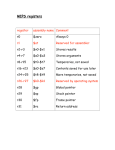
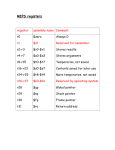
Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Mixed Model Analysis of Data: Transition from GLM to MIXED
Ramon C. Littell, Department of Statistics, University of Florida, Gainesville, FL
ABSTRACT
methods which accommodate the random effects.
The GLM procedure, initially written for fixed effect
models, does not adequately deal with all needs for
random effects.
The MIXED procedure was
conceived from the outset to handle random effects.
The GLM procedure has been the workhorse for
mixed model applications in the SAS® System. Other
procedures, including NESTED and VARCOMP, are
used for specific applications. Since its introduction
in 1976, GLM has been enhanced with several mixed
model facilities such as the RANDOM and
REPEATED statements. However, there are aspects
of certain models that none of these facilities fully
accommodate, such as structured covariance
matrices for repeated measures data. The MIXED
procedure allows applications of models previously
not possible within the SAS System. In this paper,
an overview comparison is given between GLM and
MIXED. Examples will be presented comparing
output from both procedures when either is
appropriate to assist users in the transition from GLM
to MIXED. Other examples will be presented which
illustrate the use of MIXED in applications for which
GLM is not adequate.
These concepts for fixed and random effects extend
to more complicated investigations such as split plot
and repeated measures experiments and to
observational studies. The prevailing feature of
mixed models is that random effects create
covariance between observations. A crucial step in
data analysis is to adequately model the covariance
structure of the data.
In concept, the MIXED
procedure has facilities that permit you to do this.
Actually running the MIXED procedure, except on
simple examples, can be a challenge because of
complexities of the covariance structure.
RANDOMIZED COMPLETE BLOCKS
One of the simplest and most common examples of
a mixed model is provided by the randomized
complete blocks (RCB) experimental design, with
random blocks and fIXed treatments. Letting Y,j
denote the response for treatment i in block j, the
equation for the model is
INTRODUCTION
The phrase 'mixed linear models' refers to models
which contain both fixed and random effects. Fixed
effects usually arise from factors whose levels are
being investigated and compared in an experimental
or observational study. Random effects often occur
as a result of sampling a population to obtain
replication of measurements. One of the simplest
examples of a mixed model is provided by the
randomized blocks design. This model contains fixed
effects for 'treatment" contributions and random
effects for 'block' contributions.
The primary
objectives are to estimate and compare treatment
means.
The treatments are considered fixed
because the treatments in the experiment are the
only ones to which you wish to make inference. The
blocks are considered random because the blocks in
the experiment 'are only a small subset of the
population of blocks over which you wish to make
inference about treatment means. You wish to
estimate and compare treatment means with
statements of preciSion (standard errors) and levels
of statistical significance (from tests of hypothesis)
which are valid in inference to the entire population of
blocks, not just those in the experiment. To do so
requires proper specification of random effects in
model equations and computations for statistical
where I' and 'i are fIXed parameters such that the
mean for the i th treatment is I'i ~ I' i' bj is the
random effect associated with the jth block, and £ ij is
error associated with the experimental unit in block j
which received treatment i. The block effects are
assumed to be distributed normally and
+,
independently with mean 0 and variance o~; that is,
bi - NIO(O, o~) . Ukewise, experimental errors are
assumed to be £ q - NIO(O,if). These are the
conventional assumptions for the randomized blocks
design. Denoting the observed mean for treatment i
as
Y;. ~ '-'l:Yq, it follows that
J
and
1050
Y,.- Y2 • ~ I',-I'2+£' .-~ ..
From these expressions, you see that the variances
treatment mean from a randomized blocks design is
simply MS(Error)/r. This misconception prevails 'in
many text books and in incorrect calculation of
standard errors by computer program packages. It
also gives a starting point for comparison of the GLM
and MIXED procedures in the SAS System, as
illustrated with the following example from
Mendenhall, Wackerlyand Scheaffer (1990).
--
-
of V,. and Y,.- Y2 • are
(1)
and
V(Y,. - ~.) ~ 2d'/r
(2)
Notice that the variance of a treatment mean V( Y,.)
