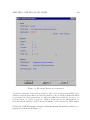
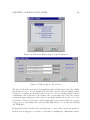
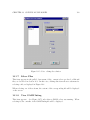
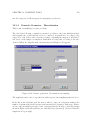
Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Predictive analytics wikipedia , lookup
Computational electromagnetics wikipedia , lookup
Inverse problem wikipedia , lookup
Hardware random number generator wikipedia , lookup
Computer simulation wikipedia , lookup
General circulation model wikipedia , lookup
History of numerical weather prediction wikipedia , lookup
Data assimilation wikipedia , lookup
Least squares wikipedia , lookup
SLP–IOR USER’S GUIDE Version 2.3.4 Peter Kall and János Mayer Zürich, 05.10.2010 Contents I BASICS 1 Introduction 1.1 Developers, availability . . . . . . 1.2 History . . . . . . . . . . . . . . . 1.3 Main features . . . . . . . . . . . 1.4 Solvers connected . . . . . . . . . 1.5 Publications concerning SLP–IOR 1.6 Hardware/software . . . . . . . . 1.7 This Guide . . . . . . . . . . . . 1.8 Acknowledgements . . . . . . . . 2 Installation and usage 2.1 Installing/deinstalling SLP–IOR . 2.2 Starting up SLP–IOR . . . . . . . 2.3 Configuring SLP–IOR . . . . . . 2.4 Usage of SLP–IOR . . . . . . . . 2.5 SLP–IOR and GAMS . . . . . . . 2.6 The student version of SLP–IOR 3 The 3.1 3.2 3.3 3.4 10 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 11 12 12 13 15 15 15 16 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 18 20 21 25 26 27 scope of SLP–IOR: SLP–models General considerations . . . . . . . . . . . . . . . One stage deterministic LP models . . . . . . . . SLP models with a joint chance constraint . . . . 3.3.1 The underlying algebraic structure . . . . 3.3.2 The underlying random variables structure 3.3.3 The underlying regression structure . . . . 3.3.4 Underlying LP model . . . . . . . . . . . . 3.3.5 Expected value problem . . . . . . . . . . 3.3.6 Current solver availability . . . . . . . . . SLP models with separate chance constraints . . . 3.4.1 The underlying algebraic structure . . . . 3.4.2 The underlying random variables structure 3.4.3 The underlying regression structure . . . . 3.4.4 Underlying LP model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28 28 30 30 31 31 32 32 32 33 33 34 34 34 34 . . . . . . 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . CONTENTS 3.4.5 Expected value problem . . . . . . . . . . . . . . . . . . . 3.4.6 Equivalent LP . . . . . . . . . . . . . . . . . . . . . . . . . 3.4.7 Current solver availability . . . . . . . . . . . . . . . . . . 3.5 SLP models with a joint integrated chance constraint . . . . . . . 3.5.1 Modeling losses . . . . . . . . . . . . . . . . . . . . . . . . 3.5.2 The underlying algebraic structure . . . . . . . . . . . . . 3.5.3 The underlying random variables structure . . . . . . . . . 3.5.4 The underlying regression structure . . . . . . . . . . . . . 3.5.5 Underlying LP model . . . . . . . . . . . . . . . . . . . . . 3.5.6 Expected value problem . . . . . . . . . . . . . . . . . . . 3.5.7 Equivalent LP . . . . . . . . . . . . . . . . . . . . . . . . . 3.5.8 Current solver availability . . . . . . . . . . . . . . . . . . 3.6 SLP models with separate integrated chance constraints . . . . . . 3.6.1 Modeling losses . . . . . . . . . . . . . . . . . . . . . . . . 3.6.2 The underlying algebraic structure . . . . . . . . . . . . . 3.6.3 The underlying random variables structure . . . . . . . . . 3.6.4 The underlying regression structure . . . . . . . . . . . . . 3.6.5 Underlying LP model . . . . . . . . . . . . . . . . . . . . . 3.6.6 Expected value problem . . . . . . . . . . . . . . . . . . . 3.6.7 Equivalent LP . . . . . . . . . . . . . . . . . . . . . . . . . 3.6.8 Current solver availability . . . . . . . . . . . . . . . . . . 3.7 SLP models with CVaR functions . . . . . . . . . . . . . . . . . . 3.7.1 Modeling losses . . . . . . . . . . . . . . . . . . . . . . . . 3.7.2 The underlying algebraic structure . . . . . . . . . . . . . 3.7.3 The underlying random variables structure . . . . . . . . . 3.7.4 The underlying regression structure . . . . . . . . . . . . . 3.7.5 Underlying LP model . . . . . . . . . . . . . . . . . . . . . 3.7.6 Expected value problem . . . . . . . . . . . . . . . . . . . 3.7.7 Equivalent LP . . . . . . . . . . . . . . . . . . . . . . . . . 3.7.8 Current solver availability . . . . . . . . . . . . . . . . . . 3.8 Multistage deterministic LP models . . . . . . . . . . . . . . . . . 3.9 Two–stage recourse models . . . . . . . . . . . . . . . . . . . . . . 3.9.1 The underlying algebraic structure . . . . . . . . . . . . . 3.9.2 The underlying random variable structure . . . . . . . . . 3.9.3 The underlying regression structure . . . . . . . . . . . . . 3.9.4 Underlying LP model . . . . . . . . . . . . . . . . . . . . . 3.9.5 EV: Expected value problem . . . . . . . . . . . . . . . . . 3.9.6 The algebraic equivalent LP . . . . . . . . . . . . . . . . . 3.9.7 WS: Wait and see approach . . . . . . . . . . . . . . . . . 3.9.8 EEV: Expected result of the EV solution . . . . . . . . . . 3.9.9 Expected value of perfect information and expected result 3.9.10 RFS: Reliability of the first–stage solution . . . . . . . . . 3.9.11 Current solver availability . . . . . . . . . . . . . . . . . . 3.10 Models with simple integer recourse . . . . . . . . . . . . . . . . . 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35 35 35 36 37 38 38 38 38 39 39 40 41 42 43 43 43 43 44 44 45 46 47 48 48 48 48 49 49 50 51 51 53 53 54 54 54 55 56 57 57 58 58 59 CONTENTS 3.10.1 Current solver availability . . . . . . . . . . 3.11 Multiple simple recourse . . . . . . . . . . . . . . . 3.11.1 Current solver availability . . . . . . . . . . 3.12 Multistage recourse models . . . . . . . . . . . . . . 3.12.1 The underlying algebraic structure . . . . . 3.12.2 The underlying random variable structure . 3.12.3 The underlying regression structure . . . . . 3.12.4 Underlying LP model . . . . . . . . . . . . . 3.12.5 EV: Expected value problem . . . . . . . . . 3.12.6 Underlying two stage problem . . . . . . . . 3.12.7 Finite discrete distribution: the scenario tree 3.12.8 Algebraic equivalent LP’s . . . . . . . . . . 3.12.9 WS: Wait and see approach . . . . . . . . . 3.12.10 Computing the recourse objective . . . . . . 3.12.11 Block–separable recourse . . . . . . . . . . . 3.12.12 Current solver availability . . . . . . . . . . II 4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . MODELING 4 Building a model instance 4.1 Setting up a new model instance . . . . . . . . . . . . . . . 4.1.1 Setting up a deterministic LP . . . . . . . . . . . . 4.1.2 Setting up a stochastic model instance . . . . . . . 4.1.3 Using building blocks . . . . . . . . . . . . . . . . . 4.2 Input/output of model instances . . . . . . . . . . . . . . . 4.2.1 SLP–IOR format . . . . . . . . . . . . . . . . . . . 4.2.2 SMPS format . . . . . . . . . . . . . . . . . . . . . 4.2.3 GAMS format . . . . . . . . . . . . . . . . . . . . . 4.3 Modifying an existing model instance . . . . . . . . . . . . 4.3.1 Changing the type of the model instance . . . . . . 4.3.2 Recasting a model instance . . . . . . . . . . . . . 4.3.3 Example: building stochastic variants of a one stage 61 61 63 63 65 66 66 66 67 67 68 70 73 74 75 76 77 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . LP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78 78 79 80 82 82 82 82 83 83 83 83 84 5 Solving a model instance 87 5.1 Starting up a solver . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87 5.2 Viewing/saving the solution . . . . . . . . . . . . . . . . . . . . . . . . . . 87 6 Analyzing the model and solution 89 6.1 Analyzing the model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89 6.2 Analyzing the solution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89 CONTENTS 5 7 Modeling tools 91 7.1 Algebraic equivalent LP . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91 7.2 Arrays in the underlying algebraic structure . . . . . . . . . . . . . . . . . 91 7.3 Probability distribution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91 8 A workbench for testing solvers 8.1 Generating batteries of deterministic LP problems . . . . . . . . . . . . . . 8.2 Generating batteries of recourse problems . . . . . . . . . . . . . . . . . . . 8.3 Generating batteries of jointly chance constrained problems . . . . . . . . . 8.4 Dealing with batteries and performing test runs with them . . . . . . . . . 8.4.1 Performing a test run . . . . . . . . . . . . . . . . . . . . . . . . . . 8.4.2 Generating a battery consisting of variants of a single problem . . . 8.4.3 Discretizing the probability distribution for each element of a battery 8.4.4 Injecting the same probability distribution into each element of a battery . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8.4.5 Endowing each element of a battery with a normally distributed RHS 8.4.6 Endowing each element of a battery with a normal distribution . . 93 93 93 93 94 94 94 94 III 96 REFERENCE 9 Building an SLP model 9.1 Main menu item: File . . . . . . . . . . . . 9.1.1 New Model Instance . . . . . . . . 9.1.2 Open, SaveAs . . . . . . . . . . . . 9.1.3 Save . . . . . . . . . . . . . . . . . 9.1.4 Browse . . . . . . . . . . . . . . . . 9.1.5 Export/Import . . . . . . . . . . . 9.1.6 Exit . . . . . . . . . . . . . . . . . 9.2 Main menu item: Edit–Model . . . . . . . 9.2.1 Name of Model . . . . . . . . . . . 9.2.2 Min or Max . . . . . . . . . . . . . 9.2.3 Number of Stages . . . . . . . . . . 9.2.4 Dimensions . . . . . . . . . . . . . 9.2.5 Edit Data Arrays/Relations . . . . 9.2.6 Edit Names . . . . . . . . . . . . . 9.2.7 Edit Underlying LP . . . . . . . . . 9.2.8 Stochastic Parts . . . . . . . . . . . 9.2.9 Pick Random Entries . . . . . . . . 9.2.10 Edit Regression Terms . . . . . . . 9.2.11 Edit Dependency . . . . . . . . . . 9.2.12 Edit Distribution . . . . . . . . . . 9.2.13 Edit Distribution on Scenario Tree 9.2.14 Recast Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95 95 95 97 97 97 98 99 99 99 102 102 103 104 104 104 104 107 107 108 109 111 112 114 115 117 CONTENTS 9.3 6 9.2.15 Building Blocks I . . . . . . . 9.2.16 Building Blocks II . . . . . . . Main menu item: View–Model . . . . 9.3.1 View Data Arrays . . . . . . . 9.3.2 View Underlying LP Structure 9.3.3 View Random Variables Map 9.3.4 View Scenario Tree . . . . . . 10 Solving an SLP model 10.1 Main menu item: Solve . . . . 10.1.1 Solve current problem 10.1.2 Select Solver . . . . . . 10.1.3 View Results . . . . . 10.1.4 View Solution on Tree 10.1.5 Edit Solution . . . . . 10.1.6 Summary on Run . . . 10.1.7 Solver Files . . . . . . 10.1.8 View GAMS listing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 Analyzing the model instance and the solution 11.1 Main menu item: Analyze . . . . . . . . . . . . 11.1.1 Analyze Model Instance . . . . . . . . . 11.1.2 Analyze solutions . . . . . . . . . . . . . 11.1.3 Some further analysis facilities . . . . . . 11.1.4 Transform Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121 122 123 123 123 124 125 . . . . . . . . . 127 . 127 . 127 . 129 . 129 . 131 . 131 . 131 . 132 . 132 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134 . 134 . 134 . 136 . 138 . 138 12 Modeling tools 12.1 Main menu item: Algeb–Equi . . . . . . . . . . . . . . . . . 12.2 Main menu item: Algeb–Struct . . . . . . . . . . . . . . . . 12.2.1 Perturbing an array . . . . . . . . . . . . . . . . . . . 12.2.2 Compute rank of an array . . . . . . . . . . . . . . . 12.2.3 Check for complete recourse . . . . . . . . . . . . . . 12.3 Main menu item: Rand–Vars . . . . . . . . . . . . . . . . . . 12.3.1 Sample/Discretize per Group . . . . . . . . . . . . . 12.3.2 Sample/Discretize All . . . . . . . . . . . . . . . . . 12.3.3 Manually Build Scenario Tree . . . . . . . . . . . . . 12.3.4 Generate Scenarios – Discretization . . . . . . . . . . 12.3.5 Generate Scenarios – Moments . . . . . . . . . . . . 12.3.6 Generating random vectors with prescribed moments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140 140 141 141 142 142 143 143 147 147 150 151 155 13 Workbench for testing solvers 160 13.1 Main menu item: Workbench . . . . . . . . . . . . . . . . . . . . . . . . . 160 13.1.1 GENSLP: LP and recourse problems . . . . . . . . . . . . . . . . . 160 13.1.2 GENSLP: joint chance constraint . . . . . . . . . . . . . . . . . . . 163 CONTENTS 7 13.1.3 Test Problem Batteries . . . . . . . . . . . . . . . . . . . . . . . . . 166 14 Editors and viewers 14.1 The matrix editor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14.2 The matrix viewer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14.3 The probability distribution viewer . . . . . . . . . . . . . . . . . . . . . 171 . 171 . 173 . 174 15 Probability distributions 15.1 Univariate distributions . . . . 15.1.1 Discrete distributions . . 15.1.2 Continuous distributions 15.2 Multivariate distributions . . . 15.2.1 Discrete distributions . . 15.2.2 Continuous distributions . . . . . . 177 . 177 . 177 . 179 . 182 . 182 . 183 . . . . . . . . . . . . 184 . 185 . 185 . 187 . 189 . 189 . 190 . 191 . 191 . 191 . 192 . 193 . 193 . . . . . . . . . . . . . . 195 . 196 . 196 . 196 . 197 . 197 . 198 . 199 . 199 . 199 . 200 . 200 . 201 . 201 . 202 16 The 16.1 16.2 16.3 . . . . . . solver library Input data file for solver . . . . . Files to be produced by the solver The solver description database . 16.3.1 Basic . . . . . . . . . . . . 16.3.2 Dimensions . . . . . . . . 16.3.3 Models . . . . . . . . . . . 16.3.4 Random Var. . . . . . . . 16.3.5 Distributions . . . . . . . 16.3.6 Input/Output . . . . . . . 16.3.7 Control . . . . . . . . . . 16.3.8 Parameters . . . . . . . . 16.3.9 Specials . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 Solvers connected to SLP–IOR 17.1 General purpose LP solvers . . . . . . . . . . . . . . . . . . . . . . . . 17.1.1 HiPlex . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17.1.2 HOPDM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17.1.3 MINOS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17.1.4 OB1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17.1.5 XMP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17.2 Solvers for recourse problems using the structure of the equivalent LP . 17.2.1 BPMPD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17.2.2 MSLiP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17.2.3 QDECOM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17.2.4 SHOR2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17.3 Solvers for two–stage recourse problems aiming at the original problem 17.3.1 DAPPROX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17.3.2 SDECOM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . CONTENTS 17.4 Solvers for simple continuous recourse . . . . . . 17.4.1 SHOR1 . . . . . . . . . . . . . . . . . . 17.4.2 SRAPPROX . . . . . . . . . . . . . . . . 17.5 Solver for simple integer recourse . . . . . . . . 17.5.1 SIRD2SCR . . . . . . . . . . . . . . . . 17.6 Solver for multiple simple recourse . . . . . . . 17.6.1 MScr2Scr . . . . . . . . . . . . . . . . . 17.7 Solvers for jointly chance constrained problems . 17.7.1 PCSPIOR . . . . . . . . . . . . . . . . . 17.7.2 PROBALL . . . . . . . . . . . . . . . . 17.7.3 PROCON . . . . . . . . . . . . . . . . . 17.8 Solver for models involving integrated chance constraints . . . . . . . . . . . . . . . . . . . . . 17.8.1 ICCMIN . . . . . . . . . . . . . . . . . . 17.9 Solver for models involving CVaR . . . . . . . . 17.9.1 CVaRMin . . . . . . . . . . . . . . . . . 8 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203 203 203 204 204 205 205 206 206 207 208 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 209 209 209 209 . . . . . . . . . . . . . . . 210 210 210 210 211 211 211 212 212 212 212 212 213 213 213 213 18 Models versus solvers 18.1 Deterministic LP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18.2 Two stage recourse problems . . . . . . . . . . . . . . . . . . . . . . . . . 18.2.1 General recourse, finite discrete distribution . . . . . . . . . . . . 18.2.2 Fixed recourse, finite discrete distribution . . . . . . . . . . . . . 18.2.3 Relatively complete recourse, finite discrete distribution . . . . . . 18.2.4 Relatively complete recourse, some continuous distributions . . . 18.2.5 Simple continuous recourse, finite discrete distribution . . . . . . 18.2.6 Simple continuous recourse, some continuous distributions . . . . 18.2.7 Simple integer recourse, finite discrete distribution . . . . . . . . . 18.2.8 Multiple simple recourse, finite discrete distribution . . . . . . . . 18.3 Multistage recourse problems . . . . . . . . . . . . . . . . . . . . . . . . 18.3.1 General–purpose LP solvers . . . . . . . . . . . . . . . . . . . . . 18.3.2 Solvers utilizing the structure . . . . . . . . . . . . . . . . . . . . 18.4 Chance constrained problems . . . . . . . . . . . . . . . . . . . . . . . . 18.4.1 Separate chance constraints, only RHS stochastic . . . . . . . . . 18.4.2 Joint chance constraints, only RHS stochastic, multinormal distribution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18.5 Models with integrated chance constraints or objective . . . . . . . . . . 18.5.1 Separate integrated chance constraints or objective, finite discrete distribution . . . . . . . . . . . . . . . . . . . . . . 18.5.2 Joint integrated chance constraints or objective, finite discrete distribution . . . . . . . . . . . . . . . . . . . . . . 18.6 Models involving CVaR constraints or objective . . . . . . . . . . . . . . 18.6.1 Finite discrete distribution . . . . . . . . . . . . . . . . . . . . . . Copyright and disclaimer . 213 . 214 . 214 . 214 . 215 . 215 221 CONTENTS A Checklists for using SLP–IOR A.1 Setting up and solving a new LP model . . . . . . . . . . . . . . . . . . A.2 Setting up and solving a new SLP model I . . . . . . . . . . . . . . . . A.3 Setting up and solving a new SLP model II . . . . . . . . . . . . . . . . A.4 Recasting a deterministic LP as a two–stage recourse model I . . . . . A.5 Recasting a deterministic LP as a two–stage recourse model II . . . . . A.6 Recasting a deterministic LP as a jointly chance–constrained model . . A.7 Computing the overall objective for a first–stage vector . . . . . . . . . A.8 Computing EVPI and VSS . . . . . . . . . . . . . . . . . . . . . . . . . A.9 Discretizing the probability distribution for a group of random variables A.10 Performing a test run with a battery . . . . . . . . . . . . . . . . . . . 9 . . . . . . . . . . 222 . 222 . 223 . 224 . 225 . 226 . 227 . 228 . 229 . 230 . 231 B Glossary 232 Author Index 234 Subject Index 236 Part I BASICS 10 Chapter 1 Introduction 1.1 Developers, availability SLP–IOR is a model management system for stochastic linear programming (SLP), developed by Peter Kall and János Mayer, Institute for OR, University of Zurich. SLP–IOR is available free of charge for academic purposes. Concerning license, copyright and disclaimer issues please consult page 221. Two versions of SLP–IOR are available and can be downloaded from the WEB–site: http://www.ior.uzh.ch/research/stochOpt en.html The full version requires registration whereas the student version is readily available by merely acknowledging the copyright and disclaimer conditions by clicking the corresponding check–box of the copyright statement. Users are kindly asked to communicate to us • their experience concerning user–friendliness and modeling with SLP–IOR; • in the case of system malfunctioning or any irregularity in system performance a short description of the circumstances (bug report). We are interested in your impression and advice; please do not hesitate to communicate to us any kind of suggestions or criticism. Correspondence: • Our postal address: Institute for Operations Research, University of Zurich, Moussonstrasse 15, CH-8044 Zurich, Switzerland. • e–mail: [email protected] and [email protected] 11 CHAPTER 1. INTRODUCTION 1.2 12 History We have started to develop SLP–IOR around 1991; the first version was running in 1992. The system has been designed for two–stage and chance–constrained problems. Between 1992 and 1999 the system has been further developed: analysis facilities have been added, several own solvers have been developed, solvers (including our own solvers) have been connected, handling of test problem batteries (including randomly generated test problems) has been included, etc. The system has been intensively debugged and tested. All these versions were running under MSDOS. Among the users of SLP–IOR the most valuable comments, suggestions, and criticism we have received from Maarten van der Vlerk and his students at the Department of Econometrics and Operations Research, University of Groningen, The Netherlands. SLP– IOR has been used for teaching purposes in Groningen: the students of the SLP courses have solved their homework assignments with the help of SLP–IOR and have experimented with the system. The system is still in use at the University of Groningen. The algebraic modeling system GAMS was tightly integrated into SLP–IOR. We have utilized the solver interface of GAMS for starting up also our own solvers. As a consequence, the availability of GAMS on the user side was indispensable for using SLP–IOR. During the years between 1992 and 1999 MSDOS became gradually obsolete, by 1999 it was already quite cumbersome to use the system under MSDOS. In 2000 we have started to develop a Win32 version of SLP–IOR. The system design has been revised to allow for multistage models, and for models with integrated probability functions and Conditional Value–at–Risk (CVaR). The integration with GAMS has been loosened to allow for a stand–alone usage of SLP–IOR. For users having GAMS, we have kept the facilities which were available with the MSDOS version. In the subsequent years we have developed our own solvers for models involving integrated probability functions and CVaR, either in the objective function or as constraints, allowing for several constraints of this type. Recently we have also released a student version of SLP–IOR. The main motivation for this was the following: In the second edition of our book [40] we have also added exercises and we wanted to provide the readers of this book with an easily accessible program for solving those exercises. 1.3 Main features • Scope: deterministic LP; multistage recourse; for the two–stage case complete–, simple continuous–, simple integer–, multiple simple recourse models; joint chance– CHAPTER 1. INTRODUCTION 13 constraints (only RHS stochastic, multivariate normal distribution); separate chance– constraints (only RHS stochastic); constraints or objectives involving integrated probability functions; constraints or objectives involving conditional value–at–risk (CVaR). • Using GAMS (optional): availability of GAMS solvers from SLP–IOR, importing an LP formulated in the algebraic modeling language GAMS in order to develop stochastic versions. • Analysis facilities for recourse models: computing EVPI and VSS (for discrete distributions directly otherwise via sampling); checking the complete recourse property; computing the recourse objective with the first stage solution being fixed. • Transformation facilities: transforming a model into another model type, e.g. two– stage to chance–constraints, two–stage to expected value problem, or multistage recourse to LP–equivalents (for discrete distributions). • Building blocks: export/import of the main model parts; export/import of (parts of) arrays via a blackboard or via the Windows clipboard. • Workbench facilities: dealing with test problem batteries which includes randomly generating test problem batteries; solving a selected set of model instances with a selected set of solvers in turn. • I/O of model instances: I/O in own data format, I/O in SMPS format for LP and two–stage recourse, input in GAMS format for LP’s. • Solver library: several solvers are connected to SLP–IOR; one of the facilities supports connecting the user’s own solver to SLP–IOR. 1.4 Solvers connected Apart from the optional GAMS solvers, the list below contains all solvers presently connected to SLP–IOR. Those which are underlined are shipped with SLP–IOR, for the rest the user needs a separate license from the author of the solver. The name of the solver is followed by the scope in parentheses, meaning the general problem class for which the solver is designed. The applicability of the solvers may further be constrained by specific model features like stochastic parts and probability distribution; for the details see Chapter 17. Solvers labeled as LP–solvers are naturally also available for SLP problems where an LP equivalent exists. The authors listed are the developers of the solver and are not necessarily the same as the authors of the underlying algorithm. The years indicated are the development years of the solver version presently connected to SLP–IOR. • BPMPD (LP) Cs. Mészáros, 1996, augmented system IP method. • CVaRMin (CVaR constraint or objective) A. Künzi–Bay and J. Mayer, 2004, Benders– decomposition. CHAPTER 1. INTRODUCTION 14 • DAPPROX (two stage complete recourse) P. Kall and J. Mayer, 2001, successive discrete approximation. • HiPlex (LP) I. Maros, 1997, simplex method. • HOPDM (LP) J. Gondzio, 1996, primal-dual IP method. • ICCMIN (integrated probability constraint or objective) A. Künzi–Bay and J. Mayer, 2005, Benders–type decomposition method of Klein Haneveld and Van der Vlerk. • MINOS (LP) B.A. Murtagh and M.A. Saunders, 1995, simplex method. • MScr2Scr (multiple simple recourse), J. Mayer and M.H. van der Vlerk, 2001, transformation method. • MSLiP (two stage recourse) H. Gassmann 1995, Benders decomposition (L-shaped method). • OB1 (LP) R.E. Marsten et al. 1989, IP methods. • PCSPIOR, (joint chance constraints) J. Mayer 1995, cutting planes. • PROBALL, (joint chance constraints) J. Mayer 2001, central cutting planes. • PROCON, (joint chance constraints) J. Mayer 1992, reduced gradient method. • QDECOM, (two stage recourse) A. Ruszczyński 1985, regularized decomposition. • SAA (two–stage recourse) J. Mayer, 2005, sample average approximation. • SDECOM, (two stage complete recourse), P. Kall and J. Mayer 1995, stochastic decomposition. • SHOR1, (two stage simple recourse), N. Shor and A. Likhovid, 1997, decomposion, r-algorithm of Shor. • SHOR2, (two stage complete recourse), N. Shor and A. Likhovid, 1998, decomposion, r-algorithm of Shor. • SIRD2SCR, (simple integer recourse), J. Mayer and M.H. van der Vlerk, 1994, convex hull method. • SRAPPROX, (simple recourse), P. Kall and J. Mayer, 1994, successive discrete approximation. • XMP (LP) R.E. Marsten, 1986, simplex method. CHAPTER 1. INTRODUCTION 1.5 15 Publications concerning SLP–IOR For a detailed description of goals and of the system architecture of SLP–IOR see Kall and Mayer [30], [31], [33], [34], [35], [36], [37], [39], [40], [41], and Mayer [56]. For our further papers with SLP–IOR in use, see Kall and Mayer [38], [42], Künzi–Bay and Mayer [50], Mayer [57], [58]. 1.6 Hardware/software The development of the present version of SLP–IOR is being done on an IBM PC/Intel Core(TM)2 Duo CPU, 3.16GHz, 3.25GB RAM computer, and has been tested by ourselves on Windows NT 4.0, Windows 95, Windows 98, Windows 2000, and Windows XP operating systems. By M.H. Van der Vlerk the system has also been tested in a Novell Network environment, see Section 1.2. The system has been developed by employing CodeGear Delphi 2007, in an object oriented style. Most of our own solvers have been developed in Fortran, the presently used compiler is Intel Visual Fortran 11.1. 1.7 This Guide The user’s Guide is organized as follows: This Part I is devoted to some basic issues. Chapter 2 describes how to install, start up and configure SLP–IOR. The subsequent Chapter 3 contains the description of the (S)LP model types which constitute the scope of the present version. Several notions used in the Guide are introduced here, along with various types of LP’s related to SLP models. Part II serves for documenting the facilities from the functional point of view. Chapter 4 gives guidelines to building a model instance. The subsequent Chapter 5 discusses issues concerning the solution of an (S)LP problem. Chapter 6 is devoted to the analysis of SLP problems. The modeling tools are summarized in Chapter 7. The final Chapter 8 in this part discusses activities related to testing of algorithms. Part III is intended as a Reference Guide. It presents the facilities in a detailed fashion, according to the items in the menu system of SLP–IOR. Separate chapters are devoted to the following additional items: Chapter 14 describes the usage of various editors and viewers. Chapter 15 contains a complete list of the presently available probability distributions. The next Chapter 16 documents the solver library, with detailed information concerning the connection of further solvers to SLP–IOR. Chapters 17 and 18 describe the solvers which are presently connected to SLP–IOR. CHAPTER 1. INTRODUCTION 16 Appendix A provides several checklists for typical activities. The idea with this checklists is twofold: on the one hand, they provide a quick way for finding out, how some of the typical modeling activities can be carried out. On the other hand, in the case if something does not work according to the user’s intention, they can be used to check whether all of the necessary actions have been carried out. Finally Appendix B provides a glossary of notions. 1.8 Acknowledgements The authors gratefully acknowledge the valuable suggestions and the indications of bugs communicated by the following persons, who used SLP–IOR during their study at the Department of Econometrics & OR of the University of Groningen, The Netherlands: Renzo Akkerman, Ilona Altena, Brenda Borst, Laura van den Brink, Gerrit J. Bronsema, Michiel van Dellen, Alex Eigenbrood, Anita Finkers, Wessel Gal, Djoerd de Graaf, Marco Groot Wassink, Jeroen Haffmans, Hans Hagedoorn, Ludwina Hobma, Erik Hülsmann, Arjan Hussem, Gerrit Jan Valk, Ewout Kasemier, Martin van Keulen, Cindy Kommerkamp, Roland van der Laan, Sandra Lukje, Allard van der Made, Tako Molanus, Bert Mulder, Christiaan Müller, Hanskje Nagel, Alice Ogink, Wieger Rekker, Frouwke van Rootselaar, Matthijs Schothans, Jos Sturm, Caren Tempelman, Tim Valkink, Sandra van Vilsteren, Johan Visser, Manon ten Voorde, Esther Vos and Erik van der Weerd. We are especially grateful to Maarten van der Vlerk for his interested and friendly cooperation. We express our thanks to Stefan Muster for his comments and bug reports during his PhD study at our Institute. We are grateful to our former colleagues Martin Densing, Peter Fusek, Raphael Rölli and Simon Siegrist, IOR University of Zurich, for their valuable comments and bug reports. We would like to express our sincere thanks to Alexandra Künzi–Bay, for her many constructive suggestions and thorough testing of the new version during her PhD study at the Institute. The solver CVaRMin has been developed in collaboration with her, see [50]. We would like to express our sincere thanks to people who provided us with their solvers. The following authors have supplied us with their solvers and gave us the permission to distribute them in an executable form as connected to SLP–IOR. Gus Gassmann, MSLiP nested decomposition for multistage recourse problems [15]; CHAPTER 1. INTRODUCTION 17 Jacek Gondzio, HOPDM interior point solver [18]; Csaba Mészáros, BPMPD interior point solver [59]; Andrzej Ruszczyński, QDECOM 1985 regularized decomposition for two stage recourse problems [66]; Naum Z. Shor and Alexey P. Likhovid, SHOR1 solver for simple recourse [68]; Naum Z. Shor and Alexey P. Likhovid, SHOR2 solver for complete recourse [68]; Maarten van der Vlerk, SIRD2SCR solver for simple integer recourse [71]; Maarten van der Vlerk, MScr2Scr solver for multiple simple recourse [72]. Tamás Szántai [69] and István Deák [13] provided us with their subroutines for calculating the multivariate normal distribution function and its gradient. For the algorithms in [69] see also Prékopa [62]. Julie Higle and Suvrajeet Sen gave us substantial help, when we have implemented their stochastic decomposition algorithm [20], [21]. The following authors have made their solvers available for using it with SLP–IOR; for these solvers we do not have the permission for distributing them with SLP–IOR. István Maros, HIPLEX simplex code for LP [52]; Andrzej Ruszczyński and Arthur Świȩtanowski, DECOMP 1995 regularized decomposition solver, [67]. The solver DECOMP is currently not connected to SLP–IOR. Andrzej Ruszczyński and István Deák have developed their codes during their stay at IOR, University of Zurich. Chapter 2 Installation and usage 2.1 Installing/deinstalling SLP–IOR The SLP–IOR distribution consists of a single file zipped with WinZip. the different versions, the filenames are: According to • For the student version I Slp-Ior-Student-32.zip and I Slp-Ior-Student-64.zip, corresponding to 32–bit and 64–bit Windows versions, respectively. • For the full version I Slp-Ior-Release-32.zip and I Slp-Ior-Release-64.zip, corresponding to 32–bit and 64–bit Windows versions, respectively. Before downloading one of the files, please check whether you have 32–bit or 64–bit Windows on your computer. After having downloaded the appropriate file, unzip this file e.g. into a temporary directory. A single executable file will result. For installing SLP–IOR please proceed as follows: 1. Double–click the executable, thus starting up the installation process. During the installation you will be asked for the directory where SLP–IOR should be installed (installation directory). 2. The installation program also creates an icon on your desktop, named SLP–IOR for the full version and SLP–IOR–Student for the student version. 18 CHAPTER 2. INSTALLATION AND USAGE 19 3. The start–up (working directory) for SLP–IOR will be the installation directory by default. If you wish to specify a different working directory before starting up SLP–IOR for the first time, please proceed as follows: • Right–click the shortcut on the desktop. Pressing the right mouse button results in popping up of a menu. • Select [Properties] and in the tabbed sheet which appears choose the tab named [Shortcut]. On the sheet set the StartIn directory according to the desired working directory. • Copy the file Config.slp, to be found in the installation directory, into the working directory. 4. If you have GAMS, then the following step has to be carried out additionally: • The GAMS (or GamsIde) system directory and the GAMS version (full or student/demo version) should also be specified as follows. Start up SLP–IOR and choose [Options] in the main menu. The information concerning GAMS can be specified under the submenu item [GAMS]. Choosing this results in popping up the menu as shown in Figure 2.1. Figure 2.1: Options: specifying version and system directory of GAMS The installation program sets up the following subdirectories of the SLP–IOR main system directory (installation directory): CHAPTER 2. INSTALLATION AND USAGE Solvers TXT Standard GMS Test Blkboard 20 solvers; solver library SLP problem library, model instances in SLP–IOR format problems in SMPS standard format problems in the GAMS language test problem batteries in SLP–IOR format a blackboard for intermediate storage The subdirectory Solvers is a system directory of SLP–IOR and neither the name, nor the content should be modified by the user. The other directories listed in the table above are user directories, holding various types of model instances and arrays. They can freely be modified or even deleted. The user can choose any other directories as user directories. The user directories can be chosen as follows: After starting up SLP–IOR, choose [Options] in the main menu, and subsequently choose [User Directories]. For removing SLP–IOR from your system please use the standard way offered by Windows, namely perform this via [Control Panel] and [Add/Remove Programs]. 2.2 Starting up SLP–IOR Starting up SLP–IOR can be done by double clicking the shortcut on the desktop established during the installation. For SLP–IOR the startup directory is the working directory, e.g. various scratch files will be put into it. The startup directory should be specified/changed on the Windows level as described in Section 2.1. The startup directory must contain a copy of the file Config.slp. This file is the configuration file for SLP–IOR, and it should not be modified manually. Please copy the file Config.slp, to be found in the installation directory, into the working directory. If your working directory does not contain a copy of the file config.slp, then a warning will be issued, and the main menu appears. In this case please exit SLP-IOR, and copy config.slp into the working directory. After starting up SLP–IOR, the main menu appears, and the user communicates with the system via a menu–driven interface. The main menu items appearing at startup are shown in Figure 2.2. These menu items correspond to a deterministic LP model. If the current model instance is stochastic, the main menu changes as can be seen in Figure 2.3 (the last menu item [Help] is not shown in this figure). A short explanation of the main menu items can be found in the table in Figure 2.8, on page 26. CHAPTER 2. INSTALLATION AND USAGE 21 Figure 2.2: Main menu items I: deterministic LP model Figure 2.3: Main menu items II: stochastic model The help system of the present version deviates from the Windows standard. Context– dependent help is provided via <Help> buttons on the various menu sheets and controls. 