Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Foundations of statistics wikipedia , lookup
Inductive probability wikipedia , lookup
Bootstrapping (statistics) wikipedia , lookup
Taylor's law wikipedia , lookup
History of statistics wikipedia , lookup
Probability amplitude wikipedia , lookup
Misuse of statistics wikipedia , lookup
1
Lecture 1
Business Statistics
Instruction: Population, Sample, Data, Statistics
A datum is a statement of fact or at least accepted as fact. Data is the plural of datum, so
a set of data is a collection of statements. Data can be quantitative or qualitative. Consider a
sporting goods store that carries jerseys. The sizes of the jerseys carried can represent a set of
data that is quantitative, e.g., N = {10, 12, 14, 16, 18, 20, 24, 28} , or a set of data that is
qualitative, e.g., D = {small, medium, large, extra large} .
Data can be collected from a population or from a sample. A population is a set of data.
A sample is a subset of a population. A sample, then, is a set of data, and in this course, we will
deal mostly with samples that are sets of quantitative (numerical) data.
There are many ways to sample the population. If our efforts are aimed at attempting to
reach all members of the population, the technique is census-taking; otherwise, we employ other
techniques to obtain a sample. Consider a shipment of 300,000 sealed crates. Law enforcement
officers searching for contraband may not possess the resources to inspect each crate (take a
census). Instead, officers may randomly select thirty crates from the population. The thirty
crates represent a random sample. There are many types of samples: random samples (selecting
thirty crates at random), cluster samples (selecting ten crates from three particular cargo bays),
stratified samples (selecting a few crates from several types such as small, medium, and large
crates or Nigerian, Ugandan, and Liberian crates), systematic samples (selecting every tenthousandth crate), and many more.
As mentioned above, we will consider numerical data sets understood to be samples,
which, in turn, are understood to be subsets of larger populations. Numbers that describe a
population are called parameters.
A parameter is a numerical value that describes a population.
We will be largely interested in statistics, that is, numbers that describe a sample in some way.
The term "statistics" is ambiguous because it refers both to the plural of statistic and to a field of
study as defined below.
A statistic is a numerical value that describes a sample.
Statistics refers both to the plural of a statistic and to a field of science, the science
of collecting, organizing, and analyzing empirical data.
Statistics–numbers that describe samples–are sometimes used to infer characteristics of
population parameters. Statistics–the field of study–employs certain tests and procedures to
gather knowledge concerning populations.
Instruction: Scores and Variables
Collecting data involves some activity requiring observation or measurement. The
measurements yield data values called scores, which are referred to as raw scores when it is
necessary to emphasize that the score has not been changed from the initial measurement.
2
Lecture 1
A score is a datum collected by measurement or observation. Raw
scores equal unchanged measurements or observations.
This course deals mostly with quantitative samples which are numerical data sets. The data is
collected via some measurement, each measurement being a particular datum or score. The
scores change (or at least could change) from object to object in the set. The measurement itself
is called a variable represented by the letter X, and scores are possible values of the variable
(possible x-values).
A variable is a measurable characteristic that takes different values.
We will be concerned with two types of variables, discrete variables and continuous variables.
Discrete variables take values that are separated by impossible values. A typical discrete
variable is one restricted to whole number values. For example, counting the number of siblings
of individuals or the number of deaths that occur in a hospital in a week. A variable restricted to
dollar values to the nearest cent are also discrete because values such as $0.015 are impossible.
A discrete variable takes values that represent separate categories such
that when the scores are ordered any two consecutive possible scores
are separated by a span of impossible values.
Not all variables are discrete. If a variable is not discrete, it is continuous.
A continuous variable takes values that represent categories such that
an infinite number of possible scores fall between any two measured
scores.
Examples of continuous variables include heights, weights, and durations. In cases where the
variable is continuous but measurements are rounded, it is important to recognize the rounded
scores as values of a continuous variable, not a discrete variable.
Instruction: Summation Notation
Statistics often requires the summation of a large number of numbers, so a special
notation for "summation" is required. The capital Greek letter sigma, Σ , serves this purpose.
For example, given a set of scores (x-values), A = { x1 , x2 , … , xn } , then ∑ X = x1 + x2 + + xn .
In particular, if A = {5, 7, 8, 9, 11, 12, 18} where each element in the set is a datum
considered to be the value of some measurement called the random variable X, then
∑ X = 5 + 7 + 8 + 9 + 11 + 12 + 18 , so ∑ X = 70 .
3
Lecture 1
Instruction: Frequency Distributions
One statistic is the frequency of a particular value in a data set. The frequency, f, of a
score, x, equals the number of times the score appears in the data set. A frequency distribution is
a common tool used to organize data from a sample.
A frequency distribution is an organized display—be it a tabulation or a graph—that
shows the frequency of each data value in a sample.
A frequency distribution helps organize data sets (samples) that contain numerous repeated
values. For example, consider the data set T collected by the National Oceanic and Atmospheric
Administration. T is the set of number of deaths in the United States attributed to tornados in the
month of February for the years 1950 to 1983.
T = {45, 1, 10, 3, 2, 0, 8, 0, 13, 21, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 134, 0, 0, 0, 7, 5, 2, 0, 0, 0, 2, 0, 1}
The random variable, X, equals the number of tornado deaths in February in the United States for
a given year. The frequency distribution shown below lists each x-value and the corresponding
frequency of that value for the data contained in T.
X 0 1 2 3 5 7 8 10 13 21 45 134
1
f 20 2 3 1 1 1 1 1 1 1 1
The frequency distribution above is in tabular form, but frequency distributions can be
graphs as well. Imagine a traffic engineer collecting data on intersections. Consider sample S
comprised of the monthly number of fatal automobile accidents at a particular intersection over a
period of sixteen months. If S = {4, 0, 1, 4, 2, 1, 1, 0, 0, 3, 0, 1, 0, 2, 0, 1} , then Figure A is a
frequency distribution of S in the form of a line graph, which is called a frequency polygon.
Figure A
f 7
6
5
4
3
2
1
0
0
1
2
3
4
x
4
Lecture 1
Besides the line graph above, frequency distributions can take the form of bar graphs. Bar
graphs represent discrete variables with rectangles whose heights represent the frequency of each
score. The widths of the bars in a bar graph are uniform (equal), and all the bars are separated by
gaps of uniform size. The bar graph below is a frequency distribution for S.
Bar Graph
7
6
5
4
3
2
1
0
0
1
2
3
4
Some frequency distributions show the relative frequency of the data values. A relative
frequency distribution shows the fraction or percentage of the data set represented by a data
value. The table below is a relative frequency distribution for sample
S = {4, 0, 1, 4, 2, 1, 1, 0, 0, 3, 0, 1, 0, 2, 0, 1} .
0
38
x
f
1
5 16
2
18
3
1 16
4
18
Figure B is a relative frequency distribution for sample S in bar graph form.
Figure B
0.4
0.35
0.3
0.25
0.2
0.15
0.1
0.05
0
0
1
2
3
4
5
Lecture 1
Figure C is a relative frequency distribution of sample S in circle graph form. Circle
graphs divide the area inside a circle into wedges whose sizes represent the relative frequencies
of the data values.
Figure C
4, 12.5%
3, 6.25%
0, 37.50%
2, 12.50%
1, 31.25%
Another type of frequency distribution is a grouped frequency distribution. A grouped
frequency distribution shows the frequencies of ranges of values. The ranges of values are
sometimes referred to as "classes" or "bins." Consider set D, a set of lengths.
D = {3.1, 3.6, 2.9, 4.1, 4.2, 2.2, 2.6, 3.1, 3.3, 4.2, 4.4, 5.0, 2.9, 4.1, 4.6}
It could be advantageous to organize this data according to ranges of values. Figure D is a
grouped frequency distribution using four classes in histogram form. Histograms conveniently
represent continuous variables. Histograms use contiguous rectangles whose heights represent
the frequency and whose widths represent some quantity. The histogram below is a grouped
frequency distribution for set D.
Figure D
f
7
6
5
4
3
2
1
0
1.5 ≤ x1< 2.5
2.5 ≤2x < 3.5 3.5 ≤ x3< 4.5
4.5 ≤ x4 < 5.5
6
Lecture 1
In histograms, the widths of the bars represent class range. A class is a division or subset
of the data that includes data that falls within a certain range of values. In Figure D, the numbers
1.5, 2.5, 3.5, and 4.5 represent lower class limits, the smallest possible data values for the four
classes respectively. The upper class limits for the four classes are 2.5, 3.5, 4.5, and 5.5
respectively. Here, the upper class limits represent a boundary on the largest possible data value
for each class. Class limits are either the extreme most possible data values (least or greatest) or
a minimal/maximal boundary on the possible data values (least or greatest). The uniform class
width approximately equals the ratio of the range of the data and the desired number of classes.
class width
largest data value − smallest data value
desired number of classes
Class limits should be chosen such that the uniform class width equals the difference of any two
successive upper class limits. The class width for Figure D is 1 as calculated here: 5.5 − 4.5 = 1 .
The class mark is the "middle" value of a class and can be calculated by dividing the sum of the
lower and upper limits of a class by two. The class marks for Figure D are calculated below.
1.5 + 2.5
= 2,
2
2.5+3.5
= 3,
2
3.5+4.5
= 4,
2
4.5+5.5
=5
2
Assignment 1
7
Problems
#1
Using a complete sentence, identify each data set described below as a sample or a population.
A.
B.
#2
Using a complete sentence, identify each numerical value described below as a statistic or a
parameter.
A.
B.
#3
The average annual salary of thirty of a company's 1,500 employees is $76,000.00.
According to ACT, Inc., the average ACT math score for all graduates in a
particular year was 20.7.
Consider the set of x-values: {5, 6, 9, 10} . Let n represent the cardinal number of the set.
A.
#4
A survey of five-hundred University of Texas students.
The age of each U. S. president upon election to office.
Find ∑ X .
B.
Evaluate
∑X
.
n
The table below shows the oil reserves (rounded to nearest billion of barrels) of countries in the
Western Hemisphere at a given time in history. Create a relative frequency distribution in the
form of a bar graph.
Country
Billions of Barrels
United States
36
Canada
16
Mexico
60
South America
72
Total
186
#5
The data set below represents the prices of grade A eggs (in dollars per dozen) for the indicated
years. Use a frequency polygon to display the data set.
1990
1991
1992
1993
1994
1995
#6
1.00
1.01
1.02
0.98
0.97
0.94
1996
1997
1998
1999
2000
2001
0.95
0.93
0.94
0.94
0.99
1.02
Use a pie chart to display the data. The numbers represent the number of Nobel Prize laureates
by country during the years from 1901 to 2002.
U. S. 270
U. K. 100
France
Sweden
49
30
Germany
Other
77
157
Assignment 1
#7
8
Construct a frequency distribution in histogram form with six classes for the arrayed data. The
data set represents the amount in dollars (rounded to the nearest dollar) spent on books for a
semester by thirty students. Show the class marks (mid-points of each class).