Data are presented for an RCB designed experiment,
in which blocks are INGOTs and treatments are
METAls (nickel, iron, or copper). The response is
the amount of PRESsure required to break a sample
of material from an INGOT which used the METAL as
the bonding agent
contains the block variance component a~ but the
variance of the difference between two means
V(Y,. - ~.) does not contain a~.
This is the
manifestation of the RCB controlling block variation;
dIfferences between treatments are estimated free of
block variation.
The SAS data set named RCB which contains the
data is presented in Figure ,.
Traditionally, data from RCBs are subjected to
analysis of variance (ANOVA). A standard ANOVA
table for the RCB, showing sources of variation,
degrees of freedom, mean squares, and expected
mean squares is:
OSS
1
2
3
4
5
6
7
Source of
Variation
MS
df
•
I.•
ExpMS
11
r-,
Blocks
t-,
Treatments
(r-,)(t-,)
Error
The
expression
MS(8Ik)
MS(Trt)
MS(Error)
4>2
in
Exp
if+t¢.
if+rtl
12
13
14
I.
15
1.
17
if
MS(Trt)
1.
2.
21
is
INGOT
METAL
PRES
1
1
1
2
2
2
3
3
3
4
4
4
5
5
5
n
61.0
i
c
71.9
n
67.S
68.8
6'.4
76.0
82.6
74.S
••
•
i
c
n
i
c
n
12.7
i
c
78.1
67.3
n
73.1
i
c
74.2
n
65.8
70.8
68.7
75.6
84.9
69.0
i
c
7
n
7
i
c
7
72.2
73.2
4>2 ~ ~(I1I-ii)2/(t-1). Thus 4>2 ~ 0 is equivalent to
/
11,
~
••.
~
Figure 1_ Data from an RCB Designed Experiment
11 t, and the expected mean squares show
that a valid test statistic for Ho: 11, ~ •.• ~ 11 t is F =
MS(Trt)/MS(Error). Also, the expected mean squares
reveal that estimates of the variance components are
r:r
First of all, to analyze the data with the GLM
procedure, run the statements;
proc glm data=rcb; class ingot metal;
model pres=ingot metal;
means metal;
contrast 'copper vs iron' metal 1 -1 0;
estimate 'copper vs iron' metal 1 -1 0;
estimate 'nickel mean' intercept 1 metal 0 0 1;
random ingot;
~ MS (EfTor)
and
o~ ~ (MS(Blk) -MS(EfTor))/t.
run;
It follows that estimates of V(Y,.) and V(Y,. - Y2 .)
are
V(Y,.) ~
Output from GLM, which has been edited for brevity,
appears in Figure 2. The ANOVA F = 6.36 for
METAL gives a valid test of the null hypothesis
MS(Blks)/rt+(t-1) MS(EfTor)/rt
Ho:l1c ~ 11/ ~ I1n' and the CONTRAST 'copper vs
and
V(Y,.- Y2 .) ~
iron' F ~ 11.02 gives a valid test of Ho:l1c ~ 11/.
Also, the standard error for the ESTIMATE 'copper vs
2 MS(EfTor)/r .
iron' is
The expression for V( Y,.) illustrates a common
misconception that the estimate of the variance of a
(2MS(Error)/7)'/2 ~ 1.72, which is an
estimate of (2d'/7),/2.
1051
But the standard error
printed
for
the
ESTIMATE
'nickel
mean'
is
REKL Variance Components Estimation Procedure
{MS{Error)/7)1/2 : 1.22, which is!!Q!an unbiased
Dependent Variable: PRES
estimate of the correct standard error ({if +a~)/7) 1/2.
The GLM procedure cannot directly produce the
correct standard error for a treatment mean from a
randomized blocks design. The RANDOM statement
in GLM produces expected mean squares but has no
effect on standard errors.
Iteration
Objective
Var(INGOT)
Var(Error)
o
50.87068437
11.44177778
10.37158730
1
50.87068437 11.44777778 10.37158730
Convergence criteria met.
Asymptotic Covariance ltatrix of Estimates
Var(INGO'l'}
76.04477922
-5.97610129
Var(IHGOT)
Var(Brror)
General Linear Hodels Proc:edure
Var(Error)
-5.97610129
17.92830386
Dependent variable: PRES
Source
OF
Mean Square
F Value
Pr > P
Hodel
8
50~O2l81
4.82
0.0016
10.37159
Error
12
COrrected 'l'otal
20
Source
OF
Type III HS
44.71492
F Value
Pr > F
4.31
0.0151
2
65.95048
6.36
0.0131
OF
Contrast MS
F Value
1
114.29571
11.02
Pr > F
0.0061
•
INGOT
METAL
COntrast
copper VB iron
Parameter
copper va iron
nickel mean
T for BO;
Estimate Parameter-D
Figure 3. VARCOMP Output for RCB Design.