2.3 Configuring SLP–IOR There are several features of SLP–IOR which can be configured by the user. These features can be found under the main menu item [Options], and are shown in Figure 2.4. Figure 2.4: Main menu: options for the full– and for the student version, respectively • [User Directories] This is for specifying the user directories which hold model instances, according to several formats, as well as building blocks. Paths of the following directories can be specified: – Model instances in SLP–IOR format; – model instances in SMPS standard format; CHAPTER 2. INSTALLATION AND USAGE 22 – test problem batteries; – blackboard for intermediate storage; – LP models in the GAMS modeling language. The form, which appears for the directory path selection, contains a <Browse> button. This works as follows: – When clicking it, the usual Windows file selection form Open appears. – Select any file in the desired directory; this results in picking the corresponding directory path. With one exception, user directories play the following role: these are the default directories offered in the standard I/O dialogs. The sole exception is [Save] under the main menu option [File]. Choosing this results in saving the current model instance into the user directory for model instances in SLP–IOR format; existing files will be overwritten without further warning. • [Usage level] SLP–IOR offers a wide range of modeling activities. For an unsophisticated user who just wishes to solve a single two–stage problem, it makes little sense to display the whole spectrum of modeling facilities. In fact, it may be even disturbing. Therefore, the system can be configured according to the desired mode of usage; the selection menu is displayed in Figure 2.5. Figure 2.5: Main menu: usage mode At the first two usage levels the reduced main menu, shown in Figure 2.6 is displayed. The difference between these two modes is in the details of modeling activities offered in the submenus. In particular, [Edit–Model] offers for sophisticated users additional facilities for model building and reformulation. For the third and fourth usage modes the whole spectrum of modeling activities is offered. The difference is that only the administrator level allows for changing system directories and solver configurations. CHAPTER 2. INSTALLATION AND USAGE 23 Figure 2.6: Main menu items III: stochastic model, straight usage • [Customize] This serves for customizing the interface. The following facilities are available: – [Color Selection] is for selecting the color for the following items: ∗ ∗ ∗ ∗ ∗ ∗ ∗ ∗ [Main Menu Background] for the main menu background. [Matrix Editor Background] is for the matrix editor background. [Matrix Viewer Background] is for the matrix viewer background. [Tree Menu Background] some of the selection menus offer the items for selection in the form of a tree. This feature serves for selecting the background color for those menus. [List Menu Background] some of the selection menus offer the items for selection in the form of a list. This feature serves for selecting the background color for those menus. [Workbench Menu Background] is for the background color of the main workbench menu. [Scenario Tree Nodes] nodes of the scenario tree. [Scenario Tree Edges] edges of the scenario tree. – [Matrix Editor Settings]: The matrix editor serves for editing arrays (vectors and matrices), see Section 14.1. The following features can be configured by the user: ∗ [Number of Rows] (default is 19) means the maximum number of rows of an array shown in the editor window; ∗ [Number of Columns] (default is 6) has the same meaning as the previous item, but for columns; ∗ [Field Length in Pixels] (default is 100) serves for specifying the length of fields for the separate array entries. ∗ [Significant Digits (Precision)] (default is 10) is the number of decimal digits of real numbers shown in the editor fields. – [Scenario Tree Editor] This graphical editor serves for editing various quantities associated to the nodes of a scenario tree; the user can select one of two alternative representations. These differ in the graphical representation of the tree. In the first form the tree is displayed in an intuitively perhaps more comprehensible form, whereas the second form looks like the folder structure in Windows. CHAPTER 2. INSTALLATION AND USAGE 24 – [Delayed Messages] The various activities of SLP–IOR are signalled to the user in a horizontal bar above the status bar at the bottom part of the main menu. The messages are delayed, in order to be readable. This item serves to choose the delay in seconds. Selecting this smaller as 0.1 seconds results in showing no messages at all. • [Regional Setting for Numbers] serves for setting the decimal symbol (default is “.”) and the thousands separator (default is “,”). • [Random Number Generator] is for choosing the uniform pseudo–random number generator, which should be used throughout in SLP–IOR. Notice, that this only has an impact on SLP–IOR itself; some solvers also do simulation, but they have their own random number generators. For the random number generators which can be chosen see Chapter 15. • [Inspect Solvers] serves for inspecting the main features of solvers currently available in the solver library. Clicking this item results in showing up a sheet with solver description. The main characteristics of all solvers, currently in the solver description database (see Section 16.3), can be viewed here. The solver to be viewed, can be selected by clicking the H arrow at the selection box situated at the upper left corner of the sheet. This click results in pulling down a list of solvers; the desired one can be selected by clicking its name. • [Update Solver Features] this serves for updating the solver library, e.g. by choosing different defaults for control parameters. It also serves for connecting new solvers to SLP–IOR; a detailed description is given in Section 16.3. • [GAMS] serves for specifying GAMS–specific features, provided that the user has GAMS installed on her/his computer; see Figure 2.1. The available version (student or full version) and the GAMS system directory should be specified here. • [SLP-IOR System Directory] serves for entering/changing the path of the system directory of SLP–IOR. It is for changing the path in the following emergency situation: during the first startup after installation, SLP–IOR tries to read the SLP– IOR system directory from the Windows Registry. Due to errors in the installation process it could occur, that SLP–IOR fails to fetch the system directory. In this case, the user can enter the system directory path in this menu. WARNING: please do never change the system directory by copying the content of it into another directory! If you want to have SLP–IOR in another directory, then use the Windows [Control Panel] and [Add/Remove Programs] facility to remove SLP–IOR from your system, and subsequently install it into the desired directory as described in Section 2.1. For the directory path specifications see also [User Directories] above. CHAPTER 2. INSTALLATION AND USAGE 2.4 25 Usage of SLP–IOR The menu system of SLP–IOR is organized as a main menu and pull-down submenus, for selecting the various facilities. For the specific modeling issues help buttons are located on (almost all) menu sheets, thus providing context dependent help in this straightforward way. Right–clicking the main menu form, results in popping up a menu as shown in Figure 2.7. Figure 2.7: Main form: popup menu The items are as follows: • Viewing the current modeling status. • Viewing the log book of the current modeling session. The log book is intended to register the user actions in a modeling session. • Viewing notes (if any) associated with the current model instance. • Some shortcuts for viewing solutions. • A shortcut for closing the modeling session. The main menu appears after system startup. Figure 2.8 shows a general description of the main menu items (see also Figure 2.3). A detailed description can be found in Part III. Closing a modeling session (shutting down SLP–IOR) can either be accomplished via the shortcut mentioned above, or via [Files],→[Exit], or simply by closing the main window by clicking at the upper right corner of the form. CHAPTER 2. INSTALLATION AND USAGE 26 → creating a new model instance; file Input/Output of model instances; quitting the session. →Section 9.1 [Edit–Model] → specifying basic model characteristics; specifying dimensions, editing arrays and probability distributions; using building blocks; recasting a model instance by e.g. moving rows/columns across stages. →Section 9.2 [Rand–Vars] → sampling and discretizing the probability distribution; scenario generation. →Section 12.3 [View–Model] → viewing arrays, random variable mapping, etc. →Section 9.2 [Solve ] → selecting and starting up a solver; viewing–, editing–, saving–, loading of results. →Section 10.1 [Analyze] → analyzing the current model instance/ solution; transforming a model instance into another type. →Section 11.1 [Algeb–Equi] → building the algebraic equivalent LP provided it exists; writing this LP in MPS format onto disk. →Section 12.1 [Algeb–Struct] → perturbing/analyzing the various arrays in the SLP model. →Section 12.2 [Workbench] → workbench facilities, including randomly generating test problem batteries (GENSLP), and working with them. →Section 13.1 [Options] → configuring SLP–IOR. →Section 2.3 [File] Figure 2.8: Main menu items 2.5 SLP–IOR and GAMS In this section we summarize the main features of the relationship between SLP–IOR and the algebraic modeling system GAMS. Having GAMS (either the commercial version or the student (demo) version) is by no means obligatory for using SLP–IOR. If the user has GAMS, this provides her/him with the advantage of utilizing also GAMS solvers, in addition to the solvers coming with SLP–IOR, for solving SLP problems. The following GAMS–solvers will be callable from SLP–IOR via GAMS: BDMLP, CONOPT, CPLEX, MINOS5 and OSL. Additional features which become also available: CHAPTER 2. INSTALLATION AND USAGE 27 • Importing an LP–model instance in GAMS–format, for the purpose of developing and testing stochastic versions of it. • Exporting for stochastic model instances the underlying data–set in GAMS–format. For the sake of completeness we also list the additional installation step required for users having GAMS (listed also in Section 2.1 ): The GAMS (or GamsIde) system directory and the available GAMS version (student or full) should be specified as follows. Start up SLP–IOR and choose [Options] in the main menu. The path and directory of GAMS, as well as the available GAMS version can be specified under the submenu item [GAMS], see Figure 2.1. 2.6 The student version of SLP–IOR The student version has the same features and offers the same solvers as the full version, with the following limitations and exceptions. On the one hand, model instance dimensions are limited according to: Number of rows/columns in arrays Number of stages Number of random variables Number of realizations per random variable (in the independent case) ≤ ≤ ≤ ≤ 10 3 5 5 On the other hand, some items concerning options are missing: • Under [Options] (see Figure 2.4) the item [Usage level] is missing. This is automatically set to the highest level (see Figure 2.5). • Under [Options] (see Figure 2.4) the item [Update Solver Features] is also missing. Consequently, no solvers can be added or removed and the solver description (including dimensional limitations) cannot be changed. Concerning GAMS, we would like to draw your attention to the fact that a free student (demo) version, having dimensional limitations, can be downloaded from: http://www.gams.com/download/ Chapter 3 The scope of SLP–IOR: SLP–models 3.1 General considerations This section is devoted to summarize the (S)LP model types currently available in SLP– IOR. In this Guide we just give an overview on SLP problems; for detailed presentations of SLP models consult e.g. Birge and Louveaux [7], Kall [27], Kall and Mayer [40], Kall and Wallace [43], or Prékopa [62]. The SLP model classes in the present scope of SLP–IOR can be seen as the hierarchy of models in Figure 3.1. Let us remark that chance–constrained models are also called models with probabilistic constraints. In the following subsections the basic model classes will be discussed, according to the hierarchy in Figure 3.1. Besides the model formulation, some further modeling issues will also be discussed for the stochastic models. According to the basic philosophy adopted in SLP–IOR, for a stochastic SLP model three basic structural components can be identified, the interplay of which makes up the SLP model. The main point is the following: random variables and stochastic array entries are considered as separate entities. The mapping from random variables to stochastic array entries is established via affine linear relations. The basic components are the following: • the underlying algebraic structure corresponds to a deterministic LP which arises when omitting stochasticity (for instance, by replacing the random array elements by their expected values); • the underlying random variable structure is essentially the probability distribution of the random variables; 28 CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 29 • One stage models – deterministic LP – chance–constraints (SLP) ∗ joint chance–constraint ∗ separate chance–constraints – integrated chance–constraints (SLP) ∗ joint chance–constraint ∗ separate chance–constraints – CVaR constraint (SLP) • Multistage models – deterministic LP – two–stage recourse (SLP) ∗ ∗ ∗ ∗ ∗ fixed recourse complete recourse simple continuous recourse simple integer recourse multiple simple recourse – multistage recourse (SLP) Figure 3.1: The hierarchy of SLP–Models in SLP–IOR • the underlying regression structure establishes the mapping from random variables to array entries as mentioned above. For several SLP model classes, some closely connected deterministic LP models exist, e.g. the expected value problem or the algebraic equivalent LP. Whenever appropriate, these will also be discussed along with the SLP model classes. CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 3.2 30 One stage deterministic LP models min cT x s.t. Ax ∝ b l≤ (3.1) x ≤ u Here A is an m1 × n1 matrix and ∝ stands for =, ≤, or ≥ in the separate rows. The default bounds are l = 0 and u = ∞. Deterministic LP is clearly a special case of SLP. It has a purely algebraic structure which is completely specified by the arrays A, b, c, l and u, along with the information concerning relation types and the information, whether it is a minimization or a maximization problem (the direction of optimization). Besides the various arrays in (3.1), the relations (rows) and variables (columns) are also identified by names. For deterministic LP models, both the underlying random variable and regression structures are clearly missing. As (3.1) is a special case of multistage models, the arrays A, b, c, l, u x are referred to in the various editors as A[1, 1], b[1], c[1], l[1], u[1], x[1], respectively. 3.3 SLP models with a joint chance constraint These models are also called models with joint probabilistic constraints. In this User’s Guide we use the terminology indicated in the title of the section; this is also the default terminology of SLP–IOR1 . min P s.t. l≤ 1 cT x ξ ( T (ξ)x ≥ h(ξ) ) ≥ α Ax ∝b x ≤u (3.2) In the case, when e.g. for educational reasons, the terminology might be significant, we ship SLP–IOR on request also with the alternative terminology (the User’s Guide is available only in its present form, though). CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS R 31 R where A is an (m1 × n1 ) matrix, b ∈ m1 , c, l, u ∈ n1 , and ξ is an r–dimensional random vector ξ : Ω → r on a probability space (Ω, F , P ). The random entries are modeled via the mappings T (·) : r → m2 ×n1 and h(·) : r → m2 . α, with 0 ≤ α ≤ 1, is a given probability level; ∝ stands for =, ≤, or ≥ in the separate rows. The default bounds are l = 0 and u = ∞. R R R R R We assume that the mappings above are specified as the following linear–affine relations: T (ξ) = T + r X T j ξj j=1 h(ξ) = h + r X (3.3) j h ξj j=1 where T , T j , j = 1, . . . , r are m2 × n1 matrices; h ∈ R m2 , hj ∈ R m2 , j = 1, . . . , r. Problem (3.2) is in general a nonconvex optimization problem. In the special case T (ξ) = T , i.e., T j = 0 ∀j, the problem becomes a convex programming problem for a wide range of probability distributions, see [62]. Notice also that in the stochastic part only inequalities are allowed. The arrays A, b, c, l, u, x, T , h are referred to in the various editors as A[1, 1], b[1], c[1], l[1], u[1], x[1], A[2, 1], b[2], respectively. 3.3.1 The underlying algebraic structure The underlying algebraic structure for jointly chance–constrained models is specified by the following quantities: Arrays A, T , b, c, l, u, h, the type of relations, the direction of optimization, and the names of relations and variables. The underlying algebraic structure corresponds to the underlying LP problem, see Section 3.3.4. 3.3.2 The underlying random variables structure This structure is defined by the dependency structure and the probability distribution of the random variables, in the following way: The random variables ξi are subdivided into groups. These groups are assumed to be mutually stochastically independent. This implies, that for specifying the joint probability distribution of the random vector ξ, it suffices to specify the probability distributions for the random vectors corresponding to the groups. Probability distributions are specified by their parameters, e.g. an empirical distribution is given by its realization tableau and a normal distribution through CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 32 specifying the vector of means, variances and the correlation matrix. A complete list of distributions, available with the present version of SLP-IOR, can be found in Chapter 15. 3.3.3 The underlying regression structure This structure is specified by hj , T j j > 0 (see (3.3)). Notice, that the constant terms h and T do not belong to this structure, they are part of the underlying algebraic structure. 3.3.4 Underlying LP model This is the following deterministic LP model: cT x min Ax ∝ b s.t. (3.4) Tx ≥h l≤ x ≤u Please notice, that the underlying LP problem means, that we build an LP model on the basis of the underlying algebraic structure, as defined in Section 3.3.1. The underlying algebraic structure and the underlying LP model are in a one–to–one correspondence. 3.3.5 Expected value problem This deterministic LP problem arises when we substitute in (3.2) all random variables by their expected value. Let us introduce the denotations: ξ¯ = [ξ] ∀i, T̄ = ξ [T (ξ)] and ¯ and h̄ = h(ξ) ¯ and the expected h̄ = ξ [h(ξ)]. Substituting ξ¯ for ξ in (3.3) gives T̄ = T (ξ) value problem can be written as: E E E cT x min Ax ∝ b s.t. T̄ x ≥ h̄ l≤ x ≤u (3.5) CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 3.3.6 33 Current solver availability Solvers are only available for the following case: • T (ξ) ≡ T , i.e., only the RHS is stochastic and • h(ξ) has a multivariate nondegenerate normal distribution. If the random vector ξ has a nondegenerate multivariate normal distribution, this does not imply automatically, that the second property above holds. The distribution of h(ξ) is determined through the distribution of ξ and the affine relations (3.3). A normally distributed ξ results in a normally distributed h(ξ), but the distribution of h(ξ) may be degenerate. This is surely the case if r < m2 holds. For available solvers and their developers see Chapter 17 and Chapter 18. 3.4 SLP models with separate chance constraints These models are also called models with separate probabilistic constraints. In this User’s Guide we use the terminology indicated in the title of the section; this is also the default terminology of SLP–IOR2 . min P s.t. cT x ξ ( tT i (ξ)x ≥ hi (ξ) ) ≥ αi , i = 1, . . . , S Ax ∝b x ≤u l≤ R R R (3.6) where A is an (m1 × n1 ) matrix, b ∈ m1 , c, l, u ∈ n1 , and ξ is an r–dimensional random vector ξ : Ω → r on a probability space (Ω, F , P ). The random entries are modeled via the mappings T (·) : r → m2 ×n1 and h(·) : r → m2 ; ti (·) is the i–th row of T (·) and hi (·) is the i–th component of h(·), i = 1, . . . , m2 . αi , with 0 ≤ αi ≤ 1, are a given probability levels. ∝ stands for =, ≤, or ≥ in the separate rows. The default bounds are l = 0 and u = ∞. R R R R T The random vectors (tT i (ξ), hi (ξ)) , i = 1, . . . , m2 , are usually assumed to be stochastically independent. Otherwise only the marginal distributions corresponding to the rows enter the model. 2 In the case, when e.g. for educational reasons, the terminology might be significant, we ship SLP–IOR on request also with the alternative terminology (the User’s Guide is available only in its present form, though). CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 34 As in the jointly chance–constrained case random entries are modeled by affine sums as follows: r X ti (ξ) = ti + tji ξj ∀i j=1 hi (ξ) = hi + r X (3.7) hji ξj ∀i j=1 where ti ∈ R , n1 tji ∈ R , j = 1, . . . , r, ∀i; hi ∈ R, hji ∈ R, j = 1, . . . , r, ∀i. n1 The arrays A, b, c, l, u, x, T , h are referred to in the various editors as A[1, 1], b[1], c[1], l[1], u[1], x[1], A[2, 1], b[2], respectively. 3.4.1 The underlying algebraic structure The underlying algebraic structure for separately chance–constrained models is specified by the following quantities: Arrays A, ti , hi ∀i, b, c, l, u, the type of relations, the direction of optimization, and the names of relations and variables. The underlying algebraic structure corresponds to the underlying LP problem, see Section 3.4.4. 3.4.2 The underlying random variables structure This is identical with that for joint chance constraints, see Section 3.3.2. 3.4.3 The underlying regression structure This is analogous to the jointly chance–constrained case, see Section 3.3.3. It is specified by hji , tji j > 0 ∀i; notice that the constant terms hi and ti belong to the underlying algebraic structure ∀i. 3.4.4 Underlying LP model This is the following deterministic LP model: cT x min Ax ∝ b s.t. (ti )T x ≥ hi ∀i l≤ x ≤u (3.8) CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 35 Please notice, that the underlying LP problem means that we build an LP model on the basis of the underlying algebraic structure defined in Section 3.4.1. The underlying algebraic structure and underlying LP model are in a one–to–one correspondence. 3.4.5 Expected value problem This deterministic LP problem arises, when we substitute in (3.6) all random variables by their expected value. Using the same denotations as for joint chance constraints in Section 3.3.5, we can formulate the expected value problem as the following deterministic LP: cT x min Ax ∝ b s.t. (t̄i )T x ≥ h̄i ∀i l≤ 3.4.6 (3.9) x ≤u Equivalent LP In the special case when in (3.6) ti (ξ) ≡ ti holds, i.e. only the RHS is stochastic, an equivalent LP formulation exists. Let us denote by Q(αi ) the minimal α−quantile of the probability distribution of hi (ξ) corresponding to αi . The equivalent LP is the following: cT x min Ax ∝ b s.t. tT i x ≥ Q(αi ) ∀i l≤ 3.4.7 (3.10) x ≤u Current solver availability Solvers are available for the following case: • ti (ξ) ≡ ti ∀i, i.e., only the RHS is stochastic and • h1 (ξ), . . . , hm2 (ξ) are stochastically independent. There are no restrictions concerning the marginal distribution of hi (ξ), i = 1, . . . , m2 . CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 36 The solution approach is solving the equivalent LP (for the latter see Section 3.4.6). For available solvers and their developers see also Chapter 17 and Chapter 18; for the available univariate distributions see Chapter 15. 3.5 SLP models with a joint integrated chance constraint Two kinds of models of this type are available in SLP–IOR. In the first one, we have a joint integrated chance constraint: cT x min + Eξ [ 1≤i≤m max ( hi (ξ) − tT i (ξ)x ) ] s.t. ≤γ (3.11) 2 Ax ∝b x ≤u l≤ R R where A is an (m1 × n1 ) matrix, b ∈ m1 , c, l, u ∈ n1 , and ξ is an r–dimensional random vector ξ : Ω → r on a probability space (Ω, F , P ). ∝ stands for =, ≤, or ≥ in the separate rows. The default bounds are l = 0 and u = ∞. R The components of ti (ξ) are the elements of the i’th row of the (m2 × n1 )–dimensional random matrix T (ξ), i = 1, . . . , m2 . We consider the random inequalities tT i (ξ)x ≥ hi (ξ), i = 1, . . . , m2 . (3.12) Let ζi (x, ξ) =: hi (ξ) − tT i (ξ)x, i = 1, . . . , m2 . If the inequalities in (3.12) hold, this is interpreted as a favorable event. Therefore, nonnegative values of the random variables ζi (x, ξ) represent losses. Employing the notation z + := max{0, z} for the positive part of a real number z, losses can be represented as + ζi+ (x, ξ) = ( hi (ξ) − tT i (ξ)x ) . The integrated chance constraint restricts the expected maximum loss where γ is a prescribed maximally tolerable expected maximum loss level. R R R The random entries are modeled via the mappings T (·) : r → m2 ×n1 and h(·) : r → m2 . We assume that these mappings are specified as the following linear–affine relations: R T (ξ) = T + r X T j ξj j=1 h(ξ) = h + r X j=1 hj ξj (3.13) CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS where T , T j , j = 1, . . . , r are m2 × n1 matrices; h ∈ R m2 , hj ∈ 37 R m2 , j = 1, . . . , r. Problem (3.11) is a convex optimization problem for any distribution for which the expected value exists, see Klein Haneveld [46]. The arrays A, b, c, l, u x will be referred to in the various editors as A[1, 1], b[1], c[1], l[1], u[1], x[1], respectively. Concerning the integrated chance constraint and the constant terms in (3.13): T and h will be referred to as A[2, 1] and b[2], respectively. We will call the function Eξ [ 1≤i≤m max 2 ζi+ (x, ξ) ] an integrated joint probability function. In the second model this function is in the objective: + min λ1 cT x + λ2 Eξ [ max ( hi (ξ) − tT i (ξ)x ) ] 1≤i≤m2 s.t. l≤ Ax ∝b x ≤u (3.14) with λ1 and λ2 being interpreted as prescribed “risk aversion parameters”. Problem (3.14) is a convex optimization problem for any distribution for which the expected value exists. 3.5.1 Modeling losses We consider the random inequalities tT i (ξ)x ∝ hi (ξ), i = 1, . . . , m2 , (3.15) where ∝ is either ≤ or ≥; i.e., it must be an inequality. Let the loss function be defined as T ti (ξ)x − hi (ξ) if ∝ represents ≤, ζi (x, ξ) = (3.16) hi (ξ) − tT i (ξ)x if ∝ represents ≥ . If the inequalities in (3.15) hold, this is interpreted as a favorable event. Therefore, nonnegative values of the random variables ζi (x, ξ) represent losses. Notice that the formulations in (3.11) and (3.14) correspond to the choice “∝”=“≥”. For the case “∝”=“≤” analogous model formulations apply, with the signs reversed in ti (ξ) and hi (ξ). SLP–IOR offers choosing the inequality in (3.15). CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 3.5.2 38 The underlying algebraic structure The underlying algebraic structure for models with joint integrated chance constraints is specified by the following quantities: Arrays A, T , b, c, l, u, h, the type of relations, the direction of optimization, and the names of relations and variables. The underlying algebraic structure corresponds to the underlying LP problem, see Section 3.5.5. 3.5.3 The underlying random variables structure This structure is defined by the dependency structure and the probability distribution of the random variables, in the following way: The random variables ξi are subdivided into groups. These groups are assumed to be mutually stochastically independent. This implies, that for specifying the joint probability distribution of the random vector ξ, it suffices to specify the probability distributions for the random vectors corresponding to the groups. Probability distributions are specified by their parameters, e.g. an empirical distribution is given by its realization tableau and a normal distribution through specifying the vector of means, variances and the correlation matrix. A complete list of distributions, available with the present version of SLP-IOR, can be found in Chapter 15. 3.5.4 The underlying regression structure This structure is specified by hj , T j j > 0 (see (3.13)). Notice, that the constant terms h and T do not belong to this structure, they are part of the underlying algebraic structure. 3.5.5 Underlying LP model This is the following deterministic LP model: cT x min Ax ∝ b s.t. Tx ≥h l≤ (3.17) x ≤u Notice, that the underlying LP problem means, that we build an LP model on the basis of the underlying algebraic structure, as defined in Section 3.5.2. The underlying algebraic CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 39 structure and the underlying LP model are in a one–to–one correspondence. 3.5.6 Expected value problem This deterministic LP problem arises when we substitute in (3.11) all random variables by their expected value. Introduce the notations: ξ¯ = [ξ] ∀i, T̄ = ξ [T (ξ)] and ¯ and h̄ = h(ξ) ¯ and the h̄ = ξ [h(ξ)] and substituting ξ¯ for ξ in (3.13) gives T̄ = T (ξ) expected value problem can be written as: E E cT x min Ax ∝ b s.t. (3.18) T̄ x ≥ h̄ l≤ 3.5.7 E x ≤u Equivalent LP We consider the case, when ξ has a finite discrete distribution, i.e. the probability distribution is specified by the realization tableau: ! p1 p2 . . . pN ξb1 , ξb2 . . . ξbN with ξbk ∈ R,p r k > 0, k = 1, . . . , N ; N X pk = 1. k=1 According to (3.13), we get for k = 1, . . . , N the realizations b hk = h + r X hj ξbjk j=1 bk T = T + r X (3.19) T j ξbjk j=1 and the realizations tableau for the random p1 p2 1 b2 b h , h Tb 1 , Tb 2 arrays is the following: . . . pN ... b hN N b ... T . CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 40 For a joint integrated chance constraint we have the equivalent LP cT x min N X s.t. pk z k ≤ γ k=1 b tki x −yik ≥b hki , k = 1, . . . , N, i = 1, . . . , m2 −yik +z k ≥ 0, k = 1, . . . , N, i = 1, . . . , m2 yik ≥ 0, k = 1, . . . , N, i = 1, . . . , m2 (3.20) z k ≥ 0, k = 1, . . . , N l≤ Ax ∝b x ≤u and for the joint integrated probability function in the objective we have min λ1 cT x + λ2 s.t. b tki x N X pk z k k=1 −yik ≥b hki , k = 1, . . . , N, i = 1, . . . , m2 −yik +z k ≥ 0, k = 1, . . . , N, i = 1, . . . , m2 yik ≥ 0, k = 1, . . . , N, i = 1, . . . , m2 (3.21) z k ≥ 0, k = 1, . . . , N Ax l≤ x ∝b ≤ u. For the validity of these equivalent LP’s see Klein Haneveld [46], Klein Haneveld and Van der Vlerk [48], or Kall and Mayer [40]. 3.5.8 Current solver availability Solvers are only available for the case when ξ has a finite discrete distribution. For available solvers and their developers see Chapter 17 and Chapter 18. CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 3.6 41 SLP models with separate integrated chance constraints Two kinds of models of this type are available in SLP–IOR. In the first one, we have separate integrated chance constraints: cT x min Eξ [ ( hi(ξ) − tTi (ξ)x )+ ] s.t. ≤ γi , i = 1, . . . , m2 Ax ∝b x ≤u l≤ R (3.22) R where A is an (m1 × n1 ) matrix, b ∈ m1 , c, l, u ∈ n1 , and ξ is an r–dimensional random vector ξ : Ω → r on a probability space (Ω, F , P ). ∝ stands for =, ≤, or ≥ in the separate rows. The default bounds are l = 0 and u = ∞. R The components of ti (ξ) are the elements of the i’th row of the (m2 × n1 )–dimensional random matrix T (ξ), i = 1, . . . , m2 . We consider the random inequalities tT i (ξ)x ≥ hi (ξ), i = 1, . . . , m2 . (3.23) Let ζi (x, ξ) =: hi (ξ) − tT i (ξ)x, i = 1, . . . , m2 . If the inequalities in (3.23) hold, this is interpreted as a favorable event. Therefore, nonnegative values of the random variables ζi (x, ξ) represent losses. Employing the notation z + := max{0, z} for the positive part of a real number z, losses can be represented as + ζi+ (x, ξ) = ( hi (ξ) − tT i (ξ)x ) . The separate chance constraints restrict the expected loss row–wise, where γi is a prescribed maximally tolerable expected loss level for the i’th constraint. T The random vectors (tT i (ξ), hi (ξ)) , i = 1, . . . , m2 , are usually assumed to be stochastically independent. Otherwise only the marginal distributions corresponding to the rows enter the model. R R R The random entries are modeled via the mappings T (·) : r → m2 ×n1 and h(·) : r → m2 . We assume that these mappings are specified as the following linear–affine relations: R T (ξ) = T + r X T j ξj j=1 h(ξ) = h + r X j=1 hj ξj (3.24) CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS where T , T j , j = 1, . . . , r are m2 × n1 matrices; h ∈ R m2 , hj ∈ 42 R m2 , j = 1, . . . , r. Problem (3.22) is a convex optimization problem for any distribution for which the expected values exist, see Klein Haneveld [46]. The arrays A, b, c, l, u x will be referred to in the various editors as A[1, 1], b[1], c[1], l[1], u[1], x[1], respectively. Concerning the integrated chance constraint and the constant terms in (3.24): T and h will be referred to as A[2, 1] and b[2], respectively. We will call the functions Eξ [ ζi+ (x, ξ) ] separate integrated probability functions. In the second model model we assume that m2 = 1 holds, that is, this model is only defined in the case when T has a single row. In this model the separate integrated probability function is in the objective: + min λ1 cT x + λ2 Eξ [ ( h1 (ξ) − tT 1 (ξ)x ) ] s.t. Ax ∝b x ≤u l≤ (3.25) with λ1 and λ2 being interpreted as prescribed “risk aversion parameters”. Problem (3.25) is a convex optimization problem for any distribution for which the expected value exists. 3.6.1 Modeling losses We consider the random inequalities tT i (ξ)x ∝ hi (ξ), i = 1, . . . , m2 , (3.26) where ∝ is either ≤ or ≥; i.e., it must be an inequality. Let the loss function be defined as T ti (ξ)x − hi (ξ) if ∝ represents ≤, ζi (x, ξ) = (3.27) hi (ξ) − tT i (ξ)x if ∝ represents ≥ . If the inequalities in (3.26) hold, this is interpreted as a favorable event. Therefore, nonnegative values of the random variables ζi (x, ξ) represent losses. Notice that the formulations in (3.22) and (3.22) correspond to the choice “∝”=“≥”. For the case “∝”=“≤” analogous model formulations apply, with the signs reversed in ti (ξ) and hi (ξ). SLP–IOR offers choosing the inequality in (3.26). CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 3.6.2 43 The underlying algebraic structure The underlying algebraic structure for models with separate integrated chance constraints is specified by the following quantities: Arrays A, T , b, c, l, u, h, the type of relations, the direction of optimization, and the names of relations and variables. The underlying algebraic structure corresponds to the underlying LP problem, see Section 3.6.5. 3.6.3 The underlying random variables structure This structure is defined by the dependency structure and the probability distribution of the random variables, in the following way: The random variables ξi are subdivided into groups. These groups are assumed to be mutually stochastically independent. This implies, that for specifying the joint probability distribution of the random vector ξ, it suffices to specify the probability distributions for the random vectors corresponding to the groups. Probability distributions are specified by their parameters, e.g. an empirical distribution is given by its realization tableau and a normal distribution through specifying the vector of means, variances and the correlation matrix. A complete list of distributions, available with the present version of SLP-IOR, can be found in Chapter 15. 3.6.4 The underlying regression structure This structure is specified by hj , T j j > 0 (see (3.24)). Notice, that the constant terms h and T do not belong to this structure, they are part of the underlying algebraic structure. 3.6.5 Underlying LP model This is the following deterministic LP model: cT x min Ax ∝ b s.t. Tx ≥h l≤ (3.28) x ≤u Notice, that the underlying LP problem means, that we build an LP model on the basis of the underlying algebraic structure, as defined in Section 3.6.2. The underlying algebraic CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 44 structure and the underlying LP model are in a one–to–one correspondence. 3.6.6 Expected value problem This deterministic LP problem arises when we substitute in (3.22) all random variables by their expected value. Introduce the notations: ξ¯ = [ξ] ∀i, T̄ = ξ [T (ξ)] and ¯ and h̄ = h(ξ) ¯ and the h̄ = ξ [h(ξ)] and substituting ξ¯ for ξ in (3.24) gives T̄ = T (ξ) expected value problem can be written as: E E cT x min Ax ∝ b s.t. (3.29) T̄ x ≥ h̄ l≤ 3.6.7 E x ≤u Equivalent LP We consider the case, when ξ has a finite discrete distribution, i.e. the probability distribution is specified by the realization tableau: ! p1 p2 . . . pN ξb1 , ξb2 . . . ξbN with ξbk ∈ R,p r k > 0, k = 1, . . . , N ; N X pk = 1. k=1 According to (3.24), we get for k = 1, . . . , N the realizations b hk = h + r X hj ξbjk j=1 bk T = T + r X (3.30) T j ξbjk j=1 and the realizations tableau for the random p1 p2 1 b2 b h , h Tb 1 , Tb 2 arrays is the following: . . . pN ... b hN N b ... T . CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 45 For separate integrated chance constraints we have the equivalent LP cT x min N X s.t. pk yik ≤ γi , i = 1, . . . , m2 k=1 b tki x −yik ≥ b hki , k = 1, . . . , N, i = 1, . . . , m2 (3.31) yik ≥ 0, k = 1, . . . , N, i = 1, . . . , m2 Ax ∝b x ≤u l≤ and for the separate integrated probability function in the objective we have min λ1 cT x + λ2 s.t. b tk1 x N X pk y k k=1 −y k yk Ax l≤ x ≥b hk1 , k = 1, . . . , N (3.32) ≥ 0, k = 1, . . . , N ∝b ≤ u. For the validity of these equivalent LP’s see Klein Haneveld [46], Klein Haneveld and Van der Vlerk [48], or Kall and Mayer [40]. 3.6.8 Current solver availability Solvers are only available for the case when ξ has a finite discrete distribution. For available solvers and their developers see Chapter 17 and Chapter 18. CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 3.7 46 SLP models with CVaR functions Two kinds of models of this type are available in SLP–IOR. In the first one, we have CVaR constraints: cT x min s.t. zi + 1 1−αi E[( hi(ξ) − tTi (ξ)x − zi )+] ≤ γi , i = 1, . . . , m2 Ax ∝b x ≤u l≤ R (3.33) R where A is an (m1 × n1 ) matrix, b ∈ m1 , c, l, u ∈ n1 , and ξ is an r–dimensional random vector ξ : Ω → r on a probability space (Ω, F , P ). ∝ stands for =, ≤, or ≥ in the separate rows. The default bounds are l = 0 and u = ∞. R The components of ti (ξ) are the elements of the i’th row of the (m2 × n1 )–dimensional random matrix T (ξ), i = 1, . . . , m2 . We consider the random inequalities tT i (ξ)x ≥ hi (ξ), i = 1, . . . , m2 . (3.34) Let ζi (x, ξ) =: hi (ξ) − tT i (ξ)x, i = 1, . . . , m2 . If the inequalities in (3.34) hold, this is interpreted as a favorable event. Therefore, nonnegative values of the random variables ζi (x, ξ) represent losses. For a detailed discussion of CVaR (Conditional Value–at–Risk) and for the interpretation of the CVaR constraints see Rockafellar and Uryasev [64], Palmquist, Uryasev, and Krokhmal [61], or Kall and Mayer [40]. αi , i = 1, . . . , m2 are high probability levels (0.99, for instance). The CVaR constraints restrict CVaR row–wise, where γi is a prescribed maximally tolerable CVaR level for the i’th constraint. T The random vectors (tT i (ξ), hi (ξ)) , i = 1, . . . , m2 , are usually assumed to be stochastically independent. Otherwise only the marginal distributions corresponding to the rows enter the model. R R R The random entries are modeled via the mappings T (·) : r → m2 ×n1 and h(·) : r → m2 . We assume that these mappings are specified as the following linear–affine relations: R T (ξ) = T + r X T j ξj j=1 h(ξ) = h + r X j=1 hj ξj (3.35) CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS where T , T j , j = 1, . . . , r are m2 × n1 matrices; h ∈ R m2 , hj ∈ 47 R m2 , j = 1, . . . , r. Problem (3.33) is a convex optimization problem for any distribution for which the expected values exist. The arrays A, b, c, l, u x will be referred to in the various editors as A[1, 1], b[1], c[1], l[1], u[1], x[1], respectively. Concerning the CVaR constraint and the constant terms in (3.35): T and h will be referred to as A[2, 1] and b[2], respectively. In the second model model we assume that m2 = 1 holds, that is, this model is only defined in the case when T has a single row. In this model the CVaR function is in the objective: min λ1 cT x + λ2 s.t. l≤ z+ 1 1−α1 Ax ∝b x ≤u E[( h1(ξ) − tT1(ξ)x − z )+] (3.36) with λ1 and λ2 being interpreted as prescribed “risk aversion parameters”. Problem (3.36) is a convex optimization problem for any distribution for which the expected value exists. 3.7.1 Modeling losses We consider the random inequalities tT i (ξ)x ∝ hi (ξ), i = 1, . . . , m2 , (3.37) where ∝ is either ≤ or ≥; i.e., it must be an inequality. Let the loss function be defined as T ti (ξ)x − hi (ξ) if ∝ represents ≤, ζi (x, ξ) = (3.38) hi (ξ) − tT i (ξ)x if ∝ represents ≥ . If the inequalities in (3.37) hold, this is interpreted as a favorable event. Therefore, nonnegative values of the random variables ζi (x, ξ) represent losses. Notice that the formulations in (3.33) and (3.36) correspond to the choice “∝”=“≥”. For the case “∝”=“≤” analogous model formulations apply, with the signs reversed in ti (ξ) and hi (ξ). SLP–IOR offers choosing the inequality in (3.37). CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 3.7.2 48 The underlying algebraic structure The underlying algebraic structure for models with CVaR constraints or objective is specified by the following quantities: Arrays A, T , b, c, l, u, h, the type of relations, the direction of optimization, and the names of relations and variables. The underlying algebraic structure corresponds to the underlying LP problem, see Section 3.7.5. 3.7.3 The underlying random variables structure This structure is defined by the dependency structure and the probability distribution of the random variables, in the following way: The random variables ξi are subdivided into groups. These groups are assumed to be mutually stochastically independent. This implies, that for specifying the joint probability distribution of the random vector ξ, it suffices to specify the probability distributions for the random vectors corresponding to the groups. Probability distributions are specified by their parameters, e.g. an empirical distribution is given by its realization tableau and a normal distribution through specifying the vector of means, variances and the correlation matrix. A complete list of distributions, available with the present version of SLP-IOR, can be found in Chapter 15. 3.7.4 The underlying regression structure This structure is specified by hj , T j j > 0 (see (3.24)). Notice, that the constant terms h and T do not belong to this structure, they are part of the underlying algebraic structure. 3.7.5 Underlying LP model This is the following deterministic LP model: cT x min Ax ∝ b s.t. Tx ≥h l≤ (3.39) x ≤u Notice, that the underlying LP problem means, that we build an LP model on the basis of the underlying algebraic structure, as defined in Section 3.7.2. The underlying algebraic CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 49 structure and the underlying LP model are in a one–to–one correspondence. 3.7.6 Expected value problem This deterministic LP problem arises when we substitute in (3.33) all random variables by their expected value. Introduce the notations: ξ¯ = [ξ] ∀i, T̄ = ξ [T (ξ)] and ¯ and h̄ = h(ξ) ¯ and the h̄ = ξ [h(ξ)] and substituting ξ¯ for ξ in (3.35) gives T̄ = T (ξ) expected value problem can be written as: E E cT x min Ax ∝ b s.t. (3.40) T̄ x ≥ h̄ l≤ 3.7.7 E x ≤u Equivalent LP We consider the case, when ξ has a finite discrete distribution, i.e. the probability distribution is specified by the realization tableau: ! p1 p2 . . . pN ξb1 , ξb2 . . . ξbN with ξbk ∈ R,p r k > 0, i = 1, . . . , N ; N X pk = 1. k=1 According to (3.35), we get for k = 1, . . . , N the realizations b hk = h + r X hj ξbjk j=1 bk T = T + r X (3.41) T j ξbjk j=1 and the realizations tableau for the random p1 p2 1 b2 b h , h Tb 1 , Tb 2 arrays is the following: . . . pN ... b hN N b ... T CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 50 For CVaR constraints we have the equivalent LP cT x min (x,z) s.t. zi + 1 1−αi N X pk yik ≤ γi , i = 1, . . . , m2 k=1 b tki x −yik ≥ b hki , k = 1, . . . , N, i = 1, . . . , m2 +zi (3.42) yik ≥ 0, k = 1, . . . , N, i = 1, . . . , m2 Ax ∝b x ≤u l≤ and for CVaR in the objective we have λ1 cT x + λ2 min (x,z) z+ 1 1−α N X ! pk y k k=1 b tk1 x s.t. +z −y k ≥ b hk1 , k = 1, . . . , N (3.43) y k ≥ 0, k = 1, . . . , N l≤ Ax ∝b x ≤u For the validity of these equivalent LP’s see Rockafellar and Uryasev [64], Palmquist, Uryasev, and Krokhmal [61], or Kall and Mayer [40]. 