91
188
189
#8
266
190
30
472
341
127
248
398
354
279
266
8
101
88
222
249
199
526
375
269
93
530
142
184
486
43
352
Fresh N Ready Sandwiches strives to provide fresh sandwiches and quick service. The table
below reflects the results of a recent survey of customers who entered the restaurant only to
leave before ordering. Use the data to create a Pareto diagram.
Reason for Leaving
Frequency
Long lines
38
Pricing
6
Restaurant appearance
4
Other
2
Total
50
#9
Using complete sentences, explain why the following procedures do not give a random sample
for the entire population of Manhattan. Be sure to note any bias the procedure may
contain.
A.
B.
C.
#10
selecting every third woman entering a beauty shop in Gramercy Park
selecting every third person entering a bar in Chelsea
selecting every third person coming out of a boxing match at Madison Square Garden
Using a complete sentence, identify each variable described below as discrete or continuous.
A.
B.
C.
D.
the number of times a telephone rings before it is answered
the amount of time a customer waits before service
the amount of oil held in reserve by a nation
the price of grade A eggs
Lecture 2
9
Instruction: Measures of Central Tendency
This lecture discusses numerical descriptive measures, beginning with three statistics of
numerical data sets called measures of central tendency.
A measure of central tendency is a statistic that assigns a numerical
value as representative of an entire data set.
One measure of central tendency is the arithmetic mean. The symbol X-bar, X , denotes
the arithmetic mean of a sample set. The arithmetic mean, defined below, can be thought of as
the average.
For a given numerical set of data S = { X 1 , X 2 ,… , X n } with n elements, the
arithmetic mean of the set is given by the formula:
n
X=
∑ Xi
i =1
n
.
The arithmetic mean has three significant characteristics. First, changing the value of any score
or adding to the data set a new score not equal to the mean, will change the mean of the data set.
Second, if some constant value c is added to each value in the data set, the mean changes to
X + c . Third, if some constant value c is multiplied by each value in the data set, the mean
changes to c ⋅ X
A second measure of central tendency is the median. The median, defined below, is the
midpoint of the distribution of the data set.
For data set S arranged in ascending order, the median is the value that divides the
data set exactly in half, and exactly 50% of the data will be equal to or less than the
median. If ( n + 1) 2 is an integer, it equals the position of the median. If ( n + 1) 2
is a not an integer, the position of the median is the midpoint between the score in
the n 2 position and the score in the ( n + 2 ) 2 position.
If n ( S ) is odd for a sample S of non-rounded data arranged in ascending order, the median is the
middle number in S. If n ( S ) is even for a sample S of non-rounded data arranged in ascending
order, the median is the mean of the two middle numbers.
The third measure of central tendency is the mode. The mode, defined below, is the most
common number in a numerical data set.
For data set S with some frequency f k greater than any other frequency f j , the
mode is the value with the greatest frequency.
Lecture 2
10
According to the definition above, there is no mode in a numerical data set that contains data
values such that the frequencies of all the data values are equal. If, however, there exists any one
or more frequencies greater than one or more other frequencies, the data set has a mode, and the
mode equals the data value (or values) with the greatest frequency. Data sets with multiple
modes are said to be multimodal. Data sets with two modes are said to be bimodal.
Consider a sample V = {6, 5, 2, 12, 1, 3, 2, 4, 0, 4, 13, 6, 6, 7, 1, 6} . To find the three
measures of central tendency, we must find the arithmetic mean, the median, and the mode.
Arranging the data set in ascending order, will help identify frequencies and the median:
V = {0, 1, 1, 2, 2, 3, 4, 4, 5, 6, 6, 6, 6, 7, 12, 13} .
The data point 6 appears in the data set the most (has the greatest frequency), so the mode equals
6. The arithmetic mean equals the ratio of the sum of the data points to the number of data
points as computed below.
X=
0 + 1 + 1 + 2 + 2 + 3 + 4 + 4 + 5 + 6 + 6 + 6 + 6 + 7 + 12 + 13 78
=
= 4.875
16
16
Since n (V ) is even, the median equals the mean of the two middle numbers as computed below.
median =
4+5 9
= = 4.5
2
2
In summary, for the given data set V, we have the three measures of central tendency:
mean = 4.875, median = 4.5, & mode = 6.
Consider a larger set of data S displayed by the frequency distribution below.
X 22 23 24 25 26 27 28 29 30 31 32 33
f 5 3 7 1 1 2 4 10 4 1 1 1
Since the frequency distribution organizes the data set, finding the three measures of central
tendency for the data set is not much more difficult for S than it was for V; even though,
n ( S ) > n (V ) . Note that n ( S ) = ∑ f = 5 + 3 + 7 + 1 + 1 + 2 + 4 + 10 +4 + 1 + 1 + 1 = 40 . To find the
mode, select the data value with the greatest frequency, which is 29. To find the median, start by
calculating its position: ( 40 + 1) 2 = 20.5. Since position of the median is 20.5, the median
equals the average of the 20th and 21st values in the data set arranged in ascending order:
( 28 + 28) 2 = 28. To find the arithmetic mean, calculate the ratio of the sum of the data points
to the number of data points as below.
∑[ f ⋅ Xi ]
n
X=
i =1
∑f
=
5 ⋅ 22 + 3 ⋅ 23 + 7 ⋅ 24 + 25 + 26 + 2 ⋅ 27 + 4 ⋅ 28 + 10 ⋅ 29 + 4 ⋅ 30 + 31 + 32 + 33
= 26.75
40
Lecture 2
11
In summary, for the given data set S, we have the three measures of central tendency:
mean = 26.75, median = 28, & mode = 29.
Instruction: Measures of Dispersion
This portion of the lecture discusses three statistics of numerical data sets called
measures of dispersion. Consider the two samples below each with the same mean and median.
A = {47, 50, 53}
B = {0, 50, 100}
For both sets, X = 50. For sample A, the mean is a good estimate for any score found in the set,
but the mean is not a good estimate for any score found in sample B. The scores in sample B are
spread further apart than those in sample A. Sample B is said to have greater variability.
Statistics that measure the magnitude of variability are called measures of dispersion.
A measure of dispersion is a statistic that assigns a numerical value
to describe the variability of a data set. Variability refers to the
spread of a data set. A measure of dispersion measures how spread
out or how widely dispersed a set of data is.
One particular measure of dispersion is the range. The range, defined below, is the
distance between the largest and smallest values in a sample.
The range is the difference of the largest and smallest values in a sample.
The range of set A above equals six because 53 − 47 = 6. The range of set B above equals 100
because 100 − 0 = 100.
A second measure of dispersion is the sample variance. To discuss variance, we must
first discuss a deviation and the squares of deviations.
Deviation equals distance from the mean. A deviation score equals X i − X .
According to the definition above, the deviations of scores below the mean are negative, and the
deviations of scores above the mean are positive. The table below shows the deviations for set
A.
X Xi − X
47
–3
50
0
53
3
Lecture 2
12
Scores below the mean have negative deviations. Scores above the mean have positive
deviations. Scores equal to the mean have zero deviations. While deviations can be positive or
(
negative depending on the position of the respective score, the squares of deviations, X i − X
),
2
are always positive.
To calculate sample variance, we must calculate the deviation of each score in the sample
as above as well as the square of each deviation as below.
(X
Xi − X
X
47
50
53
–3
0
3
i
−X
)
2
9
0
9
The population variance equals the mean of the sum of the squares of the deviations.
The sample variance equals an estimate of the population variance given by the formula in the
box below.
The sample variance, denoted var or S 2 , equals the ratio:
n
var = S 2 =
(
∑ Xi − X
i =1
)
2
.
n −1
The sample variance for sample A = {47, 50, 53} is calculated below.
var = S 2 =
9 + 0 + 9 18
=
=9
3 −1
2
The third measure of dispersion is the standard deviation, which equals the square root of the
variance.
The sample standard deviation, denoted S, is a distance from the mean that
equals the square root of the variance:
S= S =
2
(
∑ x−x
)
2
.
n −1
The sample standard deviation measures the typical or standard distance of
scores in the sample from the mean.
According to the definition above, widely dispersed samples have large standard deviations.
Indeed, the larger the sample's standard deviation, the more widely dispersed are the elements in
the sample. The standard deviation of sample A = {47, 50, 53} is given here: S = 9 = 3 .
The standard deviation has two key characteristics. First, adding a constant to each score
in a sample will not change the standard deviation. Thus, if A* = {46, 49, 52} , then S = 3.
Lecture 2
13
Second, multiplying each score by a constant causes the standard deviation to be multiplied by
the same constant. Thus, if A* = {94, 100, 106} , then S = 6.
A fourth measure of dispersion is the coefficient of variation, a relative measure always
expressed as a percentage. The coefficient of variation measures the scatter in the data relative
to the mean.
The coefficient of variation, denoted CV, equals the quotient of the
standard deviation and the mean expressed as a percent:
⎛S⎞
CV = ⎜ ⎟ .
⎝X⎠
Reconsider our sample from above, A = {47, 50, 53} , for which S = 3 and X = 50 . The
coefficient of variation for sample A is 6% as calculated below.
⎛ 3 ⎞
CV = ⎜ ⎟ = 0.06 = 6%
⎝ 50 ⎠
Instruction: Distributions
This lecture discusses types of distributions plus an interesting use of the standard
deviation. Lecture 4.2 discussed frequency distribution graphs. This lecture discusses some
general types of shapes of frequency distributions.
One general shape of frequency distribution graphs includes symmetrical distributions.
With symmetrical distributions, a vertical line can be drawn through the middle in such a way
that one side of the distribution is an exact mirror image of the other as shown below in Figures
A and B. Figure B demonstrates a bimodal symmetrical distribution.
Figure A
f 25
20
15
10
5
0
symmetrical distribution
Lecture 2
14
Figure B
f 20
15
10
5
0
bimodal symmetrical distribution
Here the term bimodal means that the two data points (or classes) have the same frequency,
which is how we will use the term bimodal in this course. Bimodal can refer to non-symmetrical
distributions with two distinct peaks on either side of the center of the distribution.
Another general shape of frequency distribution graphs includes skewed distributions.
Skewed distributions tend to form graphs that rise up toward one end of the range of scores.
These distributions often taper off gradually at the opposite end. The tapering end is called the
tail. Figure C below demonstrates a positively skewed distribution. The modifier "positively"
derives from the fact that the tail points in the positive direction. Figure D below demonstrates a
negatively skewed distribution.
Figure D
Figure C
f
f 25
25
20
20
15
15
10
10
5
5
0
0
positively skewed distribution
negatively skewed distribution
Finally, a frequency distribution graph can be uniform (or rectangular). Uniform
distributions form a rectangle because all the objects (or classes) have equal frequencies. Figure
E below demonstrates a uniform distribution.
Lecture 2
15
Figure E
f
20
15
10
5
0
uniform distribution
It is easy to imagine how challenging it would be to construct a frequency distribution
graph for a population because populations tend to be large data sets and recording
measurements and frequencies for the entire group would be cumbersome. It is sometimes
easier, however, to construct relative frequency graphs for populations. Using statistical
procedures applied to samples, researchers can sometimes infer information about the relative
frequencies of populations. In such cases, the distributions are outlined with smooth curves.