Although the MIXED statements appear very much
like the GLM statements, their function is quite
different First of all, note that the MODEL statement
contains only fixed effects, in this case METAL The
effect INGOT is specified as being random in the
RANDOM statement.
The CONTRAST and
ESTIMATE statements have basically the same
purposes in GLM and MIXED, but in MIXED the
random effects are appropriately incorporated into
standard errors computed by the ESTIMATE
statement and into F tests computed by the
CONTRAST statement Output from the PROC
MIXED statements appears in Figure 4. Note the
Std Error
of Estimate
-5.7142857
-3.32
1.72142692
71.1000000
58.41
1.21723265
Figure 2. GLM Output for RCB Design.
variance component estimates
o~: 11.45 and
r? : 10.37. Also note the correct standard error for
ESTIMATE 'nickel mean' = 1.77.
You can use the VARCOMP procedure to get
estimates of the variance components. Run the
statements
The MIXED Procedure
proc varcomp method:reml data:rcb;
class ingot metal;
model pres=metal ingot/fixed=1;
run;
Results
in
Figure
r? = 10.37 and o~
3
show
REML
REML Estimation Iteration History
Evaluations
o
1
Objective
Criterion
79.32809232
74.70841482 0.00000000
Convergence criteria met.
1
estimates
Covariance Parameter Estimates (REHL)
Cov Par..
Ratio
Estimate
Std Error
:
11.45. Thus you see that the
estimate of the variance of a METAL mean is
{r?+a~)/7 = (10.37+11.45)/7
Iteration
INGOT
1.10376333
11.44777778
8.72036577
Residual
1.00000000
10.37158730
4.23418279
3.11, and the
Tests of Fixed Effects
standard error is (3.11) 1/2 : 1.77.
SOurce
NDF
2
You can use the MIXED procedure to obtain correct
standard errors and tests. Run the statements
DDF
Type III F
12
6.36
Pr > F
0.0131
ESTIMATE Statement Results
Parameter
copper vs iron
nickel mean
proc mixed data=rcb;
class ingot metal;
model pres=metal;
contrast 'copper vs iron' metal 1 -1 0;
estimate 'copper vs iron' metal 1 -1 0;
estimate 'nickel mean' intercept 1 metal 0 0 1;
random ingot;
run;
Estimate
Std Error
-5.71428571
71.10000000
1.72142692
1.76551753
CONTRAST Statement Resulta
SOurce
copper vs iron
NDF
1
DDF
F
Pr > F
12
11.02
0.0061
Figure 4. MIXED Output for RCB DeSign.
1052
GENERAL UNEAR MIXED MODEL
model resista=et wafer(et) pos et*pos;
test h=et e=wafer(et);
random wafer(et);
contrast 'et1 vs et2' et 1 -1 00 e=wafer(et);
contrast 'pos1 vs pos2' pos 1 -1 0 0;
contrast 'pos1 vs pos2 in en' pos 1 -1 00
et*pos 1-1 00000000000000;
contrast 'et1 vs et2 in POS1' et 1 -1 00
et*pos 1 000 -100000000000;
The RCB presents a good setting for introducing Iile
general setup of Iile general linear mixed model,
GLMM. The RCB model can be written in matrix
notation as
Y = XII + Zv +
~
,
run;
where Y is Iile vector of observations, II is a vector
of treatment fixed effects, V is a vector of random
block effects, and c is Iile vector of experiment
errors. The random vector v has a multivariate
normal alStribution wilil mean vector 0 and
General Li.nea:c Hodel. Procedure
Dependent Variable: RESISTA
covarianctl matrix a~/r' i.e., v- MVN (0, a~/r); and~
- MVN (0, ~/1r). This is a special case of Iile
GLMM,
Y = XII + Zv + ~ ,
Soarce
Dr Mean Square
M0d01
Error
23
2.