3.7.8 Current solver availability Solvers are only available for the case when ξ has a finite discrete distribution. For available solvers and their developers see Chapter 17 and Chapter 18. CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 3.8 51 Multistage deterministic LP models min c1 x 1 + T X ct x t t=2 s.t. ∝ b1 A11 x1 At1 x1 + t X (3.44) Atτ xτ ∝ bt , t = 2, . . . T τ =2 lt ≤ ≤ ut , t = 1, . . . T xt where Atτ is an (mt × nτ ) matrix, ∀t, ∀τ , τ ≤ t. ∝ stands for =, ≤, or ≥ in the separate rows. The default bounds are lt = 0 and ut = ∞, ∀t. Deterministic LP is clearly a special case of SLP. It has a purely algebraic structure; both the underlying random variable and regression structures are clearly missing. The arrays Atτ , bt , ct , lt , ut xt will be referred to in the various editors as A[t, τ ], b[t], c[t], l[t], u[t], x[t], respectively, ∀t, ∀τ , τ ≤ t. 3.9 Two–stage recourse models min [ cT x + E ξ [ Q(x, ξ) ] ] Ax ∝ b s.t. (3.45) l ≤ x ≤ u, where Q(x, ξ) = min q T (ξ)y s.t. W (ξ)y ∝ h(ξ) − T (ξ)x (3.46) y ≥ 0, R R R R where A is an (m1 × n1 ) matrix, b ∈ m1 , c, l, u ∈ n1 , and ξ is an r–dimensional random vector ξ : Ω → r on a probability space (Ω, F , P ). The random entries are modeled via the mappings T (·) : r → m2 ×n1 , h(·) : r → m2 , W (·) : r → m2 ×n2 , and R R R R R CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS R 52 R q(·) : r → n2 . ∝ stands for =, ≤, or ≥ in the separate rows. The default bounds are l = 0 and u = ∞. Problem (3.45) is called a two–stage recourse problem and (3.46) is called the second– stage– or recourse problem. Matrix W is called the recourse matrix. P f ) < 1 ∀W f ∈ • If W (ξ) is random, i.e., when ξ (W (ξ) = W called a random recourse problem. f∈ • If W (ξ) is not stochastic, i.e., when ∃W a fixed recourse problem. R m2 ×n2 R m2 ×n2 , then (3.45) is f a.s., then (3.45) is : W (ξ) = W • Let us consider fixed recourse problems. Assume that ∝ stands in the second stage (3.46) for equality, i.e. that (3.46) has been reformulated as an equality constrained problem by introducing slack variables, if necessary. If for the recourse matrix W {z | z = W y, y ≥ 0} = IRm2 (and {u | W T u ≤ q(ξ)} = 6 ∅ w.p. 1) is fulfilled, then (3.45) is called a complete recourse problem. • A special case of complete recourse is simple recourse; in this case we have W = (I, −I) with I being the identity matrix and q T (ξ) ≡ q T = [(q + )T , (q − )T ]T with q + + q − ≥ 0. • SLP–IOR also deals with simple integer recourse models. In these models y is restricted to integers vectors and the model formulation has to be modified involving inequalities in the second stage, see Section 3.10. ξ is a random vector on a probability space (Ω, F, P ), and we model the way as randomness enters the model by specifying affine sums as follows: Pr j q(ξ) = q + j=1 q ξj Pr j h(ξ) = h + j=1 h ξj (3.47) Pr j T (ξ) = T + T ξ j j=1 Pr j W (ξ) = W + j=1 W ξj R R R R where q ∈ n2 , q j ∈ n2 , j = 1, . . . , r; h ∈ m2 , hj ∈ m2 , j = 1, . . . , r; T , T j , j = 1, . . . , r are m2 × n1 matrices; W , W j , j = 1, . . . , r are m2 × n2 matrices. In SLP–IOR fixed recourse is modeled by setting W j = 0 ∀j in (3.47). We will alternatively call the affine sums in (3.47) regression sums. As the main structural constituents of a two–stage recourse model we consider the following: CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 53 → The underlying algebraic structure: When considering only the constant terms in the affine sums given above, a deterministic LP results. This LP defines the underlying algebraic structure. → The underlying random variables structure: This is determined by the dependencystructure and probability distribution of the random vector ξ(ω). → The underlying regression structure: The affine sums (3.47), establishing the connection of the random variable– and algebraic structures, are considered as the regression structure. This structure is a vehicle for selecting stochastic parts ( which of T (ξ), h(ξ), q(ξ), W (ξ) are random ), for pinpointing random entries in the various arrays, and for modeling linear relationships between random variables. The above outlined three basic constituents (structures) are handled separately by SLP– IOR; they serve as building blocks for two–stage models. The arrays A, b, c, l, u, x, T , h are referred to in the various editors as A[1, 1], b[1], c[1], l[1], u[1], x[1], A[2, 1], b[2], respectively, to allow for an extension of notation to multistage recourse models. 3.9.1 The underlying algebraic structure As discussed above, the algebraic structure is the structure of a deterministic LP problem, which results when neglecting stochasticity, i.e. when in the affine sums (3.47) we simply omit the stochastic terms. In addition, names for relations and variables can be specified. 3.9.2 The underlying random variable structure This structure is defined by the dependency structure and the probability distribution of the random variables in the following way: The random variables ξi (ω) are subdivided into groups. These groups are assumed to be mutually stochastically independent. This implies, that for specifying the joint probability distribution of the random vector ξ it suffices to specify the probability distributions for the random vectors corresponding to the groups. Probability distributions are specified by their parameters, e.g. an empirical distribution is given by its realization tableau and a normal distribution through specifying the vector of means, variances, and the correlation matrix. A complete list of distributions available with the present version of SLP-IOR can be found in Chapter 15. CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 3.9.3 54 The underlying regression structure This structure is given by the affine sums (3.47), and is completely specified by the arrays q j , W j , T j , hj , j > 0. Notice, that the constant terms q, W, T,, and h do not belong to this structure, they are part of the algebraic structure. 3.9.4 Underlying LP model As discussed above, this is the following deterministic LP model: min cT x s.t. Ax Tx l≤ + qTy ∝b + x W y ∝ h̄ (3.48) ≤u y ≥ 0. The underlying algebraic structure and underlying LP model are in a one–to–one correspondence. 3.9.5 EV: Expected value problem This deterministic LP problem arises when we substitute in (3.45) all random variables by their expected value. Let us introduce the denotations: ξ¯ = [ξ] ∀i, q̄ = ξ [q(ξ)], W̄ = ξ [W (ξ)], T̄ = ξ [T (ξ)] and h̄ = ξ [h(ξ)]. Utilizing (3.47) we obviously get: Pk j¯ q̄ = q + j=1 q ξj Pk j¯ h̄ = h + j=1 h ξj (3.49) Pk j¯ T̄ = T + T ξ j j=1 Pk j¯ W̄ = W + j=1 W ξj E E E The expected value problem is the following deterministic LP: E E CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS EV = min cT x s.t. Ax T̄ x l≤ 55 q̄ T y + ∝b W̄ y ∝ h̄ + (3.50) ≤u x y ≥0 3.9.6 The algebraic equivalent LP We consider the case, when ξ has a finite discrete distribution, i.e. the probability distribution is specified by the realization tableau: ! p1 p2 . . . pN ξb1 , ξb2 . . . ξbN with ξbk ∈ R,p r k > 0, k = 1, . . . , N ; N X pk = 1. k=1 According to (3.47), we get for k = 1, . . . , N the realizations qbk = q + Pk q j ξbjk b hk = h + Pk hj ξbjk Tb k j bk j=1 T ξj Pk j bk = W + j=1 W ξj , ck W = T + j=1 j=1 Pk (3.51) and the realizations tableau for the random arrays is the following: p1 p2 . . . pN 1 qb , qb2 . . . qbN 1 2 N b b b h , h . . . h 1 2 N b b b T , T ... T c 1, W c2 ... W cN W It is easy to see that (3.45) is equivalent to the following LP, which we will call the algebraic equivalent LP. CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS T min c x N X + 56 pk (b q k )T y k k=1 s.t. ∝b Ax Tb k x l≤ (3.52) c k yk ∝ b W h k ∀k + ≤u x y k ≥ 0 ∀k 3.9.7 WS: Wait and see approach The Wait–and–see model is the following: Let us define θ(ξ) = min cT x s.t. Ax T (ξ) x l≤ + q(ξ)T y ∝b + W (ξ) y ∝ h(ξ) (3.53) ≤u x y ≥ 0, then the WS value associated with (3.45) is WS = E [θ(ξ)] (3.54) ξ In the finite discrete case WS means replacing the random variables by the realizations in turn, and solving the resulting deterministic LP models. The objective, denoted by WS, is the expected value of the optimal objective values obtained this way. In this case η is discretely distributed and we have ∀k: θbk = min cT x s.t. Ax Tb k x l≤ x + (b q k )T y ∝b + ck y ∝ b W hk ≤u y ≥ 0, (3.55) CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 57 and thus WS = N X pk θbk . (3.56) k=1 For continuous distributions SLP–IOR offers sampling for estimating WS. 3.9.8 EEV: Expected result of the EV solution Expected result means solving (3.45), with the first–stage solution being fixed as an optimal first–stage solution of the expected value problem (3.50). The objective, which will be denoted by EEV, is the expected value of the optimal objective values obtained this way. Let us denote by x̄ an optimal first–stage solution of the expected value problem (3.50). Then we have: EEV = cT x̄ + E [ min{q(ξ) T ξ y | W (ξ) y ∝ h(ξ) − T (ξ) x̄, y ≥ 0 } ] (3.57) In the finite discrete case we have T EEV = c x̄ + N X pk min (b q k )T y k=1 (3.58) s.t. ck y ∝ b W h k − Tb k x̄ y ≥ 0. For continuous distributions SLP–IOR offers sampling for estimating EEV. 3.9.9 Expected value of perfect information and expected result Let RS denote the optimal objective value of the two–stage problem with recourse (3.45) and let us assume that only the RHS h is stochastic in (3.45). In this case we have the following inequalities: EV ≤ W S ≤ RS ≤ EEV If also T is random, then EV ≤ RS ≤ EEV W S ≤ RS ≤ EEV. CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 58 The expected value of perfect information is defined as EV P I = RS − W S and the value of stochastic solution as V SS = EEV − RS For these quantities see Birge [4] and also [7]; they are measuring the “grade of stochasticity” of the recourse problem. 3.9.10 RFS: Reliability of the first–stage solution Let us assume that in the second–stage problem (3.46) ∝ stands for inequalities row–wise. Let x∗ be a solution of (3.45). The reliability of x∗ is defined as [35]: RF S = P (T (ξ)x ξ ∗ ∝ h(ξ)) (3.59) RFS gives the probability of the event that y = 0 is feasible in the recourse problem (3.46), i.e., that no recourse actions will be needed. 3.9.11 Current solver availability Solver availability depends on structural properties of the model and on the probability distribution of ξ. • The general case (random recourse, objective function stochastic), as formulated in (3.45) and (3.46). – Finite discrete distributions. Solving the equivalent LP (3.9.6). ∗ BPMPD, interior–point solver (Mészáros [59]) which utilizes the special sparsity structure. ∗ General–purpose LP solvers. – Continuous distributions. No direct solver is available. Approximate solutions can be obtained by discretizing the distribution and solving the approximate two–stage problem with finite discrete distribution. For the discretization facilities see Section 12.3. • Fixed recourse. Additional available solvers: – Finite discrete distributions. Solving the equivalent LP (3.9.6) via decomposition: ∗ MSLiP, L–shaped (Benders) decomposition ( Benders [3], Van Slyke and Wets [73], Gassmann [15]). CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 59 ∗ QDECOM, regularized (Benders) decomposition ( Ruszczyński [66]). • Complete recourse, deterministic objective in (3.46); the components of ξ are stochastically independent. Important: there are no additional restrictions concerning the distribution of the random array entries implied by the affine relations (3.47). Additional solvers: – Finite discrete distributions. ∗ DAPPROX, successive discrete approximation (Kall [26], Huang, Ziemba, and Ben–Tal [23], and Kall and Stoyan [29]). ∗ SDECOM, stochastic (Benders) decomposition (Higle and Sen [19], [20], [21]). ∗ SHOR2, decomposition method based on nondifferentiable optimization (Shor et al. [68]). – Continuous univariate uniform–, normal–, and exponential distributions. ∗ DAPPROX, successive discrete approximation (Kall [26], Huang, Ziemba, and Ben–Tal [23], and Kall and Stoyan [29]). ∗ SDECOM, stochastic (Benders) decomposition (Higle and Sen [19], [20], [21]). • Simple recourse. Additional solvers: – Finite discrete distributions. ∗ SHOR1, decomposition method based on nondifferentiable optimization (Shor et al. [68]). ∗ SRAPPROX, successive discrete approximation (Kall and Stoyan [29]). – Continuous univariate uniform–, normal–, and exponential distributions. ∗ SRAPPROX, successive discrete approximation (Kall and Stoyan [29]). For available solvers and their developers see also Chapter 17 and Chapter 18. 3.10 Models with simple integer recourse These models form a subclass of two–stage recourse models with the additional requirement that the recourse variables should only have integer values. Let us assume that n2 = 2 · m2 holds, and let us partition the second–stage variables and objective as given below: + + y q y= , q= , y− q− with y ± ∈ R m2 , q± ∈ R m2 . CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 60 In the formulation of simple integer recourse models the recourse variables are required to take only integer values and the model is formulated involving inequalities in the second stage: T min [ c x + m2 X E ξ [ Qk (χk , hk (ξ)) ] ] k=1 Ax ∝ b s.t. (3.60) Tx = χ l ≤ x ≤ u, where ∀ k Qk (χk , hk (ξ)) = min [ qk+ yk+ s.t. + qk− yk− ] yk+ ≥ hk (ξ) − χk − yk− yk+ , with yk− ≤ hk (ξ) − χk (3.61) ∈ Z+ Z+ denoting the set of nonnegative integers. For details concerning this type of models see Van der Vlerk [71]. In SLP–IOR simple integer recourse models are represented in the same form as simple continuous recourse models (for the latter see Section 3.9). This means that the user enters data exactly in the same manner as for simple continuous recourse. When sending data to a solver, however, the model is interpreted as given in (3.60) and (3.61). The underlying algebraic structure, random variable structure, and regression structure are the same, as for two–stage models. The underlying LP problem, the expected value problem, and the algebraic equivalent LP are mixed–integer LP’s. The present version of SLP–IOR does not deal with deterministic mixed–integer LP’s, therefore, when formulating these associated deterministic problems, the integrality requirement on the second–stage variables is dropped by SLP–IOR. CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 3.10.1 61 Current solver availability A solver is only available for the discretely distributed case: SIRD2SCR (Klein Haneveld et al. [47] and Van der Vlerk [71]). For available solvers and their developers in general see Chapter 17 and Chapter 18. 3.11 Multiple simple recourse This type of models represent an important generalization of simple recourse models, by allowing for piecewise linear penalty costs in the second stage, see Klein Haneveld [46]. They can be formulated as follows: T min [ c x + m2 X E ξ [ Qk (χk , hk (ξ)) ] ] k=1 Ax ∝ b s.t. (3.62) Tx = χ l ≤ x ≤ u, where ∀ k + − − Qk (χk , hk (ξ)) = min [Γ+ k (yk ) + Γk (yk )] yk+ s.t. − yk+ , R R yk− = hk (ξ) − χk yk− ≥ 0, R R − where for ∀ k the following hold: Γ+ + 7→ + , Γk : + 7→ k : both functions are piecewise linear, convex, and monotone. +, (3.63) − Γ+ k (0) = 0, Γk (0) = 0; Let us introduce the following denotations: k k k k • The breakpoints of Γ+ k : 0 = u0 < u1 < . . . < umk < umk +1 = ∞. k k k k • The breakpoints of Γ− k : 0 = l0 < l1 < . . . < lnk < lnk +1 = ∞. k+ k+ k+ • The slopes of Γ+ k : 0 ≤ q1 ≤ . . . ≤ qmk ≤ qmk +1 on the intervals [0, uk1 ], . . . , [ukmk −1 , ukmk ], [ukmk , +∞), respectively. CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 62 k− k− k− • The slopes of Γ− k : 0 ≤ q1 ≤ . . . ≤ qnk ≤ qnk +1 on the intervals [0, l1k ], . . . , [lnk k −1 , lnk k ], [lnk k , +∞), respectively. Using the ∆–method of Dantzig [10], the second–stage problem can be reformulated as follows, see Klein Haneveld [46], see also [72]. We associate variables yik+ to the intervals k [uki−1 , uki ), i = 1, . . . , mk + 1; ∀k, and yik− to the intervals [li−1 , lik ), i = 1, . . . , nk + 1; ∀k. With these variables the equivalent formulation is the following: Qk (χk , hk (ξ)) = min "m +1 k X qik+ yik+ + i=1 s.t. m k +1 X i=1 yik+ nX k +1 # qjk− yjk− j=1 − nX k +1 yjk− = hk (ξ) − χk (3.64) j=1 0 ≤ yik+ ≤ uki − uki−1 , i = 1, . . . , mk k , j = 1, . . . , nk 0 ≤ yjk− ≤ ljk − lj−1 Assuming nk ≥ 1, mk ≥ 1 ∀ k, it is easy to see that (3.62), with the second–stage problem (3.64), corresponds to a complete recourse problem: The recourse matrix obviously contains the (m2 × n2 ) matrix (I, −I) as a sub–matrix. SLP–IOR represents multiple simple recourse models according to the complete recourse formulation (3.64). Let us summarize how such a model is specified: • n2 = 2m2 + m2 P (mk + nk ). In the case, when mk = nk = 0, ∀k holds (there are no k=1 breakpoints), we have a simple recourse model. • Let us consider row k (1 ≤ k ≤ m2 ) of the recourse matrix. In the simple recourse case in this row there are two nonzeros: at position k a 1 and at position m2 + k a -1. In the multiple simple recourse case a group consisting of mk + 1 subsequent 1’s, and with an appropriate shift a second group consisting of nk +1 subsequent -1’s are to be entered. Beginning with k = 1, the shift is determined by the already entered groups. For k = 1 the group consisting 1’s is entered beginning in column position m2 P 1, whereas the group with -1’s has the starting column position m2 + mk . Each k=1 column of the recourse matrix contains a single nonzero element. • The objective coefficients are entered corresponding to the groups of 1’s and -1’s. • For the second–stage variables upper bounds have to be entered for the following variables: yik+ , i = 1, . . . , . . . , mk , yik− , i = 1, . . . , . . . , nk . The upper bounds are, according to (3.64), the lengths of the corresponding subintervals in the piecewise CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 63 k+ linear function. Note, that for ym and for ynk− no upper bounds should be k +1 k +1 specified (the length of the corresponding subinterval is ∞). For the case, when ξ has a finite discrete distribution, Van der Vlerk [72] gave an equivalent formulation as a simple recourse problem, with unchanged dimensions m2 and n2 . In the equivalent problem the number of realizations increases, which does not mean a serious trouble for the solvers of the discrete approximation type, like e.g. SRAPPROX. This result is a breakthrough for this type of models, because from the numerical point of view they are thus on the same level of difficulty, as the simple recourse models. Let us finally mention a further equivalent formulation. The second–stage problem (3.63) can also be written as follows: Qk (χk , hk (ξ)) = min Γ̃k (yk ) s.t. where Γ̃k : R 7→ R + yk (3.65) = hk (ξ) − χk , is piecewise linear and convex, with Γ̃k (0) = 0, and • the breakpoints are: −lnk k , . . . , −lnk 1 , 0, uk1 , . . . , ukmk ; • the slopes are; k+ k+ −qnk− , −qnk− , . . . , −q1k− , q1k+ , . . . , qm , qmk +1 , on the intervals: k +1 k k k k k k (−∞, −lnk ], [−lnk , −lnk −1 ], . . . , [−ln1 , 0], [0, uk1 ], . . . , [ukmk −1 , ukmk ], [ukmk , ∞). 3.11.1 Current solver availability A solver is only available for the discretely distributed case: MScr2Scr (Klein Haneveld [46] and Van der Vlerk [72]). For available solvers and their developers in general see Chapter 17 and Chapter 18. 3.12 Multistage recourse models We consider the following general formulation of a multistage recourse model: CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS E min c1 x1 + T X ξ 64 ct (ζt )xt (ζt ) t=2 ∝ b1 A1 1 x1 At 1 (ζt )x1 t X + (3.66) At τ (ζt )xτ (ζτ ) ∝ bt (ζt ), a.s., t = 2, . . . T τ =2 l1 ≤ x1 ≤ u1 , lt ≤ xt (ζt ) ≤ ut , a.s., t = 2, . . . T where R • ξ : Ω → R is a random vector ξ = (ξ2 , . . . , ξT ) with ξτ : Ω → T P and rτ = R. R rτ , τ = 2, . . . , T τ =2 • ζt : Ω → R Rt is a random vector ζt = (ξ2 , . . . , ξt ), componentwise written as t P rτ . For convenience of denotation let R1 = 0. We ζt = (η1 , . . . , ηRt ) with Rt = τ =2 have RT = R, ξ = ζT = (η1 , . . . , ηR ). We assume that the joint probability distribution of ξ is known. A1 1 is an m1 × n1 matrix, b1 ∈ m1 , c, l, u ∈ n1 . The random entries are modeled via the mappings At τ (·) : Rt → mt ×nτ , bt (·) : Rt → mt , and ct (·) : Rt → nt , 1 ≤ τ ≤ t, 2 ≤ t ≤ T. R R R R R R R R The decision variables xt (ζt ) = xt (ξ2 , . . . , ξt ) are random variables for t ≥ 2. The denotation means that these random variables should fulfill the nonanticipativity (NAN) condition, which requires that xt (ξ2 , . . . , ξt ) should be measurable w.r. to the σ–algebra generated by ξ2 , . . . , ξt . For the precise formulation we should also specify a linear space where the decision variables should belong to, this is, however beyond the scope of the manual. We model the way as randomness enters the model by the mappings above as affine sums as follows: CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS bt (ζt ) = bt + t P Rk P bt ν ην , k=2 ν=Rk−1 +1 where bt , bt ν ∈ ct (ζt ) = ct + t P Rk P where ct , ct ν ∈ t P Rk P R mt , 2 ≤ t ≤ T. ct ν ην , k=2 ν=Rk−1 +1 At τ (ζt ) = At τ + 65 R nt (3.67) , 2 ≤ t ≤ T. At τ ν ην , k=2 ν=Rk−1 +1 where At τ , At τ ν ∈ R mt ×nτ , 1 ≤ τ ≤ t, 2 ≤ t ≤ T. R et ∈ mt ×nt : At t (ζt ) = Problem (3.66) is called a fixed recourse problem, if ∀t ≥ 2 : ∃A et a.s. In SLP–IOR fixed recourse is modeled by setting in (3.67) At t ν = 0 ∀ t ≥ 2, ∀ν. A A fixed recourse problem (3.66) is called a complete recourse problem, if the matrices At t have the complete recourse property ∀ t ≥ 2. For the complete recourse property see, e.g., Kall and Wallace [43]. A fixed recourse problem (3.66) has relatively complete recourse, if (3.66) is feasible for any x1 which fulfills the first–stage restrictions. As structural constituents of a multistage recourse model we consider: → The underlying algebraic structure: As in the two stage case we consider only the constant terms in the affine sums (3.67). This way a deterministic LP emerges which defines the underlying algebraic structure. → The underlying random variables structure: This is defined by the dependency structure and probability distribution of the random vector ξ(ω), together with the partitioning imposed by stages. → The underlying regression structure: The affine sums (3.67) (without the constant terms) are considered as the regression structure. They play an analogous role as in the two stage case. 3.12.1 The underlying algebraic structure The data set which specifies the underlying algebraic structure consists of the following items: ct , t = 1, . . . , T , bt , t = 1, . . . , T , At τ , 1 ≤ τ ≤ t, t = 1, . . . , T , along with type of relations, names for variables and constraints, and with the direction of optimization. CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 3.12.2 66 The underlying random variable structure This is from the point of view of dependency groups identical with that for two stage models, see Section 3.9.2. The multistage structure, however, imposes a further subdivision according to stages. We call ξ being stagewise independent if ξ2 , . . . , ξt are stochastically independent. The model (3.66) has the stagewise independence property, if ξ is stagewise independent and (3.66) can be written as: min c1 x1 E + T X ξ ct (ξt )xt (ζt ) t=2 ∝ b1 A1 1 x1 At 1 (ξt )x1 + t X (3.68) At τ (ξt )xτ (ζτ ) ∝ bt (ξt ), a.s., t = 2, . . . T τ =2 l1 ≤ x1 ≤ u1 , lt ≤ xt (ζt ) ≤ ut , a.s., 3.12.3 t = 2, . . . T The underlying regression structure This is defined analogously as in the two-stage case, see Section 3.9.3. It is specified by cti , bti , At τ i , i ∈ Is , 1 ≤ s ≤ t, 1 ≤ τ ≤ t, 2 ≤ t ≤ T . Note, that the constant terms belong to the underlying algebraic structure. 3.12.4 Underlying LP model This arises if we drop stochasticity, i.e. we just keep the constant terms in the affine sums: min c1 x1 + T X ct xt t=2 ∝ b1 A1 1 x1 At 1 x1 + t X A t τ xτ ∝ bt , t = 2, . . . T τ =2 lt ≤ xt ≤ ut , t = 1, . . . T (3.69) CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 67 The underlying algebraic structure and underlying LP model are in a one–to–one correspondence. Note, that the matrix blocks constitute a lower triangular array of blocks, which is a typical feature of dynamic LP’s. 3.12.5 EV: Expected value problem This deterministic LP problem arises when we substitute all random variables by their expected value. Let us introduce the denotations: ξ¯ = [ξ] = (η̄1 , . . . , η̄R ), c̄t = t t t ξ [ct (ζ )], t = 2, . . . , T , b̄t = ξ [bt (ζ )], t = 2, . . . , T , Āt τ = ξ [At τ (ζ )], 1 ≤ τ ≤ t, t = 2, . . . , T . Utilizing (3.67) we get: E E E b̄t = bt Rk P t P + E bt ν η̄ν , t = 2, . . . , T k=1 ν=Rk−1 +1 c̄t = ct Rk P t P + ct ν η̄ν , t = 2, . . . , T k=1 ν=Rk−1 +1 Rk P t P Āt τ = At τ + (3.70) At τ ν η̄ν , 1 ≤ τ ≤ t, t = 2, . . . , T k=1 ν=Rk−1 +1 This way we get the expected value problem: min c1 x1 + T X c̄t xt t=2 ∝ b1 A1 1 x1 Āt 1 x1 + t X Āt τ xτ (3.71) ∝ b̄t , t = 2, . . . T τ =2 lt ≤ xt ≤ ut , 3.12.6 t = 1, . . . T Underlying two stage problem This problem arises if we drop the NAN requirement for t > 2, i.e. we put together all stages t ≥ 2 into a single second stage: CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS E min c1 x1 + T X ξ 68 ct (ζt )xt (ξ) t=2 ∝ b1 A1 1 x1 At 1 (ζt )x1 + t X (3.72) At τ (ζt )xτ (ξ) ∝ bt (ζt ), a.s., t = 2, . . . T τ =2 l1 ≤ x1 ≤ u1 , lt ≤ xt (ξ) ≤ ut , a.s., t = 2, . . . T The optimal objective value of the underlying two stage model (3.72) clearly supplies a lower bound on the optimal objective value of (3.66). 3.12.7 Finite discrete distribution: the scenario tree Let us assume that ξ has a finite discrete distribution specified by the realization tableau: ! q1 q2 . . . qS ξb1 , ξb2 . . . ξbS with P(ξ = ξb ) = q , s s s = 1, . . . , S. We assume that qs > 0 ∀s holds. The realizations ξbs = (ξb2s , . . . , ξbTs ) = (b η1s , . . . , ηbRs ) are also called scenarios, s = 1, . . . , S. Let us consider the order of the realizations of ξ as fixed, according to the realizations tableau. Let S = {1, . . . , S} be the ordered set of scenario indices. The finite discrete distribution of ξ implies a finite discrete distribution of ζt , t = 2, . . . , T as follows: The different realizations are given by {ζbtρ : ρ ∈ S t } where S t ⊂ S is defined as S t = {ρ | ∃κ ∈ S : ρ = min{s ∈ S | ζbts = ζbtκ }}, i.e., for each of the different realizations ζbtρ of ζt , the index of the realization is the minimal index of those scenarios ζbts , for which ζbts = ζbtρ . CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 69 The corresponding probabilities are πt ρ = P (ζ ξ t = ζbtρ ) = X {qs | ζbts = ζbtρ }. s∈S Let the elements of the set S t be ordered according to the ordering of S. Substituting the realizations into the affine sums (3.67), we get the realizations of the arrays, for s = 1, . . . , S: bb s t := bt + t P Rk P k=1 ν=Rk−1 +1 b cts := ct + t P Rk P k=1 ν=Rk−1 +1 t btsτ := At τ + P A Rk P k=1 ν=Rk−1 +1 bt ν ηbνs , t = 2, . . . , T cti ηbνs , t = 2, . . . , T (3.73) At τ i ηbνs , 1 ≤ τ ≤ t, t = 2, . . . , T In the case of a finite discrete distribution the joint distribution of ξ can also be represented by a scenario tree T = (N , A). This is a rooted tree, with N representing the set of nodes and A standing for the set of edges. The set of nodes and the set of edges are both considered as ordered sets; both sets will be represented by the index sets of their elements: N = {1, . . . , mN }, A = {1, . . . , mA }, where the root node has the index 1. The hierarchical levels of the nodes, imposed by the rooted tree structure, correspond to the stages of our model. For each stage 2 ≤ t ≤ T , the realizations ζbtρ = (ξb2ρ , . . . , ξbTρ ) of ζt , ρ ∈ S t are associated in a one–to–one manner with the nodes of the tree in the corresponding hierarchical level. The edges in A connect nodes of subsequent stages as follows: • The successor nodes of the root node are the nodes corresponding to ζb2ρ , ρ ∈ S 2 . • Each node in stage t ≥ 2, corresponding to ζbtρ , ρ ∈ S t , has as its successors those k nodes in stage t + 1, for which the corresponding realizations ζbt+1 , k ∈ S t+1 , fulfill ρ k ζbt = ζbt . The joint realizations (scenarios) of ξ correspond this way to the leaves of the tree. The unique leaf–to–root path will itself also be called a scenario (path). Let us introduce the following denotations: • tn is the stage to which n ∈ N belongs. • ζbn , with n ∈ N , denotes that realization of ζt , which is associated with n ∈ N . Formally, if the index of the realization which corresponds to n is ρ(n) ∈ S tn , then ρ(n) we have ζbn = ζbtn . • D(t) ⊂ N is the set of nodes in stage t, 1 ≤ t ≤ T . CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 70 • hn is the parent node of node n ∈ N , tn > 1 (immediate predecessor). • H(n) ⊂ N is the set of nodes in the path from n ∈ N to the root, including n (history of node n). • B(n) ⊂ {1, . . . , S} stands for B(n) = {s ∈ S | ζbtsn = ζbn }, i.e., it is the index set of those scenarios, for which the scenario path contains n ∈ N . B(n) itself, along with the set of corresponding scenarios, will be called a scenario bundle corresponding to n. • pn is the probability of B(n): P (ζ ξ tn = ζbn ) = πtn ρ(n) . • C(n) ⊂ N is the set of children of n ∈ N . • G n s is the future of node n along the scenario s, including n. S G n s. • G n is the future of node n ∈ N , i.e., G n = s∈B (n) The following quantities will be associated to the nodes n ∈ N : • ζbn , the marginal realization of ζtn . • pn , the probability of B(n). • We also associate marginal realizations of solutions to nodes, see Section 3.12.8. 3.12.8 Algebraic equivalent LP’s In the discretely distributed case there are several ways of equivalently formulating (3.66) as a deterministic LP. R One way of ensuring NAN is to associate solution pieces to the nodes of T . Let xn ∈ ntn be associated with node n ∈ N , ∀n. The compact LP formulation, also called the implicit formulation, is the following: min P pn ctn (ζbn )T xn n∈N P Atn ,tm (ζbn )xm ∝ btn (ζbn ) ∀n ∈ N (3.74) m∈H(n) ltn ≤ xn ≤ utn ∀n ∈ N . In the two–stage case this LP is the same as the algebraic equivalent in Section 3.9.6. SLP–IOR submits this LP to the solver when a general–purpose LP solver is selected for CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 71 solving (3.66) with a discrete distribution. Another way of ensuring NAN is by adding explicit constraints for this to the LP. In this approach we associate solution vectors to scenarios. Let xs = (xs1 , . . . , xsT ) be an n1 + · · · + nT –dimensional vector, partitioned according to stages, s = 1, . . . , S. Let us consider the collection of these vectors, and let us associate them to scenario paths in T . Considering a specific node n ∈ N , several subvectors might be associated to this node; xstn will be associated to node n ∈ N for all s ∈ B(n). For these subvectors we simply prescribe equality by adding constraints. The resulting equivalent LP’s are called explicit formulations or split–variable forms. Below we list those variants, which can be generated in SLP–IOR. For the formulation let us consider a bundle B(n) and assume that the scenarios, belonging to this bundle, are (arbitrarily) ordered. Let 1B(n) , . . . , kB(n) , be the ordered sequence of scenario indices. The next equivalent LP has the following form: min S P qs c1 xs1 + s=1 T P cst xst t=2 A1 1 xs1 Ast 1 xs1 ∝ b1 + t P Ast τ xsτ ∝ bst , t = 2, . . . , T (3.75) τ =2 l1 ≤ xs1 ≤ u1 , 1 xt B(n) lt ≤ xst ≤ ut , = xst , ∀s ∈ B(n) ∀n ∈ D(t), t = 2, . . . , T t = 1, . . . , T where 1B(n) is the first element in B(n). The last group of constraints we will call NAN–constraints. constraints in the above straight NAN–constraints. Let us call the NAN– The third formulation is the ladder formulation of the NAN–constraints: CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS T P s s s q s c1 x 1 + ct x t S P min 72 s=1 t=2 A1 1 xs1 ∝ b1 Ast 1 xs1 t P + Ast τ xsτ ∝ bst , t = 2, . . . , T (3.76) τ =2 l1 ≤ xs1 (i+1)B(n) i lt ≤ xst ≤ ut , t = 2, . . . , T , i = 1, . . . , k − 1 ∀n ∈ D(t), t = 1, . . . , T ≤ u1 , xtB(n) = xt where 1B(n) , . . . , kB(n) is the sequence of scenario indices in B(n), see Page 71. The next equivalent LP formulation is the conditional expectation formulation: min S P qs c1 xs1 + T P cst xst t=2 s=1 A1 1 xs1 ∝ b1 Ast 1 xs1 + t P Ast τ xsτ ∝ bst , (3.77) τ =2 t = 2, . . . , T l1 ≤ xs1 ≤ u1 , P σ∈B(n) pσ xσt = P lt ≤ xst ≤ ut , ! pσ xst , ∀s ∈ B(n) ∀n ∈ D(t), t = 2, . . . , T t = 1, . . . , T σ∈B(n) The last LP formulation introduces additional variables zn , n ∈ N , which are associated to the nodes; it is called the node–state variable formulation: CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS min S P 73 T P s s s q s c1 x 1 + ct x t s=1 t=2 A1 1 xs1 Ast 1 xs1 ∝ b1 + t P Ast τ xsτ ∝ bst , (3.78) τ =2 t = 2, . . . , T l1 ≤ xs1 ≤ u1 , lt ≤ xst ≤ ut , t = 2, . . . , T xst = zn , ∀s ∈ B(n) ∀n ∈ D(t), 3.12.9 t = 1, . . . , T WS: Wait and see approach This is a straightforward extension of the two–stage case, see Section 3.9.7. Let us consider the following random variable: θ(ξ) = min c1 x1 + T X ct (ζt )xt t=2 ∝ b1 A1 1 x1 At 1 (ζt )x1 + t X (3.79) At τ (ζt )xτ ∝ bt (ζt ), a.s., t = 2, . . . T τ =2 l1 ≤ x1 ≤ u1 , lt ≤ xt ≤ ut , t = 2, . . . T then W S := E [θ(ξ)] ξ (3.80) In the discretely distributed case this can be computed as follows: let for s = 1, . . . , S CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS θbs = min c1 x1 + T X 74 ct (ζbts )xt t=2 ∝ b1 A1 1 x1 At 1 (ζbts )x1 t X + (3.81) At τ (ζbts )xτ ∝ bt (ζbts ), t = 2, . . . T τ =2 l1 ≤ x1 ≤ u1 , lt ≤ xt ≤ ut , t = 2, . . . T, leading to WS = S X ps ηb s . (3.82) s=1 For continuous distributions SLP–IOR provides sampling for approximating W S. 3.12.10 Computing the recourse objective Let x̄1 be any first–stage vector which fulfills the first–stage restrictions. Fixing x1 = x̄1 in (3.66) leads to the following problem: γ(x̄1 ) = min E T X ξ ct (ζt )xt (ζt ) t=2 t X At τ (ζt )xτ (ζτ ) ∝ bt (ζt ) − At 1 (ζt )x̄1 , a.s., t = 2, . . . T τ =2 lt ≤ xt (ζt ) ≤ ut , a.s., t = 2, . . . T (3.83) where we have omitted the constant term c1 x̄1 in the objective, i.e., γ(x̄1 ) is the recourse objective value for fixed x1 = x̄1 . Choosing x̄1 as the first–stage part of an optimal solution of the expected value problem (3.70), we get EEV : EEV = c1 x̄1 + γ(x̄1 ). CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 75 Note, that in the case when (3.70) has multiple optimal solutions, we may get different EEV values for them. Let us consider the case of a finite discrete distribution. In this case, γ(x̄1 ) can be computed by solving | D(2) | subproblems, which are T −1–stage multistage recourse problems (| D(t) | is the number of nodes of the scenario tree in stage t, see Section 3.12.7). The trick is using conditional expectations by conditioning on ξ2 . • For each node n ∈ D(2) we consider the subtree T n of T , which is rooted at n and normalize the probabilities of the subtree, such that the root n has probability 1. A T − 1–stage scenario tree arises. Fixing x1 = x̄1 and ξ2 = ζbn , tn = 2, we solve the corresponding T − 1–stage problem. Let us denote the optimal objective value of this subproblem by γn (x̄1 ). • Using the well–known formula for expressing an expectation in terms of conditional expectations we get: X γ(x̄1 ) = pn γn (x̄1 ). n∈D(2) EV P I and V SS are analogously defined, as in the two–stage case, see Section 3.9.9. 3.12.11 Block–separable recourse Multistage recourse problems with block–separable recourse constitute a subclass of multistage recourse problems, which can be equivalently formulated as two stage problems. This subclass is defined by the following properties: I the problems have fixed recourse. I they have a lower bidiagonal block–structure, i.e. they are of the following form: min c1 x1 E + T X ξ ct (ζt )xt (ζt ) t=2 ∝ b1 A1 1 x1 At t−1 (ζt )xt−1 (ζt−1 ) + At t xt (ζt ) ∝ bt (ζt ), a.s., t = 2, . . . T l1 ≤ x1 ≤ u1 , lt ≤ xt (ζt ) ≤ ut , a.s., t = 2, . . . T, (3.84) CHAPTER 3. THE SCOPE OF SLP–IOR: SLP–MODELS 76 i.e., At τ (ζt ) ≡ 0 for τ < t − 1, ∀t. I there exists a partition xt (ζt ) = (wt (ζt ), yt (ζt )) such that the corresponding partition of the arrays looks as given below. Variables in the w–part are usually called aggregate– level variables, whereas the y–variables are called detailed–level variables, see Birge and Louveaux [7]. The terminology has its origin in certain practical model classes, which have this property. Ct 0 Rt (ζt ) 0 gt (ζt ) t t Āt t = , At+1,t (ξ ) = , bt (ξ ) = . 0 Dt St (ζt ) 0 ht (ζt ) This results in the following structure for two subsequent stages: wt (ζt ) yt (ζt ) wt+1 (ζt+1 ) yt+1 (ζt+1 ) 0 gt (ζt ) Ct 0 Dt ht (ζt ) R (ξ~ t ) 0 Ct+1 0 gt+1 (ζt+1 ) t St (ξ~ t ) 0 0 Dt+1 ht+1 (ζt+1 ) This structure is especially advantageous for nested decomposition in the discretely distributed case, see Birge and Louveaux [7]. In the special case, when Rt (ζt ) ≡ Rt and gt (ζt ) ≡ gt , ∀t, then (3.84) is equivalent to a two–stage problem, where in addition to x1 , the w–variables are also put into the first stage, as variables w2 , . . . , wT . SLP–IOR has a facility for checking the model instance for this property. 3.12.12 Current solver availability Currently solvers are only available for the discretely distributed case, i.e., for multistage models with scenario trees. For multistage models with continuous distributions scenario generation techniques are available, see Section 12.3. The solution approach is to solve the equivalent LP (3.74). • MSLiP, nested (Benders) decomposition ( Birge [5] and Gassmann [15]). • General–purpose LP solvers. For available solvers and their developers see also Chapter 17 and Chapter 18. Part II MODELING 77 Chapter 4 Building a model instance 4.1 Setting up a new model instance After starting up SLP–IOR, there is no current model instance, and the main menu corresponds to a deterministic model, as shown in Figure 2.2. The main menu items [File] and [Edit–Model] serve for setting up a model. The first step in setting up a new problem consists of specifying the type of the model instance. This can be accomplished via [File],→[New Model Instance]. A form, displaying the currently available models as a tree, shows up, see Figure 9.2 on page 98. For the currently available models see Chapter 3. The desired model type can be chosen by clicking its name, for the details please consult Section 9.1.1. A new model instance of the selected type will be set up, with default dimensions (all 1) and with zero arrays. The order of specifying other characteristics and of entering data is in general arbitrary; the few exceptions will explicitly be mentioned. Please notice, that in some cases, typically when changing dimensions, some care is needed in order not to loose already specified data. These kinds of side effects are discussed below, with the corresponding items. Under the main menu item [Edit–Model], the problem name and the direction of optimization (min or max) can be chosen next (see Sections 9.2.1 and 9.2.2). The current modeling status can be viewed by right clicking the main form, which pops up the menu shown in Figure 2.7 on page 25. Clicking [Modeling Status] in this menu, results in displaying an overview on the current modeling status. The nonzero pattern, and stage– or chance constraint boundaries can be viewed by choosing [View–Model],→[View Underlying LP Structure], see Section 9.3.2 and Figure 9.25 on page 124. The remaining features for setting up a model instance are also located under the main 78 CHAPTER 4. BUILDING A MODEL INSTANCE 79 menu item [Edit–Model]. We first discuss the features for the case, when a deterministic LP has been chosen. Subsequently the facilities additionally available for a stochastic model will be described. 