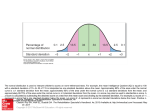
Figure P below displays a symmetrical relative frequency distribution for a population.
Figure P
Instruction: Chebyshev's Theorem
The Russian statistician Pafnuti Chebyshev discovered a useful fact given in the box
below that applies to all distributions regardless of their shape.
Chebyshev's Theorem states that the fraction of any data set lying within k
standard deviations of the mean where k > 1 is at least:
k2 −1
.
k2
This theorem tells us that at least 75% of the scores in a data set lie within two standard
deviations of the mean as calculated below.
Instruction: Measures of Position
This lecture discusses measures of position. The median discussed in Lecture 4.3 is an
example of a measure of position. Since the median is the middle number (or average of the two
middle numbers), the median is a measure of position that reveals which score occupies the
center of the distribution.
Lecture 2
16
A measure of position is a statistic that reveals a score's position in the
distribution of a data set.
Percentiles are measures of position that reveal what percent of the scores equal or fall
below a given score. Percentiles divide the distribution of the data set into one hundred parts.
A percentile is a numerical value assigned to a given score that indicates what
percent of the scores in the data set equal or fall below the given score.
According to the definition above, a percentile is a position. The bottom percentile is zero. The
top percentile is 99. The score with zero percentile is the lowest score. The score with the 99th
percentile is the greatest score. To calculate the percentile of X i , divide the number of scores
less than X i by n where n is the total number of scores in the data set and convert to a percent.
To find the position of a score that occupies a given percentile, multiply the decimal equivalent
of the percentile by n and select the next largest integer.
Consider data set A = {22, 21, 14, 20, 19, 27, 17, 22, 26, 24}. Arranging the data set in
ascending order reveals that eight scores fall below 26:
A = {14, 17, 19, 20, 21, 22, 22, 24, | 26, 27}
Accordingly, a score of 26 corresponds to the 80th percentile as calculated below.
8
= 0.8 = 80%
10
To find the position of the score in the 40th percentile for set A, we multiply 40% by the cardinal
number of the set to get 4 then move to the next integer 5.
0.4 × 10 = 4 ⇒ 5
Hence, the fifth score in the ordered data set occupies the 40th percentile, so 21 corresponds to
the 40th percentile.
Another statistical measure of position is the quartile defined in the box below.
A quartile divides the distribution into quarters. The quartiles, denoted
Q1 , Q2 , and Q3 , are the three numbers that occupy the 25th, 50th, and 75th
percentiles respectively.
The second quartile, Q2 , equals the median. The first quartile, Q1 , equals the median of the
scores that fall below Q2 . The third quartile, Q3 , equals the median of the scores that fall above
Q2 .
For a given sample, the three quartiles together with the lowest value (zero percentile)
and the greatest value (99th percentile) act as a set of five numbers called the five number
Lecture 2
17
summary of a data set. These five numbers are used to create a box plot (or box-and-whisker
plot) defined below.
A box plot is a graphical display that uses a rectangle and two line
segments to summarize a data set. The entire display hovers over a
number line. The rectangle extends from the first quartile to the third
quartile and is divided into two parts by a vertical line segment drawn over
the median (second quartile). From the left and right sides of the rectangle,
two line segments called whiskers extend to the least and greatest scores
respectively.
Consider the data set B = {1, 2, 3, 6, 6, 7, 8, 8, 8, 9, 9, 11, 11, 12, 17}. The display below is a
box plot representing data set B.
Q1
Q2
Q3
The box plot conveys the central tendency, the location of the middle half of the data, the
dispersion, and the skew-ness. The location of the median shows the central tendency. The
rectangle reveals the middle half of the data. The reach of the whiskers exposes the range, and
the non-symmetry or symmetry of box and whiskers displays the skew-ness.
The most important measure of position is the Z-score defined below.
A Z-score is a numerical value assigned to a raw score that measures the
distance between the raw score and the mean in standard deviations. For a
given sample A with mean X and standard deviation S, the Z-score of
some raw score X i in A, is given by
Zi =
Xi − X
.
S
Since a Z-score is a ratio of a raw score's deviation from the mean to the standard deviation, Zscores assigned to raw scores below the mean will be negative while those assigned to raw scores
above the mean will be positive.
If we recall Chebyshev's Theorem, we see the significance of a Z-score. Chebyshev's
theorem stated that at least ( k 2 − 1) k 2 of the data of any distribution falls within k standard
deviations. Since a Z-score equals a number of standard deviations, a raw score's Z-score can be
substituted for k. Using Chebyshev's Theorem, we know that at least 93.75% of the data falls
between the data point with a Z-score of –4 and the data point with a Z-score of +4. As a
consequence, we note that any data point with a Z-score smaller than –4 or greater than +4 is
fairly atypical of the data set. Imagine a doctor examining a child of a certain age whose weight
Lecture 2
18
has a Z-score of –4.2. The doctor knows immediately that most children in a comparable
population or sample have a greater weight. Accordingly, the doctor has statistical evidence to
warrant expensive medical tests to see if there is some underlying medical cause for the child's
low weight. Chebyshev's Theorem applies to any distribution of data. A future lecture discusses
a particular type of distribution that imbues Z-scores with even more significance.
Instruction: Measuring the Strength of Linear Relationships
A scatter plot like the one shown below visually examines the relationship between two
numerical variables.
Blood Alcohol Concentration (mg%)
90
80
70
60
50
40
30
20
10
0
0
0.5
1
1.5
2
2.5
3
3.5
4
t-hours
In the scatter plot above, there appears to be a linear relationship between hours elapsed and the
alcohol concentration in a patient's bloodstream. The sample covariance measures the strength
of such linear relationships.
The sample covariance, denoted cov ( X , Y ) , measures the strength of the
linear relationship between variables X and Y and is given by
n
(
)(
)
∑ ⎡ X i − X Yi − Y ⎤⎦
i =1 ⎣
cov ( X , Y ) =
.
n −1
The covariance is limited in its usefulness because it does not provide a relative strength of the
relationship it purports to measure as does the coefficient of correlation.
The coefficient of correlation, denoted r, measures the relative strength of a linear
relationship between two numerical variables. The values of the coefficient of correlation range
from negative one to positive one. If r = −1 , the relationship is said to be a perfect negative
Lecture 2
19
correlation and the points in the scatter diagram will all fall in a straight line with a negative
slope. If r = 1 , the relationship is said to be a perfect positive correlation and the points in the
scatter diagram will all fall in a straight line with a positive slope. If r = 0 , the data points all
fall in a straight horizontal line. In general, the smaller the difference between one and r , the
stronger the linear relationship between the two variables.
The sample coefficient of correlation, denoted r, measures the relative
strength of the linear relationship between variables X and Y and is given
by
cov ( X , Y )
r=
S X SY
where
n
(
)(
)
∑ ⎡ X i − X Yi − Y ⎤⎦
i =1 ⎣
cov ( X , Y ) =
,
n −1
(
)
n
2
∑ ⎡⎢ X i − X ⎤⎥
⎦ , and S =
S X = i =1 ⎣
Y
n −1
(
)
n
2
∑ ⎡⎢ Yi − Y ⎤⎥
⎦.
i =1 ⎣
n −1
Assignment 2
20
Problems
#1
Find three measures of central tendency and three measures of dispersion for the data displayed
in the frequency distribution below. Assume the data belongs to a sample.
Value
2
4
6
8
#2
Frequency
5
1
8
4
Two friends, Frick and Frack, who take different history classes, took their midterm exams on
the same day. Frick’s score was 86 while Frack’s score was 78. Use a complete sentence to
identify which student did relatively better, given the class data shown below.
Class mean
Class standard deviation
Frick
73
8
Frack
69
5
#3
Consider a distribution where the mean is seventy and the standard deviation is eight. At least
what fraction of the values are between 54 and 86?
#4
Construct a box plot for the data set below.
46
69
61
56
#5
59
79
64
61
63
62
67
64
66
52
70
67
69
59
83
71
75
64
66
88
51
67
56
71
59
70
62
58
63
79
65
68
66
55
68
72
An efficiency expert has developed the JSI, a test measuring job satisfaction of civil service
clerks. The following information reflects data collected from a random sample of ten civil
service clerks. Use a complete sentence and a relevant statistic to discuss the effectiveness of
the JSI.
Job Satisfaction Index (JSI)
92 32 56 20 72 16 56 76 80 48
Absences for Year JSI was taken 8 14 10 14 6 17 8 12 7 15
Lecture 3
21
Business Statistics
Instruction: Introduction to Counting
Combinatorics or the study of counting is a branch of mathematics that deals with the
selection and arrangement of elements of sets. For example, given a universal set that includes
the first ten whole numbers: U = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} , a fundamental question in
combinatorics asks, "In how many ways can the elements of U be arranged?"
To answer this question and others like it, we will use the Fundamental Counting
Principle as a direct application of the Multiplication Principle, which states that the number of
elements in a Cartesian product equals the product of the number of elements in each factor of
the Cartesian product so that n ( E1 × E2 × × E p ) = n ( E1 ) ⋅ n ( E2 ) ⋅ ⋅ n ( E p ) . To develop the
Fundamental Counting Principle, we will think of the task of finding the cardinality of a
Cartesian product as a series of tasks. Consider set E with m elements and set F with n elements.
Recall that a Cartesian product is a set of ordered pairs. The first task in finding the number of
elements in the product E × F requires choosing the number of distinct leading components in
the product. There are m ways to accomplish this task. The second task requires choosing the
number of distinct second components, and there are n ways to accomplish this task. The
number of ways to accomplish the overall task (of finding the number of ordered pairings of each
distinct leading component with each distinct second component) equals m ⋅ n . From this
exercise we have the Fundamental Counting Principle stated below.
If one task can be performed in n1 different ways, a second task can be
performed in n2 different ways, a third task can be performed in n3
different ways, and so on for p tasks, then the total number of ways to
perform the overall task of performing task one, task two, task three,
and so on to task p equals n1 ⋅ n2 ⋅ n3 ⋅ ⋅ n p .
To illustrate a simple example of the Fundamental Counting Principle, consider the
number of ways to enter and exit the sports arena below if one must enter through an east gate
and exit through a west gate.
West Gate A
West Gate B
East Gate A
East Gate B
West Gate C
West Gate D
East Gate C
There are two subtasks associated with the overall task of determining how many ways to enter
and exit the sports arena. The first subtask requires finding the number of entrances, 3, while the
Lecture 3
22
second task requires finding the number of exits, 4. Using the Fundamental Counting Principle,
we find the number of ways to enter and exit by multiplying the number of ways to enter by the
number of ways to exit: 3 ⋅ 4 = 12 .
This same problem can be visualized as a Cartesian product. Consider the sets of gates
below.
N = {EA, EB, EC}
X = {WA, WB, WC, WD}
Now consider the Cartesian product N × X .
⎧( EA,WA ) , ( EA,WB ) , ( EA,WC ) , ( EA,WD ) , ⎫
⎪
⎪
N × X = ⎨( EB,WA ) , ( EB,WB ) , ( EB,WC ) , ( EB,WD ) , ⎬
⎪
⎪
⎩( EC,WA ) , ( EC,WB ) , ( EC,WC ) , ( EC,WD ) ⎭
Note that n ( N × X ) = 12 .