COrrected Total
'7
Soarce
Dr Type III MS
3
1.0373861
P Value
3.65
Pr > P
P value
Pr > P
0.0003
0 .. 0013
0.1111493
•
0.5343104
•
0.0899417
9.33
4.81
3.39
0.81
DF
Contrast HS
P Value
Pr > F
1
POSl VS POS2 IN E'rl 1
0.0710661
0.0400167
0.5541
E'l'l VS ET2 IN POSl
0.2166000
0.69
0.36
1.95
""
lGFER( E'l' )
where v - MVN(O, G) and ~ - MVN(O, R), and G
and R are only required to be covariance matrices.
It follows Iilat Y - MVN(XII, Z'GZ + R). Thus Iile
generalized least squares (and maximum likelihood)
estimate of II is
0.405051
POS
3
BT"1'05
Contrast
POSl VS POS2
1
0.3762972
0.0013
0.0345
0.fil25
0.4132
0.1755
Tests of Hypotheses using the 'type XII HS
for llAFER(Er) as an error term
where V = V(Y) = Z'GZ + R, (see Searle (1971)).
Also,
Source
E'l
COntrast
E',n VS E72·
In reality, Iile covariance matrices G and Rare
usually functions of unknown parameters which must
Source
be estimated. Also, the matrix X'V-1X will typically
be singular so Iilat a generalized inverse is used, but
Iilis has no bearing on issues in Iile present paper.
The RANDOM statement in PROC MIXED defines G
and Iile REPEATED statement defines R.
WAFER(E7)
DF
Type III KS
P Value
Pr > l'
3
1.0373861
1.94
0.2015
DF
Contrast KS
P Value
Pr > P
1
0.6936000
1.30
0.2815
Type III Expected Mean Sqnare
Var(Error) + 4 Var(WAFBR.(ET» + Q(E'l'.B':r+POS)
Var(Error) + 4 Var(iQFER(E'l'»
POS
Var(Error) +Q(POS,E'l'·POS)
E7"POS
Var(Error) +Q(Er.POS)
Contrast
COntrast Expected Mean Sqnare
E'1'1 VS ET2
Var(Ettor) + 4 Var(lG!'ER(Er»
CROSSED-NESTED EXPERIMENT
+ Q(E'l' ,ET·P05)
POS1 VS 1'052
Var(Error) +Q(POS,E'l''*POS)
This example of an experiment in Iile semiconductor
industry is from Uttell, Freund, and Spector (1991).
Twelve silicon wafers were selected from a lot, and
Ihree were randomly assigned to each of four levels
of a process variable named ET. The response
variable, RESISTAnce, was measured in circuits in
four POSitions on each wafer. Data were recorded
in a SAS data set named CHIPS, wilil variables ET,
WAFER, POS and RESISTA. Rgure 5 contains
output from Iile GLM statements
1'OS 1 VS 1'052 III E'l'1
Var(Error) +Q(POS,Er·POS)
E'l'1 'VS ET2 IN POS1
Var(Error) +Va.r(WUI'ER(E'l'» +Q(Er .. ET·POS)
Figure 5. GLM Output for Crossed-Nested Design.
Results can be used to complete Iile ANOVA in
Table 1.
proc glm data=chips; class et wafer pos;
1053
Source of
Variation
ET
WAFER(E1)
POS
ET"POS
ERROR
df
SS
MS
F
P
3
8
3
9
24
3.11
4.27
1.13
0.81
2.67
1.037
0.534
0.376
0.090
0.111
1.94
0.202
3.39
0.81
0.034
0.1>13
contrast 'pos1 vs pos2 in et1' pos 1 -1 0 0
et*pos 1 -1 00 0000 0000 0000;
contrast 'en vs et2 in pos1' et 1 -1 00
et*pos1 000 -100000000000;
run;
= 0!/. Since
=
Results
The RANDOM statement specifies G
0:1.
no REPEATED statement is used, R
appear in Figure 6, and agree closely witl1 tI1e hand
computations using GLM.
Note, however the
incorrect number (24) of degrees of freedom for the
contrast ET1 vs ET2 (should be 8).
Table 1. ANOVA for Crossed-Nested Design.
