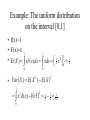Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Probability theory 2 Tron Anders Moger September 13th 2006 The Binomial distribution • Bernoulli distribution: One experiment with two possible outcomes, probability of success P. • If the experiment is repeated n times • The probability P is constant in all experiments • The experiments are independent • Then the number of successes follows a binomial distribution The Binomial distribution If X has a Binomial distribution, its PDF is defined as: n! x n x P( X x) P (1 P) x!(n x)! E ( X ) nP Var ( X ) nP (1 P ) Example • Since the early 50s, 10000 UFO’s have been reported in the U.S. • Assume P(real observation)=1/100000 • Binomial experiments, n=10000, p=1/100000 • X counts the number of real observations P(At least one observatio n is real) P( X 1) 1 P( X 0) 0 10000 10000 1 1 1 0.095 9.5% 1 0 10000 10000 The Hypergeometric distribution • Randomly sample n objects from a group of N, S of which are successes. The distribution of the number of successes, X, in the sample, is hypergeometric distributed: S N S S! ( N S )! x n x x!( S x)! (n x)!( N S n x)! P( X x) N! N n!( N n)! n Example • What is the probability of winning the lottery, that is, getting all 7 numbers on your coupon correct out of the total 34? 7 34 7 7! (34 7)! 7 7 7 7!(7 7)! (7 7)!(34 7 7 7)! 1.86 10 7 P( X 7) 34! 34 7!(34 7)! 7 The distribution of rare events: The Poisson distribution • Assume successes happen independently, at a rate λ per time unit. The probability of x successes during a time unit is given by the Poisson distribution: x e P( x) x! E( X ) Var ( X ) Example: AIDS cases in 1991 (47 weeks) • Cases per week: 110121300000021221301000 11111021020216100102000 • Mean number of cases per week: λ=44/47=0.936 • Can model the data as a Poisson process with rate λ=0.936 Example cont’d: No. of No. Expected no. observed cases observed (from Poisson dist.) 0 20 18.4 1 16 17.2 2 8 8.1 3 2 2.5 4 0 0.6 5 0 0.11 6 1 0.017 • Calculation: P(X=2)=0.9362*e-0.936/2!=0.17 • Multiply by the number of weeks: 0.17*47=8.1 • Poisson distribution fits data fairly well! The Poisson and the Binomial • • • • Assume X is Bin(n,P), E(X)=nP Probability of 0 successes: P(X=0)=(1-p)n Can write λ =nP, hence P(X=0)=(1- λ/n)n If n is large and P is small, this converges to e-λ, the probability of 0 successes in a Poisson distribution! • Can show that this also applies for other probabilities. Hence, Poisson approximates Binomial when n is large and P is small (n>5, P<0.05). Bivariate distributions • If X and Y is a pair of discrete random variables, their joint probability function expresses the probability that they simultaneously take specific values: – – – – P ( x, y ) P ( X x Y y ) marginal probability: P( x) P( x, y ) P ( x, y ) P( x | y ) conditional probability: P( y ) X and Y are independent if for all x and y: y P ( x, y ) P ( x ) P ( y ) Example • The probabilities for – A: Rain tomorrow – B: Wind tomorrow are given in the following table: No wind Some wind Strong wind Storm No rain 0.1 0.2 0.05 0.01 Light rain 0.05 0.1 0.15 0.04 Heavy rain 0.05 0.1 0.1 0.05 Example cont’d: • Marginal probability of no rain: 0.1+0.2+0.05+0.01=0.36 • Similarily, marg. prob. of light and heavy rain: 0.34 and 0.3. Hence marginal dist. of rain is a PDF! • Conditional probability of no rain given storm: 0.01/(0.01+0.04+0.05)=0.1 • Similarily, cond. prob. of light and heavy rain given storm: 0.4 and 0.5. Hence conditional dist. of rain given storm is a PDF! • Are rain and wind independent? Marg. prob. of no wind: 0.1+0.05+0.05=0.2 P(no rain,no wind)=0.36*0.2=0.072≠0.1 Covariance and correlation • Covariance measures how two variables vary together: Cov( X , Y ) E ( X E( X ))(Y E(Y )) E( XY ) E( X ) E(Y ) • Correlation is always between -1 and 1: Corr ( X , Y ) Cov( X , Y ) Cov( X , Y ) Var ( X )Var (Y ) XY • If X,Y independent, then E ( XY ) E ( X ) E (Y ) • If X,Y independent, then Cov( X , Y ) 0 • If Cov(X,Y)=0 then Var ( X Y ) Var ( X ) Var (Y ) Continuous random variables • Used when the outcomes can take any number (with decimals) on a scale • Probabilities are assigned to intervals of numbers; individual numbers generally have probability zero • Area under a curve: Integrals Cdf for continuous random variables • As before, the cumulative distribution function F(x) is equal to the probability of all outcomes less than or equal to x. • Thus we get P(a X b) F (b) F (a) • The probability density function is however b now defined so that P(a X b) f ( x)dx • We get that F ( x0 ) a x0 f ( x)dx Expected values • The expectation of a continuous random variable X is defined as E ( X ) xf ( x)dx • The variance, standard deviation, covariance, and correlation are defined exactly as before, in terms of the expectation, and thus have the same properties Example: The uniform distribution on the interval [0,1] • f(x)=1 • F(x)=x 1 1 1 1 2 • E ( X ) xf ( x)dx xdx 2 x 12 0 0 0 2 2 Var ( X ) E ( X ) E ( X ) • 1 x d ( x) 0.5 13 14 121 2 0 2 The normal distribution • The most used continuous probability distribution: – Many observations tend to approximately follow this distribution – It is easy and nice to do computations with – BUT: Using it can result in wrong conclusions when it is not appropriate Histogram of weight with normal curve displayed Distribution of weight among 95 students 25 20 15 10 5 0 40.0 45.0 50.0 Weight (kg) 55.0 60.0 65.0 70.0 75.0 80.0 85.0 90.0 95.0 The normal distribution • The probability density function is f ( x) 1 2 2 e ( x )2 / 2 2 where E ( X ) Var ( X ) 2 2 Notation N ( , ) Standard normal distribution N (0,1) Using the normal density is often OK unless the actual distribution is very skewed • Also: µ±σ covers ca 65% of the distribution • µ±2σ covers ca 95% of the distribution • • • • The normal distribution with small and large standard deviation σ 0.4 0.3 0.2 0.1 02 4 6 8 10 x 12 14 16 18 20 Simple method for checking if data are well approximated by a normal distribution: Explore • As before, choose Analyze->Descriptive Statistics->Explore in SPSS. • Move the variable to Dependent List (e.g. weight). • Under Plots, check Normality Plots with tests. Histogram of lung function for the students 20 16 12 8 4 Std. D ev = 120.12 Mean = 503 N = 95.00 0 300 400 350 500 450 600 550 700 650 800 750 Aver age PEF value measur ed in a sitting position Q-Q plot for lung function Normal Q-Q Plot of PEFSITTM 3 2 1 0 -1 -2 -3 200 300 Observed Value 400 500 600 700 800 Age – not normal Histo gra m 50 40 30 20 10 Std. D ev = 3.11 Mean = 22.4 N = 95.00 0 20.0 Age 22.5 25.0 27.5 30.0 32.5 35.0 Q-Q plot of age Normal Q-Q Plot of AGE 3 2 1 0 -1 -2 10 Observed Value 20 30 40 A trick for data that are skewed to the right: Log-transformation! 40 30 20 10 Std. Dev = 1.71 Mean = 1.50 0 0.0 0 1.0 0 2.0 0 3.0 0 4.0 0 5.0 0 6.0 0 7.0 0 8.0 0 9.0 0 10 .00 = 1 06.00 1N 1.0 0 SKEWED Skewed distribution, with e.g. the observations 0.40, 0.96, 11.0 Log-transformed data 14 12 10 8 6 4 Std. Dev = 1.05 2 Mean = -.12 N = 1 06.00 0 25 2. 75 1. 25 1. 5 .7 5 .2 25 -. 75 -. 5 .2 -1 5 .7 -1 5 .2 -2 5 .7 -2 LNSKEWD ln(0.40)=-0.91 ln(0.96)=-0.04 ln(11) =2.40 Do the analysis on logtransformed data SPSS: transform- compute OK, the data follows a normal distribution, so what? • First lecture, pairs of terms: – Sample – population – Histogram – distribution – Mean – Expected value • In statistics we would like the results from analyzing a small sample to apply for the population • Has to collect a sample that is representative w.r.t. age, gender, home place etc. New way of reading tables and histograms: • Histograms show that data can be described by a normal distribution • Want to conclude that data in the population are normally distributed • Mean calculated from the sample is an estimate of the expected value µ of the population normal distribution • Standard deviation in the sample is an estimate of σ in the population normal distribution • Mean±2*(standard deviation) as estimated from the sample (hopefully) covers 95% of the population normal distribution In addition: • Most standard methods for analyzing continuous data assumes a normal distribution. • When n is large and P is not too close to 0 or 1, the Binomial distribution can be approximated by the normal distribution • A similar phenomenon is true for the Poisson distribution • This is a phenomenon that happens for all distributions that can be seen as a sum of independent observations. • Means that the normal distribution appears whenever you want to do statistics The Exponential distribution • The exponential distribution is a distribution for positive numbers (parameter λ): f (t ) e t • It can be used to model the time until an event, when events arrive randomly at a constant rate E (T ) 1/ Var (T ) 1/ 2 Next time: • Sampling and estimation • Will talk much more in depth about the topics mentioned in the last few slides today