Now, we will return to our universal set U = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} and our
fundamental question, "In how many ways can the elements of U be arranged?" The word
arranged implies an order, and for our purposes an arrangement of objects is one where order is
important. To arrange the elements of U, we must accomplish ten tasks--that is, we must select
the element for the first position in the arrangement, select the element for the second position,
select the element for the third position, and so on. The number of ways to accomplish the first
task equals ten because there are ten different elements that can be placed first. The number of
ways to accomplish the second task equals nine because there are nine elements remaining that
can occupy the second position after one element has been chosen for the first position. For each
subsequent position there is one fewer element remaining, so the number of ways to accomplish
each task keeps descending by one. Thus, the number of ways to arrange the ten elements in U
equals 10 ⋅ 9 ⋅ 8 ⋅ 7 ⋅ 6 ⋅ 5 ⋅ 4 ⋅ 3 ⋅ 2 ⋅1 .
To answer our fundamental question, we find the product of n (U ) and each of the
natural numbers that precede n (U ) . This type of product appears frequently in combinatorics,
so frequently, in fact, that a special notation called "factorial" is defined.
By definition, n-factorial, denoted n!, equals the product n × ( n − 1) × ( n − 2 ) ×
×1 .
In fact, this notation is used in the Factorial Rule which answers the question, "In how many
ways can the elements of U be arranged?"
The number of ways to arrange n distinct objects (in order) equals n !.
Lecture 3
23
Factorial provides a means for expressing the product of any natural number multiplied by all the
preceding natural numbers. The symbol for factorial is !. Thus, 5! = 5·4·3·2·1 = 120. Since zero
is not a natural number, 0! has no meaning according to the definition above. Instead, 0! is
defined as 1. Counting methods called permutations and combinations use factorials as we shall
see in the following discussions.
Instruction: Counting with the General Addition Rule and the Complement Principle
This portion of the lecture relies on the General Addition Rule and the Complement
Principle discussed in Section 1.5 in order to address some indirect methods of counting.
First, we will use the Complement Principle restated below.
n ( E C ) = n (U ) − n ( E )
n ( E ) = n (U ) − n ( E C )
Consider a universal set such that n (U ) = 50 and set F, a proper subset of U, such that
n ( F C ) = 6 . To find n ( F ) , we apply the Complement Principle below.
n ( F ) = n (U ) − n ( F C )
n ( F ) = 50 − 6 = 44
This principle can be applied to counting problems. Consider the number of ways that at least
one coin will land on heads if five fair coins are tossed. The Fundamental Counting Principle
helps ascertain the number of possible ways the five coins can land, 25 = 32 . Only one of these
thirty-two results does not satisfy the condition that "at least one coin will land on heads" and
that is the result of getting no heads whatsoever (all tails). Let U be the set of thirty-two results
from tossing the five coins. Let H be the set of results that contain at least one head. We know
that n ( H C ) = 1 . Applying the Complement Principle, we can find n ( H ) .
n ( H ) = n (U ) − n ( H C )
n ( H ) = 32 − 1 = 31
Thus, there are thirty-one ways that at least one coin will land on heads if five fair coins are
tossed.
Second, we will use the General Addition Rule restated below.
n( E ∪ F ) = n( E) + n(F ) − n( E ∩ F )
Lecture 3
24
Consider a universal set such that n (U ) = 50 and sets A and B, proper subsets of U, such that
n ( A ) = 10 , n ( B ) = 20 , and n ( A ∩ B ) = 5 . To find n ( A ∪ B ) , we apply the General Addition
Rule below.
n ( A ∪ B ) = n ( A) + n ( B ) − n ( A ∩ B )
n ( A ∪ B ) = 10 + 20 − 5 = 25
This principle, too, can be applied to counting problems. Consider the number of ways that a
jury foreman could be a woman or a Hispanic if the foreman is selected from the jury described
by the table below.
Men Women Totals
non-Hispanic
4
4
8
Hispanic
3
1
4
Totals
7
5
12
Let H represent the set of Hispanic jury members. Let W represent the set of women jury
members. Let H ∩ W represent the set of jury members who are Hispanic women. The set of
jury members who are either Hispanic or a woman is H ∪ W . Applying the General Addition
Rule, we can find n ( H ∪ W ) :
n ( H ∪ W ) = n ( H ) + n (W ) − n ( H ∩ W )
n ( H ∪W ) = 4 + 5 −1 = 8
Instruction: Permutation
In general, a permutation is an arrangement. With arrangement order is important.
Consider a decorator who wants to display eight photographs on the mantel of a fireplace. How
many ways can the decorator arrange the photographs in a line? There are eight ways to place the
first photograph. After placing the first, there are only seven ways to place the second
photograph since only seven spots remain. After placing the first two, there are only six ways to
place the third, etc. Using the Fundamental Counting Principle, the total number of ways to
place the eight photographs can be found by multiplying the number of ways to place each
succeeding photograph: 8·7·6·5·4·3·2·1 = 8! = 40,320. Each arrangement is a permutation. Note
that in this example, n objects where chosen from a set with n elements. According to the
Factorial Rule, the number of permutations when n objects are chosen from a set of n objects
equals n! Sometimes, however, some subset of r objects are chosen from a set of n objects
where r < n to form a linear arrangement of r distinct objects. When this occurs, the Permutation
Formula stated below dictates the number of permutations.
If set S has n elements, then the number of linear arrangements containing r distinct
objects taken from S is denoted by P(n,r) or nPr and given by
P ( n, r ) =
n!
.
( n − r )!
Lecture 3
25
Reconsider the decorator who wants to adorn a fireplace mantel with photographs. If the
decorator has eight photographs to choose from but only three spots on the mantel, then the
number of arrangements equals the permutation of eight objects taken three at a time:
n
Pr =
n!
8!
8! 8 ⋅ 7 ⋅ 6 ⋅ 5!
=
=
=
= 8 ⋅ 7 ⋅ 6 = 336
( n − r ) ! ( 8 − 3) ! ( 5 ) !
( 5)!
There are 336 arrangements (permutations) that the decorator can use.
One final warning: since the Permutation Formula gives the number of arrangements of r
distinct objects taken from a set of n distinct objects, there is no duplication of objects.
Instruction: Combinations
Combinations are selections of distinct objects in which the order of the objects is not
important. If a club with twenty members, for example, is to select which three members must
attend a national conference, the arrangements are combinations because choosing Alice, Bobby,
and Charlene is not different from selecting Charlene, Bobby, Alice. In either case, the same
three members will attend the conference. The number of combinations of n distinct objects
⎛n⎞
taken r at a time has three acceptable notations including n C r , C ( n, r ) , and ⎜⎜ ⎟⎟ . The number of
⎝r ⎠
combinations of n objects taken r at a time is given by the Combination Formula below.
If set S has n elements, then the number of combinations of r distinct objects taken
from S is given by
⎛n⎞
n!
.
⎜⎜ ⎟⎟ =
⎝ r ⎠ r! (n − r )!
Consider a marketing director planning a promotion for a product sold in twelve different
cities. If the director's budget only allows a promotional blitz in three cities, how many different
ways can the director select three cities from the twelve target cities? The selection of Dallas,
San Diego, and Nashville is no different from the selection of Nashville, San Diego, and Dallas
because the order of the selection of those three cities does not change the fact that those three
cities will be the focus of the marketing promotion. Since order does not make a difference, the
Combination Formula gives the answer:
2
12!
12 × 11× 10 × 9! 12 × 11× 10
C (12,3) =
=
= 2 × 11× 10 = 220 .
=
3!(12 − 3)! 3 × 2 × 1× ( 9!)
3× 2
Lecture 3
26
Instruction: Experiments, Sample Spaces, and Outcomes
In his Pensées, Blaise Pascal compared man's choice between belief and non-belief in
God as a coin "being spun which will come down heads or tails," and he asks, "How will you
wager?" Not everyone will choose their faith based on probability, but decisions based on
probability are not uncommon. In chapter three, we will examine some basic precepts of
probability theory, and we will begin with the definition of an experiment.
An experiment is a finite set of actions with a finite set of
associated observable results.
For example, if a student flips a coin twice, each flip of the coin represents an action with two
possible results (heads, h, or tails, t). The two flips together represent an experiment, a set of two
actions. The experiment in this example has four possible results: hh, ht, th, tt. It is important to
note that a single toss of a coin (a single action) can comprise an experiment.
Any execution or performance of an experiment represents a trial.
A trial is a single execution or performance of an experiment
The results of an experiment are called the outcomes.
Outcomes are the most basic results of an experiment.
The set of outcomes associated with an experiment is called the sample space and denoted S.
The sample space, S, of an experiment is the set of all the associated outcomes.
For the experiment above comprised of two coin flips, the sample space is the set of sequences of
heads/tails that result, i.e., S = {( hh ) , ( ht ) , ( th ) , ( tt )} . If the experiment consisted of only one
coin flip, then there are only two basic outcomes, heads or tails, and S = {h, t}
Consider an experiment comprised of a single random roll of the six-sided die in Figure 1
observing the number of dots facing up. The sample space for this simple experiment would be
the set of numbers: S = {1, 2, 3, 4, 5, 6} .
Figure 1.
If this experiment is performed and the die lands with three dots facing up, the outcome of this
particular trial is 3. Viewed as a set with a single element, the outcome of the trial is a subset of
the sample space. Subsets of the sample space will be discussed further in the next segment of
the lecture.
Lecture 3
27
Consider two sets: A = {1, 2, 3, 4} and B = {1, 2, 3} , and the number wheels below. Set A
is the sample space associated with the action defined as one spin of number wheel A. Set B is
the sample space associated with the action defined as one spin of number wheel B. Assume that
each number wheel or dial is fair, meaning that for either of the dials the likelihood that the
arrow will indicate any given number after operation is no greater than the likelihood of another
number being indicated.
A
B
1
2
4
3
1
2
3
Imagine spinning the arrows of the number wheels A and B above and observing the ordered pair
of numbers obtained. This activity would be an experiment with two actions. Spinning dial A is
one action. Spinning dial B is a second action. Recall that the sample space is the set of all the
possible outcomes of the experiment. In this case, the sample space is the Cartesian product of
set A and set B:
S = A × B = {(1,1) , (1, 2 ) , (1,3) , ( 2,1) , ( 2, 2 ) , ( 2,3) , ( 3,1) , ( 3, 2 ) , ( 3,3) , ( 4,1) , ( 4, 2 ) , ( 4,3)}
In probability, the cardinal number of the sample space, denoted n(S), is important. The
cardinal number of a set equals the number of elements in the set; therefore, the cardinal number
of S equals the total number of possible outcomes in the sample space. The Multiplication
Principle stated below gives the cardinal number of a Cartesian product.
n ( E1 × E2 ×
× E p ) = n ( E1 ) ⋅ n ( E2 ) ⋅
⋅ n ( Ep )
Accordingly, the Multiplication Principle can be used to determine the number of outcomes of
an experiment involving p independent actions where n ( E1 ) represents the number of outcomes
associated with action E1 , n ( E2 ) represents the number of outcomes associated with action E2 ,
and so on. For the experiment with the two dials A and B:
Lecture 3
28
n ( S ) = n ( A) ⋅ n ( B )
n(S ) = 4⋅3
n ( S ) = 12
Since S has twelve elements, the experiment with sample space S has twelve possible outcomes.