Proper F-tests for fixed effects in Table 1 can be
obtained from GLM. The option E=WAFER(El) in
the TEST and one of the CONTRAST statements
provide correct F tests for ET and the contrast ET1
vs ET2. But some contrasts cannot be correctly
tested by GLM. In particular, proper error terms are
not aVailable for simple effect tests for the ET factor,
nor are correct standard errors for POS means. You
can use expected means squares and otl1er features
of GLM in somewhat of a roundabout way to
The JUXED Procedure
covariance Parameter Estimates (REML)
COy Pa:rm
+o!
is needed both
determine tI1at an estimate of o~
for the F-test for the ET simple effect and the
standard error of the POS mean (see Uttell and
Unda, 1990, and Milliken and Johnson, 1984, Ch.
28). The linear combination of mean squares MS =
.7SMS(Error) + .2SMS(WAFER(ET)) = 0.217 is an
Std Error
0.10579028
0.06726878
Residual
1.00000000
0.11114931
0.03208604
Observations
o! +0=,
= MS(et1
Estimate
0.95178532
Model Fitting Information for RESISlA
Description
Value
and has approximately
unbiased estimate of
18 degrees of freedom according to Satterthwaite's
formula. The test statistic for the contrast is
F
Ratio
~(E7)
48.0000
Variance Estimate
0.1111
Standard Deviation Estimate
0.3334
REHL Loq Likelihood
-25.3252
Akaike's Information Criterion
-27.3252
Schvarz'. Bayesian Criterion
-28.7910
-2 REHL Log Likelihood
50.6505
Tests of Fixed Effects
DDP
Type III F
Pr > F
ET
NDP
l
8
}.94
0.2015
POS
l
3.39
0.0345
E'l'*POS
•
2.
2.
0.81
0.6125
Source
vs et2 in pos1)/MS
= 0.217/0.217 = 1.0 ,
and the standard error for the POS 1 mean is
CONTRAST Statement Results
(1i6~'1»1/2
= (MS/12)1/2 = 0.134
RDP
DDP
P
Pr> P
2.
2.
1.30
0.2658
POSl vs POS2
1
1
0.69
0.4132
POS1 vs POS2 IN BTl
1
2.
0.36
0.5541
BTl VS :ET2 IN paSl
1
2'
1.00
0.3277
SOur=
.
E'l'1 VS BTl
The contrast F test and standard error can be
obtained directly by PROC MIXED.
Rgure 6. MIXED Output for Crossed-Nested Design.
A statistical model for ti1e data is
REPEATED MEASURES EXPERIMENT
This example also comes from Uttell et al (1991).
Fifty-seven subjects participated in a study of three
exercise therapy programs involving weight lifting.
The programs CO NT, RI in which numbers of
repetitions of ti1e exercise were increased with
constaJ1t amount of weight, and WI in which amounts
of weight were increased with constant number of
repetitions. Strength of eaci1 subject was measured
at seven equally spaced time points. Objectives of
the study were to estimate and compare strength
profiles over time. Data were stored in a SAS data
where Yfie is the measurement at POS=k on
WAFER=j assigned to ET=i. This model is fitted with
the MIXED statements
proc mixed data=chips;
class et wafer pos;
model resista=et pos et*pos;
random wafer(et);
contrast 'en vs et2' et 1 -1 0 0 ;
contrast 'pos1 vs pos2' pos 1 -1 0 0 ;
1054
variable defining blocks. The 1YPE=CS specification
tells MIXED that the submatrices R~ for each SUBJ
are to have compound symmetric structure; that is,
equal variances cf on the .diagonal and equal
covariances pc! off the diagonal within each block.
Results appear in Figure 7. Covariance parameter
set named WEIGHTS. with variables PROGRAM.
SUBJ. and Sl-S7 (Sl = strength measurement at
time 1. etc.).
The structure of this data is similar to that of the
CHIPS data. with the correspondence
program subject time -
estimates yield Q2 = 9.60 + 1.20 and po" = 9.60.
Tests of significance for the fixed effects are similar
to tests that would be produced by a univariate
ANOVA using GLM. This is expected. because the
univariate ANOVA is based on an assumption that
the H-F covariance condition is met, which for
practical purposes is similar to compound symmetry.
In fact, equivalent results would be obtained with the
RANDOM statement
et
wafer
position
A univariate analysis of variance with attendant
comparisons and estimates coul.d be employed
similar to the methods used on the CHI PS data. but
comparisons and standard errors involving the time
effect would not be valid due to failure of the
intrasubject correlation matrix to meet the HuhynFeldt (H-F) conditions (Milliken and Johnson. 1984).