4.1.1 Setting up a deterministic LP For a checklist how to do this see Section A.1. Specifying dimensions If the model instance is of the multistage LP type, see Section 3.8, the number of stages can be entered under [Edit–Model],→[Number of Stages]. • Increasing the number of stages: for the new stages default dimensions and zero arrays are added. • Decreasing the number of stages: for the stages above the new number of stages, all data will be lost without warning. The row/and column dimensions corresponding to stages and to the chance constraint, (if appropriate), can be specified under [Edit–Model],→[Dimensions], see also Section 9.2.4. • Increasing a dimension: for the corresponding arrays the dimension will be increased, the new entries will be zeros. • Decreasing a dimension: for the corresponding arrays the dimension will be decreased, data in the deleted part will be lost without warning. Specifying array elements For entering array elements via keyboard, [Edit–Model],→[Edit Data Arrays/Relations] can be used. A form for selecting an array shows up first, see Section 9.2.5 and Figure 9.13 on page 110. Clicking the button <View> in this array selection form shows a summary on the model instance, see Figure 9.8 on page 106. Having selected the array which should be updated, the matrix editor appears, where data can be edited for the specific array, see Section 14.1 and Figure 14.1 on page 171. Clicking <View> in the matrix editor shows the nonzero pattern of the array, see Section 14.2 and Figure 14.3 on page 174. For multistage models, the underlying LP model can be edited as a whole, under [Edit– Model],→[Edit Underlying LP]. For larger arrays, entering all elements via the keyboard may be cumbersome or even prohibitive. The following facilities are available for such cases: CHAPTER 4. BUILDING A MODEL INSTANCE 80 • Using the Windows Clipboard: proceed as described before, for updating array elements. When the matrix editor appears, click the right mouse button over the editor sheet. A pop up menu, as shown in Figure 14.2 on page 172, appears which offers exporting/importing rectangular array parts via the Clipboard, as described in Section 14.1. • Using the SLP–IOR blackboard: arrays can be saved/retrieved via the blackboard directory on disk, see Section 9.2.16 and Figure 9.23 on page 122. Already saved arrays can be appended to existing arrays either row–wise or column–wise; the problem dimensions will be updated accordingly. Please notice, that in both cases existing array elements will be overwritten without warning. Specifying relations [Edit–Model],→[Edit Data Arrays/Relations] serves also for specifying relations (≤, =, ≥) in the constraints; they should be entered as (<, =, >), respectively. Specifying names [Edit–Model],→[Edit Names] serves for updating names of rows and columns. For the details see Section 9.2.6 and Figure 9.10 on page 107. 4.1.2 Setting up a stochastic model instance For checklists how to do this see Sections A.2 and A.3. In addition to the items discussed above, the number and names of random variables are to be specified, along with the stochastic dependency structure and probability distribution of the random vector. Finally, the connection between the random variables and the random array entries is to be specified. The current mapping between random variables and random array entries can be viewed via [View–Model],→[View Random Variables Map], see Section 9.3.3 as well as Figures 9.26 and 9.27 on page 125. Specifying random variables dimension Choose [Edit–Model],→[Dimensions], and edit the dimension corresponding to the random variable. • Increasing the number of random variables: the new random variables will be stochastically independent among each other and w.r. to the existing ones. Their probability distribution will be a one–point discrete distribution. CHAPTER 4. BUILDING A MODEL INSTANCE 81 • Decreasing the number of random variables: in this case some of the last random variables will become superfluous. SLP–IOR will first try to simply delete them, as long as the groups structure of the remaining random variables does not change (this is e.g. the case if the random variables are independent). If unsuccessful, then the distribution of the whole random vector will be dropped, and the default setting (independent, one–point discrete distributions) will be established. In this case the user will be asked for a confirmation of this drastic operation first. Specifying random variable names This can be done under [Edit–Model],→[Edit Names] in a straightforward manner. Specifying the dependency structure This means choosing between three cases: stochastic independence, totally dependent (one group), or mutually stochastically independent groups of random variables, see e.g. Section 3.3.2. For details how to specify this, see Section 9.2.11 and Figure 9.16 on page 113. Changing this structure involves loss of the currently specified probability distribution; before carrying it out the user will be asked for a confirmation first. Specifying the probability distribution The probability distribution of the mutually stochastically independent groups is to be specified, see Section 9.2.12 and Figure 9.17 on page 114. For the currently available distributions see Chapter 15. Establishing the mapping: random variables 7→ array entries Up to this point, the random variables have no connection to the model instance, they exist as a separate entity. For establishing the mapping, SLP–IOR uses affine relations “regression terms”, as described e.g. for a two–stage model in Section 3.9, relations (3.47) on page 52. For establishing the mapping there are two ways available: • If random variables and random array entries are in a one–to–one correspondence, i.e., the random variables straightly represent random entries, then the connection can be established in a direct way, i.e. without involving regression terms. Choosing the random array entries can be accomplished via [Edit–Model],→[Pick Random Entries], see Section 9.2.9 and Figure 9.14 on page 111. • In the general case, the specification is to be done in the following order: Stochastic arrays (arrays which contain random entries) are to be chosen first, via [Edit–Model],→[Stochastic Parts], see Section 9.2.8 and Figure 9.12 on page 109. CHAPTER 4. BUILDING A MODEL INSTANCE 82 After having done this, the regression arrays are to be specified via [Edit–Model],→[Edit Regression Terms], see Section 9.2.10. 4.1.3 Using building blocks There are two types of building blocks available for constructing model instances: • The individual arrays appearing in the model formulations can be saved/retrieved via the blackboard directory on disk, see Section 9.2.16 and Figure 9.23 on page 122. Already saved arrays can also be appended to existing arrays either row– or column– wise; the problem dimensions will be updated accordingly. • For stochastic models, the three underlying structures, as discussed in Chapter 3, constitute the highest level of building blocks. The underlying algebraic–, random variable– and regression structures can be saved/retrieved, see Section 9.2.15 and Figure 9.22 on page 122. Please notice, that in both cases existing data will be overwritten without warning. 4.2 Input/output of model instances These features are available under the main menu item [File]. 4.2.1 SLP–IOR format Saving a model instance in SLP–IOR internal format can be accomplished either by [File],→[Save] or by [File],→[SaveAs]. The difference is, that for the former there is no dialog for file and directory specification: the file will be saved in the directory for model instances in SLP–IOR format, according to the current system settings, see Section 2.3. An existing file with the same name will be overwritten without warning. For [SaveAs] the usual Windows SaveAs dialog appears, and the user will be asked for confirmation before overwriting an existing file. See also Sections 9.1.2 and 9.1.3. Loading a model instance which has previously been saved in SLP–IOR format can be carried out via [File],→[Open], which invokes a dialog corresponding to the usual Windows dialog with the same name, see Section 9.1.2. There is a feature for browsing (S)LP problem data files, before choosing one for actually loading it. During browsing the main characteristics of the models is displayed, thus supporting the choice of the problem to be loaded. For details see Section 9.1.4. 4.2.2 SMPS format This is the standard format for multistage recourse problems proposed by Birge et al. [6], which is widely accepted for communicating SLP model instances. For SMPS, random CHAPTER 4. BUILDING A MODEL INSTANCE 83 variables must coincide with random array entries implying that not all SLP problems SLP–IOR deals with can be exported in this format. This facility can be utilized via [File],→[Export/Import]. For details please consult Section 9.1.5. 4.2.3 GAMS format Deterministic LP model instances, written in the GAMS modeling language [8], can be imported into SLP–IOR, provided the user has access to GAMS. The facility is available via [File],→[Export/Import], see Section 9.1.5. The imported model will be represented as a one–stage deterministic LP (see Section 3.2). Conversely, the data–set of a one– or two–stage SLP model can be exported in GAMS format. 4.3 Modifying an existing model instance The facilities described in Section 4.1, for setting up a new model instance, can naturally also be used to update various parts of the model instance. In this section we present features, which serve for changing the model as a whole, by e.g. involving all arrays belonging to a certain stage or by changing the type of the model. 4.3.1 Changing the type of the model instance This facility serves for building various types of SLP models, based on the same data set. Typical application is to build various kinds of stochastic variants of an LP model. The facility can be utilized via [Analyze],→[Transform Model], see Section 11.1.4. If a stochastic model is transformed into a deterministic one, the stochastic data will be lost. If a deterministic model is transformed into a stochastic one, default arrays (e.g. a recourse matrix) and a default random variable structure will be added. If a stochastic model is transformed into a stochastic model of another type, the transformation may involve adding default parts (e.g. if a chance–constrained model is transformed into a two–stage model then a default recourse matrix is added), and it may also involve loosing data (e.g. if a two–stage model is transformed into a chance–constrained model then the recourse matrix will be lost). Because transformation might involve loosing data, the user is asked for confirmation before the transformation is actually carried out. 4.3.2 Recasting a model instance This facility serves for recasting the model instance without changing its type, by performing operations on constraints (rows) and variables (columns), which may simultaneously CHAPTER 4. BUILDING A MODEL INSTANCE 84 involve several stages, or in the chance constrained case both the deterministic and the stochastic part. The available facilities and their usage are described in detail in Section 9.2.14. As an example let us consider moving a constraint from the first stage to the second stage in a two–stage complete recourse model, see Section 3.9. The following changes will occur: The corresponding row of A will be inserted into T (ξ); a zero row will be inserted into W , the corresponding element of b will be inserted into h(ξ); the relation (≤, =, or ≥) and row name from the first stage will be inserted into the second–stage relations and names list, respectively. The corresponding constraint will be deleted in the first stage (involving A, b and the first stage relations and names). Finally problem dimensions and regression arrays will be updated accordingly. Please notice, that after this operation the problem ceases to be a complete recourse problem. SLP–IOR does not automatically change the model type to (non–complete) fixed recourse, because the user supposedly will enter elements into the new (zero) row in W , such that complete recourse is restored. Please notice, that the complete recourse property can be checked under the main menu item [Analyze],→[Analyze Model Instance]. 4.3.3 Example: building stochastic variants of a one stage LP As described in Section 4.2.3, after importing an LP in GAMS format, a one–stage deterministic LP appears in SLP–IOR. Below we give examples of sequences of actions which end up with stochastic problems as stochastic variants of that LP. Target type is a two–stage recourse model For checklists how to do this see Sections A.4 and A.5. For the two–stage model we use the denotations of Section 3.9. We suppose for the sake of simplicity that in the targeted two–stage model random variables coincide with random entries. Let us suppose first that the technology matrix of the LP consists solely of the rows of the matrices A and T̄ 0 , i.e., in the targeted two–stage model a recourse matrix W is to be added. • Transform the model into a two–stage fixed recourse model via [Analyze],→[Transform Model]. The model instance will be transformed into a two–stage recourse model with the following features: the technology matrix, RHS, objective and relation types of the original LP will now belong to the first stage. The second stage will have a single row, the dimension of the second–stage variables will be 1, all added matrices will be zero matrices. The random vector ξ will be CHAPTER 4. BUILDING A MODEL INSTANCE 85 1–dimensional with a one–point discrete distribution. All regression terms will be zeros, i.e. there is no connection between random variables and array entries. • Enter the number of variables in the second stage, via [Edit–Model],→[Dimensions]. • By utilizing [Edit Model],→[Recast Model] perform the following operations: – Move the constraints (rows), which should belong to the second stage, from the current first stage into the second stage. – Delete the zero row in the second stage, which has automatically been introduced during the transformation. • Update the recourse matrix W (which is a zero matrix currently), via [Edit–Model],→[Edit Data Arrays/Relations]. • Update names and relations in the second stage, [Edit–Model],→[Edit Names]. • Proceed by specifying the stochastic structure as described in Section 4.1.2. Let us suppose now that the technology matrix of the LP contains also columns which should belong to the recourse matrix. • Transform the model into a two–stage fixed recourse model via [Analyze],→[Transform Model]. The model instance will be transformed into a two–stage recourse model with the features described above. • Enter the number of variables in the second stage, via [Edit–Model],→[Dimensions]. • By utilizing [Edit–Model],→[Recast Model] perform the following operations: – Move the constraints (rows), which should belong to the second stage, from the current first stage into the second stage. – Delete the zero row in the second stage, which has automatically been introduced during the transformation. – Move the desired variables (columns) from the first stage to the second stage. Please notice that this will cut off elements in the moved column with row indices belonging to the first stage. – Delete the superfluous zero columns in the second stage. • Update the recourse matrix W , if it should contain additional elements which do not originate in the deterministic LP, via [Edit–Model],→[Edit Data Arrays/Relations]. CHAPTER 4. BUILDING A MODEL INSTANCE 86 • Update relations in the second stage, [Edit–Model],→[Edit Data Arrays/Relations]. • Update names in the second stage, [Edit–Model],→[Edit Names]. • Proceed by specifying the stochastic structure as described in Section 4.1.2. Target type is a jointly chance–constrained model For a checklist how to do this see Section A.6. For the jointly chance constrained model we use the denotations of Section 3.3. We suppose for the sake of simplicity, that in the targeted chance–constrained model random variables coincide with random entries. • Transform the model into a jointly chance–constrained model via [Analyze],→[Transform Model]. The model instance will be transformed into a jointly chance–constrained model with the following features: the technology matrix, RHS, objective, and relation types of the original LP will now belong to the deterministic part. The stochastic part will have a single row, all added matrices will be zero matrices. The random vector ξ will be 1–dimensional, with a one–point discrete distribution. All regression terms will be zeros, i.e. there is no connection between random variables and array entries. The probability level α will be 0.9. • By utilizing [Edit–Model],→[Recast Model] perform the following operations: – Move the constraints (rows), which should belong to the stochastic part, from the deterministic part into the stochastic part. – Delete the zero row in the stochastic part, which has automatically been introduced during the transformation. • Update the probability level α if necessary, via [Edit–Model],→[Edit Data Arrays/Relations]. • Update relations in the second stage, [Edit–Model],→[Edit Data Arrays/Relations]. • Update names in the second stage, [Edit–Model],→[Edit Names]. Pay special attention to the relations in the stochastic part, which should be inequalities for this model type. • Proceed by specifying the stochastic structure as described in Section 4.1.2. Chapter 5 Solving a model instance 5.1 Starting up a solver Starting up a solver consists of selecting a solver, and subsequently starting it up. The former can be accomplished via [Solver–Lib],→[Select Solver], the latter via [Solve],→ [Solve Current Problem]. If there is no current solver selected (see the status bar at the bottom line of the main form) then it is possible to go directly to [Solve Current Problem]; SLP–IOR will offer solver selection automatically. The solvers offered for the current model instance are those, which are considered as appropriate for the model instance, on the basis of information supplied in the solver description database, see Section 16.3. Solver selection can be accomplished by checking the checkbox situated at the left of the solver name. After clicking [Solve Current Problem], a form shows up which offers update facilities for the selected solver’s run time (control) parameters, see Section 10.1.1 and Figure 10.2 on Page 128. When starting up a solver for the first time during a modeling session (a run of SLP–IOR ), the run time parameters will be the defaults as specified in the solver description database. Otherwise the form will show the parameter values as selected at the previous run of the solver. It is always possible to select the defaults, though. Clicking <Run Solver> starts up the solver run. 5.2 Viewing/saving the solution The lastly obtained solution can be viewed via [Solve],→[View Results], resulting in popping up of a form as shown in Figure 10.3 on Page 130, and described in Section 10.1.3. For recourse problems, several solvers just return the first–stage solution. The button <Compute Recourse Solution> serves for computing the recourse solution, in the 87 CHAPTER 5. SOLVING A MODEL INSTANCE 88 discretely distributed case. [Solve],→[Edit Solution] serves for editing, saving, and loading solutions. [Solve],→[Summary on Run] offers an overview on the last solver run; [Solve],→[Solver Files] serves for viewing various files (like a log file), possibly produced by the solver. For a GAMS solver the GAMS listing file can be viewed via [Solve],→[View GAMS Listing]. Chapter 6 Analyzing the model and solution 6.1 Analyzing the model These facilities are currently only available for recourse problems. For a checklist how to do this see Section A.8. The facilities serve for analyzing the model instance. They can be utilized via [Analyze],→[Analyze Model Instance]. Several indicators can be computed, like EVPI and VSS, see Sections 3.9.7, 3.9.8, and 3.9.9. The computations can be carried out for finite discrete distributions exactly (in the numerical sense), or alternatively by simulation (which also works for continuous distributions). For the details see Section 11.1.1 and Figure 11.2 on Page 135. The facility also offers various checking services, like checking whether the model has the complete– or simple recourse property, or for multistage models, additionally stagewise independence or block–separable recourse can be checked. See also Section 11.1.1. 6.2 Analyzing the solution These facilities are currently only available for recourse problems. For a checklist how to do this see Section A.7. Analysis in this case means analysis of a first–stage solution, meaning in general any vector having the dimension of the first–stage solution. The reliability of the solution can be computed as well as the overall objective value corresponding to this solution. The facilities are available via [Analyze],→[Analyze Solutions]. The computations can be carried out for finite discrete distributions exactly (in the numerical sense), or alternatively by simulation (which also works for continuous distributions). For the details 89 CHAPTER 6. ANALYZING THE MODEL AND SOLUTION see Section 11.1.2 and Figure 11.2 on Page 135. 90 Chapter 7 Modeling tools 7.1 Algebraic equivalent LP These tools are accessible under [Algeb–Equi]. The facilities can be utilized, provided that for the current model instance an algebraic equivalent deterministic LP exists. In this case this LP can be built, edited, and saved in MPS data format. The last facility serves for exporting this LP to external LP solvers. For the details see Section 12.1 and Figure 12.1 on Page 140. 7.2 Arrays in the underlying algebraic structure These facilities serve for performing various operations on the individual arrays in the underlying algebraic structure. The facilities can be utilized under [Algeb–Struct]. The [Perturb Array] feature is for imposing a random perturbation on a selected array, e.g. for stress testing the model, see Section 12.2.1 and Figure 12.3 on Page 141. The remaining facilities serve for computing the rank and for checking the complete recourse property. For details see Section 12.2 and Figure 12.2 on Page 141. 7.3 Probability distribution The facilities can be utilized under [Rand–Vars]. The first group of facilities serves for discretizing the probability distribution either for each of the mutually independent groups separately or for the whole random vector in a unified manner. A checklist how to carry out the discretization for the separate groups, is available in Section A.9. 91 CHAPTER 7. MODELING TOOLS 92 The main steps in the discretization of a group are the following: • For distributions with an unbounded support a truncation is to be specifed first. • A sample is to be computed next. • A subdivision of the truncated support is to be specified. • Finally based on the sample and the subdivision the discretization is computed. For details see Section 12.3.1 and Figure 12.5 on Page 144. For multistage recourse problems additional facilities serve for manually building the scenario tree, for generating scenarios via sampling and discretization, or via generating scenarios with prescribed moments. Chapter 8 A workbench for testing solvers 8.1 Generating batteries of deterministic LP problems Batteries of randomly generated LP test problems can be generated via [Workbench],→[GENSLP: recourse problems]. On the form which pops up choose [Deterministic], in the radio button group located on the form, see Figure 13.2 on Page 13.2. For specifying characteristics of the test problems to be generated, please proceed as described in Section 13.1.1. Having finished the specification, click <Generate> to generate the battery. 8.2 Generating batteries of recourse problems Batteries of randomly generated recourse problems can be generated via [Workbench],→[GENSLP: recourse problems]. On the form which pops up choose [Stochastic], in the radio button group located on the form, see Figure 13.2 on Page 13.2. For specifying characteristics of the test problems to be generated, please proceed as described in Section 13.1.1. Having finished the specification, click <Generate> to generate the battery. For the test problems in the generated battery the existence of a solution is ensured. 8.3 Generating batteries of jointly chance constrained problems Batteries of randomly generated jointly chance constrained problems can be generated via [Workbench],→[GENSLP: jointly chance constrained]. For specifying characteristics of the test problems to be generated, please proceed as described in Section 13.1.2. Having finished the specification, click <Generate> to generate the battery. For the test problems in the generated battery an optimal solution is known which can be viewed 93 CHAPTER 8. A WORKBENCH FOR TESTING SOLVERS 94 after loading the test problem, in the Notes associated to the problem. For viewing the notes, right click the main form, and in the pop up menu which appears choose [Notes]. 8.4 Dealing with batteries and performing test runs with them The facilities for dealing with test problem batteries are available via [Workbench],→[Test Problem Batteries], which results in popping up of the form shown in Figure 13.6 on Page 166. The references to menu points below are with respect to this form. 8.4.1 Performing a test run For a checklist how to do this see Section A.10. This facility serves for solving each of the problems in a selected test problem battery, with a group of selected solvers in turn. The selection of the elements of the battery can be carried out via <new battery>, and the group of solvers can be selected via <select solvers>. Important: before selecting solvers, a test problem representing the model type of the battery elements should be loaded via <load model instance>. The reason is, that the list of solvers offered for selection should only contain solvers which are capable (according to their specification in the solver description database) to solve each of the test problems in the battery. For details how a test run can be carried out see Section 13.1.3. 8.4.2 Generating a battery consisting of variants of a single problem The facility is available via <perturb current model instance>. This facility serves for randomly generating variants of an (S)LP problem; the problem which constitutes the basis of the perturbation, is the current model instance. The idea is to impose random perturbations on a selected array of the problem. For details see Section 13.1.3. 8.4.3 Discretizing the probability distribution for each element of a battery The facility is available via [discretize]. This facility is for discretizing the probability distribution for each of the test problems of a battery, in a uniform manner. The battery CHAPTER 8. A WORKBENCH FOR TESTING SOLVERS 95 is to be selected first and clicking <discretize> subsequently results in carrying out the operation. For the details, especially for the name conventions of the generated problems/files see Section 13.1.3. 8.4.4 Injecting the same probability distribution into each element of a battery The facility is available via <inject current distribution>. This facility is for injecting the same probability distribution into each of the test problems of a battery. The probability distribution to be injected, will be taken from the current model instance. The battery is to be selected first, and clicking <inject current distribution> subsequently results in carrying out the operation. For the details, especially for the name conventions of the generated problems/files, see Section 13.1.3. 8.4.5 Endowing each element of a battery with a normally distributed RHS The facility is available via <endow with normal RHS>. This facility is for endowing each of the test problems of a battery with the following stochastic structure: only the RHS is stochastic and has a normal distribution. The battery is to be selected first, and clicking <endow with normal RHS> subsequently results in carrying out the operation. For the details, especially for the name conventions of the generated problems/files, see Section 13.1.3. 8.4.6 Endowing each element of a battery with a normal distribution The facility is available via <endow with normal distribution>. This facility is for endowing each of the test problems of a battery with normally distributed random entries. The battery is to be selected first, and clicking <endow with normal distribution> subsequently results in carrying out the operation. For the details, especially for the name conventions of the generated problems/files, see Section 13.1.3. Part III REFERENCE 96 Chapter 9 Building an SLP model 9.1 Main menu item: File The facilities available here serve for creating a new model instance, for reading/writing SLP model instances in SLP–IOR format, for exporting/importing model instances in other formats, and for terminating the modeling session. Clicking this main menu item results in the pull down menu shown in Figure 9.1. Figure 9.1: Main menu item: File 9.1.1 New Model Instance This serves for setting up a new model instance; an existing model instance will be lost. Clicking this item result in the form as shown in Figure 9.2. The menu items in Figure 9.2 are provided in a tree format, according to the hierarchy of (S)LP models presently available in SLP–IOR. Selecting an item consist of left clicking the text corresponding to the leaves of the tree. If a model instance already exists, the 97 CHAPTER 9. BUILDING AN SLP MODEL 98 Figure 9.2: Models: New model instance user will be prompted whether to continue. If confirmed, the new model will be created and the existing model is lost. We suggest to select the type of model as specific as possible. The reason is that this way a larger list of solvers may become available, including also solvers specialized to the corresponding subclass of models. 9.1.2 Open, SaveAs Clicking [Open], or [SaveAs] invokes the corresponding Windows dialog. If in the case [Open] a model instance already exists, the user will be prompted whether to continue. If confirmed, the new model will be loaded and the existing model is lost. CHAPTER 9. BUILDING AN SLP MODEL 9.1.3 99 Save Clicking [Save] saves the current model instance in a file, with file name being the model’s name and extension being slm. The file will be saved in the current directory for models in SLP–IOR format, see Section 2.3 on page 21. If a file with the same name and extension already exists in that directory, it will be overwritten without warning! 9.1.4 Browse Clicking [Browse] results in the usual Window file opening dialog. there, results in displaying a window shown in Figure 9.3. Selecting a file The form shown displays the main characteristics of the model. If the user decides to load the model, then clicking <Load> results in loading the model instance and the system returns to the main menu. Clicking <Close> results in returning to file selection, i.e. browsing can be continued. 9.1.5 Export/Import The facilities under [Export/Import] serve for reading/writing model instances in formats different from that of SLP–IOR. Clicking this item, pops up the menu displayed in Figure 9.4. The menu items in Figure 9.4 are provided in a tree format; selecting an item consists of left clicking the text, corresponding to the leaves of the tree. If in the case [Import] a model instance already exists, then the user will be prompted whether to continue. If confirmed, the new model will be loaded and the existing model is lost. SMPS format means the standard SLP I/O format of Birge, Dempster, Gassmann, Gunn, King, and Wallace [6]. A stochastic model in SMPS format consists of three files. The CORE file (default extension cor) contains essentially the expected value problem, see Section 3.9.5, in the MPS format of IBM. The STOCH file (default extension sto) contains the location and probability distribution of the random entries. The TIME file (default extension tim) describes the decision stages structure. For deterministic LP’s, only the CORE file is needed. The default directory for these I/O operations is the directory specified as the SMPS directory, according to the present specification, see Section 2.3 on page 21. Please notice, that not all models handled by SLP–IOR can be exported in SMPS format. Concerning model type, the present standard is restricted to (multistage) recourse problems. Within the class of recourse problems, exporting a model instance is further restricted by the CHAPTER 9. BUILDING AN SLP MODEL 100 Figure 9.3: File menu: Browse model instances dependency structure of the random variables. The reason is, that in the SMPS representation random array entries and random variables coincide. In SLP–IOR randomness is represented in a more general way, by employing affine linear relations, as can e.g. be seen in Section 3.9, (3.47), on page 52. Anyhow, in the special case when random entries and random variables coincide, the model instance can be exported in SMPS format. Clicking the [SMPS Format] item under [Import Model Instance], results in popping up the form shown in Figure 9.5. CHAPTER 9. BUILDING AN SLP MODEL 101 Figure 9.4: File menu: Export/import of model instances Figure 9.5: Export/import: file selection The three fields in the form serve for entering the paths and filenames for the three SMPS files mentioned above. For deterministic LP problems, only the first field must be filled in. Instead of entering the filenames, this can also be done by browsing; simply click the <Browse> button which is located right to the corresponding field. The radio button group in the upper right part of the form is for specifying whether the model to be loaded is stochastic. Please don’t forget to click the appropriate radio button, in the case you are going to load a deterministic LP, otherwise SLP–IOR will try to look after the STOCH and TIME files. Frequently the three files have the same filename, i.e. they differ only in the extension. In such cases we suggest to select the core file first, by utilizing the <Browse> button; CHAPTER 9. BUILDING AN SLP MODEL 102 SLP–IOR will fill the other two fields automatically. Clicking the [SMPS Format] item under [Export Model Instance], results again in popping up the form shown in Figure 9.5 and behaves analogously as in the case of importing. In both cases the export/import operation will only be carried out, if you click the corresponding button in the bottom row of the form. The GAMS format means models written in the algebraic modeling language GAMS, see [8]. The default directory for these I/O operations is the directory specified as the GAMS model directory, according to the present specification, see Section 2.3 on page 21. This modeling language does not contain language elements for representing stochastic models. Therefore, in the present version only the following facility is available: deterministic LP models, written in the GAMS language and stored in a text file, can be imported for the purpose of creating stochastic variants of them. After clicking [GAMS Format], the usual Windows dialog for opening files appears. The model instance imported this way appears in SLP–IOR as a one stage deterministic LP. In order to build stochastic variants of it, it should first be transformed into an SLP model type, see Section 11.1.4. Restrictions concerning the GAMS model: • It must be a linear programming model. • The GAMS model file must contain both a “Model” statement like, e.g., Model iron /all/; and a solve statement, like, e.g., Solve iron using lp minimizing z;, with the Solve statement being the last statement in the file. This requirement is needed for SLP–IOR, in order to recognize the direction of optimization, as well as the objective variable. • The objective variable should appear in a single equation definition statement. It should be defined in a straight form, like e.g. obj.. Sum(j1, c1(j1)*X1(j1)) + Sum(j2, c2(j2)*X2(j2))=e=z;. 9.1.6 Exit Finally the item [Exit] serves for closing the current modeling session, clicking it will terminate the SLP–IOR run. 9.2 Main menu item: Edit–Model Selecting this main menu item results in a submenu as shown in Figure 9.6. CHAPTER 9. BUILDING AN SLP MODEL 103 Figure 9.6: Main menu item: Edit–Model The menu item [Edit Distribution on Scenario Tree] only shows up for multistage models with discrete distribution. For deterministic LP models the menu items concerning stochastic quantities are missing. Regarding integrated probability functions and CVaR functions, these may either be appearing in the constraints or in the objective, see Sections 3.5, 3.6, and 3.7. For these models the additional menu item [Constraint or Objective] appears, offering the choice between the two alternatives. If the Objective option is chosen, then the list of menu points will also contain [Objective Weights], enabling to choose the weights in the objective. 9.2.1 Name of Model Clicking this item results in popping up a query just asking for the name of the model instance. If you have access to GAMS, please make sure that the model name will be acceptable for GAMS, e.g. choose a letter for the first character in the name. CHAPTER 9. BUILDING AN SLP MODEL 9.2.2 104 Min or Max Clicking this pops up a simple pair of radio buttons for selecting the direction of optimization. 9.2.3 Number of Stages This item is for specifying the number of stages. Selecting it pops up a simple query for the number of stages. 9.2.4 Dimensions This item serves for specifying the number of rows and columns according to stages or w.r. to the chance–constraint; and for specifying the number of random variables. Clicking this item results in a form, where the dimensions can be specified in a straightforward manner. 9.2.5 Edit Data Arrays/Relations In general, this serves for editing the various arrays in the underlying LP of the model (for the underlying LP see Sections 3.3.4, 3.4.4, 3.9.4), 3.5.5, 3.6.5, 3.7.5, as well as for specifying the relations for the constraints. Clicking this item pops up the form as shown in Figure 9.7, for deterministic LP and for two– and multistage recourse models. For editing an array, please proceed as follows: The stage is to be selected first. This can be accomplished by clicking the name of the appropriate stage, in the list on the left–hand side part of the form. Doing this pops up at the right–hand side a list of arrays. The abbreviations for the arrays are those given in Chapter 3. Select an array by clicking the corresponding item in the list; this will result in displaying the array in the matrix editor, where the elements/entries can be updated. The matrix editor will separately be documented in Section 14.1. Clicking <Edit Relations> results again in popping up the editor, this time for specifying relations. Note, that the relations ≤, =, ≥ are to be entered as <, =, >, respectively. The button <Uniform Relations> implements a shortcut for the case, when all relations in the selected stage are the same. Clicking it sets all the relations according to the radio button group below the button <Uniform Relations>. CHAPTER 9. BUILDING AN SLP MODEL 105 Figure 9.7: Editing data arrays and relations I The button <View> provides an overview on dimensions and number of nonzeros of the blocks, as displayed in Figure 9.8. The numbers on the vertical and horizontal border line indicate stage dimensions for rows and columns, respectively. The numbers in the table are the number of nonzero elements in the corresponding blocks. For a model involving CVaR functions, the menu displayed in Figure 9.9 appears. In the right–hand–side now [alpha] and [gamma] also appear, in addition to [A[2,1]] and [b[2]], the latter standing for the matrix and right–hand–side in the stochastic part, respectively. [alpha] offers the facility of choosing the probability level, and [gamma] serves for editing the right–hand–side vector in the CVaR constraint. Notice that, also for the stochastic constraint, inequalities can be specified. These serve for defining the loss function to be used, for a detailed explanation see Sections 3.5.1, 3.6.1, and 3.7.1. Similar menus serve for models with integrated probability functions (ICC), for specifying data. For chance–constrained models [gamma] is missing whereas for integrated chance constraints [alpha], being superfluous, is not displayed. CHAPTER 9. BUILDING AN SLP MODEL Figure 9.8: Editing data arrays: overview Figure 9.9: Editing data arrays and relations II 106 CHAPTER 9. BUILDING AN SLP MODEL 9.2.6 107 Edit Names This feature serves for editing names of rows and columns, as well as for random variables. The form shown in Figure 9.10 pops up, after selecting this item. Figure 9.10: Editing names and relations: item selection The stage (or for chance–constrained models the chance constraint) is to be selected first. This can be accomplished by clicking the name of the appropriate stage/chance constraint, in the list on the left–hand side part of the form. After this, the item to be edited is to be selected, at the right–hand part of the form, by clicking the appropriate button. This results in popping up of the matrix editor, for carrying out the update. The matrix editor will separately be documented in Section 14.1. 