Instruction: Events
An event is a subset of a sample space. Since a sample space is a set of all the possible
outcomes of an experiment, an event is a set of outcomes.
An event is a subset of a sample space.
Recall that the elements of a sample space are outcomes associated with an experiment.
Accordingly, a subset of the sample space is a set of outcomes. To illustrate the distinction
between an outcome and an event, we will regard an experiment defined as spinning the two
number wheels below and observing the result.
A
B
1
2
1
2
4
3
4
3
The sample space for this experiment—a Cartesian product of the sample spaces associated with
each action (the spin of dial A and the spin of dial B) —is below.
⎧⎪(1,1) , (1, 2 ) , (1,3) , (1, 4 ) , ( 2,1) , ( 2, 2 ) , ( 2,3) , ( 2, 4 ) , ⎫⎪
S =⎨
⎬
⎩⎪( 3,1) , ( 3, 2 ) , ( 3,3) , ( 3, 4 ) , ( 4,1) , ( 4, 2 ) , ( 4,3) , ( 4, 4 ) ⎭⎪
Using this experiment, an event might be the set of ordered pairs whose sum is even or the set or
ordered pairs whose product is less than four. For example, if D is the event that the ordered
pairs have a ratio of one, then D = {(1,1) , ( 2, 2 ) , ( 3,3) , ( 4, 4 )} . If X is the event that the sum of
the ordered pairs equals six, then X = {( 2, 4 ) , ( 3,3) , ( 4, 2 )} . If N is the event that the product of
the ordered pairs is greater than nine, then N = {( 3,4 ) , ( 4,3) , ( 4,4 )} . The event that the ordered
Lecture 3
29
pairs will have a sum equal to six or a product greater than nine is the union of event X with
event N: X ∪ N = {( 2, 4 ) , ( 3,3) , ( 3, 4 ) , ( 4, 2 ) , ( 4,3) , ( 4, 4 )} .
Events X and N are two mutually exclusive events according to the definition stated
below.
Events are mutually exclusive if they contain no common outcomes.
Consequently, E and F are mutually exclusive if E ∩ F = { } .
Since event X does not contain any outcomes present in event N, events X and N are mutually
exclusive. Consequently, the intersection of event X with event N is empty.
Instruction: The Cardinal Number of Events
As we have seen, the cardinal number of the sample space, n ( S ) , equals the number of
possible outcomes of the associated experiment. Similarly, the cardinal number of an event
equals the number of outcomes that describe the event. For example, recall the experiment with
dials A and B above. There are only three outcomes in S that describe N, the event that the
ordered pair generated by the experiment has a product greater than nine; therefore, n ( N ) = 3 .
If two events are mutually exclusive, then the Addition Rule for Mutually Exclusive Sets
stated below gives the cardinal number (the number of outcomes) of the union of the two events.
If E and F are mutually exclusive, then n ( E ∪ F ) = n ( E ) + n ( F )
The General Addition Rule stated below gives the cardinal number of the union of any two
events.
n(E ∪ F ) = n(E) + n(F ) − n(E ∩ F )
Reconsider set D and set X.
D = {(1,1) , ( 2, 2 ) , ( 3,3) , ( 4, 4 )} , n ( D ) = 4
X = {( 2, 4 ) , ( 3,3) , ( 4, 2 )} , n ( X ) = 3
D ∩ X = {( 3,3)} , n ( D ∩ X ) = 1
The General Addition Rule gives number of outcomes in the union of event D with event X.
n ( D ∪ X ) = n ( D) + n ( X ) − n ( D ∩ X )
n(D ∪ X ) = 4 + 3 −1
n(D ∪ X ) = 6
Lecture 3
30
The General Addition Rule gives the number of outcomes in the union of any two events whether
or not the two events are mutually exclusive. In the case that the events are mutually exclusive
the intersection is an empty set whose cardinal number is zero.
In probability, the sample space of an experiment serves as the universal set.
Accordingly, the complement of an event E, denoted E C or E ' or E (or even ∼ E , which reads
"not E"), is the subset of the sample space whose elements are the outcomes in S not found in E.
Earlier we defined event D as the event that the ordered pairs in S have a ratio equal to
one. The complement event, D C , is the event that the ordered pairs in S will not have a ratio of
one; thus, D C = {(1, 2 ) , (1,3) , (1, 4 ) , ( 2,1) , ( 2,3) , ( 2, 4 ) , ( 3,1) , ( 3, 2 ) , ( 3, 4 ) , ( 4,1) , ( 4, 2 ) , ( 4,3)} .
The definition of the complement event can be used to find a general rule for the cardinal
number of a complement event. The complement of E is the set of outcomes in the sample space
not in E. Accordingly, n ( E C ) + n ( E ) = n ( S ) . Subtracting n ( E ) from both sides, we have
n ( E C ) = n ( S ) − n ( E ) , which can be generalized as the Complement Principle for a Sample
Space stated below.
n ( S ) = n ( EC ) + n ( E )
n ( EC ) = n ( S ) − n ( E )
n ( E ) = n ( S ) − n ( EC )
Instruction: Theoretical & Empirical Probability
Probability is a numerical measure of the likelihood of an outcome or event associated
with an experiment. Specifically, probability is a ratio. To address probability, this segment of
the lecture will consider two experiments. First, the flip of a coin that can land head-side up or
tail-side up. Second, the birth of a child that can be born male or female.
The coin flip experiment has two possible outcomes: the coin lands head-side up,
denoted h, and the coin lands tail-side up, denoted t. The sample space, S, for the coin flip is
S = {h, t} . Let H represent the event that the coin lands head-side up, then H = {h} . Let T
represent the event that the coin lands tail-side up, then T = {t} . A typical question associated
with this experiment asks, "How likely is event H?" To answer this question, we assign a
measure called the probability of H, denoted P ( H ) , based on the definition of probability as the
ratio of the number of favorable outcomes to the number of total outcomes, i.e.,
P ( H ) = n ( H ) n ( S ) , so P ( H ) = 1 2 . This definition of probability requires that all the
outcomes be equally likely. Applied to the coin flip experiment, the likelihood of each possible
outcome intuitively seems equal and no actual flip of the coin has to be performed. This type of
Lecture 3
31
probability is called theoretical probability since the likelihoods are based on theory rather than
actual performed experiments. Formally, Theoretical Probability is defined below.
For a finite sample space S of equally likely outcomes, the theoretical
probability of event E, a subset of S, is given by
P(E) =
number of elements (outcomes) in E n ( E )
.
=
number of elements (outcomes) in S n ( S )
Not all probabilities are theoretical. Some are based on the performance of experiments.
Consider, for example, our second experiment, the birth of a child that can be born male or
female. According to Mark Alpert writing in Scientific American in July 1998, there were 74
children born in the years 1977 to 1984 to parents who were exposed to a cloud of dioxin
released into the atmosphere after a chemical plant explosion in Seveso, Italy in 1976. Of these
74 births, 26 of the infants were boys. The other 48 infants were girls. These 74 births reported
by Mark Alpert represent 74 trials of an experiment. The set of actual outcomes of each of the
trials is called a trial space.
A trial space, T , is a set of outcomes recorded from a finite set of trials.
In this example, T = {b1 , b2 , …, b26 , g1 , g 2 , …, g 48 } , and n ( T
) = 74.
The trials that resulted in
boy births are a special subset of the trial space called an event space. For example, if B
represents the event space that includes all the outcomes from the finite set of trials in which a
boy was born, B = {b1 , b2 , …, b26 } , and n ( B ) = 26 . Similarly, if G represents the event space
that includes all outcomes from the finite set of trials in which a girl was born, then
G = { g1 , g 2 , …, g 48 } , and n ( G ) = 48 . Based on these births, it is obvious that the likelihood of a
boy being born under the given conditions is not equal to the likelihood of a girl being born. For
such instances, the definition of theoretical probability does not apply. Instead, we will rely on
the definition of Empirical Probability stated in the box on the following page.
For an outcome E that may happen when an experiment is performed, then
the empirical probability of the outcome E is given by
P(E) =
number of trials with outcomes that describe E n ( E )
=
number of trials
n (T )
where E is the event space that contains all the outcomes from a finite set of
trials that describe event E.
Lecture 3
32
The two definitions of probability are similar and the distinction between the two is
subtle, having mostly to do with the difference between a sample space and a trial space.
Theoretical probability depends in part on the definition of a sample space, which is the set of all
the equally likely possible outcomes associated with an experiment. This is a set of outcomes
that could occur for a given experiment. Empirical probability relies in part on the definition of a
trial space, which is the set of all the actual outcomes that have occurred in a finite set of trials of
an experiment.
Let's reconsider the trials comprised of the 74 births in the years 1977 to 1984 to parents
exposed to dioxin due to the chemical plant explosion in Seveso, Italy in 1976. Here, it is
evident that the definition for empirical probability applies because experiments have been
performed and outcomes have occurred. If B represents the event that a boy was born under the
stated conditions of the dioxin-exposure experiment, then we find P(B), the probability of event
B, using the definition of empirical probability:
P ( B) =
number of trials with outcomes that describe B n ( B ) 26 13
=
=
=
≈ 0.351 ≈ 35.1% .
number of trials of experiment
n ( T ) 74 37
The Law of Large Numbers stated below makes a connection between empirical and
theoretical probability.
As an experiment undergoes an increasing number of trials, the empirical
probability of a particular event approaches a fixed number. More specifically, as
n ( T ) approaches infinity, the empirical probability of an event approaches the
theoretical probability of the event.
The Law of Large Numbers allows us to estimate the theoretical probability of an event using
experiments, multiple trials, and empirical probability. The Law of Large Numbers indicates that
the estimate becomes more accurate as the number of trials increases. If, for example, there had
been 10,000 births instead of only 74 under the stated dioxin-exposure conditions, the percent of
boy births would be even closer to the theoretical probability of giving birth to a boy after such
exposures.
Instruction: Properties of Probability
Recall that events are subsets of a sample space. Accordingly, event E is a subset of S
and 0 ≤ n ( E ) ≤ n ( S ) . Using this inequality, we can arrive at a fundamental property of
probability. Consider dividing the terms of the inequality, 0 ≤ n ( E ) ≤ n ( S ) , by n ( S ) :
n(E) n(S )
0
≤
≤
.
n(S ) n(S ) n(S )
Lecture 3
33
Note that zero divided by any non-zero number is zero and any non-zero number divided by
itself is one:
n(E)
0≤
≤ 1.
n(S )
Recall that theoretical probability defines P ( E ) as n ( E ) n ( S ) :
0 ≤ P ( E ) ≤ 1.
Using the same process using the definition of empirical probability and the fact that an event
space is a subset of a trial space, we can arrive at the same conclusion for empirical probability.
Accordingly, probability is a measure from zero to one inclusive.