Multivariate repeated measures analysis and other
methods could be applied using GLM. but these do
not exploit the intrasubject covariance structure. The
MIXED procedure permits specification of a variety of
intrasubject covariance structures. This is done with
the REPEATED statement It should be noted that
the REPEATED statements in GLM and MIXED
procedures have very different form and function.
Rrst of all, the REPEATED statement in GLM runs
with response variable data in a multivariate mode.
whereas response variable data must be in a
univariate mode for MIXED. So the data in the set
WEIGHTS must be transformed and stored in a data
set named WEIGHT2 which has variables
PROGRAM. SUBJ. TIME and STRENGTH.
random subj(program);
with PROC MIXED in place of the REPEATED
statement with the 1YPE=CS option. This would
correspond to a model
yielding G =
0:'
and
R=
0="
Parameter estimates
corresponding to Rgure 7 would be 0:=9.60 and
0==1.20.
The MIXED Procedure
covariance Parameter Estimates (REML)
Ratio
Estimate
std Error
DIAG CS
8.02368623
9.60333050
1.88111525
Residual
1.00000000
1.19687264
0.09403520
COy Para
A model is
Hodel Fittinq Information for STRENG1'H
Value
Description
399.0000
Observations
Variance Estimate
Standard Deviation Estimate
where the vector eiL= (egf••••• e jj7) has covariance
matrix V( eq) = RiJ 1l1is model is implemented with
the statements
proc mixed data=weight2;
class program subj time;
model strength=program time program"'time;
repeated/type=CS sub=subj;
1.1969
REHL Log Likelihood
1.0940
-710.410
Akaike's Infor.ation Criterion
-712.410
SChwarz's Bayesian Criterion
-2 ilEML w9 Likelihood
Null Model LR7 Chi-Square
-716.345
14.20.820
613.0628
Hull Model LRr DP
Null Model LR7 P-Value
1.0000
0.0000
run;
Tests of Fixed. Effects
Rxed effects of PROGRAM. TIME. and
PROGRAM"TIME are listed in the MODEL statement
Instead of using a RANDOM statement, as was done
with the CHIPS data which de facto specifies an
intrasubject covariance. the REPEATED statement is
used to directly specify the intrasubject covar:iance.
The SUB=SUBJ option tells MIXED to construct the
covariance on an intrasubject basis. This means that
the matrix R is block diagonal with SUBJ as the
Source
PROGRAK
TIME
PROGRAM'*TDCE
HDF
2
•
12
DDF
31.
31.
31.
Type III P
Pr> F
3.07
7.43
0.0478
0.0000
2.99
0.0005
Figure 7. MIXED Output for Repeated Measures.
Compound Symmetric Structure of Covariance Matrix.
Now nm the same MIXED statements. except change
1055
the REPEAlED statement to
obtained by computing the difference between the -2
REML Log Ukelihood values in Figures 7 and 8:
Us"e a chi-square
1420.8 - 1234.9 = 185.9.
distribution with 26 degrees of freedom to obtain the
Significance level: p < 0.001. You conclude that the
UN GLMM fits better than the CS GLMM. The
number of degrees of freedom is equal to the
difference between the number of covariance
parameters in Figure 8 (28) and the number of
covariance parameters in Figure 7 (2).
repeated/type=un sub=subj;
The TYPE=UN option specifies nonstructured
intrasubject covariance matrix Rg = (0",), which
imposes no structural conditions on the matrix.
Results appear in Figure 8. You see 0 11 =8.78,0 ,2
= 8.76, etc. Tests for fixed effects are similar to
those you would get from a multivariate repeated
measures analysis using GLM. This also is expected
because the multivariate repeated measures analysis
assumes no covariance structure.
Change the REPEAlED statement and add the
RANDOM statement
Tho IUXED Proc:edqre
random subj(program);
repeated/type=ar(1) sub=subj;
Covariance Parameter Bstiaat•• (REKL)
Cov Parm
TDD! OH(l,l)
W(2,1)
UN(2,2)
UH(3,I)
Est.iJDa.te
Std Error
8.78036817
8.75733025
9.47322531
1.68978264
8.96588404
9(3,2)
9.406334877
UN{3,3) 10.70827822
8.19863316
ON(4,l)
W(4,2)
ON(4,3)
ON(4 ... ')
tJN(S,l)
UN(S.2)
tJN(S,3)
tJN(5,4)
UN(S,S)
UH(6,1)
tJN{6,2)
UN(6,3}
UN('."