9.2.7 Edit Underlying LP This menu serves for editing the underlying LP (see Sections 3.3.4, 3.4.4, 3.9.4, 3.12.4). The idea is to offer all matrix blocks, objective and RHS simultaneously for editing. The CHAPTER 9. BUILDING AN SLP MODEL 108 feature is especially useful in the multistage case for entering constraints which connect several stages. Choosing this menu item results in popping up the matrix editor, this time with the dataset of the underlying LP, as shown in Figure 9.11. For the matrix editor see Section 14.1. Figure 9.11: Models: editing the underlying LP The button <Recast> serves for a crossover to the recast menu, which serves for performing structural changes in the underlying LP, see Section 9.2.14 and Figure 9.21. 9.2.8 Stochastic Parts This item is for choosing the stochastic parts of a model. In the case of a two–stage recourse model, clicking it results in popping up of the form shown in Figure 9.12. For specifying/modifying stochastic parts please proceed as follows: The stage (or for chance–constrained models the chance constraint) is to be selected first. This can be accomplished by clicking the name of the appropriate stage/chance constraint, in the list on the left–hand side part of the form. Doing this pops up, at the right–hand side of the form, a list of arrays with check boxes. The abbreviations for the arrays are those given in Chapter 3. Select/deselect an array by clicking the corresponding checkbox. Selecting an array means that it will contain stochastic entries. CHAPTER 9. BUILDING AN SLP MODEL 109 Figure 9.12: Models: Stochastic parts 9.2.9 Pick Random Entries For the special case when random array entries and random variables coincide (there is a one–to–one correspondence between them), the regression arrays are simply unit arrays (arrays with a single nonzero which is 1). In this case, this facility provides a shortcut for pinpointing the random entries directly. This runs as follows: The first form which appears serves for selecting an array, where stochastic entries should be chosen. This is a similar array selection form, as described in Section 9.2.5; it is shown in Figure 9.13. Choosing an array here results in starting up the matrix editor (detailed description in Section 14.1). Double–clicking an array element with the left mouse button results in selecting it as a stochastic entry. This can be repeated with several array elements. A list of the selected elements arises, which is shown after each double–click. Clicking the <OK> button closes the selection procedure; clicking <Cancel> aborts the selection procedure for this array, and returns to the array selection menu. In the case <OK> has been clicked, the selected elements must afterwards be associated with random variables. This can be accomplished via the form which pops up, and is shown in Figure 9.14. There are two ways for establishing the correspondence; clicking the <Toggle> button CHAPTER 9. BUILDING AN SLP MODEL 110 Figure 9.13: Models: Array selection toggles between the two possibilities. In our case, clicking <Toggle> results in the form as shown in Figure 9.15. In the first way, as shown in Figure 9.14, for each random entry a new random variable will be introduced. In the specific problem there are already 5 random variables, therefore the random variable indices offered for the random entries are 6 and 7. Changes can be accomplished by directly entering the indices into the edit fields; the order of the indices can freely be chosen. The second possibility, shown in Figure 9.15, consists of associating the random entries with already existing random variables. In our case indices between 1 and 5 can be associated, in any order, with the random entries. In both cases, if you have made up your mind and do not want to have a selected entry random, simply enter 0 as random variable index. Clicking the <OK> button establishes the association. Please notice, that if you have chosen random entries in an array, which was not previously declared as stochastic part of CHAPTER 9. BUILDING AN SLP MODEL 111 Figure 9.14: Associating random entries to random variables I the model, see Section 9.2.8, then after this operation it will naturally become a stochastic part. SLP–IOR will not prevent you to associate the same random variable to several arrays; please take care of this if you wish a one–to–one correspondence. 9.2.10 Edit Regression Terms This facility serves for updating the arrays in the affine sums, which map the random variables onto random entries, as described e.g. in Section 3.9. For the mapping see (3.3) on page 31, (3.7) on page 34, (3.47) on page 52, and (3.67) on page 65. Clicking this item pops up the array selection form shown in Figure 9.13. Selecting an item by clicking the corresponding element in the list starts up the matrix editor, which offers the terms in the affine sums for editing, in turn for each of the random variables. The matrix editor will separately be documented in Section 14.1. CHAPTER 9. BUILDING AN SLP MODEL 112 Figure 9.15: Associating random entries to random variables II 9.2.11 Edit Dependency This menu item serves for specifying the dependency structure of the random vector ξ. Clicking it pops up a form shown in Figure 9.16. As explained e.g. in Section 3.3.2 on page 31, the random vector ξ is considered as being subdivided into mutually independent groups of random variables. The probability distribution is to be specified separately for the separate groups, see Section 9.2.12. For groups containing several random variables, this is the joint distribution for the group. In the case when a group consists of a single random variable, the distribution reduces to a univariate distribution. Nevertheless, SLP–IOR treats (and calls in the user queries) groups consisting of a single random variable as groups for the sake of uniformity. If the random variables are stochastically independent, then the number of groups equals the number of random variables and each group consists of a single random variable. Single group means that the number of groups is 1 and this group contains all random variables.The joint probability distribution is to be specified for the group. The radio button group on the left–hand side serves for selecting the dependency struc- CHAPTER 9. BUILDING AN SLP MODEL 113 Figure 9.16: Stochastic dependency structure ture. The list of groups at the right–hand side of the form shows the current group structure. When selecting the third item in the radio button group, the list of groups becomes editable, and two buttons are popping up. The groups can be selected as follows: Enter the same (arbitrary) name for random variables belonging to the same group, in a case insensitive manner. Please notice, that groups must consist of consecutive random variables. The buttons <Current Selection OK> and <OK> serve for accepting the current selection. Button <Clear Selection> clears the list of groups. In Figure 9.16 there are 5 random variables, partitioned into two groups. The first group consists of the first two random variables; the second contains the remaining 3 random variables. CHAPTER 9. BUILDING AN SLP MODEL 9.2.12 114 Edit Distribution The probability distribution for the groups of random variables can be specified via the form shown in Figure 9.17. Figure 9.17: Probability distribution The group is to be selected first, by clicking the name of the group in the list at the left–hand side of the form. This results in showing a list of available distributions, in the form of a tree menu, at the right–hand side of the form. The current distribution is distinguished by a different color. Selecting a distribution can be accomplished by clicking the distribution name, located at the leaves of the tree. As a consequence a query follows, concerning the distribution parameters. For the available distributions and their parameters see Chapter 15. The figure shows a case, with independent random variables, i.e. each group consists of a single random variable. In this case, the name of the random variables is shown in the list at the left–hand side (otherwise group identifiers appear there). On the right–hand CHAPTER 9. BUILDING AN SLP MODEL 115 side the univariate distributions are listed, because the selected “group” contains a single random variable. The dimension of the selected group as well as the current distribution is displayed also in a separate line below the list. For distributions with an unbounded support, a truncation probability level α, 0 < α < 1 must also be specified. This serves the following purpose: our implementation of successive discrete approximation methods requires a bounded support for the probability distribution, therefore, for discretization purposes (see Section 12.3.1) the support will be truncated at the specified probability level α. Please notice the toggle button <Edit/View>. Clicking this toggles between edit– and view mode. In view mode, after selecting a distribution, a graphical view is provided for univariate distributions; for the viewer see Section 14.3. 9.2.13 Edit Distribution on Scenario Tree This menu serves for editing the joint distribution on the scenario tree, for multistage recourse models with a finite discrete distribution. When selecting this item, the graphical editor shown in Figure 9.18 appears. When choosing in [File],→[Customize],→[Scenario Tree Editor] the option [Folder Tree Style], then the editor takes the form shown in Figure 9.19. As discussed in Section 3.12.7, realizations and probabilities are associated with the nodes of the tree. For selecting a node there are two possibilities: • A node is identified by two numbers: the stage to which it belongs and the sequence number within the stage. These can manually be entered in the edit boxes at the bottom of the form. Subsequently clicking <Edit Data> pops up the editor, shown in Figure 9.20, for editing data. • Right–clicking with the mouse nearby a node pops up a menu (in this case containing a single element), choosing this results again in appearing of the editor in Figure 9.20, with the data corresponding to the node. The editor serves for changing the realization and/or the probability of the realization, associated with the node. The changes are only carried out, when the button <Update> is clicked. Changing the realization or probability associated with the node has the following consequences: I Probability: the probabilities of all the nodes, having the same parent, as the node where the probability was changed, are normalized, such that their sum is the same, as before the change. Subsequently the probabilities associated to the subtrees, which are rooted at the nodes with changed probabilities, are also updated in order to maintain a valid overall scenario tree. CHAPTER 9. BUILDING AN SLP MODEL 116 Figure 9.18: Editing the probability distribution on the scenario tree I I Realization: this has no immediate effect. After saving the tree, and loading it again, it may happen, that the topology changes. The reason is this: assume, that for two nodes, having the same parent, the realizations associated with the two nodes were different before the change. When in the editor the realizations have been changed, such that now they are equal, then SLP–IOR will merge the two nodes and change the tree topology accordingly. I Realization and/or probability: let us assume, that the random variables are independent, or the random variable structure consists of mutually independent groups (see Sections 3.12.2 and 3.3.2), then changing the realizations and/or the probabilities most probably destroys this structure. Therefore, when the user clicks <OK> in the editor shown in Figure 9.18 (or 9.19), then SLP–IOR drops the information consisting of dependency groups, changes the dependency information to having a single group, and saves the joint distribution. Before doing this, however, the user gets a warning, and can make up her/his mind concerning saving the changes. CHAPTER 9. BUILDING AN SLP MODEL 117 Figure 9.19: Editing the probability distribution on the scenario tree II The button <Load> in Figure 9.20 serves for the following purpose: entering the sequence number of the current node and clicking this button loads the data of the corresponding node, for editing. The idea is to edit data, corresponding to nodes of the same stage, without returning to the graphical tree editor. 9.2.14 Recast Model This facility is for recasting the model instance, by moving or copying rows/columns within a stage or across stages (or to the chance constraint), as well as for deleting or inserting rows and columns pertaining to all stages. Selecting this menu item results in popping up the form shown in Figure 9.21. The button <Edit> serves for a crossover to editing the array elements of the underlying LP, see Section 9.2.7 and Figure 9.11. CHAPTER 9. BUILDING AN SLP MODEL 118 Figure 9.20: Editing node–data of a scenario tree Figure 9.21: Recasting a model instance A typical situation, where such a recasting is needed, is after importing an LP in GAMS format, see Section 9.1.5. After importing the model, a one–stage deterministic LP will be available in SLP–IOR for building stochastic variants. To achieve this, the model must first be transformed into a stochastic type, via [Ana- CHAPTER 9. BUILDING AN SLP MODEL 119 lyze],→[Transform Model], see Section 11.1.4. Selecting e.g. two–stage recourse (see Section 3.9) as the target type, the resulting model will contain in the first–stage matrix A the technology matrix of the imported LP and for the second stage the dimensions will be m2 = 1, n2 = 1 and zero matrices will be added for T and W . Most probably, some of the original rows of the LP should be moved into the second stage of the stochastic model. This can be accomplished with the facility we are discussing. We will discuss the usage of this facility for two–stage recourse models (see Section 3.9); for chance–constrained– and multistage recourse models it is analogous. For a two–stage recourse model the matrices A, T , and W are used to build the matrix ! A 0 T W which is displayed in the matrix editor. For a two–stage recourse model, this aggregate is shown in Figure 9.21. The desired operation is first to be chosen, using the two radio button groups situated above the matrix editor. In the group at the left–hand side, the operation can be chosen, whereas on the right–hand side it can be decided whether the operation should be performed on rows or on columns. The desired operation can afterwards be carried out as follows: • [INSERT zero] This can be accomplished by double–clicking as follows: – mark a field in the desired row/column as the active field, by a single left mouse click (the selected field becomes either blue or it will be lightly framed); – double click the field with the left mouse button. A zero row/column will be inserted after the row/column corresponding to the field which has been double clicked. [COPY] This can be accomplished by dragging as follows: – mark a field in the desired row/column as the active field, by a single left mouse click (the selected field becomes either blue or it will be lightly framed); – left click the name of the row/column which has to be copied and keep the mouse button pressed; – while keeping the left button pressed, move the cursor to the name of the row/column, after which the selected row/column should be copied. If the target column is outside the matrix viewport to the left, then while keeping the left mouse button pressed, move the cursor outside the matrix editor to CHAPTER 9. BUILDING AN SLP MODEL 120 the left. By applying small movements to the cursor, the matrix viewport will be scrolled. When the desired target column appears in the editor, move the cursor back to the name of the target column. – Release the left mouse button. The row/column which has been selected, when pressing the left mouse button, will be copied after the selected target row/column. [MOVE] This can be accomplished by dragging as follows: – mark a field in the desired row/column as the active field, by a single left mouse click (the selected field becomes either blue or it will be lightly framed); – left click the name of the row/column which is to be moved, and keep the mouse button pressed; – while keeping the left button pressed, move the cursor over the name of the row/column, after which the selected row/column should be moved. If the target column is outside the matrix viewport to the left, then while keeping the left mouse button pressed, move the cursor outside the matrix editor to the left. By applying small movements to the cursor, the matrix viewport will be scrolled. When the desired target column appears in the editor, move the cursor back over the name of the target column. – Release the left mouse button. The row/column, which has been selected when pressing the left mouse button, will be moved after the selected target row/column. • [DELETE] This can be accomplished by double–clicking as follows: – mark a field in the desired row/column as the active field, by a single left mouse click (the selected field becomes either blue or it will be lightly framed); – double click the field with the left mouse button. The row/column, corresponding to the field which has been double clicked, will be deleted. Before actually carrying out the operations, the user will be asked to confirm the operation first, for all of the four operations. Please notice, that the above described operations are carried out on the model as a whole. If e.g. the selected operation has been [MOVE] of a [Row], from the first stage to the second stage, then after carrying it out, the following changes on the model will take place: • The corresponding row will be deleted from matrix A along with the component of b; m1 will be decreased by 1. • The moved row will be inserted into matrix T and the corresponding component of b into RHS h, and m2 will be increased by 1. If the model is not a simple recourse CHAPTER 9. BUILDING AN SLP MODEL 121 model, then a zero row will be inserted into matrix W . For simple recourse models, the (I, −I) structure will be restored after the operation. If the selected operation has been [MOVE] of a [Row] within the second stage, then m2 remains the same, the operation is carried out analogously as before. If the second stage contained random entries, then the regression terms will also be transformed accordingly. If the selected operation has been [MOVE] of a [Row] from the second stage to the first stage then: • The corresponding row will be deleted from matrices T , W along with the component of h; m2 will be decreased by 1. • If the model is a simple recourse model then the (I, −I) structure will be restored after the operation. • If the second stage contained random entries corresponding this row, then the regression terms will also be transformed accordingly. • The moved row will be inserted into matrix A and the corresponding component of h into RHS b, and m1 will be increased by 1. The corresponding row of W will be lost. In general, if moving a row from a stage to a lower indexed stage, or moving a column from a stage to a higher indexed stage, parts of the moved arrays will be lost, because the lower block triangular structure is being kept. For the other operations [INSERT zero], [COPY], and [DELETE] the operation is carried out analogously throughout the whole model. 9.2.15 Building Blocks I This feature is designed for using the three underlying structures of an SLP model, as described in Chapter 3, as building blocks for models. Choosing this menu item pops up the form shown in Figure 9.22. Choosing an item in this tree shaped menu can be accomplished by clicking the appropriate name/expression at the leaves. [Extract and Save] means that a copy of the chosen structure will be extracted from the model instance and saved on disk. The default directory in the Windows SaveAs dialog is the Blackboard directory, see Section 2.3 on page 21. [Load and Replace] means that the chosen structure will be loaded from disk and injected into the current model. Please notice, that the original data corresponding to CHAPTER 9. BUILDING AN SLP MODEL 122 Figure 9.22: The underlying structures as building blocks the chosen structure will be replaced by the loaded data, the original data is being lost without warning. The default directory in the Windows Open dialog is the Blackboard directory, see Section 2.3 on page 21 on page 21. 9.2.16 Building Blocks II When choosing this item, a further selection list will be pulled down, as shown in Figure 9.23. Figure 9.23: Arrays as building blocks These facilities are for dealing with arrays as building blocks. Selecting one of the items results in popping up the array selection menu as shown in Figure 9.13. The desired array can be selected by clicking the corresponding element of the list. In the I/O operations involved the default directory is the Blackboard directory. The functionality is: CHAPTER 9. BUILDING AN SLP MODEL 123 • [Read Array] reads the selected array from disk and replaces the corresponding array with the array read without warning. • [Write Array] writes the selected array to disk. • [Append Array to Rows] reads the selected array from disk and appends it to the rows of the corresponding array without warning. The model dimension is changed accordingly. • [Append Array to Columns] reads the selected array from disk and appends it to the columns of the corresponding array without warning. The model dimension is changed accordingly. 9.3 Main menu item: View–Model Figure 9.24: Main menu item: View–Model 9.3.1 View Data Arrays The only difference between this item and [Edit Data Arrays] is, that in this case the matrix editor does not permit changing data array elements. In both cases the selected array’s nonzero pattern can be viewed by clicking a button in the matrix editor, see the documentation of the latter in Section 14.1. 9.3.2 View Underlying LP Structure Choosing this item results in showing the nonzero pattern of the underlying LP (see Sections 3.3.4, 3.4.4, 3.9.4) as shown in Figure 9.25. For a two–stage recourse model, an example of which is shown in the figure, the matrices A, T and W are used to build the matrix ! A 0 T W CHAPTER 9. BUILDING AN SLP MODEL 124 Figure 9.25: Nonzero pattern of the underlying LP the nonzero pattern of which is shown in the viewer. The viewer is documented in the separate Section 14.2. 1’s and -1’s are displayed using separate symbols; the circles correspond to general elements (neither 1 nor -1). The black lines show the decision stages boundary. 9.3.3 View Random Variables Map The mapping from random variables to random array entries is accomplished in SLP–IOR via affine linear relations, which we call regression terms, see e.g. Section 3.9, relations (3.47) on page 52. This viewer serves for displaying information, concerning the random array entries generated by the mapping. Clicking this menu item pops up the display shown in Figure 9.26. The display shows, for each random variable (a row in the table), the arrays where random entries emerge via the affine relations. The number in parentheses is the number of random entries attributed to the specific random variable. The particular example corresponds to a two–stage recourse model with 5 random variables. The first one, RV1, influences the second–stage RHS b[2] and the second–stage technology matrix A[2, 1]. The relations (3.47) on page 52 introduce 1 random entry in b[2] (h1 has a single nonzero entry) and 100 random entries in A[2, 1] (T 1 has 100 random entries). Clicking <View stochastic parts> results in showing a second display, see Figure 9.27. This figure shows the matrix blocks of the model, where the stochastic parts (blocks containing stochastic entries) are distinguished by displaying the number of random entries in red. Please notice, that a random entry may be influenced by several random variables, according to (3.47) on page 52; the display shows the number of random entries, i.e. for a specific random entry multiple random variable influence counts just once. Please notice, that in this model instance the random vector ξ is 5–dimensional; but the number of random entries in the model instance is 331. CHAPTER 9. BUILDING AN SLP MODEL 125 Figure 9.26: Random variables versus random arrays Figure 9.27: The number of random entries in arrays 9.3.4 View Scenario Tree This serves for viewing the joint distribution as associated to the nodes of the scenario tree. For using this facility see Section 9.2.13. CHAPTER 9. BUILDING AN SLP MODEL 126 Chapter 10 Solving an SLP model 10.1 Main menu item: Solve The submenu items corresponding to this main menu item are shown in Figure 10.1. Figure 10.1: Main menu item: Solve I The items will be explained in subsequent sections. 10.1.1 Solve current problem This menu item serves for carrying out a solver run. If no solver has been selected so far, then the solver selection list is displayed first, (see Section 10.1.2) for choosing a solver. Having a current solver, SLP–IOR performs the following steps: Step 1. The current model instance data is written into a data file, according to the specifications in the solver description database, see Section 16.3.6. Step 2. The user is asked to update run time control parameters. This is accomplished by the menu shown in Figure 10.2. 127 CHAPTER 10. SOLVING AN SLP MODEL 128 Figure 10.2: Solver: run time parameters The table contains the solver’s run time (control) parameters, as specified in the solver description database, see Sections 16.3.7 and 16.3.8, preceded by the maximum number of iterations and maximum solution time in seconds. The updated information is written into a text file, with filename TheSolver.par, where TheSolver is the name of the current solver. The format is as follows: • The integer parameters (if any) come first. 8 numbers are written per record; the field length for a single number is 8; the numbers are right justified within the fields. • The real parameters (if any) come next, beginning with a new record. 3 numbers are written per record in floating point format; field length for a single number is 20. The numbers are right justified. • The maximum number of iterations and the maximum solution time in seconds is written in integer format in a separate record; field length is 8; the numbers are right justified. If the solver requires an option or specification file, this can be edited by clicking the button <Edit>. The updated data is written into a text file, as specified in the solver CHAPTER 10. SOLVING AN SLP MODEL 129 description database, Section 16.3.7. When selecting [Warm start], then SLP–IOR writes a text file with file name TheSolver.hot, where TheSolver is the name of the current solver. The format is as follows: The dimension of the first–stage variables comes first in integer format, field length 10, right justified. Starting in a separate record, the current first–stage solution follows; one real number per record; field length 20; right justified. Zeros will also be written. The switch [Current values] means, that the parameters shown in the table come from the last run (if any) in the current session; [Default values] means, that the default values are reloaded from the database. Step 3. Clicking <Run solver> starts up the solver; control is passed to the solver and SLP–IOR waits for solver termination. For a premature termination of the solver, press <Ctrl>–<c>. Clicking <Cancel run> means that the solver startup is cancelled and the system returns to the main menu. Step 4. After solver termination SLP–IOR tries to retrieve the results. First it looks whether the text file, with file name TheSolver.inf, with TheSolver being the name of the current solver, exists. For this file see Section 16.2. If it does not exist, then an error message is displayed, otherwise the results file according to filename specified in the solver description database (see Sectionssec:sio) will be read. 10.1.2 Select Solver As explained in the previous section, when no solver has been selected so far, the solver selection menu automatically appears. If the User wishes to switch to another solver, this can be accomplished via this menu item. When clicking this item a list of solvers shows up. This list consists of those solvers, which are considered by SLP–IOR as appropriate for the current model instance. The basis of selection is the solver description database, see Section 16.3. The solvers are listed in a lexicographic order of their names; i.e. no specific recommendation to the user is included. Selection from this list occurs by clicking the check box situated to the left of the solver’s name. 10.1.3 View Results The results returned by the solver can be viewed here, see Figure 10.3. In this example, the results correspond to a two–stage simple recourse problem. In the heading the overall– and first–stage objective values are displayed. As the solver (SRAP- CHAPTER 10. SOLVING AN SLP MODEL 130 Figure 10.3: Solve: viewing results I PROX) returned lower and upper bounds on the optimal objective value, these bounds are also displayed. The solver has returned only the first–stage primal solution. This can be viewed by clicking first the stage in the list at the left–hand part of the sheet first, and afterwards the checkbox corresponding to the solution, at the right–hand side of the sheet. The solution will be shown in the matrix editor. If the solver returns solutions to other stages as well, or the dual solution is also available, these can be viewed analogously. Button <Compute recourse solution> is intended for the case with finite discretely distributed random variables. In this case, clicking this button results in computing the recourse solution, which is then available for viewing/saving afterwards. Doing this, results in the display in Figure 10.4. The first column in the display at the top part shows, as before, the values returned by the solver. To the right to it, the recomputed values are shown. CHAPTER 10. SOLVING AN SLP MODEL 131 Figure 10.4: Solve: viewing results II 10.1.4 View Solution on Tree For multistage recourse models with finite discrete distribution the solution, appropriately partitioned, can also be associated to the nodes of the scenario tree (see Section 3.12.8). The same graphical editor appears, when choosing this item, as shown in Figures 9.19 and 9.19, in Section 9.2.13. This time the solution can be viewed utilizing them. 10.1.5 Edit Solution This serves for editing, saving, and loading the selected part of the solution. Figure 10.5 displays the menu, which appears. The desired activity can be chosen via the radio button group on the form. When editing has been chosen, the matrix editor appear, otherwise the usual Windows dialogs pop up for the I/O operation. 10.1.6 Summary on Run Choosing this menu item shows a summary of the latest run. CHAPTER 10. SOLVING AN SLP MODEL 132 Figure 10.5: Solve: editing the solution 10.1.7 Solver Files This item appears in the pulled down menu, if the current solver produced additional files, as described in Section 16.3. In this case, clicking this item shows a submenu for selecting a file, as displayed in Figure 10.6. When selecting one of these items, the content of the corresponding file will be displayed on the screen. 10.1.8 View GAMS listing This item appears (see Figure 10.7) only when a GAMS solver was running. When selecting it, the contents of the GAMS listing file will be displayed. CHAPTER 10. SOLVING AN SLP MODEL Figure 10.6: Main menu item: Solve II Figure 10.7: Main menu item: Solve III 133 Chapter 11 Analyzing the model instance and the solution 11.1 Main menu item: Analyze This main menu item covers the features shown in Figure 11.1. Figure 11.1: Main menu item: Analyze 11.1.1 Analyze Model Instance This encompasses several analysis facilities as shown in Figure 11.2. The facilities located on this form are currently only available for recourse problems. The computations can be carried out in one of two modes; changing between modes can be accomplished by clicking <Toggle Evaluate/Simulate>. The two modes are the following: • Complete evaluation is only available for finite discrete distributions. In this mode, all quantities are computed exactly (in the numerical sense). 134 CHAPTER 11. ANALYZING THE MODEL INSTANCE AND THE SOLUTION 135 Figure 11.2: Analyze model instance • Simulation is available for all distributions, which are in the scope of SLP–IOR. In this case, the computations are carried out via simulation. The sample size and seeds can be updated in the edit boxes, situated at the lower–left corner, below the toggle button. The facilities located at the upper part of the form serve for computing various indicators: • EV: computing the solution of the expected value problem, see Section 3.9.5. • WS: computing the wait–and–see solution, see Section 3.9.7. • RS : compute the recourse solution. In the Complete evaluation mode, choosing this facility leads to the solution dialog as described in Section 10.1, and starting up a solver. In the Simulation mode, a sample is computed and the Monte–Carlo approximation to the SLP problem is being set up and solved. • EEV: computing the expected result, see Section 3.9.8 for explanation. CHAPTER 11. ANALYZING THE MODEL INSTANCE AND THE SOLUTION 136 Having computed the above quantities, EVPI and VSS (see Section 3.9.9) are displayed at the upper–right part of the sheet. Starting up the computation can be carried out by clicking the corresponding “calculator” button, located at the left of the facility name. The computed solutions can be viewed/saved by clicking the button, located at the right of the facility name. For WS an additional button is also located right. Clicking this shows a basic statistics concerning the optimal objective values of the separate scenario–solutions. At the bottom part there is a button <Clear> which serves for clearing the display boxes. The second group of facilities consist of various checks. The following properties of the model instance can be checked: • <Check Complete Recourse> This is for checking whether the model instance has the complete recourse property; for the algorithm see Kall [27] or Kall and Wallace [43]. • <Check Simple Recourse> This facility serves for checking whether the model has simple recourse. For larger models, this may not be immediately clear, due e.g. to inequalities in the second stage; the algorithm is straightforward: it is checked, whether it is possible to achieve a simple recourse structure, by changing the ordering of the rows and columns and by introducing surplus and slack variables. • <Check Stagewise Independence> This is for multistage recourse, for the definition of the property see Section 3.12.2. • <Check Block–Separable Recourse> This facility is also for multistage recourse, for the definition of the property see Section 3.12.11. 11.1.2 Analyze solutions This means analyzing first–stage solutions. The vector called first–stage solution in this section means any vector, which has the dimension of the first–stage solution; see Figure 11.3 The first–stage solution from a solver run, or the first stage–part of the solution of the expected–value problem, can be chosen as such a vector, via the buttons, situated at the upper–left part of the form. The current first–stage solution can be changed/loaded/saved by clicking the button at the central part of the sheet. The following facilities are currently available: CHAPTER 11. ANALYZING THE MODEL INSTANCE AND THE SOLUTION 137 Figure 11.3: Analyze first–stage solutions • Computing the objective value means computing the objective value corresponding to the chosen first–stage solution. The facility is located at the upper–right part of the form. • Computing the reliability of the solution makes sense, if all relations in the second stage are inequalities. In this case it means the probability of the event, that no recourse actions will be needed, see Section 3.9.10. Let us notice, that in the case when the first–stage part of an optimal solution has been chosen, then this quantity contributes also to the analysis of the model. The facility is located at the lower–right part of the form, and is only available for two–stage recourse problems. With relatively incomplete recourse it may happen, that parts of the computations can not be carried out, due to infeasibility. CHAPTER 11. ANALYZING THE MODEL INSTANCE AND THE SOLUTION 138 The computations can be carried out in one of two modes; changing between modes can be accomplished by clicking <Toggle Evaluate/Simulate>. The two modes are the following: • Complete evaluation is only available for finite discrete distributions. In this mode, all quantities are computed exactly (in the numerical sense). • Simulation is available for all distributions, which are in the scope of SLP–IOR. In this case, the computations are carried out via simulation. The sample size and seeds can be updated in the edit boxes, situated at the lower–left corner, below the toggle button. 11.1.3 Some further analysis facilities These concern the separate arrays in the model and can be found in Section 12.2. 11.1.4 Transform Model Transformation means here the following: the current model instance will be transformed into an instance of another, user selected model type. When choosing this menu item, a tree structured menu similar to that in Figure 9.2 appears. Selecting an item consist of left clicking the text corresponding to the leaves of the tree. This allows for selecting any of the stochastic model types displayed in Figure 9.2 . The deterministic target model types can be seen in Figure 11.4. Figure 11.4: Transform: deterministic target types The meaning is the following: • [One stage LP] this LP arises as follows: the underlying LP problem (see Sections 3.3.4, 3.4.4, 3.9.4) is constructed first. The periods– or chance–constrained structure is afterwards dropped and a one stage LP is built. One stage LP means, that SLP– IOR does not permit later on to make a multistage model out of this model by simply increasing the number of stages. CHAPTER 11. ANALYZING THE MODEL INSTANCE AND THE SOLUTION 139 • [Multistage LP] this LP arises as follows: the underlying LP problem, as before, is constructed first. The periods are kept and a multistage LP is being built. For a one stage deterministic original, this just means that for the transformed model the number of stages can later on be increased. • [Expected value problem] This is the expected value LP as documented in Sections 3.3.5, 3.4.5, 3.9.5, 3.5.6, 3.6.6, 3.7.6. • [Underlying LP] This is the underlying LP problem as documented in Sections 3.3.4, 3.4.4, 3.9.4, 3.5.5, 3.6.5, 3.7.5. • [Algebraic equivalent] This is the algebraic equivalent LP provided it exists, as described in Sections 3.4.6, 3.9.6, 3.5.7, 3.6.7, 3.7.7. Chapter 12 Modeling tools 12.1 Main menu item: Algeb–Equi This main menu item serves for dealing with the algebraic equivalent LP, provided it exists, and covers the features shown in Figure 12.1. For the algebraic equivalents see Sections 3.4.6 and 3.9.6; and for the multistage case Section 3.12.8. Figure 12.1: Main menu item: Algeb–Equi This facility serves for building the algebraic equivalent LP, provided it exists, for the purpose of editing it, viewing the nonzero pattern (see Section 14.1 on the matrix editor), or for exporting it in MPS format, e.g. for solving it with external LP solvers. The menu items are supposed to be self explaining: If there is no algebraic equivalent, then a message notifies the user that the equivalent does not exist. Otherwise: When clicking [Build Algebraic Equivalent], then either the equivalent LP will be built, if there is only one to choose, otherwise a submenu appears for choosing between the variants, and the LP will be built after this. Choosing [Edit It] starts up the matrix editor (Section 14.1); [Drop It] drops the equivalent LP for memory saving reasons (it can be quite large). Finally [Write MPS File] writes the LP into file in MPS format; the standard Windows SaveAs dialog appears. 