In summary, we see that the probability of an event must be a number r such that zero is
less than or equal to r and r is less than or equal to one. Moreover, if E is an event that does not
or cannot occur in the experiment or is an impossible event, then P ( E ) = 0 . If, on the other
hand, E is the only event that occurs in the experiment or is an event certain to occur, then
P ( E ) = 1 . The box below summarizes these properties.
If E is an event associated with an experiment, then
I.
0 ≤ P ( E ) ≤ 1.
II.
If E = {
III.
} or if E = { } , then P ( E ) = 0 .
If E = S or if E = T , then P ( E ) = 1 .
Instruction: Probability Distribution
This part of the lecture discusses probability distributions. In tabular form, a probability
distribution is a table of two rows (or columns). One row lists the mutually exclusive events
whose union comprises the sample space of an experiment. The second row lists the
probabilities associated with each event of the experiment. Consider an experiment that entails
rolling the twelve-sided die shown in Figure 1 and observing the number that lands face up.
Figure 1
The sample space for the experiment is S = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12} . To construct the
probability distribution, we assign a random variable, X, to represent events under observation.
One row will list the "values" of X and the other will list the corresponding probabilities, P ( X ) .
Lecture 3
X
P(X )
34
1
1 12
2
1 12
3
1 12
4
1 12
5
1 12
6
1 12
7
1 12
8
1 12
9
1 12
10
1 12
11
1 12
12
1 12
Since X represents the mutually exclusive events whose union comprises the sample space, the
sum of the probabilities equals one.
The experiment above was comprised of one action. Consider now an experiment
comprised of two actions: rolling two six-sided die like those in Figure 2, observing the sum of
the result of each die.
Figure 2
Let A be the set of outcomes associated with a single toss of a six-sided die, A = {1, 2, 3, 4, 5, 6} ,
then the sample space of the experiment equals the Cartesian product, A × A .
⎧(1,1) , (1, 2 ) , (1, 3) , (1, 4 ) , (1, 5 ) , (1, 6 ) , ⎫
⎪
⎪
⎪( 2,1) , ( 2, 2 ) , ( 2, 3) , ( 2, 4 ) , ( 2, 5 ) , ( 2, 6 ) , ⎪
⎪
⎪
⎪( 3,1) , ( 3, 2 ) , ( 3, 3) , ( 3, 4 ) , ( 3, 5 ) , ( 3, 6 ) , ⎪
S = A× A = ⎨
⎬
⎪( 4,1) , ( 4, 2 ) , ( 4, 3) , ( 4, 4 ) , ( 4, 5 ) , ( 4, 6 ) , ⎪
⎪ 5,1 , 5, 2 , 5, 3 , 5, 4 , 5, 5 , 5, 6 , ⎪
⎪( ) ( ) ( ) ( ) ( ) ( ) ⎪
⎪( 6,1) , ( 6, 2 ) , ( 6, 3) , ( 6, 4 ) , ( 6, 5 ) , ( 6, 6 ) ⎪
⎩
⎭
The defined experiment observes the sum of the result of each die, so the random variable X will
represent a sum of the ordered pairs.
X
P(X )
X
P(X )
2
1
36
8
5
36
3
2
1
=
36 18
3
1
=
36 12
4 1
=
36 9
5
36
6 1
=
36 6
9
4 1
=
36 9
3
1
=
36 12
2
1
=
36 18
1
36
5
36
4
5
6
7
10
11
12
8
Lecture 3
35
Graphically, a probability distribution is a set of ordered pairs ( X , P ( X ) ) .
P(X )
0.18
0.16
0.14
0.12
0.10
0.08
0.06
0.04
0.02
0.00
2
3
4
5
6
7
8
9
10
11
12
X
Instruction: Probability with "Not"
Recall the Complement Principle for a Sample Space below.
n ( E ) = n ( S ) − n ( EC )
Dividing each term of the equality by n ( S ) , we get:
n(E)
n (S )
= 1−
n ( EC )
n (S )
.
Applying the definition of theoretical probability, we get the Complement Property of
Probability:
P ( E ) = 1− P ( EC )
The Complement Property allows probabilities to be found indirectly. Consider the probability
of a multiple of ten not occurring in an experiment comprised of spinning the two number wheels
below and observing the two-digit numbers that result.
Ten's
One's
8
9
1
7
2
6
3
5
4
0
7
2
6
3
5
4
Lecture 3
36
The Multiplication Principle gives n ( S ) : 8 ⋅ 8 = 64 . There are sixty-four possible outcomes,
but only eight outcomes will end in zero (numbers that end in zero are multiples of ten). If N
represents the event that the two-digit number is not a multiple of ten, then N C represents the
event that the two-digit number is a multiple of ten, and the Complement Property finds P ( N )
as below.
P ( N ) = 1− P ( N
C
n(NC )
) = 1− n (S )
= 1−
8 56
=
64 64
Instruction: Probability with "Or"
Recall the General Addition Rule below.
n(E ∪ F ) = n(E) + n(F ) − n(E ∩ F )
Dividing each term of the equality by n ( S ) , we get:
n(E ∪ F )
n (S )
=
n(E)
n (S )
+
n(F )
n (S )
−
n(E ∩ F )
n (S )
.
Applying the definition of theoretical probability, we get the General Addition Rule of
Probability:
P (E ∪ F ) = P (E) + P (F ) − P (E ∩ F )
The General Addition Rule of Probability helps find probabilities involving "or." The
conjunction "or" corresponds to the union of events. Consider the probability of a multiple of
three or a multiple of two occurring in an experiment comprised of spinning the two number
wheels below and observing the product of the result.
A
B
8
1
7
2
6
1
5
3
5
4
7
Lecture 3
37
Let W represent the event that the product is a multiple of two. Let H represent the event that the
product is a multiple of three. Thinking of the sample space as a Cartesian product, it is easy to
see that W includes all the outcomes with two, four, six, or eight from dial A as a factor.
Likewise H includes all the outcomes with three or six from dial A as a factor. Consequently,
W ∩ H will include the outcomes with the six from dial A as one factor (multiples of six are
multiples of two and three). The probability of a multiple of three or a multiple of two occurring
is the probability of W ∪ H given by the General Addition Rule of Probability below.
12 6
3 15 5
+
−
=
=
24 24 24 24 8
A classic example of probability with "or" involves drawing a card from a standard deck
of fifty-two playing cards. A standard deck has four suits: hearts, diamonds, clubs, and spades.
Each suit has thirteen cards: ace, 2, 3, 4, 5, 6, 7, 8, 9, 10, jack, queen, and king. Imagine an
experiment that requires the draw of one card from a standard deck. If J represents the event of
drawing a jack, then n ( J ) = 4 because there are four jacks. If D represents the event of drawing
P (W ∪ H ) = P (W ) + P ( H ) − P (W ∩ H ) =
a diamond, then n ( D ) = 13 because there are fourteen diamonds. Since one of the diamonds is a
jack, n ( J ∩ D ) = 1 . What is the probability of drawing a jack or a diamond? Apply the General
Addition Rule of Probability.
P ( J ∪ D) = P ( J ) + P ( D) − P ( J ∩ D)
4 13 1
+ −
52 52 52
16
P ( J ∪ D) =
52
4
P ( J ∪ D) =
13
P ( J ∪ D) =
In the two previous examples, the probability involving "or" involved events not
mutually exclusive. If the events are mutually exclusive, then the intersection of the two events
is empty. Since P ( ∅ ) = 0 , then we have the Addition Rule of Probability for Mutually
Exclusive Events:
If E and F are mutually exclusive, then P ( E ∪ F ) = P ( E ) + P ( F )
To apply this rule, consider the experiment from above involving the draw of a single card from
a deck of playing cards. Let J represent the event of drawing a jack, and let K represent the event
of drawing a king. What is the probability of drawing a jack or a king? Since there are no jacks
that are also kings in the deck, the Addition Rule of Probability for Mutually Exclusive Events
applies. Note n ( J ) = 4 and n ( K ) = 4 , and apply the rule.
Lecture 3
38
P(J ∪ K ) = P(J ) + P(K )
4
4
+
52 52
8
P(J ∪ K ) =
52
2
P(J ∪ K ) =
13
P(J ∪ K ) =
Instruction: Probability with "And"
Previously, we discussed the experiment of drawing one card from a standard deck, and
asked, "What is the probability of drawing a jack or a diamond?" Now, we will ask, "What is the
probability of drawing a jack and a diamond." In symbols, if J represents the event that a jack is
drawn and D represents the event that a diamond is drawn, then the question asks, "What is
P ( J ∩ D ) ?" Since only one card in the fifty-two card deck is both a jack and a diamond,
P ( J ∩ D ) = 1 52 . Another way to answer the question is to apply the Special Multiplication
Rule of Probability of Independent Events demonstrated below in particular.
P ( J ∩ D) = P ( J ) ⋅ P ( D)
P ( J ∩ D) =
4 13
⋅
52 52
13
P ( J ∩ D) =
1
52
The reader may notice that the previous discussion gave a rule for probabilities involving "or"
that required addition (and subtraction if the events were not mutually exclusive) while above we
see a probability involving "and" that requires multiplication. It is typically true that
probabilities involving "or" require addition while probabilities involving "and" require
multiplication. We have also noted, however, that simple addition is not enough to find the
probability of event E or F if the two events are not mutually exclusive (subtraction of the
intersection is also required). Similarly, with probabilities involving "and," we must think
carefully about the types of events involved.
The Special Multiplication Rule of Probability of Independent Events demonstrated
above only applies to the intersection of independent events. Independent events are defined
below.
Events E and F are independent if the occurrence of one has no
affect on the probability of the other.
The Special Multiplication Rule of Probability of Independent Events is stated below in general
terms.
Lecture 3
39
If E and F are independent events, then P ( E ∩ F ) = P ( E ) ⋅ P ( F ) .
Consider an experiment that consists of rolling two six-sided dice, one red and one black.
This experiment involves two actions: the roll of the red die and the roll of the black die. What
is the probability of rolling a "four" on the red die and rolling a "two" on the black die?
Intuitively, we know that whatever happens with the red die will have no affect on the
probabilities of outcomes associated with the black die, so the Special Multiplication Rule of
Probability of Independent Events applies. Let F represent the event that the red die lands with
the "four" facing up, and let T represent the event that the black die lands with the "two" facing
up. Then,
P ( F ∩ T ) = P ( F ) ⋅ P (T )
P (F ∩T ) =
1 1 1
⋅ =
6 6 36
The Special Multiplication Rule of Probability of Independent Events is "special" in the
sense that it only applies to independent events. Consequently, its application depends on
recognizing whether or not two events are independent. Consider our red and black six-sided die
and events F and T from above. Would the probability of T change if we knew F had occurred?
If not, the events are independent. Let's assume we know the red die has rolled a "four," so F has
occurred. In this situation, we call F a given event. The notation P (T | F ) indicates the
probability of event T given that event F has occurred. If P (T | F ) = P (T ) , the events are
independent. Checking to see if this equality is true, is called the Test for Independence.
Events E and F are independent if P ( E | F ) = P ( E ) .