UH(6,5)
UH(6,6)
UH(7,1)
UH(7,2)
UN (7 ,3)
UN(7,4)
UN(7,S)
ON(7,6)
UN(7,7)
Residual
8.56882716
9.92680776
10.07755732
8.67835097
'.20154321
10.66644621
10.59982363
12.09541446
8.22056878
8.73101852
10.07043651
9.89894180
11.34470899
11.15621693
8.41721781
8.68780864
10.21417549
10.04356261
11.36410935
11.65039683
12.71036155
1.00000000
1.72062241
1.82312306
1.79716702
1.88068596
2.06080910
1.69805035
1.7&850936
1.95530,96
1.93942681
1.83341398
1.920e9381
2.12260383
2.08277101
2.32776360
1.77848075
1.86388670
2.05165937
2.00214231
2.235118644
2.26248500
1.83813114
1.90460523
2.11009684
2.055113748
2.28878130
2.251797622
2.44611022
Z Pr >
5.20
5.09
5.20
4.,9
5.03
5.20
4.83
4.s5
5.08
5.20
4.73
4.79
5.03
5.09
5.20
4.62
4.68
4.511
4.94
5.07
5.20
4.58
4.56
4.84
4.88
4.97
5.07
5.20
IZI
The option TYPE=AR(1) specifies an autoregressive
covariance matrix of order one, in which the
intrasubject correlation between measurements k
units apart in time is pk. Autoregressive covariance
is an attractive option for repeated measures data
because it models the correlation between two
measurements on the same subject as decreasing
with increasing length of the time interval between the
measurements. Due to 'technical aspects of the
autoregressive covariance structure, the RANDOM
statement is needed to account for all random
variation between subjects in the same program.
Use of a RANDOM statement like this in conjunction
with a REPEAlED statement with TYPE=CS or
TYPE=UN would define redundant parameters in the
model. Output with the autoregressive covariance
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
s1ructure appears in Fl9ure 9. The titled model has G =o~ I
and Rij=(o",)' where OU+k=O~pk.
Model Pitting Information for STRENGTH
Value
De.cription
observation8
Variance Estimate
Standard J)eviation Estimate
REKL Log Lik.lihood
Aka.ike'a Inforaation CriteriOli
Schwarz's Bayesian Criterion
-2 REML Log Liblihood
lfQU Hodel LR7 Chi-square
Rull Hodel LR7 DP
Hull Model LRr P-Value
parameter estimates are o~ =6.48, 0= =4.28 and
399.0000
1.0000
1.0000
-617.·448
-645.448
-700.536
1234.8516
798.9813
27.0000
0.0000
p=O.88.
The AR(1) GLMM fitted in Figure 9 is a generalization
of the CS GLM M fitted in Figure 7 and it is a special
case of the GLMM fitted in Figure 8 (UN). So you
can use (REML) likelihood ratio tests to compare the
fits. The difference between -2 REML Log Ukelihood
values from Figures 8 and 9 is 1265.8 - 1234.9 =
Tests of :rixed Effects
Source
PROGRAM
TDIB
PROGRAK·TDm
lmF
DDP
'1ype III P
Pr > F
2
,
12
378
378
378
3.07
7.12
1.57
0.0478
0.0000
0.0989
Covariance
ai!
30.9. This is not significant when referred to
distribution with 28-3=25 degrees of freedom. You
conclude the UN model does not fit significantly
better than the AR(1) model. Thus the AR(1)
covariance model is preferred to the unstructured
covariance model because it has only three
parameters and is thus much simpler. Also, the
structure of the AR(1) covariance parameters agrees
with our perception that correlation between
measurements on the same subject should decrease
as the interval length between the measurements
Figure 8. MIXED Output for Repeated Measures,
Unstructured Covariance Matrix.
The unstructured (UN) covariance GLMM is a
generalization of the compound symmetric (CS)
covariance GLMM, so you can perform a (REML)
likelihood ratio test of whether the UN GLMM fits.
better than the CS GLMM. The test statistic is
1056
applications. It is not yet time to discard GLM, but
MIXED should be considered in most applications
involving random effects.
increases.