140 CHAPTER 12. MODELING TOOLS 12.2 141 Main menu item: Algeb–Struct These facilities serve for dealing with the main constituents of the underlying algebraic structure: the individual arrays. When choosing this facility, the subitems displayed in Figure 12.2 become available. Figure 12.2: Main menu item: Algeb–Struct 12.2.1 Perturbing an array The first menu item [Perturb Array] serves for imposing a random perturbation on the elements of an array. The form shown in Figure 12.3 appears. Figure 12.3: Main menu item: Perturb array CHAPTER 12. MODELING TOOLS 142 The array to be perturbed can be chosen by clicking <Select array>; the standard array selection form, as shown in Figure 9.13 will appear. The radio button group at the left hand part serves to choose, how the perturbation should be carried out. • Nonzero positions means that perturbation will only be carried out on nonzero elements. Please notice, that 1’s and -1’s are considered as structural elements in this respect, and they will not be perturbed. If the array consist solely of 1’s and -1’s, then there occurs no perturbation at all. • Arbitrary positions means that the positions, where perturbation will be imposed, will randomly be chosen, according to the uniform distribution on row– and column indices. The density of perturbed elements can be selected at the right hand side part of the form. Density of perturbed elements means the following: let the array dimension be (m × n), let k be the number of elements perturbed and let d be the density to be specified. Then the following relation holds: k · 100. d= m·n The density only comes into play, if Arbitrary positions is the selected item in the radio button group. The distribution, according to which the perturbation will be carried out, can be chosen by clicking <Select distribution>. The standard distribution selection tree shaped menu, as discussed in Section 9.2.12, will appear, with univariate distributions. For the available distributions and sampling methods see Chapter 15. The perturbation will be carried out, when clicking the button <Perturb>, at the bottom row of the form. The following operations will be carried out: a sequence of pseudo random random variates will be generated, which will be added to the current value in the selected positions of the array. If Arbitrary positions have been chosen, then the position itself will also randomly be generated, according to the uniform distribution. The perturbed arrays can be edited/inspected afterwards under [Edit–Model] or [View– Model]. 12.2.2 Compute rank of an array The array selection form, as discussed in Section 9.2.12 will appear. For the chosen array, the rank will be computed and shown in a simple dialog box on the screen. 12.2.3 Check for complete recourse As for the previous item, the array selection form, (discussed in Section 9.2.12) will appear. The chosen array will be checked, whether it has the complete recourse property. The user will be informed via a simple message on the screen. CHAPTER 12. MODELING TOOLS 12.3 143 Main menu item: Rand–Vars The main purpose of the tools belonging to this menu item is the discretization of the distribution of the random variables. We will refer to this operation in the sequel as discretization of the random variables. The subitems shown in Figure 12.4 belong to it. Figure 12.4: Main menu item: Rand–Vars 12.3.1 Sample/Discretize per Group Choosing [Sample/Discretize per Group] results in popping up of the form displayed in Figure 12.5. The form consists of three main parts. At the leftmost part the random variable or group, which is to be discretized, can be selected (a group is a group of random variables the joint distribution of which is specified, see e.g. Section 3.3.2). At the central part, entitled as Sample, facilities related to sampling are located. The part at the right hand side, entitled as Empirical, serves for carrying out the discretization which results in an empirical distribution. Assuming that the random variable/group has been selected, and a sample has been computed, the discretization is carried out as follows: The support, possibly truncated at a given probability level (see Section 9.2.12) and represented as an interval, is partitioned according to user specification. Based on the sample and the subdivision of the support, an empirical distribution is being built as described below. The number of realization equals the number of subintervals. This is to be understood in the multidimensional sense. Considering, e.g., a 2–dimensional group of random variables, and choosing 5 intervals for each of them, results in 25 realizations for the group. The overall number of realizations is the product of the number of realizations for the CHAPTER 12. MODELING TOOLS 144 Figure 12.5: Discretizing the distribution per group individual groups. The realization corresponding to a subinterval is the arithmetic mean of sample elements falling into the specific subinterval; the probability assigned to this realization is the relative frequency of hitting the subinterval. This construction consists basically in assigning conditional expectations and probabilities to subintervals, as estimated from the sample. The intended sequence of actions is as follows: I Choose a random variable/group; I compute a sample using the tools under [Sample]; I build an empirical distribution utilizing the facilities under [Empirical]. Selecting a random variable/group can be performed by clicking the name of it in the list at the left hand part of the form. The Sample list of activities at the central part of the form can be used by simply clicking the list element corresponding to the desired activity. As a result, the selected activity will be carried out. The items in the list have the following functionality: CHAPTER 12. MODELING TOOLS 145 • [Edit Support] means, in the case of an unbounded support, truncating the support. The form shown in Figure 12.6 appears. The truncation probability is to be specified first. Subsequently clicking the ButtonCompute button results in computing the corresponding truncated interval. The interval, corresponding to the truncation on the specified probability level, is displayed in the edit boxes. The facility merely has a display function for distributions with a bounded support. • [Compute] computes the sample according to the specifications below the radio button group. • [Retrieve], [Save], [Edit], [View] are the activities indicated by their name w.r. to the current sample. • [Mean and Sdev] results in computing and showing the mean and standard deviation of the sample. Figure 12.6: Editing the support The parameters controlling the sampling procedure can be specified in the edit boxes below the radio buttons. For the sampling methods, employed for the various distributions, see Chapter 15. The Empirical list of activities at the right–hand–side of the form can be used by simply clicking the list element corresponding to the desired activity. As a result, the selected activity will be carried out. The items in the list have the following functionality: • [Edit Subdivision] serves for specifying the subdivision of the support. For groups containing several random variables this is done for each member of the group, in CHAPTER 12. MODELING TOOLS 146 Figure 12.7: Editing the subdivision of the support turn. The form displayed in Figure 12.7 pops up. The picture with black background shows the current subdivision points. When moving the cursor over this picture, the edit window above it shows the actual coordinate, corresponding to the current cursor position. The cursor assumes the form of a cross +, if over the picture; see Figure 12.7. The table below the picture shows the coordinates of the subdivision points along with the two endpoints. Double–clicking a field in this table results in changing the corresponding mark on the line to a small filled rectangle. Please notice, that for this the field must be clicked, otherwise the blue (current) field in the table does not correspond to the small rectangle in the picture. Besides displaying the current subdivision, the table may also serve for entering subdivision points. For making the table values the current subdivision points, the CHAPTER 12. MODELING TOOLS 147 button <Take Data From Table> must be clicked, though. There are three ways (and possibly combinations) for specifying the subdivision: – An equidistant subdivision can be specified, by first entering the number of subintervals into the edit box below the picture, and subsequently clicking the button <Compute Equidistant>. The subdivision will be computed and the subdivision points will be shown in the picture and table. – Clicking the white line at the desired position. Please notice, that while moving the cursor above the picture, the actual coordinate corresponding to the cursor position is shown in the edit box above the picture. Clicking the line introduces a new subdivision point, the table and the number of intervals are updated accordingly. – The third possibility is to change the values in the table, and subsequently clicking <Take Data From Table>. This mainly serves for updating existing subdivision points. Introducing a new point can be carried out by first creating it at an approximate position by clicking the line, and correcting the value afterwards in the table (do not forget to click <Take Data From Table> afterwards). Please note, that when clicking the <OK> button, the subdivision displayed in the table will be taken as the current subdivision. • [Draw] serves for carrying out the discretization. • [Retrieve], [Save], [Edit], [View] are the activities indicated by their name w.r. to the discretized distribution. • [Mean and Sdev] results in computing and showing the mean and standard deviation of the discretized distribution. 12.3.2 Sample/Discretize All This facility serves for carrying out the discretization in a uniform manner, for all random variables simultaneously. Choosing this results in popping up of the form displayed in Figure 12.8. Besides the seeds, the quantities which can be specified by the user are the sample size and number of subintervals, for each of the random variables/groups. Clicking <Compute> results in carrying out the discretization for all of the random variables/groups. 12.3.3 Manually Build Scenario Tree This is only for multistage recourse problems with finite discrete distribution. It can be used for manually setting up the scenario tree, or for manual changes in the topology of CHAPTER 12. MODELING TOOLS 148 Figure 12.8: Discretizing all random variables/groups an existing tree. The graphical editor shown in Figure 12.9 appears. The tree topology can be changed in a node–oriented fashion. The node can be selected by right–clicking nearby the node, which pops up a selection menu, as shown in the figure. The following activities are available: • [Add Child] means, that starting from the selected node, a new node–to–leaf path will be added. This introduces a new leaf into the tree. • [Split Node] means the following: a new child is added to the selected node’s parent, and the subtree rooted in the selected node is copied at the newly added child. • [Cut Branch] does the following: the selected node, together with the subtree rooted at it, is deleted among the children of the parent node. Performing these operations is accompanied with appropriate updates of probabilities, in order to keep the tree a valid scenario tree. There are two further facilities on this form, for generating trees of a special structure. I Balanced tree is a tree, where each node in the same stage has the same number of children. The topology of such a tree can be specified by listing the number of children CHAPTER 12. MODELING TOOLS 149 Figure 12.9: Build a scenario tree manually according to stages (except of the last stage). This can be done in the edit box entitled as “Mask”, at the bottom–right part of the form; the elements in this list should be separated by ‘/’–characters. The figure shows the specification of a balanced tree, where the root has two children, and each node in the second stage has two children, too. Clicking <Create BTree> results in creating the balanced tree. I Fan tree is a tree, where, apart of the root, each node has a single child. Such a tree is completely specified by specifying the number of children of the root. This can be done in the edit box with the title “Number of Fans”, situated above the facility for the balanced tree. Clicking <Create FTree> results in creating the fan tree. There are two further buttons at the upper–right part of the form. These make only sense for larger trees. Clicking <Show Topology> results in a graphical view (and serves only for viewing), where the whole tree is fitted into the viewport. Clicking <Show/Edit Tree> sets the viewport again in editing mode. In this mode, if the tree does not fit CHAPTER 12. MODELING TOOLS 150 into the viewport, scrollbars appear for navigating over the tree. 12.3.4 Generate Scenarios – Discretization This is only for multistage recourse problems. The idea is the following: a sample is generated according to the joint distribution first. Subsequently the overall random vector is considered as partitioned according to the stages. For each of these subvectors the rectangle containing the support is subdivided, and based on the sample, an empirical distribution is being built, according to the subdivision. When choosing this item, the menu shown in Figure 12.10 appears. Figure 12.10: Scenario generation: discretization via sampling The samplesize and seeds to be specified are with respect to the sampling mentioned above. In the list at the left–hand–part the user is asked to enter, in a stagewise manner, the number of subintervals for the separate random variables belonging to that stage. If there are two random variables in stage 2 and 2 random variables in stage 3, then the setting shown in Figure 12.10 will result in a tree with 100 leaves (scenarios). (Provided that the samplesize is big enough.) CHAPTER 12. MODELING TOOLS 12.3.5 151 Generate Scenarios – Moments This is only for multistage recourse problems. The basic tool for generating scenarios is a tool, designed to generate discretely distributed random vectors with the following quantities prescribed: the number and probability of realizations, the first (maximally) four central moments, and the correlation matrix. We have implemented the algorithm of Hoyland, Kaut, and Wallace [22]. The scenario generation runs in a root–to–leaf fashion. The starting tree consists of a single root–to–node path, as shown in Figure 12.11. Figure 12.11: Scenario generation: starting tree In this situation we have generated, using the tool to be described later, three scenarios. This results in the tree in Figure 12.12. CHAPTER 12. MODELING TOOLS 152 Figure 12.12: Scenario generation: the first tree generated Selecting the node as shown in the figure, and generating two scenarios, results in the next tree, shown in Figure 12.13. Finally, generating 3 scenarios at the node shown in the figure, results in a tree in Figure 12.14. IMPORTANT: in each step in the above procedure select such a node for further processing, for which the subtree, rooted at this node, consist of a single path to a leaf. CHAPTER 12. MODELING TOOLS Figure 12.13: Scenario generation: the second tree generated 153 CHAPTER 12. MODELING TOOLS Figure 12.14: Scenario generation: the third tree generated 154 CHAPTER 12. MODELING TOOLS 12.3.6 155 Generating random vectors with prescribed moments This tool serves for the following purpose: a finite discrete distribution of a random vector is to be generated, with the following quantities being prescribed: • The number of realizations; • the probabilities of the realizations; • the marginal central moments, (maximally) up to the fourth; • the correlation matrix. We have implemented the heuristic algorithm of Hoyland, Kaut, and Wallace [22] for generating an approximate solution to the problem above. The program is integrated into SLP–IOR. Starting up the generator, the main menu as shown in Figure 12.15 appears, where we have already clicked the [File] main menu item of the generator. Figure 12.15: Random vector generator: the File menu [Save] serves for saving the settings (e.g., marginal moments) and the generated scenarios, if any. [Return and Use Generated Data] should be chosen, if the generated distribution is to be integrated into the scenario tree. If this is not the case, choose [Return and Skip Generated Data]. The reason for these two options is, that the generator might be used for simply generating the distribution of the random vector, saving it for other purposes, and returning to the [Generate Scenarios – Moments] without changing CHAPTER 12. MODELING TOOLS 156 the tree. Figure 12.16 shows the submenus of [Edit]. Figure 12.16: Random vector generator: the Edit menu [Number of Scenarios] serves for specifying the number of realizations; [Distribution Data] is for specifying the probabilities and moments, to be prescribed. The latter submenu is shown in Figure 12.17. The button <Rand. Gener.> served for randomly generating input data in the development phase of the generator. The point is, that for arbitrarily chosen marginal moments, probabilities and correlation matrix there does not always exist a distribution with these properties. We have kept this feature, for further–testing purposes of the generator. The menu item [Generate] has a single subitem [Compute Scenarios]. Clicking this starts up computing the scenarios. The results can be viewed according to the submenus of [Results], shown in Figure 12.18. [Summary] provides summary tables on the deviations from the target, and information concerning the behavior of the algorithm in this run. [Moments] shows the target and computed moments, the latter as returned by the algorithm. CHAPTER 12. MODELING TOOLS 157 Figure 12.17: Random vector generator: specifying data Figure 12.18: Random vector generator: viewing results [Scenarios] shows the recomputed moments, i.e., they are computed from the generated distribution directly, as well as the generated distribution itself. CHAPTER 12. MODELING TOOLS 158 The menu item [Options] has the subitems as shown in Figure 12.19. Figure 12.19: Random vector generator: options [Targets] serves for selecting the target properties, e.g., only moments up to order three should be prescribed. It is shown in Figure 12.20. Figure 12.20: Random vector generator: choosing the targets CHAPTER 12. MODELING TOOLS 159 The remaining options in Figure 12.19: [Algorithm]: run–time parameters of the algorithm; [Random Seed]: setting it; [Randomly generated input data]: is for setting parameters for the experimental facility mentioned above. Chapter 13 Workbench for testing solvers 13.1 Main menu item: Workbench These facilities serve for dealing with test problem batteries and they encompass the items shown in Figure 13.1. Figure 13.1: Main menu item: Workbench 13.1.1 GENSLP: LP and recourse problems This is a further developed version of GENSLP of Kall and Keller [44], a generator for randomly generating two–stage recourse problems. The form displayed in Figure 13.2 appears on the screen. The form consists of two main parts: a main menu line for specifying various characteristics of the batteries and several features which can be specified on the main form. Having completely specified the battery, clicking <Generate> on the bottom line starts up the generator. The (S)LP problems generated will be stored in the test problem directory, as specified under [Options], see Section 2.3. The facility serves for generating deterministic LP– and SLP recourse problems. For LP problems and for complete recourse problems the existence of the solution is guaranteed. Switching between deterministic and stochastic problems can be accomplished via the 160 CHAPTER 13. WORKBENCH FOR TESTING SOLVERS 161 Figure 13.2: GENSLP: randomly generating recourse problems radio button group on the lower left–hand side of the form. GENSLP can also be used to generate multistage problems. The number of stages can be specified by the corresponding edit box. The number of test problems in the battery can be entered in the corresponding edit box. Base name of battery has the following meaning: the names of the test problems will be constructed by appending the base name with a sequence number, in the order of generation. The filenames will be the test problem names with slm extension. Now let us discuss the menu items: • [Dimensions] is for specifying the problem dimensions. Selecting this item results in popping up the standard dimension specification menu, as discussed in Section 9.2.4. • [Densities] serves for prescribing the nonzero density of the various arrays, via the form shown in Figure 13.3. The figure shows the default specification for two–stage recourse problems. The desired densities can simply be entered into this table; please notice, that they should be specified as percents. The row and column headings CHAPTER 13. WORKBENCH FOR TESTING SOLVERS 162 St1, St2 indicate stages. The white area in the table corresponds to matrix blocks. Figure 13.3: GENSLP: specifying nonzero densities • [Magnitudes] serves for specifying the magnitudes of the array entries, i.e. upper bounds on the absolute value of the entries. The specification can be carried out via a form analogous to that shown in Figure 13.3. • [Signs] is for the following purpose: the sign of the entries can be prescribed. A sheet similar to that displayed in Figure 13.3 appears. Enter 1, 2 or 3 for arbitrary, nonnegative or non–positive entries, respectively. • [MatrTypes] serves for specifying the type of the matrix blocks, via a form similar to Figure 13.3. The codes which can be entered are as follows: – 0 means arbitrary matrix. – 1 stands for a matrix with full rank. – 2 indicates complete recourse. In this case the number of columns in the recourse matrix has to exceed the number of rows by at least one. The generation method is based on a theorem of Kall [27], see also [43]. – 3 indicates simple recourse. • [StochParts] serves for indicating stochastic blocks (arrays). Enter 0 for deterministic and 1 for stochastic, respectively. • [RegrType] is for controlling the way, in which random variables are mapped into stochastic array entries via the affine sums, see in Section 3.9 relations (3.47). We will discuss the two–stage case, the multistage case is analogous. Let us consider CHAPTER 13. WORKBENCH FOR TESTING SOLVERS 163 the case, when T (ξ) is stochastic; for the other arrays the meaning is similar. The affine relation is r X T (ξ) = T̄ + T̄ j ξj j=1 The idea is to prescribe the nonzero pattern of T̄ j , (j ≥ 1), relative to the nonzero pattern of the constant term T̄ . The codes are as follows: – 0 means arbitrary pattern for T̄ j , (j ≥ 1). – 1 indicates that the nonzero pattern of T̄ j is the same for ∀j ≥ 1. This pattern has no relation to the nonzero pattern of T̄ . – 2 means, that the nonzero pattern of T̄ j is the same as that of T̄ , ∀j ≥ 1. – 3 indicates, that the nonzero pattern of T̄ j is a subset of that of T̄ , ∀j ≥ 1. – 4 prescribes, that the nonzero pattern of T̄ j should be a superset of that of T̄ , ∀j ≥ 1. – 5 requires, that T̄ j should be unit arrays, ∀j ≥ 1. Unit array in this case means a matrix having as the single nonzero a 1 on the diagonal. If the dimension of ξ permits it, GENSLP will try to arrange these unit arrays in such a way, that a one–to–one correspondence between random variables and array entries is established. • [RegrData] shows only up, when in the previous form the regression type has been different from 5, for at least one of the blocks. It serves for prescribing the density, magnitude and sign of the terms T̄ j , ∀j ≥ 1. The same menus will be popped up, as for the corresponding items discussed above. Please note, that the forms permit entering numbers and codes for all blocks, but only those will be taken into account, which are relevant to the specifications entered previously. For complete recourse problems the existence of the solution is guaranteed, see Mayer [56]. Please notice, that the problems generated by GENSLP are not really completely random, several features, as discussed above, impose structure on the test problems. Generating the battery can be carried out by clicking <Generate>. 13.1.2 GENSLP: joint chance constraint This feature has been added to the original GENSLP, thus extending it for randomly generating jointly chance constrained problems, see Section 3.3. The form shown in Figure 13.2 appears on the screen. The facility serves for randomly generating problems with a joint chance constraint, where only the RHS is stochastic, and has a nondegenerate multivariate normal distribution. The CHAPTER 13. WORKBENCH FOR TESTING SOLVERS 164 Figure 13.4: GENSLP: randomly generating jointly chance constrained problems regression terms (see Section 3.3) are unit arrays. The features located in the forefront of the form have the same meaning as those discussed above for the recourse case. The main menu items on the top line of the form have the following meaning: • [Dimensions] is the same as the corresponding item for recourse problems. • [Matrices] serves for specifying nonzero density, magnitude and sign for A and T , as well as for specifying whether A should be of full rank. The form, which pops up contains an additional item, which can be used to control “difficulty” of the generated problems. It is entitled [Number of active rows at the solution] and means the following: The number entered is the number of active first–stage restrictions (which are generated as inequalities), at a known optimal solution. GENSLP generates this type of problems with a known optimal solution. • [Stochastics] is for specifying features concerning the correlation matrix and standard deviations of the multivariate normal distribution. The form which pops up can be seen in Figure 13.5. The features located at the right–hand side part concern the correlation matrix. Two generation methods are available: CHAPTER 13. WORKBENCH FOR TESTING SOLVERS 165 Figure 13.5: GENSLP: specifying stochasticity for joint chance constraints – [Unit sphere method] is a method of Marsaglia, see [14]. – [Gershgorin theorem] this method ensures positive definiteness by utilizing Gershgorin’s theorem concerning diagonal dominance. If the second method has been chosen, then the density and sign of the correlations can also be prescribed, on the upper part of the form. If the first method has been chosen, these specifications have no effect. On the right–hand side, [Standard deviation] means that the standard deviations vector of the multivariate normal distribution will be the specified percentage of the generated RHS vector h̄0 , see e.g. (3.3) on Page 31. The remaining terms in the affine sum will be unit vectors. The expected value vector of the multivariate normal distribution will be h̄0 . The required probability level α can also be specified at the right–hand side part of the form. GENSLP will generate jointly chance constrained problems with a known solution, by ensuring the fulfillment of the Kuhn–Tucker conditions. The stochastic constraint will be active at this solution, along with a prescribed amount of deterministic constraints (see CHAPTER 13. WORKBENCH FOR TESTING SOLVERS 166 the discussion above). Generating the battery can be carried out by clicking <Generate>. 13.1.3 Test Problem Batteries These integrated workbench facilities serve for dealing with test problem batteries. The main purpose is to test solvers. When choosing it, the form displayed in Figure 13.6 pops up. Figure 13.6: Test problem batteries: main menu We will describe the facilities, grouped according to functionality. Single test problems These features can be found at the upper left corner of the form, entitled as Model instances. CHAPTER 13. WORKBENCH FOR TESTING SOLVERS 167 [Load Model Instance] and [Save Model Instance] is for loading/saving (S)LP problems. The sole difference to the analogous features under the main menu item [File] (see Section 9.1) is, that the default directory in this case is the test problems directory, as specified under the main menu option [Options] (see Section 2.3). [Perturb Current Model Instance] serves for generating a test problem battery, based on the current model instance. The test problems in the battery are generated by imposing random perturbations on a selected array of the current model instance. A similar form appears, as under [AlgebStruct],→[Perturb], see Section 12.2.1, Figure 12.3. In addition to those in Figure 12.2.1, two further items can be specified concerning the battery: the number of test problems to be generated and the generic name of the battery. Generic name means, that the names of the test problems generated will be constructed by appending the generic name with sequence numbers. The files containing the generated problems will have filenames consisting of the model name and slm as extension. The file will be saved in the test problem directory, as specified under the main menu option [Options] (see Section 2.3). Selecting a test problem battery The facilities under the heading Select test problem battery are as follows: • [new battery] serves for selecting a new battery. Any previous battery selection will be cleared. The usual Windows OpenAs file selection menu appears. Multiple files can be selected as usual, by pressing <Ctrl> or <Shift>, and simultaneously the left mouse button. The number of selected test problems in the current battery is displayed in the edit box, located to the right of the selection items. • [add test problems] is for adding test problems to a previously selected battery; file selection can be performed as for the previous item. • [view battery/delete test problems] pops up the matrix editor where Y or N can be entered for the test problems for keeping or deleting them w.r. to the battery, respectively. [view model types in the battery] pops up a simple dialog box, showing the different model types in the current battery. This information can be important, when subsequently choosing solvers for the battery. The list of solvers offered for selection is based on the current model instance. It may happen however, that the battery is inhomogeneous w.r. to model type, which could imply that a solver for simple recourse will be started up for a chance–constrained problem, which would surely result in solver crash. Selecting solvers for the test problem battery These facilities are located below the battery selection part of the sheet. • [select solvers] offers a list of solvers for selection. This list of solvers is based on the current model instance, i.e. those solvers are offered, which are appropriate CHAPTER 13. WORKBENCH FOR TESTING SOLVERS 168 according to their description in the solver selection database (Section 16.3), for the current model instance. After selecting the solvers, a test run can be started up by clicking <run test battery>. This will involve starting up each of the selected solvers, for each of the model instances in the battery in turn. Therefore it is important to load a model via [load model instance], which is representative for the battery, i.e. solvers available for this model instance should also be capable to solve the problems in the battery. The number of selected solvers is displayed in the edit box, located to the right of the selection items. • [update solver parameters]. The control parameters of the solvers, when running them on the test problems, are taken as their current values. This e.g. means after startup of SLP–IOR, that the values are the defaults, as specified in the description database, see Section 16.3. The solver control parameter values can be specified for the test run, via this facility. The query discussed in Section 10.1.1 and displayed in Figure 10.2 will be offered, for each of the selected solvers in turn. Performing a test run The facilities for performing a test run are located in the lower part of the form as buttons. • <run test battery> initiates a group run, i.e. each of the test problems in the battery in turn will be solved by each of the selected solvers in turn. The results will be stored in a text file. If you want that the log files produced by the solvers should also be included, check the checkbox entitled as include solver log file, located at the lower right part of the form. Please notice, that selecting this option may result in a huge results file for the run. A solver run can forcefully be terminated by pressing <Ctrl>–<c> simultaneously. Between two solver runs a sheet appears, offering premature termination of group run. • <view results> serves for viewing the results of a group run. These include summary tables in LATEX for the solution time, objective values, solver termination status, etc. • <save results> serves for saving the results of a group run before initiating a next group run. Please save the results after each group run, otherwise the results of the previous run are being lost! Performing changes on a battery These facilities are located at the lower left part of the form, and are entitled as Manipulate test problem battery. • [endow with normal RHS] The following operation will be carried out on each of the test problems in the current battery. The current stochastic structure is dropped and is replaced with the following one: only the RHS is stochastic; random CHAPTER 13. WORKBENCH FOR TESTING SOLVERS 169 variables and RHS components are in a one–to–one correspondence; the RHS components are independent random variables with a normal distribution. Expected value is the current RHS value, standard deviation is a user–specified percentage of the RHS value, which can be specified in the form as shown in Figure 13.7. Figure 13.7: Endowing a test problem battery with a random RHS Please notice the items at the left–hand part of the form, entitled as (File)names of test problems. These serve to specify the names of the modified test problems. The modified problems will be saved using filenames equal to the test problem name, and extension being slm; in the test problem directory, as specified under [Options], see Section 2.3. There are two possibilities for the names of the modified problems; the choice between them is offered via the radio button group: – [use original names] means that the original names are kept. This has the following implication: the files containing the original model instances will be overwritten without warning. – [use generic name] a generic name will be used, which can be specified in the edit box below the radio button group. There are two ways how the names will be constructed, depending on the status of the checkbox entitled keep original numbering, which is located on the main workbench form, see Figure 13.6. ∗ The check box is checked: in this case the original name will be checked, whether it has a number as ending. If so, then the numbering will be kept and the name part of the original name will be replaced by the generic name. If the original name does not end with a number, then numbers will be appended to the generic name in generation order. CHAPTER 13. WORKBENCH FOR TESTING SOLVERS 170 ∗ The check box is unchecked: the names will be constructed by appending the generic name by numbers, in generating order. • [endow with normal distribution] means that the stochastic structure is kept, except of changing the probability distribution (and the dimension if needed) of ξ as well as the mapping to the RHS. This implies e.g. that the regression terms for matrices, see e.g. Section 3.9, (3.47), are kept. The number of the random variables will be the sum of dimensions of the RHS over stages, except stage 1 (or the deterministic stage in the chance constrained case). The random variables will be in a one–to–one correspondence to the RHS. The new distribution will be independent normal, with expected value zero and standard deviation being equal to the user specified percentage of the RHS value. Please notice, that the random entries as implied by (3.47) will be jointly normally distributed, but if the technology matrices are also stochastic, there will be a strong stochastic dependence among the matrix entries and with the RHS. The same form as shown in Figure 13.7 is used for specifying the transformation. Concerning name conventions, please see the description under [endow with normal RHS]. • [discretize] serves for discretizing the probability distribution of each of the test problems of the battery. A form much similar to the discretization form discussed in Section 12.3.2, and shown in Figure 12.8 appears. The sole difference is, that a section for specifying the filenames is added, as in Figure 13.7. Concerning name conventions please see the description under [endow with normal RHS]. • [inject current distribution] is for injecting the probability distribution of the current problem into each of the test problems of the battery. The form which appears serves merely for specifying the names of the test problems of the new battery, see the name convention part in Figure 13.7. Concerning name conventions please see the description under [endow with normal RHS]. Chapter 14 Editors and viewers 14.1 The matrix editor The matrix editor can be used for editing arrays (matrices and vectors), as well as for editing names and relations. Figure 14.1 shows the editor. Figure 14.1: The matrix editor Besides scrolling by utilizing the scroll bars, the matrix viewport can also be scrolled by 171 CHAPTER 14. EDITORS AND VIEWERS 172 keeping the left mouse button pressed and moving it outside of the editor. Additional navigation features are located in the pop up menu, which can be popped up by a right mouse click, while the cursor is within the boundaries of the editor. The popup menu is shown in Figure 14.2; the navigation features are self–explaining. Figure 14.2: The matrix editor: pop up menu Besides the navigation features, this menu offers possibilities to export/import (parts) of an array via the Windows Clipboard. This can e.g. be used to import arrays or parts of arrays from Excel, by putting the array onto the Clipboard within Excel, and pasting it subsequently from the Clipboard in SLP–IOR–array. An additional feature in this menu serves for printing the current array. The import facility works as follows: Make the upper left corner of the matrix area, where the array should be pasted, the active cell by single–clicking the field (it becomes blue). In the popup menu (see Figure 14.2) choose [Paste From Clipboard]. Provided that the Clipboard has a numeric content in rectangular form, its content will be pasted into the array by matching the upper left corners, and clipping it according to the row/column dimensions of the matrix currently being edited. The matrix will be updated without warning. The export facility works as follows: CHAPTER 14. EDITORS AND VIEWERS 173 Make the upper left corner of the matrix area, which should be pasted onto the Clipboard, the active cell, by clicking the field with normal speed (it becomes blue). In the popup menu (see Figure 14.2) choose [Copy Onto Clipboard]. The matrix having its first– row/first–column position at the active cell and last–row/last–column position according to the dimension of the matrix currently being edited, will be pasted onto the clipboard in rectangular form. The current content of the Clipboard can be viewed by choosing [View Clipboard Content]. The editor can be configured, as described in Section 2.3. The following items can be configured: number of rows and columns in the matrix viewport; field length of a cell in pixels; number of decimal digits (precision) displayed. A further navigation possibility runs as follows: clicking the button <View> in the editor results in a form which shows the nonzero pattern of the array (see Section 14.2). Double–clicking a position in the picture results in returning to the matrix editor, in which the viewport is now positioned according to the position clicked in the graphical view. 14.2 The matrix viewer This facility serves for viewing the nonzero pattern of a matrix. An example for displaying a small matrix can be seen on Figure 9.25. Another example is shown in Figure 14.3. The four speed buttons in the picture. at the upper left corner serve for zooming in/out The leftmost button is for zooming in. Clicking it first, and clicking subsequently a position in the picture, results in zooming into the picture such that the upper left corner of the zoomed–in picture corresponds to the cursor position at clicking. The actual cursor position in the matrix is displayed at the right hand side of the form, in the first two edit boxes entitled as Row and Column, respectively. The next speed button is for zooming out. Clicking the third button has the following effect: entering a row and column number into the above mentioned edit fields, and subsequently clicking the fourth speed button, results in zooming in according to the row and column specified this way. Figure 14.4 shows the zoomed in picture according to the position (33,22). As already mentioned in connection with Figure 9.25, in the zoomed–in picture 1’s and -1’s are displayed using symbols which indicate the content; circle means general element (neither 1 nor -1). Clicking a circle results in showing the value in the third edit box, at CHAPTER 14. EDITORS AND VIEWERS 174 Figure 14.3: The matrix viewer the right hand side of the picture. The button <Toggle Dot> toggles the size of the nonzero indicator. <Color> can be used to choose the color of nonzero element indicators. <Save> serves for saving the picture. 