If the test above shows independence, that is, if P ( E | F ) = P ( E ) , then multiplying
P ( E ) by P ( F ) gives P ( E ∩ F ) . If the test, however, fails to show independence, that is, if
P ( E | F ) ≠ P ( E ) , then the Special Multiplication Rule of Probability of Independent Events no
longer applies, and it is necessary to apply the General Multiplication Rule of Probability stated
below.
If E and F are any two events, then P ( E ∩ F ) = P ( E ) ⋅ P ( F | E ) .
The General Multiplication Rule of Probability can be extended for more than two events. The
rule extended to three events is stated below.
If E, F, and G are any three events, then P ( E ∩ F ∩ G ) = P ( E ) ⋅ P ( F | E ) ⋅ P ( G | E ∩ F ) .
Lecture 3
40
The beginning of this discussion examined a single draw from a standard deck of fiftytwo playing cards. Now, we turn to multiple successive draws without replacement. (The phrase
"without replacement" indicates that cards are not returned to the deck once they are drawn.)
What is the probability of drawing two successive kings? Let K1 represent the event that a king
is drawn first. Let K 2 represent the event that the second draw is also a king. Intuitively, we note
that K1 and K 2 are not independent because P ( K 2 ) has two different measures dependent on
the outcome of the first draw. If a king is drawn first, then there are fifty-one cards left and only
three kings remaining, so P ( K 2 ) = 3 51 = 1 17 . If, however, a king is not drawn first, then there
are fifty-one cards left and four kings remaining, so P ( K 2 ) = 4 51 . Accordingly, we will apply
the General Multiplication Rule of Probability, P ( E ∩ F ) = P ( E ) ⋅ P ( F | E ) :
P ( K1 ∩ K 2 ) = P ( K1 ) ⋅ P ( K 2 | K1 )
1
1
4 3
1
.
P ( K1 ∩ K 2 ) =
⋅
=
52 51 221
13
17
If the number of draws increases, the General Multiplication Rule of Probability still
applies. Consider five draws from a standard deck without replacement. What is the probability
of drawing five diamonds? Let D1 , D2 , … , D5 represent the events of drawing diamonds on each
of the five successive draws.
P ( D1 ∩ D2 ∩ D3 ∩ D4 ∩ D5 ) =
13 12 11 10 9
33
⋅ ⋅ ⋅ ⋅
=
≈ 0.000495
52 51 50 49 48 66,640
Instruction: Conditional Probability
The previous discussion examined the General Multiplication Rule of Probability stated
below.
If E and F are any two events, then P ( E ∩ F ) = P ( E ) ⋅ P ( F | E ) .
P ( F | E ) , the probability of event F given event E, is called a conditional probability.
Conditional probabilities are computed on the assumption that some other event—the given
event—has occurred. Now, we will use the General Multiplication Rule of Probability to derive
a rule for conditional probabilities.
Consider the General Multiplication Rule of Probability:
P (E ∩ F ) = P (E)⋅ P (F | E) .
Divide both sides of the equality by P ( E ) :
Lecture 3
41
P (E ∩ F )
P (E)
P (E ∩ F )
P (E)
=
P (E) ⋅ P (F | E)
P (E)
= P ( F | E).
Substituting the definition for probability, we have:
n(E ∩ F )
n (S )
n(E)
= P (F | E)
n (S )
Simplifying, we arrive at a definition for conditional probability stated in the box below.
P(F | E) =
P(F | E) =
P(F | E) =
P (F | E) =
n( E ∩ F )
n(S )
÷
n( E )
n(S )
n( E ∩ F ) n(S )
⋅
n( E )
n(S )
n( E ∩ F )
n( E )
n(F ∩ E)
number of outcomes that describe both F and E
=
.
number of outcomes that describe the given event
n(E)
To arrive at this definition in particular, consider an experiment involving the roll of two
six-sided dice like those pictured in Figure 1 observing the ordered pair of the number of dots
that face up after the roll.
Figure 1
Let N represent the event that the sum of the two numbers facing up is nine and let T represent
the event that one of the two dice lands with a three facing up. We see,
N = {( 3, 6 ) , ( 4, 5 ) , ( 5, 4 ) , ( 6, 3)} , and
Lecture 3
42
⎧⎪(1, 3) , ( 2, 3) , ( 3, 3) , ( 4, 3) , ( 5, 3) , ( 6, 3) , ⎫⎪
T =⎨
⎬.
⎪⎩( 3,1) , ( 3, 2 ) , ( 3, 4 ) , ( 3, 5 ) , ( 3, 6 )
⎪⎭
To consider P ( N | T ) , first think about the denominator in the definition of theoretical
probability:
P (E) =
number of elements (outcomes) in E
.
number of elements (outcomes) in S
The sample space includes all the possible outcomes of the experiment. The sample space for the
experiment or rolling two six-sided dice includes thirty-six possible outcomes.
⎧(1,1) , (1, 2 ) , (1, 3) , (1, 4 ) , (1, 5 ) , (1, 6 ) , ( 2,1) , ( 2, 2 ) , ( 2, 3) , ( 2, 4 ) , ( 2, 5 ) , ( 2, 6 ) , ⎫
⎪
⎪
S = ⎨( 3,1) , ( 3, 2 ) , ( 3, 3) , ( 3, 4 ) , ( 3, 5 ) , ( 3, 6 ) , ( 4,1) , ( 4, 2 ) , ( 4, 3) , ( 4, 4 ) , ( 4, 5 ) , ( 4, 6 ) , ⎬
⎪
⎪
⎩( 5,1) , ( 5, 2 ) , ( 5, 3) , ( 5, 4 ) , ( 5, 5 ) , ( 5, 6 ) , ( 6,1) , ( 6, 2 ) , ( 6, 3) , ( 6, 4 ) , ( 6, 5 ) , ( 6, 6 ) ⎭
For conditional probability, we know some outcomes have occurred, which means we know
some outcomes have not occurred. Thus, the number of possible outcomes has been reduced
from the number of elements in S to the number of elements in T. Adjusting the definition for
this possibility, we might word the definition differently:
P (E) =
number of possible outcomes that describe E
.
number of possible outcomes
For P ( N | T ) , the numerator will equal n ( N ∩ T ) because the only possible outcomes that
describe N | T are those that describe N that are in T. Moreover, the denominator will equal
n (T ) because those are the only possible outcomes when it is known that T has occurred. Thus,
P(N |T ) =
n (N ∩T )
n (T )
=
4
.
11
Assignment 3
43
Problems
For the first two problems below, consider an experiment whose outcomes are the ordered pairs (m,n)
formed from the outcomes of two tosses: 1) spinning dial M, and 2) spinning dial N.
Dial M
Dial N
Represent the outcomes of the toss with dial M with set M = {1, 2, 3, 4, 5, 6, 7, 8} and the outcomes of
the toss with dial N with set N = {1, 2, 3} .
#1
#2
A.
Find the sample space S using roster notation for the experiment by finding the
Cartesian product M × N .
B.
Let E represent the event that the product of an ordered pair in S is even, and let F
represent the event that the product of an ordered pair in S is less than seven. Calculate
n ( E ) , n ( F ) , n ( E ∩ F ) , and n ( E ∪ F ) .
A.
Calculate P ( E ) , P ( F ) , and P ( E ∩ F ) .
B.
Calculate P ( E ∪ F ) .
---------------------------------------------------------------------------------------------------------------------------#3
A combination lock consists of three numbers each from zero to fifty-four inclusive. Find the
probability that a combination is not composed of three of the same digits in a row.
#4
A.
From a standard deck of fifty-two playing cards, draw one card, note the outcome,
reshuffle the card back into the deck, and draw again. Under these circumstances, find
the probability of drawing two diamonds.
B.
From a standard deck of fifty-two playing cards, draw one card, note the outcome, do
not replace the card, and draw again. Under these circumstances, find the probability of
drawing two diamonds.
#5
Consider an experiment involving the toss of two six-sided dice observing the sum of the
results of each die. Let P ( S ) represent the probability that the sum equals six. Let P ( E )
represent the probability that the sum equals an even number and P ( O ) represent the
probability that the sum equals an odd number. Let P ( D ) equal the probability that the
addends of the sum are equal (i.e., doubles). Find P ( S | E ) , P ( S | O ) , and P ( S | D ) .
Lecture 4
44
Instruction: Expected Value
The start of this lecture discusses expected value or mathematical expectation. Expected
value is a special sum associated with the probability distribution of a game. A game, defined
below, is an experiment.
A game is an experiment with a defined set of discrete values called payoffs
for a random variable, X, that represents a set of mutually exclusive events
whose union comprises the sample space of the experiment.
The probability distribution associated with a game lists the values of a random variable, X, and
the probabilities, P(X), corresponding to the values of the random variable. The values of the
random variable will be "payoffs" measured in dollars, time units, spaces on a board, or other
units of measures. The expected value associated with a probability distribution equals the sum
of the products of the values of the payoffs of the random variable and the probabilities
corresponding to those payoffs. In other words, the mean µ of a probability distribution is the
expected value of its random variable.
If X is a discrete random variable with payoffs X 1 , X 2 , … , X n , occurring with
probabilities P ( X 1 ) , P ( X 2 ) , … , P ( X n ) , respectively, then the expected
value, denoted E ( X ) , is given by the sum of the products:
E ( X ) = µ = ∑ X i P ( X i ) =X 1 ⋅ P ( X 1 ) + X 2 ⋅ P ( X 2 ) +
n
i =1
+ Xn ⋅ P( Xn )
Consider a roulette wheel with thirty-eight equally-likely possible outcomes. Typically, a bet
placed on a single number pays thirty-five to one, meaning a winning one-dollar bet earns thirtyfive dollars. The table below represents a probability distribution for a one-dollar bet placed on
one spin of the roulette wheel.
X
P(X )
–$1.00 $35.00
37
1
38
38
The sum of products below gives E ( X ) , the expected value of this experiment.
37
1
+ 35 ⋅
38
38
37 35
E(X ) = − +
38 38
2
E(X ) = −
≈ −0.053
38
E ( X ) = −1 ⋅
Lecture 4
45
Thus, the expected value of the one dollar bet on a single number and single spin of a roullette
wheel equals a loss of about five cents.
Significantly, the expected value does not equal the amount the player might win or lose.
Accordingly, expected value has nothing to do with the subjective expectations of the player.
The player may optimistically expect to win thirty-five dollars, or the player may realistically
expect to lose one dollar. No rational player would expect to lose five cents. Indeed, it is
impossible to lose five cents on a single spin. The term "expected" comes from the average
payoff per game after a large number of trials. The roullette player can expect to lose an average
of five cents per game if he/she plays the game a large number of times.
Consider the board game with the unbiased spinner in Figure 1. Assume each player
spins the dial on his or her turn and moves along the board according to the result of the spin.
Any adult who plays a game like this may have found him/herself wondering if the game will
ever end. In other words, "Can a player reasonably expect to reach the finish space?" The
question involves expected value. The expected value associated with a player's turn is
calculated below.
