 2.0 Å poor ~ 50% ~ 3.0 Å > 5.0 Å fair ~ 75% ~ 1.0 Å ~ 3.0 Å fair ~75% ~ 1.0 Å ~ 2.5 Å fair ~75% ~ 1.0 Å ~ 2.0 Å CASP4: overall model accuracy ranging from 1 Å to 6 Å for 50-10% sequence identity **T128/sodm – 1.0 Å (198 residues; 50%) **T111/eno – 1.7 Å (430 residues; 51%) **T122/trpa – 2.9 Å (241 residues; 33%) **T125/sp18 – 4.4 Å (137 residues; 24%) **T112/dhso – 4.9 Å (348 residues; 24%) **T92/yeco – 5.6 Å (104 residues; 12%) Fold recognition at CASP - methods • Visual inspection with sequence comparison (Murzin group) • Procyon - potential of mean force based on pairwise interactions and global dynamic programming (Sippl group) • Threader - potential of mean force and double dynamic programming (Jones group) • Environmental 3D Profiles (Eisenberg group) • NCBI Threading Program using contact potentials and models of sequence-structure conservation (Bryant group) • Hidden Markov Models (Karplus group) • Combination of threading with ab initio approaches (Friesner group) • Environment-specific substitution tables and structure-dependent gap penalties (Blundell group) Fold recognition at CASP - conclusions • Fold recognition is one of the more successful approaches at predicting structure at all four CASPs • At CASP2 and CASP4, one of the best methods was simple sequence searching with careful manual inspection (Murzin group) • At CASP3 and CASP4, none of the threading targets could have been recognised by the best standard sequence comparison methods such as PSI-BLAST • For the most difficult targets, the methods were able to predict 60 residues to 6.0 Å Ca RMSD, approaching comparative modelling accuracies as the similarity between proteins increased. Ab initio prediction at CASP – methods • Assembly of fragments with simulated annealing (Simons et al) • Exhaustive sampling and pruning using knowledge-based scoring functions (Samudrala et al) • Constraint-based Monte Carlo optimisation (Skolnick et al) • Thermodynamic model for secondary structure prediction with manual docking of secondary structure elements and minimisation (Lomize et al) • Minimisation of a physical potential energy function with a simplified representation (Scheraga et al, Osguthorpe et al) • Neural networks to predict secondary structure (Jones, Rost) Semi-exhaustive segment-based folding EFDVILKAAGANKVAVIKAVRGATGLGLKEAKDLVESAPAALKEGVSKDDAEALKKALEEAGAEVEVK generate … fragments from database 14-state f,y model … minimise … monte carlo with simulated annealing conformational space annealing, GA … filter all-atom pairwise interactions, bad contacts compactness, secondary structure Historical perspective on ab initio prediction Before CASP (BC): “solved” CASP1: worse than random (biased results) CASP2: worse than random with one exception CASP3: consistently predicted correct topology - ~ 6.0 Å for 60+ residues *T56/dnab – 6.8 Å (60 residues; 67-126) **T61/hdea – 7.4 Å (66 residues; 9-74) **T64/sinr – 4.8 Å (68 residues; 1-68) *T74/eps15 – 7.0 Å (60 residues; 154-213) **T59/smd3 – 6.8 Å (46 residues; 30-75) **T75/ets1 – 7.7 Å (77 residues; 55-131) CASP4: ? Prediction for CASP4 target T110/rbfa Ca RMSD of 4.0 Å for 80 residues (1-80) Prediction for CASP4 target T97/er29 Ca RMSD of 6.2 Å for 80 residues (18-97) Prediction for CASP4 target T106/sfrp3 Ca RMSD of 6.2 Å for 70 residues (6-75) Prediction for CASP4 target T98/sp0a Ca RMSD of 6.0 Å for 60 residues (37-105) Prediction for CASP4 target T126/omp Ca RMSD of 6.5 Å for 60 residues (87-146) Prediction for CASP4 target T114/afp1 Ca RMSD of 6.5 Å for 45 residues (36-80) Postdiction for CASP4 target T102/as48 Ca RMSD of 5.3 Å for 70 residues (1-70) Ab initio prediction at CASP - conclusions Before CASP (BC): “solved” CASP1: worse than random (biased results) CASP2: worse than random with one exception CASP3: consistently predicted correct topology - ~ 6.0 Å for 60+ residues CASP4: consistently predicted correct topology - ~4-6.0 A for 60-80+ residues **T97/er29 – 6.0 Å (80 residues; 18-97) *T98/sp0a – 6.0 Å (60 residues; 37-105) **T102/as48 – 5.3 Å (70 residues; 1-70) **T106/sfrp3 – 6.2 Å (70 residues; 6-75) **T110/rbfa – 4.0 Å (80 residues; 1-80) *T114/afp1 – 6.5 Å (45 residues; 36-80) Computational aspects of structural genomics A. sequence space B. comparative modelling * * C. fold recognition * * * * * * * * E. target selection D. ab initio prediction F. analysis * * * * * * * * * * * * * * targets (Figure idea by Steve Brenner.) Key points • DNA/gene is the blueprint - proteins are the functional representatives of genes • Protein structure can be used to understand protein function • Large numbers of genes being sequenced - need structures • Protein folding (from primary sequence to tertiary structure) is a fast self-organising process where a disordered non-functional chain of amino acids becomes a stable, compact, and functional molecule • The free energy difference between the folded and unfolded states is not very high • Experimental methods to determine protein structures include x-ray crystallography and NMR spectroscopy • Theoretical methods to predict protein structures include comparative/homology modelling, fold recognition/threading, and ab initio prediction • For ab initio prediction, you need a method that samples the conformational space adequately (to find native-like conformations) and a function that can identify them • CASP experiment shows limited progress in protein structure prediction Acknowledgements Michael Levitt, Stanford University John Moult, CARB Patrice Koehl, Stanford University Yu Xia, Stanford Univeristy Levitt and Moult groups <http://compbio.washington.edu>