14.3 The probability distribution viewer This viewer serves for displaying the density function and the distribution function of univariate random variable, as it can be seen in Figure 14.5. The two edit boxes to the right to the picture display the expected value and standard deviation, provided that they exist. This feature will further be extended by some basic statistics. CHAPTER 14. EDITORS AND VIEWERS Figure 14.4: The matrix viewer: zoomed in 175 CHAPTER 14. EDITORS AND VIEWERS Figure 14.5: Distribution viewer 176 Chapter 15 Probability distributions Here we give a list of probability distributions available in the present version of SLP– IOR. The list contains the following information: Distribution parameters, numerical method for computing the distribution function or distribution and numerical methods for sampling. If the identifiers of distribution parameters differ in SLP–IOR and in the description below then the former are given in parentheses. 15.1 Univariate distributions For the definitions and properties see [17], [24], [25]. 15.1.1 Discrete distributions Empirical distribution • Parameters: Realizations/probabilities tableau. • Computing the distribution: Given by the tableau. • Computing random variates: Inversion method, see e.g. [12]. Uniform discrete distribution • Parameters: Realizations tableau. • Computing the distribution: Given by the tableau. • Computing random variates: Inversion method, see e.g. [12]. Binomial distribution • Parameters: P(ξ = k) = N k P k (1 − P )N −k ; k = 0, . . . , N ; N ∈ N number of trials; 0 ≤ P ≤ 1 probability of success. 177 CHAPTER 15. PROBABILITY DISTRIBUTIONS • Computing the distribution: formula. 178 Recursive formula for N < 500, else asymptotic • Computing random variates: Rejection technique [45]. Hypergeometric distribution N −M n−k • Parameters: P(ξ = k) = N n max{0, n − N + M } ≤ k ≤ min{M, n}; M k ; N ∈ N+ population size, M ≤ N marked elements, n ∈ N+ sample size. • Computing the distribution: If N ≤ 20 then direct computation; for 20 < N ≤ 500 Stirling-formula; else normal approximation. • Computing random variates: Simulating a sampling experiment [65]. Geometric distribution • Parameters: P(ξ = k) = P (1 − P )k , k = 0, 1, . . .; 0 ≤ P ≤ 1 Bernoulli probability parameter. • Computing the distribution: Given by formula. • Computing random variates: Exponential distribution method [65]. Negative binomial distribution • Parameters: P(ξ = N + k) = N +k−1 N −1 (1 − P )k P N ; k = 0, . . . , N ; N ∈ N+ success parameter, 0 ≤ P ≤ 1 Bernoulli probability parameter. • Computing the distribution: Recursive formula, for N < 500. • Computing random variates: Inversion method in [9]. Poisson distribution λk • Parameters: P(ξ = k) = e−λ , k = 0, 1, . . .; k! λ > 0, the mean. • Computing the distribution: Recursive formula. • Computing random variates: Knuth’s method [49] for λ ≤ 20. Else 1 : Ahrens and Dieter Gamma method [9]. 2 : Ahrens and Dieter ratio of uniforms method [2]. CHAPTER 15. PROBABILITY DISTRIBUTIONS 15.1.2 179 Continuous distributions Uniform distribution • Parameters: Endpoints of an interval. • Computing the distribution function: Explicit formula. • Computing random variates: 1. L’Ecuyer’s version of Park & Miller method [16]. 2. The previous method with shuffling from [63]. 3. Generalized feedback shift register method of Lewis and Payne, see [16]. 4. Knuth’ s lagged Fibonacci generator [49]. 5. Knuth’ s lagged Fibonacci generator; better but slower version [49] 6. Ripley’ s universal multiplicative LCG generator, slow, [63]. 7. Random function of Borland Pascal; not recommended. Normal distribution 1 e • Parameters: Density function f (x) = √ 2πσ mean µ and standard deviation σ > 0. −(x − µ)2 2σ 2 ; • Computing the distribution function: Chebyshev approximation, see [45]. • Computing random variates: Box and Muller method, Marsaglia’s polar method, Marsaglia and Bray convenient method and the Kinderman-Ramage procedures are available, see [45] and [9]. Exponential distribution • Parameters: Density function: f (x) = λ e−λx ; λ > 0. • Computing the distribution function: Explicite formula. • Compuing random variates: Inversion method, see e.g. [49]. Gamma distribution x 1 x a−1 − • Parameters: Density function: f (x) = e b; bΓ(a) b a > 0 (AA) shape parameter and b > 0 (BB) scale parameter. CHAPTER 15. PROBABILITY DISTRIBUTIONS 180 • Computing the distribution function: Based on the gamma– and incomplete gamma–functions. For the gamma–function series expansion with Chebyshev polynomials [51]; for the incomplete gamma–function series expansions 6.5.29 and 6.5.32 and continued fractions 6.5.31 in [1]. • Computing random variates: Combination of the Ahrens-Dieter method, the inversion method and the method of Best, see [9]. Beta distribution 1 • Parameters: Density function: f (x) = xa−1 (1 − x)b−1 with B(a, b) being B(a, b) Z 1 ua−1 (1 − u)b−1 du; the beta function: B(a, b) = 0 a > 0 (AA), b > 0 (BB) shape parameters. • Computing the distribution function: Incomplete beta–function, approximation method in [45]. • Computing random variates: Gamma-variate method, see [9]. Cauchy-distribution • Parameters: Density function: f (x) = 1 2 + 1 π arctan x−a ; b a (AA) location parameter, b > 0 (BB) scale parameter. • Computing the distribution function: Explicit formula. • Computing random variates: Ratio of uniforms [9] and ratio of normals [65]. Weibull distribution x !a b ; a a−1 − x e ba b > 0 (BB) scale parameter, a > 0 (AA) shape parameter. • Parameters: Density function: f (x) = • Computing the distribution function: Explicit formula. • Computing random variates: Inversion method, see e.g. [49]. ChiSquared distribution ν−2 x x 2 e− 2 • Parameters: Density function: f (x) = ν ν ; 2 2 Γ( 2 ) ν ∈ N+ (Df) degrees of freedom. CHAPTER 15. PROBABILITY DISTRIBUTIONS • Computing the distribution function: in [1]. 181 Series expansions 26.4.28 and 26.4.19 • Computing random variates: Gamma variate method [9]. Student’ s t–distribution − ν+1 2 Γ ν+1 x2 2 • Parameters: Density function: f (x) = √ 1 + ; ν ν πν Γ 2 ν ∈ N+ (Df) degrees of freedom. • Computing the distribution function: Via the incomplete beta-function [45]. • Computing random variates: F-variate method [45]. Fisher’ s F–distribution ν1 +ν2 2 Γ • Parameters: Distribution function: f (x) = Γ ν1 2 ν ν21 1 ν2 ν2 2 Γ ν1 ∈ N+ (Df1), ν2 ∈ N+ (Df2) degrees of freedom. ν1 −2 x 2 ; ν1 +ν 2 2 ν1 1 + ν2 x • Computing the distribution function: Via the incomplete beta-function [45]. • Computing random variates: Beta–variate method [45]. Extreme–value (Gumbel) distribution [17] • Parameters: Density function: f (x) = 1b e− x−a b − x−a b e−e ; a (AA) location parameter, b > 0 (BB) scale parameter. • Computing the distribution function: Explicit formula. • Computing random variates: Inversion method, see e.g. [49]. Logistic distribution [17] • Parameters: Density function: f (x) = e− x−a b ; x−a 2 b 1 + e− b a (AA) location parameter, b > 0 (BB) scale parameter. • Computing the distribution function: Explicit formula. • Computing random variates: Inversion method, see e.g. [49]. CHAPTER 15. PROBABILITY DISTRIBUTIONS 182 Lognormal distribution [17] (log x 2 m) • Parameters: Density function: √1 x1 e− 2σ2 ; σ 2π m > 0 the median, σ > 0 (s) shape parameter. • Computing the distribution function: Computed from normal. • Computing random variates: Computed from normal. Pareto distribution [17] 1 • Parameters: Density function: f (x) = a xa+1 ; a > 0 (AA) shape parameter. • Computing the distribution function: Explicit formula. • Computing random variates: Inversion method, see e.g. [49]. Power function distribution [17] • Parameters: Density function: f (x) = a xa−1 ; a (AA) shape parameter. • Computing the distribution function: Explicit formula. • Computing random variates: Inversion method, see e.g. [49]. Triangular distribution • Parameters: The density function has a triangular shape; parameters are the endpoints of an interval and the projection of the third vertex on this interval. • Computing the distribution function: Explicit formula. • Computing random variates: Inversion method, see e.g. [49]. 15.2 Multivariate distributions 15.2.1 Discrete distributions Empirical distribution • Parameters: Realizations/probabilities tableau. • Computing the distribution: Given by the tableau. • Computing random variates: None implemented. CHAPTER 15. PROBABILITY DISTRIBUTIONS 15.2.2 183 Continuous distributions Uniform distribution • Parameters: Endpoints of the intervals coordinatewise. • Computing the distribution function: Not implemented. • Computing random variates: Based on univariate uniform. (Nondegenerate) Normal distribution • Parameters: Mean vector and positive definite correlation matrix. • Computing the distribution function: Not implemented. • Computing random variates: Standard univariate normal variates are generated and transformed afterward using the Cholesky-factorization of the covariance matrix. (Multivariate Lognormal distribution • Parameters: Mean vector and positive definite correlation matrix of the underlying normal distribution. • Computing the distribution function: Not implemented. • Computing random variates: Normal random vectors are generated which are transformed by component–wise taking exponents. Chapter 16 The solver library SLP–IOR maintains solvers in a solver library. Two types of solvers are distinguished: • Solvers connected by the developers or the users of SLP–IOR; let us call this type of solvers added solvers. • GAMS solvers, provided that the user has access to GAMS. The solver library consists of two components: • The solver executables are in the subdirectory Solvers of the SLP–IOR system (installation) directory. This directory contains also the default parameter–, options– and specification files, provided the solver works with them. If a solver consists of several executables, then a batch file (*.bat) for starting them up should also be placed into this directory. • The solver description database contains information about the solvers and serves for SLP–IOR to organize solver runs. This information includes: – Solver capabilities including model type; special features like complete recourse or independent random variables; maximal dimensions. – The solver’s control parameters; option files (if any); termination codes. – Input/output data format of the solver; names of I/O files; name of the executable or batch file. In general, connecting a solver to SLP–IOR consists of three steps; for GAMS solvers only the third step is to be carried out. The steps are as follows: S1: Carrying out minor modifications on the solver code as follows: – Input of problem data: if the solver accepts data in SMPS [6] format, then no additional change in the code is needed. Otherwise the solver has to be endowed with a facility for reading problem data in SLP–IOR’s own data format. This will be documented in the next release of the user’s guide, because due to introducing multistage there are still format changes anticipated. 184 CHAPTER 16. THE SOLVER LIBRARY 185 – Output of solution: in order to communicate results from the solver to SLP– IOR, the solver is supposed to write two simple text files as described in Section 16.2. S2: Putting the executable and additional files needed for execution into the Solvers subdirectory as outlined above; S3: Updating the solver description database in a menu driven fashion, as described in Section 16.3 16.1 Input data file for solver This is the data file of the current model instance, produced by SLP–IOR, which serves as input for the solver. Its name should be specified in the solver description database. • If the solver accepts data in SMPS [6] format, then the solver code need not be changed; it is sufficient to declare this fact in the solver description database. • Otherwise the solver code must be changed in order to accept data in SLP–IOR’s data format. This will be documented in the next release of the user’s guide, because due to introducing multistage there are still format changes anticipated. 16.2 Files to be produced by the solver For a smooth connection of your solver to SLP–IOR, the solver should produce two files. Assume that the solver is named as TheSolver. • The first file serves for communicating general information. The name of this file must be TheSolver.inf, and should contain a single record (line) containing the following items, in the order as specified below, and separated by at least one blank: – termination code in integer format; – number of iterations in integer format; – elapsed time in seconds in any real format; – overall objective value in any real format. • The second file consists of the solution vector. The name of this file should be the same as specified in SLP–IOR via the solver connection facility. For avoiding collisions with other files written by SLP–IOR please use sol as extension, e.g. TheSolver.sol. The solver connection facility allows for three types of solution: – only the first–stage primal solution is available; CHAPTER 16. THE SOLVER LIBRARY 186 – primal solutions are available for all stages; – primal and dual solutions are available for all stages. The order is the following: primal solution comes first; if available for all stages then the order is the node order in the tree (see remark below in this section). This is followed by the dual solution, if available, in the same order as for the primal solution. The interpretation of the dual solution is the dual solution of the equivalent LP. For keeping the format as simple as possible, we have chosen the following: a single number per record (line) in any real format; zeros must also be listed. For the other files produced by the solver, three types can be specified. They serve solely for viewing them within SLP–IOR, and therefore can have any format. The filenames can be specified via the solver connection facility of SLP–IOR. The three types are as follows: • log file; • summary file; • error file. Remark For solvers connected via SMPS [6] format, SLP–IOR assumes the following ordering of the solution for multiple stages: INDEP and BLOCKS: Realizations are taken in the order as they appear in the INDEP or BLOCKS sections; joint realizations are considered in a lexicographic order, according to the sequence as they appear in the STOCH file. SCENARIO: This is not yet fixed because I/O for scenarios is under development in SLP–IOR. We plan the following ordering: stagewise first and nodewise within stages afterwards. For the case, when the STOCH file contains both INDEP/BLOCKS and SCENARIO sections, we have no precise idea yet how to order this. The consistent way would be to generate a single scenario tree, and taking the tree order there. Filename conventions for SMPS For solvers with SMPS input format, the datafiles should have the extensions cor, tim and sto, respectively, for avoiding filename collisions. The name part can arbitrarily be chosen, as specified in the SLP–IOR solver connection facility; we suggest TheSolver.cor, CHAPTER 16. THE SOLVER LIBRARY 187 etc. If the solver reads a SPECS or OPTIONS file, please use the extension opt, suggested filename is TheSolver.opt. 16.3 The solver description database This is a simple database containing a single record for each solver; data are stored in a single text file Solvers.dft, which is located in the Solvers subdirectory. It contains the solver descriptions; the solvers themselves are in the Solvers subdirectory. Please notice, that solver description and solver executable are separate items. Putting a new solver executable into the Solvers directory does not imply, that SLP– IOR does know about the existence of this solver. Conversely, entering the information concerning a new solver into the solver database just notifies SLP–IOR about the new solver. The system presupposes, that the solver executable has been placed by the user into the Solvers directory. The solver information database can be updated in a menu driven fashion, under [Options] choose [Update Solver Features]. The form with a tabbed sheet shown in Figure 16.1 shows up. The central part of the form is occupied by a tabbed sheet, which serves for updating data concerning the currently selected solver. Solver selection can be accomplished in two ways: • On the upper left part of the first sheet, by clicking the H arrow, and subsequently clicking the solver name in the list of solvers, which is pulled down; • or by scrolling the solvers in the scroll box located at the right–hand part of the form; scrolling can be accomplished by clicking the arrows H or N. Each solver item in the database can either be enabled or disabled. SLP–IOR only considers solvers which are enabled. There are two ways to update the status of a solver in this respect: • Select the solver as current solver. In the first sheet check/uncheck the Enable/Disable check box, by clicking it. • The button <Solvers>, entitled as Enable/Disable at the lower right–hand part of the form, provides a shortcut. By clicking this button, a list containing all solvers pops up, where the status can conveniently be updated by checking/unchecking the check boxes located before the solver name. CHAPTER 16. THE SOLVER LIBRARY 188 Figure 16.1: Updating the solver description database In the top row of the form, the three display boxes show the current solver’s sequence number in the database, its name and the overall number of solvers in the database, respectively. In Figure 16.1, the selected solver is SRAPPROX, which is the 31th solver out of 33 solvers in that specific database. The solvers are sorted alphabetically. The buttons on the right–hand side of the form have the following functionality: • <New> serves for adding a new solver. After clicking this button a new form pops up where the user is prompted for the name of the new solver. Clicking <Cancel> on this form cancels the operation. Entering a name and clicking <OK> results in adding a new item to the solver database. If you wish that SLP–IOR considers this solver, please don’t forget to enable it, see this feature above in this section. • <Delete> deletes the current solver. Before this happens, the user will be asked to confirm the operation. If confirmed the solver will be deleted from the database. WARNING: all information concerning this solver will be lost. See also the backup facility described below in this section. • <Solvers> titled as Enable/Disable has been described above. CHAPTER 16. THE SOLVER LIBRARY 189 The button <Backup> in the bottom row serves for saving the current database on disk. When clicking it, the usual save dialog appears. This backup copy can be used for restoring the solver description database as follows: Rename the file as Solvers.dft, and replace the file with the same name in the Solvers directory with the renamed backup copy. The remaining buttons in the bottom row have the usual functionality. The information concerning the current solver can be updated via the tabbed sheet, which occupies the central part of the form. For changing between sheets, please click the appropriate tab. The items which can be specified on the separate sheets are as follows: 16.3.1 Basic The solver selection combo box (upper left corner) serves for selecting the current solver. The check box entitled as Enabled/Disabled is for choosing the solver status. Both facilities have already been discussed in this section. Solvers are subdivided into two groups: • GAMS Solver means a solver available for the user via her/his copy of GAMS (if any); • Added Solver means a solver which came either with the SLP–IOR distribution or has been added later on by the user. The solver type must be specified via the radio buttons at the upper right corner of the sheet. The remaining items on this sheet need no further explanation. 16.3.2 Dimensions This sheet serves for specifying maximal dimensions, for which the solver should be considered as appropriate (applicable). The sheet is shown in Figure 16.2. The first group on the left–hand side of the sheet, is for specifying maximal dimensions of the arrays in a deterministic LP or for stochastic models in the expected value problem, see Sections 3.3.5, 3.4.5, and 3.9.5. Entering zero means that SLP–IOR should assume no upper bounds. The second group on the left–hand side serves for specifying the minimal and maximal number of stages. CHAPTER 16. THE SOLVER LIBRARY 190 Figure 16.2: Solver description database: dimensions The first group on the right–hand side of the sheet can be used to enter upper bounds concerning the algebraic equivalent LP, provided it exits, see Section 3.9.6. Entering zero means that SLP–IOR should assume no upper bounds. The second item on this side stands for the maximum number of random variables; again, entering zero means that SLP–IOR should assume no upper bound. The third item is for the joint realizations, provided that the distribution is discrete. The specification can also separately be done for the groups of mutually independent random variables, see Section 3.3.2. Entering zero means, as above, that SLP–IOR should assume no upper bound. 16.3.3 Models This sheet serves for specifying the type of models, for which the solver is appropriate. For the description of the currently available model types see Chapter 3. This sheet is supposed to be self–explaining. CHAPTER 16. THE SOLVER LIBRARY 16.3.4 191 Random Var. This is for the specification of the stochastic dependency structure accepted by the solver, e.g. stochastic independence, see Section 3.3.2. It is supposed to be self–explaining. 16.3.5 Distributions This sheet serves for specifying the probability distributions, see Chapter 15, for which the solver is appropriate. Again, the sheet is supposed to be self–explaining. 16.3.6 Input/Output The sheet serves for entering various filenames and file structure information. It can be seen in Figure 16.3. Figure 16.3: Solver description database: I/O files The group labeled as Data Input specifies the data input filename and format, which the solver presupposes. • Dataformat: MPS, SMPS are standard data formats, see [6]; SLP–IOR is the data CHAPTER 16. THE SOLVER LIBRARY 192 format of SLP–IOR; GAMS means the model written in the GAMS modeling language. • Input Datafile: the input data filename is to be specified. The solver is supposed to take this file as data input file for the current problem. When checking the box Ask name before startup, the user will be prompted for the solver input filename before SLP–IOR actually writes the file and starts up the solver. The group labelled as Output of Results specifies the content of the results file, produced by the solver. This information serves for SLP–IOR for retrieving the results. • Format of Results is an obsolete feature, just kept, because in the earlier version of SLP–IOR we still had some hope, that there will be some standard (like MPS) for results. Selecting Special means, that SLP–IOR assumes that the results are in the output format of XMP. Except when your solver writes an output file in that format, please choose Plain results here. • Available Results serves for specifying the type of solution produced by the solver and should be self–explaining. The group labelled as Output Filenames specifies the names of files, including the results file, produced by the solver. This information serves for SLP–IOR for retrieving the results. The first filename, with edit box labeled as Results, is the filename containing the results produced by the solver. SLP–IOR will try to retrieve the results from this file. The remaining filenames are names of files, which the solver might produce additionally. They can be viewed after the solver run in SLP–IOR. Leaving a field blank, means that SLP–IOR will not look for the corresponding file. 16.3.7 Control The purpose of this sheet is specifying various issues concerning the solver run. It can be seen in Figure 16.4. In the upper left part the name of an option/specification file can be entered. This file is supposed to contain run-time control information for the solver. A default copy of such a file must be available in the Solvers directory. Before starting up the solver, the file will be offered for editing. If the solver does not take such a file, please leave this field blank. The hot start check box has the straightforward meaning. If this box is checked, then, provided that such a solution is available (e.g. from a previous run), SLP–IOR will write a file with the filename being the solver name and extension being .hot, containing the first–stage solution. CHAPTER 16. THE SOLVER LIBRARY 193 Figure 16.4: Solver description database: control A further item which must be specified is the name of the solver executable or batch file; the corresponding edit box is labeled as Exec file. Please enter the filename with extension as in the example in Figure 16.4. On the right–hand side of the sheet the termination codes of the solver should be updated, and finally the number of real– and integer run–time parameters (control parameters) should be entered. The data concerning parameters can the be specified on the next sheet. The control parameter values are written into a text file, as described in Section 10.1.1. 16.3.8 Parameters This sheet serves for specifying the following data for the run–time parameters: short description, lower bound, default value and upper bound. 16.3.9 Specials The purpose of this sheet is to enter information, not contained in the previous sheets; the sheet is displayed in Figure 16.5. CHAPTER 16. THE SOLVER LIBRARY 194 Figure 16.5: Solver description database: special issues The check box group at the left–hand side is supposed to be self–explaining. Algebraic equivalent needed signalizes to SLP–IOR that the solver aims at the algebraic equivalent LP, consequently data concerning this LP will be sent to the solver (provided that such an equivalent exists). General purpose LP solver means that the solver will automatically receive the algebraic equivalent LP provided it exists. Relation codes are for the case when the solver accepts SLP–IOR data format for model data, but deviates internally in relation codes from the SLP–IOR convention (which is the default). Chapter 17 Solvers connected to SLP–IOR This chapter is devoted to the solvers currently connected to SLP–IOR. We did not include the GAMS solvers, for these see [8]. The year indicated in the solver tables is the development year of the version connected to SLP–IOR. The entries for the availability item in the tables below have the following meaning: • SLP–IOR means that the executable of the solver, as connected to SLP–IOR, is part of the SLP–IOR distribution. These are either solvers, for which we have the permission of the authors to distribute the solver in the form mentioned above with SLP–IOR, or the solvers which have been developed by ourselves. • author means that although the solver is connected to SLP–IOR, the solver executable is not distributed with the system. The user needs a separate license from the author for using the solver. • commercial means that although the solver is connected to SLP–IOR, the solver executable is not distributed with the system. The user has to purchase a license on the market. 195 CHAPTER 17. SOLVERS CONNECTED TO SLP–IOR 17.1 General purpose LP solvers 17.1.1 HiPlex Identification: Developer: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: Remarks: 17.1.2 HiPlex, Version 1.01, 1994 I. Maros I. Maros author advanced research simplex method with the Phase I method of of Maros [52] I deterministic LP I recourse problems with finite discrete distribution I separate chance constraints, only RHS stochastic I Option file HOPDM Identification: Developer: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: Remarks: HOPDM, Release 2.3, 1996 J. Gondzio J. Gondzio SLP–IOR advanced research higher order primal–dual predictor–corrector method of Gondzio [18] I deterministic LP I recourse problems with finite discrete distribution I separate chance constraints, only RHS stochastic I SPECS file 196 CHAPTER 17. SOLVERS CONNECTED TO SLP–IOR 17.1.3 MINOS Identification: Developers: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: Remarks: 17.1.4 OB1 Identification: Developers: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: Remarks: MINOS Version 5.4, 1995 B.A. Murtagh, P.E. Gill, W. Murray, M.A. Saunders, M.H. Wright Stanford University commercial commercial primal simplex method for LP [60] I deterministic LP I recourse problems with finite discrete distribution I separate chance constraints, only RHS stochastic I SPECS file OB1, Version ROB1, 1989 R.E. Marsten, M.J. Saltzman, D.F. Shanno, G.S. Pierce XMP Optimization Software, Inc. commercial research version of OB1; advanced research interior point methods [54] I deterministic LP I recourse problems with finite discrete distribution I separate chance constraints, only RHS stochastic I maximum number of dense columns, default is 13 I SPECS file 197 CHAPTER 17. SOLVERS CONNECTED TO SLP–IOR 17.1.5 XMP Identification: Developer: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: Remarks: XMP, 1986 R.E. Marsten R.E. Marsten author advanced research primal– and dual simplex method [53] I deterministic LP I recourse problems with finite discrete distribution I separate chance constraints, only RHS stochastic I refactorization frequency, default 30 I dual feasibility tolerance, default 10−6 I primal feasibility tolerance, default 10−4 I pivot tolerance, default 10−6 198 CHAPTER 17. SOLVERS CONNECTED TO SLP–IOR 17.2 199 Solvers for recourse problems using the structure of the equivalent LP These solvers are for recourse problems with a finite discrete distribution; in this case the equivalent LP exists. 17.2.1 BPMPD Identification: Developer: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: BPMPD, Version 2.1, 1996 Cs. Mészáros Cs. Mészáros SLP–IOR advanced research interior point method; augmented system approach of Mészáros [59] I deterministic LP I recourse problems with finite discrete distribution I separate chance constraints, only RHS stochastic I relative tolerance for the duality gap, default 10−7 I SPECS file Remarks: 17.2.2 MSLiP Identification: Developer: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: Remarks: MSLiP, Version 8.3, 1995 H.I. Gassmann H.I. Gassmann SLP–IOR advanced research nested Benders decomposition with added algorithmic features by Gassmann [15] I recourse problems with finite discrete distribution, which can be written in SMPS format I Option file CHAPTER 17. SOLVERS CONNECTED TO SLP–IOR 17.2.3 QDECOM Identification: Developer: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: Remarks: 17.2.4 QDECOM, 1985 A. Ruszczyński IOR University of Zurich SLP–IOR advanced research regularized decomposition method of Ruszczyński [66] I two–stage fixed recourse problems with finite discrete distribution I cut tightness tolerance, default 10−8 SHOR2 Identification: Developers: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: Remarks: SHOR2, 1998 N.Z. Shor and A.P. Likhovid Glushkov Institute, Kiev SLP–IOR advanced research decomposition scheme based on the r–algorithm of Shor [68] I two–stage complete recourse problems with finite discrete distribution where only the is RHS stochastic and which can be written in SMPS format I Options file 200 CHAPTER 17. SOLVERS CONNECTED TO SLP–IOR 17.3 201 Solvers for two–stage recourse problems aiming at the original problem These solvers do not aim at the equivalent LP; consequently they also work with continuous distributions. 17.3.1 DAPPROX Identification: Developers: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: Remarks: DAPPROX, 2001 P. Kall and J. Mayer P. Kall and J. Mayer SLP–IOR advanced research successive discrete approximation method of Kall [26], [29] I two–stage problems with relative complete recourse with independent random variables and with distributions: I I finite discrete distribution I I uniform distribution I I normal distribution I I exponential distribution I maximal number of subdivisions, default 2000 I maximal number of different dual vertices, default 200 I coordinate selection strategy for subdivision, default 2: I I 1: strategy based on relative error from bounds; I I 2: strategy based on the previous quantity multiplied by the interval probability; I I 3: strategy based on the previous quantity weighted by the number of subdivisions leading to the interval; I interval selection strategy for subdivision, default 2: I I 1: strategy based on dual solutions; I I 2: strategy based on the linearization error; I I 3: coordinate is randomly selected I enable/disable subdivision saving (1/0) after solver termination, default 0 I fix/free first stage solution during run (1/0), default 0 I enable/disable subdivision hotstart (1/0), default 0 meaning hotstart from previously saved subdivision I stopping tolerance for the relative error, default 10−5 uses Minos 5.4 for solving LP subproblems CHAPTER 17. SOLVERS CONNECTED TO SLP–IOR 17.3.2 SDECOM Identification: Developers: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: Remarks: 202 SDECOM, 1995 P. Kall and J. Mayer P. Kall and J. Mayer SLP–IOR advanced research stochastic decomposition method of Higle and Sen [19], [21] I two–stage problems with relative complete recourse with independent random variables and with distributions: I I finite discrete distribution I I uniform distribution I I normal distribution I I exponential distribution I maximum number of different dual vertices, default 200 I maximum samplesize, default 1000 I maximum number of cuts kept, default 200 I incumbent update period, default 5 I period for considering a cut as loose, default 10 I cut dropping period, default 10 I gap in incumbent sequence (stopping), default 20 I gap in new–vertex sequence (stopping), default 30 I enable/disable keeping Benders cuts (1/0), default 1 I maximum number of Benders cuts (Phase I), default 100 I random seed1 for sampling I random seed2 for sampling (shuffling) I stopping tolerance, default 10−4 I descent tolerance in SD, default 0.7 I uses Minos 5.4 for solving LP subproblems I development based on guidelines of Higle and Sen [20] CHAPTER 17. SOLVERS CONNECTED TO SLP–IOR 17.4 Solvers for simple continuous recourse Reminder: for simple recourse only the RHS is stochastic. 17.4.1 SHOR1 Identification: Developers: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: Remarks: 17.4.2 SRAPPROX Identification: Developers: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: Remarks: SHOR1, 1997 N.Z. Shor and A.P. Likhovid Glushkov Institute, Kiev SLP–IOR advanced research decomposition scheme based on the r–algorithm of Shor [68] I two–stage simple recourse problems with finite discrete distribution I Options file SRAPPROX, 1994 P. Kall and J. Mayer P. Kall and J. Mayer SLP–IOR advanced research successive discrete approximation method of Kall [26], [29] I two–stage simple recourse with distributions: I I finite discrete distribution I I uniform distribution I I normal distribution I I exponential distribution I maximum number of coordinate splits, default 500 I primal/dual master solved (1/2), default 2 I stopping tolerance for the relative error, default 10−6 uses Minos 5.4 for solving LP subproblems 203 CHAPTER 17. SOLVERS CONNECTED TO SLP–IOR 17.5 Solver for simple integer recourse 17.5.1 SIRD2SCR Identification: Developers: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: Remarks: 204 SIRD2SCR, 1994 J. Mayer and M.H. van der Vlerk J. Mayer and M.H. van der Vlerk SLP–IOR advanced research convex hull method of Klein Haneveld and Van der Vlerk [47], [71] I two–stage simple integer recourse with finite discrete distribution I maximum number of coordinate splits, default 500 I primal/dual master solved (1/2), default 2 I stopping tolerance, default 10−6 I uses SRAPPROX for solving simple recourse subproblems I In the following cases the optimal solution and/or the optimal objective value may be incorrect: I I matrix T is not of full row rank; I I optimal solution is on the boundary of the feasible domain. In both cases the resulting objective function value is a lower bound for the true optimal value. CHAPTER 17. SOLVERS CONNECTED TO SLP–IOR 17.6 Solver for multiple simple recourse 17.6.1 MScr2Scr Identification: Developers: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: Remarks: 205 MScr2Scr, 2001 J. Mayer and M.H. Van der Vlerk J. Mayer and M.H. Van der Vlerk SLP–IOR advanced research transformation method of Van der Vlerk [72] I two–stage multiple simple recourse with finite discrete distribution I maximum number of coordinate splits, default 500 I primal/dual master solved (1/2), default 2 I stopping tolerance, default 10−6 I uses SRAPPROX for solving simple recourse subproblems CHAPTER 17. SOLVERS CONNECTED TO SLP–IOR 17.7 206 Solvers for jointly chance constrained problems The following solvers are for the case when only the RHS is stochastic and has a multivariate nondegenerate normal distribution. 17.7.1 PCSPIOR Identification: Developer: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: Remarks: PCSPIOR, 1995 J. Mayer J. Mayer SLP–IOR advanced research supporting hyperplane method of Szántai [70] I jointly chance constrained problems with only the RHS being stochastic having a multivariate nondegenerate normal distribution I samplesize for Monte–Carlo integration, default 1000 I maximum number of cuts, default 200 I Monte–Carlo method (1:Szántai/2:Deák), default 1 I Deák: using samplesize or epsilon (1/2), default 1 I Stopping tolerance, default 10−4 I Deák probability epsilon, default 10−4 provided this Monte–Carlo method was chosen I uses Minos 5.4 for solving LP subproblems I for computing the normal distribution function and its gradient two subroutine packages are used: I I PCSPNOR3 of Szántai, [69] I I NORSUBS of Deák, [13] CHAPTER 17. SOLVERS CONNECTED TO SLP–IOR 17.7.2 PROBALL Identification: Developer: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: Remarks: PROBALL, 2001 J. Mayer J. Mayer SLP–IOR advanced research central cutting plane method of Mayer [56] I jointly chance constrained problems with only the RHS being stochastic having a multivariate nondegenerate normal distribution I samplesize for Monte–Carlo integration, default 1000 I maximum number of cuts, default 200 I iterations between two cut droppings, default 30, meaning the period of iterations after which cut dropping should be considered I number of subsequent iterations for counting a cut as loose, default 3 I Monte–Carlo method (1:Szántai/2:Deák), default 1 I Deák: using samplesize or epsilon (1/2), default 1 I Stopping tolerance, default 10−4 I Deák probability epsilon, default 10−4 provided this Monte–Carlo method was chosen I uses Minos 5.4 for solving LP subproblems I for computing the normal distribution function and its gradient two subroutine packages are used: I I PCSPNOR3 of Szántai, [69] I I NORSUBS of Deák, [13] 207 CHAPTER 17. SOLVERS CONNECTED TO SLP–IOR 17.7.3 PROCON Identification: Developer: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: Remarks: PROCON, 1992 J. Mayer J. Mayer SLP–IOR advanced research reduced gradient method of Mayer [55], [56] I jointly chance constrained problems with only the RHS being stochastic having a multivariate nondegenerate normal distribution I samplesize for Monte–Carlo integration, default 1000 I stopping tolerance, default 10−4 I uses XMP for solving LP subproblems I for computing the normal distribution function and its gradient the following subroutine packages is used: I I PCSPNOR3 of Szántai, [69] 208 CHAPTER 17. SOLVERS CONNECTED TO SLP–IOR 209 17.8 Solver for models involving integrated chance constraints 17.8.1 ICCMIN Identification: Developer: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: Remarks: ICCMIN, 2005 A. Künzi–Bay and J. Mayer A. Künzi–Bay and J. Mayer SLP–IOR advanced research Benders–type decomposition method of Klein Haneveld and Van der Vlerk [48] I integrated probability functions as constraints or in the objective; finite discrete distribution I maximum number of cuts, default 500 I stopping tolerance, default 10−10 I uses MINOS for solving LP subproblems 17.9 Solver for models involving CVaR 17.9.1 CVaRMin Identification: Developer: Copyright: Availability: Characterization: Method: Reference: Type of problems: Run time parameters: Remarks: CVaRMin, 2004 A. Künzi–Bay and J. Mayer A. Künzi–Bay and J. Mayer SLP–IOR advanced research Benders decomposition [50] I CVaR functions as constraints or in the objective; finite discrete distribution I maximum number of cuts, default 500 I stopping tolerance, default 10−10 I uses MINOS for solving LP subproblems Chapter 18 Models versus solvers 18.1 Deterministic LP • BPMPD (Page 199) • HiPlex (Page 196) • HOPDM (Page 196) • Minos (Page 197) • OB1 (Page 197) • XMP (Page 198) 18.2 Two stage recourse problems 18.2.1 General recourse, finite discrete distribution • BPMPD (Page 199) • HiPlex (Page 196) • HOPDM (Page 196) • Minos (Page 197) • OB1 (Page 197) • XMP (Page 198) 210 CHAPTER 18. MODELS VERSUS SOLVERS 18.2.2 211 Fixed recourse, finite discrete distribution • BPMPD (Page 199) • HiPlex (Page 196) • HOPDM (Page 196) • Minos (Page 197) • MSLiP (Page 199) • OB1 (Page 197) • QDECOM (Page 200) • XMP (Page 198) 18.2.3 Relatively complete recourse, finite discrete distribution • BPMPD (Page 199) • DAPPROX (Page 201) • HiPlex (Page 196) • HOPDM (Page 196) • Minos (Page 197) • MSLiP (Page 199) • OB1 (Page 197) • QDECOM (Page 200) • SDECOM (Page 202) • SHOR2 (Page 200) • XMP (Page 198) 18.2.4 Relatively complete recourse, some continuous distributions • DAPPROX (Page 201) • SDECOM (Page 202) CHAPTER 18. MODELS VERSUS SOLVERS 18.2.5 212 Simple continuous recourse, finite discrete distribution • BPMPD (Page 199) • DAPPROX (Page 201) • HiPlex (Page 196) • HOPDM (Page 196) • Minos (Page 197) • MSLiP (Page 199) • OB1 (Page 197) • QDECOM (Page 200) • SDECOM (Page 202) • SHOR1 (Page 203) • SHOR2 (Page 200) • SRAPPROX (Page 203) • XMP (Page 198) 18.2.6 Simple continuous recourse, some continuous distributions • DAPPROX (Page 201) • SDECOM (Page 202) • SRAPPROX (Page 203) 18.2.7 Simple integer recourse, finite discrete distribution • SIRD2SCR (Page 204) 18.2.8 Multiple simple recourse, finite discrete distribution • MScr2Scr (Page 205) 18.3 Multistage recourse problems Presently we only have solvers connected for finite discrete distributions. CHAPTER 18. MODELS VERSUS SOLVERS 18.3.1 213 General–purpose LP solvers • HiPlex (Page 196) • HOPDM (Page 196) • Minos (Page 197) • OB1 (Page 197) • XMP (Page 198) 18.3.2 Solvers utilizing the structure • BPMPD (Page 199) • MSLiP (Page 199) 18.4 Chance constrained problems 18.4.1 Separate chance constraints, only RHS stochastic • BPMPD (Page 199) • HiPlex (Page 196) • HOPDM (Page 196) • Minos (Page 197) • OB1 (Page 197) • XMP (Page 198) 18.4.2 Joint chance constraints, only RHS stochastic, multinormal distribution • PCSPIOR (Page 206) • PROBALL (Page 207) • PROCON (Page 208) CHAPTER 18. MODELS VERSUS SOLVERS 214 18.5 Models with integrated chance constraints or objective 18.5.1 Separate integrated chance constraints or objective, finite discrete distribution • BPMPD (Page 199) • HiPlex (Page 196) • HOPDM (Page 196) • ICCMIN (Page 209) • Minos (Page 197) • OB1 (Page 197) • XMP (Page 198) 18.5.2 Joint integrated chance constraints or objective, finite discrete distribution • BPMPD (Page 199) • HiPlex (Page 196) • HOPDM (Page 196) • ICCMIN (Page 209) • Minos (Page 197) • OB1 (Page 197) • XMP (Page 198) CHAPTER 18. MODELS VERSUS SOLVERS 215 18.6 Models involving CVaR constraints or objective 18.6.1 Finite discrete distribution • BPMPD (Page 199) • CVaRMin (Page 209) • HiPlex (Page 196) • HOPDM (Page 196) • Minos (Page 197) • OB1 (Page 197) • XMP (Page 198) Bibliography [1] M. Abramowitz and I.A. Stegun. Handbook of mathematical functions. National Bureau of Standards, 1964. [2] J.H. Ahrens and U. Dieter. A convenient sampling method with bounded computation times for poisson distributions. In P.R. Nelson, A. Dudewicz, A. Öztürk, and E.C. van der Meulen, editors, The frontiers of statistical computation, simulation and modeling, pages 137–149. American Sciences Press, Syracuse NY, 1991. [3] J. F. Benders. Partitioning procedures for solving mixed variables programming problems. Numer. Math., 4:238–252, 1962. [4] J. R. Birge. The value of stochastic solution in stochastic linear programs with fixed recourse. Math. Prog., 24:314–325, 1982. [5] J. R. Birge. Decomposition and partitioning methods for multistage stochastic linear programs. Oper. Res., 33:989–1007, 1985. [6] J. R. Birge, M. A. H. Dempster, H. I. Gassmann, E. Gunn, A. J. King, and S. W. Wallace. A standard input format for multiperiod stochastic linear programs. Working Paper WP-87-118, IIASA, Laxenburg, Austria, 1987. [7] J.R. Birge and F. Louveaux. Introduction to stochastic programming. Springer-Verlag, 1997. [8] A. Brooke, D. Kendrick, A. Meeraus, and R. Raman. GAMS. A user’s guide. Technical report, GAMS Development Corporation, Washington DC, USA, 1998. It can be downloaded from http://www.gams.com/docs. [9] J. Dagpunar. Principles of random variate generation. Clarendon Press, 1988. [10] G. B. Dantzig. Linear programming and extensions. Princeton University Press, 1963. [11] I. Deák. Three digit accurate multiple normal probabilities. Numer. Math., 35:369– 380, 1980. [12] I. Deák. Random number generators and simulation. Akadémiai Kiadó, 1990. 