Akaike's Information Criterion or Schwarz's Bayesian
Criterion can be used to compare models. These are
Log Ukelihood values with penalties for estimating
parameters. Using either of these criteria, choose the
model with the largest value of the criterion. In this
application, both criteria point to AR (1) as the
preferred model.
ADOmONAL READING
For 'technical documentation of MIXED, see SAS
Institute, Inc. (1992). Wolfinger (1992) presents
supplemental technical and tutorial description of
mixed models and PROC MIXED. Mclean, Sanders
and Stroup (1991) discuss practical implications of
mixed model methodology.
'!the HIXED Procedure
REML EstilDation Iteration Kistory
Iteration
Evaluations
o
1
3
2
2
1
1
1
1
2
3
4
5
•
Objective
Criterion
REFERENCES
1339.1654525
572.9'499185
O.C0667120
571.31135283
571.16478583
0.(10092586
571.09824642
0.00000857
0.00000002
0.00000000
Uttell, R.C., Freund, R.J., and Spector, P.C., SA$"
System for Unear Models, Third Edition, Cary, NC:
SAS Institute Inc., 1991. 329pp.
Uttell, R.C., and Unda, S.B. (1990). 'Computation of
Variances of Functions of Parameter Estimates for
Mixed Models in the GLM Procedure.' Proceedings
of the Fifteenth Annual SAS® Users Group
International Conference, Cary, NC: SAS Institute
Inc.
Mclean, RA, Sanders, W.L, and Stroup, W. (1991).
'A Unified Approach to Mixed Unear Models,' The
American Statistician 45, 54-64.
Mendenhall, W., Wackerly, D.O., and Scheaffer, R.L
(1990). Mathematical Statistics with Application,
4th ed., Belmont, Ck Duxbury Press.
Milliken, GA, and Johnson, D.E. (1984). Analysis of
Messy Data, Vol. 1, Designed Experiments.
Belmont, CA: Ufetime Learning.
SAS Institute, Inc. (1992) SAS® Technical Report P229, SAS/STATi' Software: changes and
Enhancements, Release 6.07. SAS Institute, Inc.,
Cary NC.
Searle, S.R. (1971). Unear Models, John Wiley and
Sons, Inc. New York.
Wolfinger, R.D. (1992). SAS® Technical Support
Document 260, A Tutorial on Mixed Models. SAS
Institute, Inc. Cary, NC.
0.(10020906
571.09513315
571.09572875
Convergence criteria met.
COVariance Parameter Estimates (REHL)
Ratio
Bstimate
Std Error
nKE ARCI)
1.51479119
0.20530521
6.48374685
0.81816628
3.03379103
0.07314431
Residual
1.00000000
4.28029084
2.56664320
Cov Para
S1JBJ (PROGRJIM l
Model Fitting Infonu.tion for STRENGTH
J)eaeripti01l
Obeervations
Variance Estimate
Standard Deviation Estilllate
IU!ML Log Likellhood
Akaike·. Information Criterion
Schwarz". Bayesian Criterion
-2 REML Log Likelihood
Value
399;0000
4.2803
2.0689
-632.907
-635.907
-641.809
1265.813
'lests of Pixed. Effects .
Source
PROGRAM
'lIME
PROGllAH'*TIMB
NDF
DOF
Type III P
Pr > F
2
6
12
54
324
324
3.0e
4.65
1.32
0.0543
0.0001
0.2067
Rgure 9. MIXED Output for Repeated Measures,
Autoregressive Structure of Covariance Matrix.
SUMMARY ANO CONCLUSIONS
The need for mixed linear models occurs in a wide
variety of applications. It is important to adequately
model the random effects in order to make valid
statistical inference. The MIXED procedure allows
you 10 do this for an extensive array of covariance
structures using the RANDOM and REPEATED
statements. Some basic applications were illustrated
in this paper. The MIXED procedure is a giant step
fotward in the SAS System, but it is not a panacea
MIXED handles most random effect problems more
adequately than GLM, particularly so with missing
data. The MIXED procedure represents state-of-theart statistical and computing technology. Yet some
problems persist. such as finding degrees offreedom.
Also, MIXED requires a lot of time for some large
Ra. Ag. Exp. Sta J. Series No. N-00914
1057