216 BIBLIOGRAPHY 217 [13] I. Deák. Subroutines for computing normal probabilities of sets – Computer experiments. Ann. Oper. Res., 100:103–122, 2000. [14] L. Devroye. Non–uniform random variate generation. Springer-Verlag, 1986. [15] H.I. Gassmann. MSLiP: A computer code for the multistage stochastic linear programming problem. Math. Prog., 47:407–423, 1990. [16] P. L’Ecuyer. Random number generation. In J. Banks, editor, Handbook on Simulation, Chapter 4. John Wiley & Sons, 1998. [17] M. Evans, N. Hastings, and B. Peacock. Statistical distributions. John Wiley & Sons, 1993. [18] J. Gondzio. HOPDM (version 2.12) – A fast LP solver based on a primal–dual interior point method. Eur. J. Oper. Res., 85:221–225, 1995. [19] J. L. Higle and S. Sen. Stochastic decomposition: An algorithm for two-stage linear programs with recourse. Methods of Oper. Res., 16:650–669, 1991. [20] J. L. Higle and S. Sen. Guidelines for a computer implementation of stochastic decomposition algorithms. Technical report, Systems and Industrial Engineering Department, University of Arizona, Tucson, February 1991. [21] J. L. Higle and S. Sen. Stochastic decomposition. A statistical method for large scale stochastic linear programming. Kluwer Academic Publ., 1996. [22] K. Hoyland, M. Kaut, and S. W. Wallace. A heuristics for generating scenario trees for multistage decision problems. Technical report, Stochastic Programming E-Print Series, 2002. http://dochost.rz.hu-berlin.de/speps. [23] C. C. Huang, W. T. Ziemba, and A. Ben-Tal. Bounds on the expectation of a convex function of a random variable: With applications to stochastic programming. Oper. Res., 25:315–325, 1977. [24] N.L. Johnson and S. Kotz. Continuous univariate distributions. Houghton Mifflin, 1970. [25] N.L. Johnson, S. Kotz, and A.W. Kemp. Univariate discrete distributions. John Wiley & Sons, 1992. [26] P. Kall. Approximations to stochastic programs with complete fixed recourse. Numer. Math., 22:333–339, 1974. [27] P. Kall. Stochastic linear programming. Springer-Verlag, 1976. [28] P. Kall. On approximation and stability in stochastic programming. In J. Guddat, H. Th. Jongen, B. Kummer, and F. Nožička, editors, Parametric Optimization and Related Topics, pages 387–407. Akademie–Verlag, 1987. BIBLIOGRAPHY 218 [29] P. Kall and D. Stoyan. Solving stochastic programming problems with recourse including error bounds. Math. Operationsforsch. Statist., Ser. Opt., 13:431–447, 1982. [30] P. Kall and J. Mayer. SLP-IOR: A model management system for stochastic linear programming — system design —. In A.J.M. Beulens and H.-J. Sebastian, editors, Optimization-Based Computer-Aided Modelling and Design, pages 139–157. SpringerVerlag, 1992. [31] P. Kall and J. Mayer. A model management system for stochastic linear programming. In P. Kall, editor, System Modelling and Optimization, pages 580–587. Springer-Verlag, 1992. [32] P. Kall and J. Mayer. SLP-IOR: On the design of a workbench for testing SLP codes. Preprint, IOR, University of Zurich, 1992. [33] P. Kall and J. Mayer. SLP-IOR: A model management system for stochastic linear programming. In G. Hellwig, P. Kall, and P. Abel, editors, Statistical Methods for Decision Processes, pages 54–63. Daimler Benz AG, Stuttgart-Möhringen, 1994. [34] P. Kall and J. Mayer. Computer support for modeling in stochastic linear programming. In K. Marti and P. Kall, editors, Stochastic Programming: Numerical Techniques and Engineering Applications, pages 54–70. Springer-Verlag, 1995. [35] P. Kall and J. Mayer. SLP–IOR: An interactive model management system for stochastic linear programs. Math. Prog., 75:221–240, 1996. [36] P. Kall and J. Mayer. On solving stochastic linear programming problems. In K. Marti and P. Kall, editors, Stochastic Programming Methods and Technical Applications, pages 329–344. Springer-Verlag, 1998. [37] P. Kall and J. Mayer. On testing SLP codes with SLP–IOR. In F. Giannessi, T. Rapcsák, and S. Komlósi, editors, New trends in mathematical programming, pages 115–135. Kluwer Academic Publ., 1998. [38] P. Kall and J. Mayer. On the role of bounds in stochastic linear programming. Optimization, 47:287–301, 2000. [39] P. Kall and J. Mayer. Modeling support for multistage recourse problems. In K. Marti, Y. Ermoliev, and G. Pflug, editors, Dynamic stochastic optimization, Lecture Notes in Economics and Math. Systems 532, pages 21–41. Springer-Verlag, 2004. [40] P. Kall and J. Mayer. Stochastic linear programming. Models, theory and computation. Springer-Verlag, 2005. [41] P. Kall and J. Mayer. Building and solving stochastic linear programming models with SLP-IOR. In S.W. Wallace and W.T. Ziemba, editors, Applications of Stochastic Programming, Series in Optimization, chapter 6, pages 79–93. MPS SIAM, SIAM, Philadelphia, 2005. BIBLIOGRAPHY 219 [42] P. Kall and J. Mayer. Some insights into the solution algorithms for SLP problems. Ann. Oper. Res., 142:147–164, 2006. [43] P. Kall and S. W. Wallace. Stochastic programming. John Wiley & Sons, 1994. [44] E. Keller. GENSLP: A program for generating input for stochastic linear programs with complete fixed recourse. Manuscript, IOR, University of Zurich, 1984. [45] W. J. Kennedy Jr. and J. E. Gentle. Statistical computing. Marcel Dekker, 1980. [46] W.K. Klein Haneveld. Duality in stochastic linear and dynamic programming. Springer-Verlag, 1986. Lecture Notes in Economics and Mathematical Systems 274. [47] W.K. Klein Haneveld, L. Stougie, and M.H. Van der Vlerk. An algorithm for the construction of convex hulls in simple integer recourse programming. Ann. Oper. Res., 64:67–81, 1996. [48] W.K. Klein Haneveld and M.H. Van der Vlerk. Integrated chance constraints: reduced forms and an algorithm. Computational Management Science, 2006. To appear. Originally appeared as Research Report 02A33, SOM, University of Groningen, 2002. [49] D.E. Knuth. The art of computer programming; Volume 2; Seminumerical algorithms. Addison-Wesley Publ. Co., third edition, 1998. [50] A. Künzi-Bay and J. Mayer. Computational aspects of minimizing conditional value– at–risk. Computational Management Science, 3:3–27, 2006. [51] Y.L. Luke. The special functions and their applications. Academic Press, 1969. [52] I. Maros. A general Phase–I method in linear programming. Eur. J. Oper. Res., 23:64–77, 1986. [53] R. E. Marsten. The design of the XMP linear programming library. ACM Transactions on Mathematical Software, 7:481–497, 1981. [54] R. E. Marsten, M. J. Saltzman, D. F. Shanno, G. S. Pierce, and J. F. Ballintijn. Implementation of a dual affine interior point algorithm for linear programming. ORSA Journal on Computing, 4:287–297, 1989. [55] J. Mayer. Probabilistic constrained programming: A reduced gradient algorithm implemented on PC. Working Paper WP-88-39, IIASA, 1988. [56] J. Mayer. Stochastic Linear Programming Algorithms: A Comparison Based on a Model Management System. Gordon and Breach, 1998. [57] J. Mayer. On the numerical solution of jointly chance constrained problems. In S. Uryasev, editor, Probabilistic constrained optimization: Methodology and applications, pages 220–233. Kluwer Academic Publ., 2000. BIBLIOGRAPHY 220 [58] J. Mayer. On the numerical solution of stochastic optimization problems. In F. Ceragioli, A. Dontchev, H. Futura, K. Marti, and L. Pandolfi, editors, System Modeling and Optimization, pages 193–206. Springer-Verlag, 2006. [59] Cs. Mészáros. The augmented system variants of IPM’s in two stage stochastic programming. Eur. J. Oper. Res., 101:317–327, 1997. [60] B. A. Murtagh and M. A. Saunders. Large scale linearly constrained optimization. Math. Prog., 14:41–72, 1978. [61] J. Palmquist, S. Uryasev, and P. Krokhmal. Portfolio optimization with conditional Value–at–Risk objective and constraints. The Journal of Risk, 4(2), 2002. [62] A. Prékopa. Stochastic programming. Kluwer Academic Publ., 1995. [63] B.D. Ripley. Stochastic simulation. John Wiley & Sons, 1987. [64] T.R. Rockafellar and S.P. Uryasev. Optimization of Conditional Value–at–Risk. Journal of Risk, 2:21–41, 2000. [65] R.Y. Rubinstein. Simulation and the Monte Carlo method. John Wiley & Sons, 1981. [66] A. Ruszczyński. A regularized decomposition method for minimizing a sum of polyhedral functions. Math. Prog., 35:309–333, 1986. [67] A. Ruszczyński and A. Świȩtanowski. Accelerating the regularized decomposition method for two stage stochastic linear programming problems. Eur. J. Oper. Res., 101:328–342, 1997. [68] N. Shor, T. Bardadym, N. Zhurbenko, A. Likhovid, and P. Stetsyuk. The use of nonsmooth optimization methods in stochastic programming problems. Kibernetika i Sistemniy Analiz, (5):33–47, 1999. (In Russian); English translation: Cybernetics and System Analysis, vol. 35, No. 5, pp. 708–720, 1999. [69] T. Szántai. Calculation of the multivariate probability distribution function values and their gradient vectors. Working Paper WP-87-82, IIASA, 1987. [70] T. Szántai. A computer code for solution of probabilistic-constrained stochastic programming problems. In Y. Ermoliev and R.J-B. Wets, editors, Numerical Techniques for Stochastic Optimization, pages 229–235. Springer-Verlag, 1988. [71] M. H. van der Vlerk. Stochastic programming with integer recourse. Labyrint Publ. Capelle aan den IJssel, The Netherlands, 1995. [72] M. H. van der Vlerk. On multiple simple recourse models. SOM Research Report 02A06, University of Groningen, 2002. [73] R. Van Slyke and R. J-B. Wets. L–shaped linear program with applications to optimal control and stochastic linear programs. SIAM J. Appl. Math., 17:638–663, 1969. Copyright and disclaimer notice COPYRIGHT The software SLP-IOR and the User’s Guide to it are both Copyright (c) 2000-2010 by the authors Peter Kall and Janos Mayer, Institute for Operations Research of the University of Zurich, All Rights Reserved. The authors grant you, the End User, a nonexclusive and non-transferable personal license to use this software under the terms stated in this agreement. You may use the software for academic purposes, on a single personal computer and make as many copies as needed for backup and archival. You may not distribute, modify, alter, translate, disassemble, decompile, sell, lease, or electronically transfer the software. The license is effective until terminated. You may terminate it at any time by destroying the software. The license will also terminate if you fail to comply with any term or condition of this agreement. You agree upon such termination to destroy the software. WARRANTY The authors and the Institute of Operations Research of the University of Zurich hereby disclaim all warranties relating to this software, whether express or implied, including without limitation any implied warranties of merchantability or fitness for a special purpose. The authors and the Institute for Operations Research of the University of Zurich will not be liable for any lost or anticipated profits, or for any incidental, special, consequential, indirect or exemplary damages, whether or not the authors or the Institute for Operations Research of the University of Zurich were advised of the possibility of such damages. The person using this software bears all risk as to the quality and performance of the software. This software is provided as it is, and you, the End User, assume all risks when using it. 221 Appendix A Checklists for using SLP–IOR The order of activities listed in this appendix corresponds to our suggested order for carrying them out. A.1 Setting up and solving a new LP model ~ Choose model type, [File],→[New Model Instance]. ~ Name the model instance, [Edit–Model],→[Name of Model]. ~ Specify direction of optimization, [Edit–Model],→[Min or Max]. ~ Enter number of stages (only for multistage), [Edit–Model],→[Number of Stages]. ~ Specify dimensions, [Edit–Model],→[Dimensions]. ~ Specify names for rows/columns [Edit–Model],→[Edit Names]. ~ Specify array elements, specify relations for the constraints (≤, =, ≥), [Edit–Model],→[Edit Data Arrays/Relations]. ~ Save the model instance, [File],→[SaveAs]. ~ Select a solver, [Solver–Lib],→[Select Solver]. ~ Initiate a solver run, [Solve],→[Solve Current Problem]. ~ On the form which pops up update run time parameters as desired, and subsequently click <Run Solver>. ~ View results, [Solve],→[View Results]. ~ Save results, [Solve],→[Edit Solution]. 222 APPENDIX A. CHECKLISTS FOR USING SLP–IOR A.2 223 Setting up and solving a new SLP model I In this variant random variables and random array entries coincide. ~ Set up the underlying LP as described above in Section A.1. ~ Specify the dimension of the random vector, [Edit–Model],→[Dimensions]. ~ Update random variable names, [Edit–Model],→[Edit Names]. ~ Specify stochastic dependency structure of the random vector, [Edit–Model],→[Edit Dependency]. ~ Choose the probability distribution, [Edit–Model],→[Edit Distribution]. ~ Establish the correspondence between random variables and random array entries, [Edit–Model],→[Pick Random Entries]. ~ Save the model instance, [File],→[SaveAs]. ~ Select a solver, [Solver–Lib],→[Select Solver]. ~ Initiate a solver run, [Solve],→[Solve Current Problem]. ~ On the form which pops up update run time parameters as desired, and subsequently click <Run Solver>. ~ View results, [Solve],→[View Results]. ~ Save results, [Solve],→[Edit Solution]. APPENDIX A. CHECKLISTS FOR USING SLP–IOR A.3 224 Setting up and solving a new SLP model II In this variant random variables and random array entries do not coincide. ~ Set up the underlying LP as described above in Section A.1. ~ Specify the dimension of the random vector, [Edit–Model],→[Dimensions]. ~ Update random variable names, [Edit–Model],→[Edit Names]. ~ Specify stochastic dependency structure of the random vector, [Edit–Model],→[Edit Dependency]. ~ Choose the probability distribution, [Edit–Model],→[Edit Distribution]. ~ Choose those arrays first which will contain random entries, [Edit–Model],→[Stochastic Parts]. ~ Establish the correspondence between random variables and random array entries by editing (updating) the regression terms which establish the connection, [Edit–Model],→[Edit Regression Terms]. ~ Save the model instance, [File],→[SaveAs]. ~ Select a solver, [Solver–Lib],→[Select Solver]. ~ Start up the solver, [Solve],→[Solve Current Problem]. ~ View results, [Solve],→[View Results]. ~ Save results, [Solve],→[Edit Solution]. APPENDIX A. CHECKLISTS FOR USING SLP–IOR A.4 225 Recasting a deterministic LP as a two–stage recourse model I We suppose for the sake of simplicity that in the targeted two–stage model random variables coincide with random entries. Let us suppose also that the technology matrix of the LP consists solely of the rows of the matrices A and T̄ . ~ Transform the model into a two–stage fixed recourse model via [Analyze],→[Transform Model]. ~ Enter the number of variables in the second stage, via [Edit–Model],→[Dimensions]. ~ By utilizing [Edit–Model],→[Recast Model] perform the following operations: ~ Move the constraints (rows) which should belong to the second stage from the current first stage into the second stage. ~ Delete the zero row in the second stage, which has automatically been introduced during the transformation. ~ Update the recourse matrix W (which is a zero matrix currently), and relations via [Edit–Model],→[Edit Data Arrays/Relations]. ~ Update names in the second stage, [Edit–Model],→[Edit Names]. ~ Specify the dimension of the random vector, [Edit–Model],→[Dimensions]. ~ Update random variable names, [Edit–Model],→[Edit Names]. ~ Specify stochastic dependency structure of the random vector, [Edit–Model],→[Edit Dependency]. ~ Choose the probability distribution, [Edit–Model],→[Edit Distribution]. ~ Establish the correspondence between random variables and random array entries, [Edit–Model],→[Pick Random Entries]. ~ Save the model instance, [File],→[SaveAs]. APPENDIX A. CHECKLISTS FOR USING SLP–IOR A.5 226 Recasting a deterministic LP as a two–stage recourse model II We suppose for the sake of simplicity that in the targeted two–stage model random variables coincide with random entries. Let us suppose also that the technology matrix of the LP contains also columns which should belong to the recourse matrix. ~ Transform the model into a two–stage fixed recourse model via [Analyze],→[Transform Model]. ~ Enter the number of variables in the second stage, via [Edit–Model],→[Dimensions]. ~ By utilizing [Edit–Model],→[Recast Model] perform the following operations: ~ Move the constraints (rows) which should belong to the second stage from the current first stage into the second stage. ~ Delete the zero row in the second stage, which has automatically been introduced during the transformation. ~ Move variables (columns) from the first stage to the second stage. Please notice that this will cut off elements in the moved column with row indices belonging to the first stage. ~ Delete superfluous zero columns in the second stage. ~ Update the recourse matrix W if it should contain additional elements which do not originate in the deterministic LP, update relations, via [Edit–Model],→[Edit Data Arrays/Relations]. ~ Update names in the second stage, [Edit–Model],→[Edit Names]. ~ Specify the dimension of the random vector, [Edit–Model],→[Dimensions]. ~ Update random variable names, [Edit–Model],→[Edit Names]. ~ Specify stochastic dependency structure of the random vector, [Edit–Model],→[Edit Dependency]. ~ Choose the probability distribution, [Edit–Model],→[Edit Distribution]. ~ Establish the correspondence between random variables and random array entries, [Edit–Model],→[Pick Random Entries]. ~ Save the model instance, [File],→[SaveAs]. APPENDIX A. CHECKLISTS FOR USING SLP–IOR A.6 227 Recasting a deterministic LP as a jointly chance– constrained model For the jointly chance–constrained model we use the denotations of Section 3.3. We suppose for the sake of simplicity that in the targeted two–stage model random variables coincide with random entries. ~ Transform the model into a jointly chance–constrained model via [Analyzes],→[Transform Model]. ~ By utilizing [Edit–Model],→[Recast Model] perform the following operations: ~ Move the constraints (rows) which should belong to the stochastic part from the deterministic part into the stochastic part. ~ Delete the zero row in the stochastic part, which has automatically been introduced during the transformation. ~ Update the probability level α if necessary, via [Edit–Model],→[Edit Data Arrays/Relations]. ~ Update names in the second stage, [Edit–Model],→[Edit Names]. Pay special attention to the relations in the stochastic part, which should be inequalities for this model type. ~ Specify the dimension of the random vector, [Edit–Model],→[Dimensions]. ~ Update random variable names, [Edit–Model],→[Edit Names]. ~ Specify stochastic dependency structure of the random vector, [Edit–Model],→[Edit Dependency]. ~ Choose the probability distribution, [Edit–Model],→[Edit Distribution]. ~ Establish the correspondence between random variables and random array entries, [Edit–Model],→[Pick Random Entries]. ~ Save the model instance, [File],→[SaveAs]. APPENDIX A. CHECKLISTS FOR USING SLP–IOR A.7 228 Computing the overall objective for a first–stage vector Choose [Analyze],→[Analyze Solutions] and utilizing the form which pops up proceed as follows: ~ Choose a first–stage solution vector by utilizing the facilities: ~ [Pick first–stage solution from solver run], or ~ [Pick solution of the expected value problem], or ~ [Edit first–stage solution], or ~ [Load new first–stage solution]. ~ By clicking <Toggle Evaluate/Simulate> ensure that the desired modus of operation is active. Please notice that Complete evaluation is only available if the joint distribution is finite discrete. ~ If the modus is Simulation update the sample size and seeds as desired. ~ Carry out the computation by clicking <Compute> under the heading Compute objective value. ~ If you also wish to compute the reliability of the first–stage solution click <Compute> under that heading. APPENDIX A. CHECKLISTS FOR USING SLP–IOR A.8 229 Computing EVPI and VSS Choose [Analyze],→[Analyze Model Instance] and utilizing the form which pops up proceed as follows: ~ By clicking <Toggle Evaluate/Simulate> ensure that the desired modus of operation is active. Please notice that Complete evaluation is only available if the joint distribution is finite discrete. ~ If the modus is Simulation update the sample size and seeds as desired. ~ Click <EV: solve expected value problem>. ~ Click <WS: compute wait and see solution>. ~ If for the recourse problem there is no solution available click <RS: compute recourse solution> which will ~ start up the solver dialog in the Complete evaluation modus, or ~ build and solve the Monte–Carlo approximation to the recourse problem in Simulation modus. ~ Click <EEV: compute expected result>. After this operation both EVPI and VSS can be seen in the corresponding view boxes. APPENDIX A. CHECKLISTS FOR USING SLP–IOR A.9 230 Discretizing the probability distribution for a group of random variables Choose [Rand–Vars],→[Sample/Discretize Per Group] and utilizing the form which pops up proceed as follows: ~ Choose one of the mutually independent groups of random variables by clicking its name in the list located at the right hand side of the form. ~ By utilizing the facilities in the central part of the form: Choose sample size, seeds and sampling method. ~ By utilizing the facilities in the central part of the form: For distributions with an unbounded support choose the truncation of the support by clicking the radio button (or its caption) [Edit Support]. ~ By utilizing the facilities in the central part of the form: Compute the sample by clicking [Compute]. ~ By utilizing the facilities in left hand side part of the form: Specify the subdivision of the truncated support by clicking [Edit Subdivision]. ~ By utilizing the facilities in left hand side part of the form: Click [Draw] for carrying out the discretization. APPENDIX A. CHECKLISTS FOR USING SLP–IOR A.10 231 Performing a test run with a battery Choose [Workbench],→[Test Problem Batteries] and utilizing the form which pops up proceed as follows: ~ Choose the model instances which constitute the battery via <new battery>. ~ Load a test problem which represents the model type of the battery elements, via <load model instance>. ~ Select a group of solvers via <select solvers>. ~ Update the selected solvers’ run time parameters if needed, via <update solver parameters>. ~ Start up the test run by clicking <run test battery>. Each of the test problems in the battery will be solved by each of the selected solvers in turn. ~ View the results by clicking <view results>. ~ Save the results by clicking <save results>. Appendix B Glossary Array is either a vector or a matrix. Battery is a set of test problems, mainly used for testing solvers. Blackboard is a directory for temporary storage of various arrays, samples etc. It is not automatically cleared when a modeling session is closed. Building blocks are structural parts of the model. The purpose of their usage is supporting the model building phase. They can be extracted from the model instance and saved on disk as well as loaded from disk and injected into the current model instance. Two levels of building blocks are available: on the higher level these correspond to the underlying algebraic–, random variables– and regression structures (see Chapter 3). On the lower level building blocks are arrays. Check box is an element of the user interface which serves for activate/deactivate features. They have two states: unchecked or checked ; toggling between the two states can be accomplished by left–clicking either the box itself or its caption (text to the right). There is another type of check box associated , which can only be checked/unchecked by right– with lists, like clicking the box itself. Direction of optimization means either maximization or minimization. Density of an array means the density of nonzeros in the array, expressed as percentage. More precisely, let the array dimension be (m × n), let k be the number of k nonzero elements, and let d be the density. Then the following holds: d = ·100. m·n Edit box is an element of the user interface which serves for editing/viewing various entities, it looks like . GAMS is a General Algebraic Modeling System and serves for formulating optimization models in an algebraic modeling language and solving them with one of the 232 APPENDIX B. GLOSSARY 233 available powerful solvers, see Brooke, Kendrick, Meeraus and Raman, [8] Having access to GAMS is not mandatory for using SLP–IOR. If the user has GAMS this has the following advantages: the user can formulate the underlying LP in the powerful modeling language GAMS and import it subsequently into SLP–IOR for the purpose of building stochastic variants of it. Additionally, the general purpose solvers licensed with GAMS are available from SLP–IOR: the system automatically writes LP problems (e.g. equivalent LP’s for a recourse problem) in the GAMS language, transmits them to GAMS, and retrieves the solution. GENSLP is a program integrated into SLP–IOR for randomly generating test problem batteries. The model instances in the battery are all of the same type and size. Available model types are deterministic LP’s, two stage recourse problems, multistage recourse problems and jointly chance constrained problems. Log book serves for logging the main actions during a modeling session. It can be viewed by right clicking the main form and choosing [Log Book] in the pop up menu. Modeling status is a display showing the current model characteristics including dimensions, random variable structure etc. It can be viewed by right clicking the main form and choosing [Modeling Status] in the pop up menu. Modeling session is the period between starting up and shutting down SLP–IOR. Notes are associated with model instances. They can e.g. be used to record origins of the problem, analysis results, etc. The current notes can be viewed by right clicking the main form and choosing [Notes] in the pop up menu. Radio button group is an element of the user interface which serves for choosing between mutually exclusive items, like: . Choosing an item can be accomplished by right–clicking either the button or its caption (the name to the right to it). Solver is a computer implementation of a solution algorithm. Solver library is a library of solvers, which are currently available with SLP–IOR. It consists of two parts: a solver description database and the corresponding exe or bat files. SMPS format is a standard data format for (multistage) recourse problems, see Birge, Dempster, Gassmann, Gunn, King, and Wallace [6]. It is an extension of the MPS data format of IBM for LP’s, and consists in general of three files per model instance. The underlying LP corresponds roughly to the COR file, the TIM file serves for representing the decision stages, and finally the stochastic structure is represented in the STO file. Author Index A K Ahrens, J.H., 178, 180 Kall, P., 11, 14, 15, 28, 40, 45, 46, 50, 59, 136, 160, 201–203, 221 Kaut, M., 151, 155 Keller, E., 160 Kendrick, D., 233 Kinderman, A.J., 179 King, A.J., 99, 233 Klein Haneveld, W.K., 37, 40, 42, 45, 61–63, 204 Knuth, D., 179 Krokhmal, P., 46, 50 Künzi–Bay, A., 13–15, 209 B Ballintijn, J.F., 14, 197 Bardadym, T., 59, 200 Ben–Tal, A., 59 Benders, J.F., 58 Birge, J.R., 28, 58, 76, 99, 233 Box, G.E.P, 179 Brooke, A., 233 D Dantzig, G.B, 62 Deák, I., 17, 206, 207 Dempster, M.A.H., 99, 233 Dieter, U., 178, 180 G L L’Ecuyer, P., 179 Lewis, T.G, 179 Likhovid, A., 14, 17, 59, 200, 203 Louveaux, F., 28 M Gassmann, H.I., 14, 17, 58, 76, 99, 199, 233 Maros, I., 14, 17, 196 Gill, P.E., 197 Marsaglia, G., 165, 179 Gondzio, J., 14, 17, 196 Marsten, R.E., 14, 195, 196 Gunn, E., 99, 233 Mayer, J., 11, 13–15, 28, 40, 45, 46, 50, 201– 209, 221 Meeraus, A., 233 H Mészáros, Cs., 13, 17, 58, 199 Higle, J.L., 17, 59, 202 Miller, K.W., 179 Hoyland, K., 151, 155 Muller, M.E., 179 Huang, C.C., 59 Murray, W., 197 Murtagh, B.A., 14, 197 234 AUTHOR INDEX P Palmquist, J., 46, 50 Park, S.K., 179 Payne, W.H., 179 Pierce, G.S., 14, 197 Prékopa, A., 17, 28, 31 R Ramage, J.G., 179 Raman, R., 233 Ripley, B.D., 179 Rockafellar, R.T., 46, 50 Ruszczyński, A., 14, 17, 59, 200 S Saltzman, M.J., 14, 197 Saunders, M.A., 14, 197 Sen, S., 17, 59, 202 Shanno, D.F., 14, 197 Shor, N., 14, 17, 59, 200, 203 Stetsyuk, P., 59, 200 Stougie, L., 61, 204 Stoyan, D., 59 Świȩtanowski, A., 17 Szántai, T., 17, 206–208 U Uryasev, S., 46, 50 V Van der Vlerk, M.H., 12, 14, 15, 17, 40, 45, 60, 61, 63, 204, 205 Van Slyke, R., 58 W Wallace, S.W., 28, 99, 136, 151, 155, 233 235 Wets, R. J-B., 58 Wright, M.H., 197 Z Zhurbenko, N., 59, 200 Ziemba, W.T., 59 Subject Index Algeb–Equi menu Build Algebraic Equivalent, 140 Drop It, 140 Edit It, 140 Write MPS File, 140 Algeb–Struct menu Check for complete recourse, 142 Compute rank of an array, 142 Perturb Array, 141–142 Analyze menu Analyze Model Instance, 134–136 Analyze Solutions, 137 Check Complete Recourse, 136 Check Simple Recourse, 136 Transform Model, 138 availability of SLP–IOR, 11 chance constraints, separate, 33 equivalent LP, 35 expected value problem, 35 underlying algebraic structure, 34 underlying LP, 34 underlying random variables structure, 34 underlying regression structure, 34 configuring SLP–IOR, 20 contact the authors, 11 CVaR constraints or objective, 46 algebraic equivalent LP, 49 expected value problem, 49 underlying algebraic structure, 48 underlying LP, 48 underlying random variables structure, 48 underlying regression structure, 48 CVaRMin, 13, 209 B D A Blackboard, 232 BPMPD, 13, 58, 199 bug report, 11 DAPPROX, 14, 59, 201 DECOMP, 17 deterministic LP, 30 multistage, 51 one stage, 30 C directories blackboard for intermediate storage, 19, chance constraints, joint, 30 21 expected value problem, 32 default directory structure, 19 underlying algebraic structure, 31 GAMS system directory, 24 underlying LP, 32 SLP problems, GAMS, 19, 21 underlying random variables structure, SLP problems, SLP–IOR format, 19, 21 31 SLP problems, SMPS standard, 19, 21 underlying regression structure, 32 SLP problems, test batteries, 19, 21 236 SUBJECT INDEX 237 Edit Distribution on Scenario Tree, 116, SLP–IOR system directory, 19, 24 117 solvers, 19 Edit Names, 107 distribution Edit Regression Terms, 111 beta, 180 Edit Underlying LP, 108 binomial, 177 Editing node–data of a scenario tree, 118 Cauchy, 180 Min or Max, 104 Chi Squared, 180 Name of Model, 103 exponential, 179 Number of Stages, 104 extreme value, 181 Pick Random Entries, 109–112 F, 181 Recast Model, 117–121 gamma, 179 Stochastic Parts, 108, 109 geometric, 178 EEV, see two–stage recourse model hypergeometric, 178 EV, see two–stage recourse model logistic, 181 EVPI, see two–stage recourse model lognormal, 182 multivariate (nondegenerate) normal, 183 multivariate empirical, 182 F multivariate lognormal, 183 multivariate uniform, 183 File menu negative binomial, 178 Browse, 99, 100 Pareto, 182 Exit, 102 Poisson, 178 Export/Import, 99–102 power function, 182 New Model Instance, 97, 98 t, 181 Open, 98 triangular, 182 Save, 99 univariate discrete uniform, 177 SaveAs, 98 univariate empirical, 177 univariate normal, 179 univariate uniform, 179 G Weibull, 180 GAMS, 12, 13, 19, 26, 83, 132, 233 distribution viewer, 174, 176 solvers, 26, 195 GENSLP, 93, 160, 161, 163–165, 233 E Edit–Model menu Array Selection, 110 Building Blocks I, 121, 122 Building Blocks II, 122 Dimensions, 104 Edit Data Arrays, 104–106 Edit Data Arrays/Relations, 106 Edit Dependency, 112–113 Edit Distribution, 114–115 H hardware, 15 HiPlex, 14, 196 history of SLP–IOR, 12 HOPDM, 14, 196 I ICCMIN, 14, 209 SUBJECT INDEX installing SLP–IOR, 18 integrated chance constraints, joint, 36 algebraic equivalent LP, 39 expected value problem, 39 underlying algebraic structure, 38 underlying LP, 38 underlying random variables structure, 38 underlying regression structure, 38 integrated chance constraints, separate, 41 algebraic equivalent LP, 44 expected value problem, 44 underlying algebraic structure, 43 underlying LP, 43 underlying random variables structure, 43 underlying regression structure, 43 L logbook, 233 LP, see deterministic LP M matrix editor, 171–173 popup menu, 172 matrix viewer, 173–175 menu system help, 20 main features, 12 main menu items, 20, 22, 25 Algeb–Equi, 140 Algeb–Struct, 141–142 Analyze, 134–139 Edit–Model, 102–123 File, 97–102 Options, 20, 21 Rand–Vars, 143 Solve, 127–133 View–Model, 123–126 Workbench, 160–170 popup menu, 24 238 MINOS, 14, 197 model classes in SLP–IOR, 28 modeling session, 233 status, 233 MScr2Scr, 14, 63, 205 MSDOS, 12 MSLiP, 14, 58, 76, 199 multiple simple recourse model, 61 equivalent complete recourse model, 62 equivalent simple recourse model, 63 multistage recourse model, 64 affine sums for random entries, 64 algebraic equivalent LP, 70 compact form, 70 cond. exp. nonanticipativity constraints, 72 explicit form, 71 implicit formulation, 70 ladder nonanticipativity constraints, 71 split–variable formulation, 71 state variable nonanticipativity constraints, 72 straight nonanticipativity constraints, 71 block–separable recourse, 75 computing the recourse objective, 74 expected value problem, 67 scenario tree, 68 stagewise independence, 65 underlying algebraic structure, 65 underlying LP, 66 underlying random variable structure, 66 underlying regression structure, 66 underlying two–stage model, 67 wait and see approach, 73 N NORSUBS, 206, 207 notes, 233 SUBJECT INDEX O OB1, 14, 197 Options menu Customize, 22 Delayed Messages, 23 Matrix Editor, 22 Random Number Generator, 23 Regional Setting for Numbers, 23 Scenario Tree Editor, 23 Update Solver Features, 23, 187 Usage level, 21 User Directories, 20 239 recourse model, multistage, see multistage recourse model recourse model, simple, see two–stage recourse model recourse model, simple integer, see two–stage recourse model recourse model, two–stage, see two–stage recourse model RFS, see two–stage recourse model RS, 135, 229 S SAA, 14 scenario tree, 68 scope of SLP–IOR, 28 P SDECOM, 14, 59, 202 PCSPIOR, 14, 206 setting up PCSPNOR3, 206–208 an SLP model, 223, 224 printing an array, 172 deterministic LP, 222 probabilistic constraints, joint, see chance SHOR1, 14, 59, 203 constraints, joint SHOR2, 14, 59, 200 probabilistic constraints, separate, see chance simple integer recourse model, 59 constraints, separate SIRD2SCR, 14, 61, 204 PROBALL, 14, 207 SMPS, 99–102, 184–186, 192, 233 PROCON, 14, 208 software, 15 publications concerning SLP–IOR, 15 sofware Borland Delphi, 15 Compaq Visual Fortran, 15 Q Solve menu Edit Solution, 131, 132 QDECOM, 14, 59, 200 Solve current problem, 127–129 Solver Files, 132 Summary on Run, 131 R View GAMS listing, 132 Rand–Vars menu View Results, 129–131 Generate Scenarios – Discretization, 150 View Solution on Tree, 131 Generate Scenarios – Moments, 151–158 solver, 233 Manually Build Scenario Tree, 149 solver library, 233 Sample/Discretize All, 147–148 Solver–Lib menu Sample/Discretize per Group, 143–147 Inspect Solvers, 23 recourse model, multiple simple, see two– Select Solver, 129 stage recourse model solvers SUBJECT INDEX 240 underlying LP problem, 54 connecting a new solver, 184–187 underlying random variable structure, description database, 184, 187–194 53 for deterministic LP, 196–199 underlying regression structure, 54 for integrated chance–constraints, 209 value of stochastic solution (VSS), 58, for joint chance–constraints, 206–208 135, 229 for multistage recourse, 196–199 wait and see approach (WS), 56, 135, for optimizing CVaR, 209 229 for separate chance–constraints, 196–199 for two–stage complete recourse, 200– 202 for two–stage fixed recourse, 199, 200 U for two–stage general recourse, 196–199 uniform random numbers, 179 for two–stage multiple simple recourse, Knuth, 179 205 Lewis and Payne, 179 for two–stage simple integer recourse, Park, Miller, L’Ecuyer, 179 204 Ripley, 179 for two–stage simple recourse, 203 short list, 13 SRAPPROX, 14, 59, 63, 130, 203 V starting up SLP–IOR, 19 View–Model menu student version of SLP–IOR, 26–27 View Data Arrays, 123 View Random Variables Map, 124–125 View Underlying LP Structure, 123–124 T VSS, see two–stage recourse model two–stage recourse model, 51 affine sums for random entries, 52 algebraic equivalent LP, 55 W complete recourse, 52 Windows, 12, 13, 15 expected result (EEV), 57, 135, 229 expected value of perfect information (EVPI), check box, 232 clipboard, 80, 172 58, 135, 229 edit box, 232 expected value problem (EV), 54, 135, radio button group, 233 229 WinZip, 18 fixed recourse, 52 Workbench integer recourse, 52 GENSLP: joint chance constraint, 163– multiple simple recourse, see multiple 166 simple recourse model GENSLP: LP and recourse problems, 160– random recourse, 52 163 reliability of two–stage solution (RFS), Test Problem Batteries, 166–170 58, 137 WS, see two–stage recourse model simple integer recourse, 59 simple recourse, 52 underlying algebraic structure, 53 SUBJECT INDEX X XMP, 14, 198 241