⎛1⎞ ⎛1⎞
⎛1⎞
⎛1⎞
⎛1⎞
E ( X ) = 3 ⎜ ⎟ + 1⎜ ⎟ − 2 ⎜ ⎟ + 4 ⎜ ⎟ + 0 ⎜ ⎟
⎝5⎠ ⎝5⎠
⎝5⎠
⎝5⎠
⎝5⎠
E ( X ) = 3 ( 0.2 ) + 1( 0.2 ) − 2 ( 0.2 ) + 4 ( 0.2 ) + 0 ( 0.2 )
E ( X ) = 0.6 + 0.2 − 0.4 + 0.8 = 1.2
According to the result, a player can expect to average a gain of 1.2 spaces after a large number
of turns, so, yes, the player can expect to finish the game.
Another question associated with expected value involves fairness. Previously, we have
equated fairness with a lack of bias. If all the outcomes of a die are equally likely the die is said
to be fair. With games, however, fairness equates to a zero expected value. Consider a game
that pays according to the results of the unbiased spinner below.
win win
$8 $2
lose
$5
Lecture 4
46
The expected value, calculated to be zero below, shows that this game is fair.
E ( X ) = $8 ( 0.25 ) + $2 ( 0.25 ) − $5 ( 0.5 )
E ( X ) = $2 + $0.5 − $2.5
E ( X ) = $0
Instruction: Standard Deviation of a Discrete Random Variable
The variance of a probability distribution is calculated by multiplying each possible
squared deviation ⎡⎣ X i − E ( X ) ⎤⎦ by its corresponding probability P ( X i ) and then finding the
sum of the resulting products. Accordingly, the equation below defines σ 2 , the variance of a
discrete random variable.
2
The variance of a discrete random variable, denoted σ 2 , is given by
(
σ 2 = ∑ ⎡⎣ X i − E ( X ) ⎤⎦ ⋅ P ( X i )
n
i =1
2
)
where X i equals the ith outcome of the discrete random variable, and P ( X i )
equals the probability of occurrence of the ith outcome of the discrete random
variable.
As with the population standard deviation, the standard deviation of a discrete random
variable equals the square root of its variance.
The standard deviation of a discrete random variable, denoted σ , is given by
(
σ = σ 2 = ∑ ⎡⎣ X i − E ( X ) ⎤⎦ ⋅ P ( X i )
i =1
n
2
)
where X i equals the ith outcome of the discrete random variable, and P ( X i )
equals the probability of occurrence of the ith outcome of the discrete random
variable.
Instruction: The Binomial Probability Distribution
Imagine a game that requires spinning the dial below. Imagine a player that "wins" if the
arrow lands on the R-sector (occupying one-third of the dial) only once in the two spins.
R
RC
Lecture 4
47
A natural question asks, "What is the probability that the player wins?" To calculate the
probability that the player "wins," we will think of each spin as a trial of an experiment, and we
will consider two events, R and R C . Since R occupies one-third of the dial, P ( R ) = 1 3 and
P ( RC ) = 2 3 .
Recall that the player "wins" only if the arrow lands on the R-sector exactly once in two
spins. In other words, the player could win if R occurs on the first spin and R does not occur on
the second spin, or if R does not occur on the first spin and R does occur on the second spin. Let
R1 represent the event that R occurs on the first spin, R1C represent the event that R C occurs on
the first spin, R2 represent the event that R occurs on the second spin, and R2C represent the
event that R C occurs on the second spin. Applying the Addition Rule of Probability for Mutually
Exclusive Events together with the Multiplication Rule of Probability of Independent Events we
can find P ( winning ) as below.
P ( winning ) = P ( R1 ) ⋅ P ( R2C ) + P ( R2 ) ⋅ P ( R1C )
1 2 1 2
P ( winning ) = ⋅ + ⋅
3 3 3 3
4
P ( winning ) =
9
This probability can be written as below.
1
⎛1⎞ ⎛ 2⎞
P ( winning ) = C ( 2,1) ⋅ ⎜ ⎟ ⎜ ⎟
⎝3⎠ ⎝ 3⎠
2 −1
This is a specific example of the Binomial Probability Formula stated below in general terms.
Let W represent exactly X number of occurrences of success in n trials. If the
probability of success remains constant throughout n trials, the probability of W
is given by
X
n− X
P ( W ) = C ( n, X ) ⋅ [ p ] ⋅ [1 − p ]
where p equals the probability of success.
Applying the formula, to the situation above, we note that n = 2 because there were two spins,
X = 1 because the player won only if R occurred exactly once, p = 1 3 . Thus,
P ( W ) = C ( n, x ) ⋅ [ p ] ⋅ [1 − p ]
n− X
X
1
⎛1⎞
P ( W ) = C ( 2,1) ⋅ ⎜ ⎟
⎝3⎠
1 2
P (W ) = 2 ⋅ ⋅
3 3
4
P (W ) =
9
⎛2⎞
⋅⎜ ⎟
⎝3⎠
2 −1
Lecture 4
48
Let's consider an example from meteorology. Consider a set of weather conditions such
that a meteorologist can determine from past data that there exists a 30% chance for rain (a 0.3
probability for rain). What is the probability, that it will rain at most three times in ten instances
of these weather conditions? To answer this question, we first note the phrase "at most" and
recall that the Binomial Probability Formula applies to an exact number of occurrences.
Nevertheless, the Binomial Probability Formula will help us arrive at an answer to the question.
Let R represent the event that it rains under these conditions, and Let W1 represent exactly one
instance of rain in ten instances of the given set of conditions. P ( W1 ) , then, represents the
probability that there is one occurrence of R in ten trials:
P ( W1 ) = C ( n, X ) ⋅ ⎡⎣ P ( R ) ⎤⎦ ⋅ ⎡⎣1 − P ( R ) ⎤⎦
X
P ( W1 ) = C ( n, X ) ⋅ ⎡⎣ P ( R ) ⎤⎦ ⋅ ⎡⎣ P ( R C ) ⎤⎦
X
n− X
n− X
P ( W1 ) = C (10,1) ⋅ ( 0.3) ⋅ ( 0.7 )
10 −1
1
P ( W1 ) = 10 ⋅ ( 0.3) ⋅ ( 0.7 )
9
P ( W1 ) ≈ 0.1210608
Now, let W2 represent exactly two instances of rain and W3 represent exactly three instances of
rain, and find P ( W2 ) and P ( W3 ) in the same manner.
P ( W2 ) = C ( n, X ) ⋅ ⎡⎣ P ( R ) ⎤⎦ ⋅ ⎡⎣ P ( R C ) ⎤⎦
X
n− X
P ( W3 ) = C ( n, X ) ⋅ ⎡⎣ P ( R ) ⎤⎦ ⋅ ⎡⎣ P ( R C ) ⎤⎦
X
P ( W2 ) = C (10, 2 ) ⋅ ( 0.3) ⋅ ( 0.7 )
P ( W3 ) = C (10,3) ⋅ ( 0.3) ⋅ ( 0.7 )
P ( W2 ) = 45 ⋅ ( 0.09 ) ⋅ ( 0.7 )
P ( W3 ) = 120 ⋅ ( 0.027 ) ⋅ ( 0.7 )
P ( W2 ) ≈ 0.2334744
P ( W3 ) ≈ 0.2668279
10 − 2
2
8
n− X
10 −3
3
7
We are now ready to answer the question, "What is the probability, that it will rain at most three
times in ten instances of these weather conditions?" In other words, "What is the value of
P ( W1 ∪ W2 ∪ W3 ) ?" Applying the Addition Rule of Probability for Mutually Exclusive Events
we find P ( W1 ∪ W2 ∪ W3 ) below.
P ( W1 ∪ W2 ∪ W3 ) = P ( W1 ) + P ( W2 ) + P ( W3 )
P ( W1 ∪ W2 ∪ W3 ) ≈ 0.1210608 + 0.2334744 + 0.2668279
P ( W1 ∪ W2 ∪ W3 ) ≈ 0.6213631
The mean of the binomial distribution is equal to the product of n and p.
The mean of the binomial distribution of sample size n with p probability
of success is given by
µ = E ( X ) = np .
Lecture 4
49
The standard deviation of the binomial distribution equals the square root of the product of the
mean and the probability of failure.
The standard deviation of the binomial distribution of sample size n with p
probability of success is given by
σ = np (1 − p ) = µ (1 − p ) .
Instruction: The Poisson Probability Distribution
Suppose that we want to find the probability distribution of the number of industrial
accidents at a particular station during a time period of one month. Initially, this random variable
may not seem related to a binomial random variable, but there is an interesting relationship.
Think of the time period as being split into n subintervals, each of which is so small that
at most one accident could occur in it. Denoting the probability of an accident in any subinterval
by p, we have a binomial probability because the probability that one accident occurs equals p
while the probability that no accident occurs equals 1 – p (and the probability that more than one
accident occurs equals zero). Using this relationship to the binomial distribution, it can be
shown that the probability of X-number of industrial accidents in one month at a particular
e− λ λ X
station is given by P ( X ) =
where lambda equals the expected number of industrial
X!
accidents, i.e., the mean. Random variables possessing this distribution are Poisson random
variables.
In general, the number of random events that occur in an interval of time or space or any
other dimension often follows the Poisson distribution. The Poisson distribution applies
particularly to "rare" events, that is, events which occur infrequently in time, space, volume, etc.
The dimension in which the events occur is called the area of opportunity.
The Poisson probability distribution where λ events are expected is given by
P( X ) =
e−λ ⋅ λ X
X!
where P ( X ) equals the probability of X events in an area of opportunity.
Consider a case where the mean number of cars pulling into the drive-thru lane of a restaurant
during a two-minute interval is two. The probability that the number of vehicles exceeds three
can be calculated using the Poisson distribution. First, we calculate the probability of exactly
zero cars entering the lane as shown below.
e −2 ⋅ 2 0
P ( X = 0) =
0!
P ( X = 0 ) ≈ 0.1353
Lecture 4
50
Second, we calculate the probability of exactly one car entering the lane as well as exactly two
cars, and exactly three cars.
e −2 ⋅ 21
1! ,
P ( X = 1) ≈ 0.2707
P ( X = 1) =
e −2 ⋅ 22
e −2 ⋅ 23
P ( X = 3) =
2! ,
3!
P ( X = 2 ) ≈ 0.2707 P ( X = 3) ≈ 0.1804
P ( X = 2) =
To find the probability that the number of cars exceeds three, we use the Complement Principle
as below.
P ( X > 3) = 1 − ⎡⎣ P ( ( X = 0 ) ∪ ( X = 1) ∪ ( X = 2 ) ∪ ( X = 3) ) ⎤⎦
P ( X > 3) = 1 − ⎡⎣ P ( X = 0 ) + P ( X = 1) + P ( X = 2 ) + P ( X = 3) ⎤⎦
P ( X > 3) ≈ 1 − [ 0.1353 + 0.2707 + 0.2707 + 0.1804]
P ( X > 3) ≈ 1 − [0.8571]
P ( X > 3) ≈ 0.1429
Assignment 4
51
Problems
#1
An experiment requires the toss of a four-sided die and a six-sided die and observing the sum
of the results. Construct a probability distribution for the experiment.
#2
Consider a game where the player spins the number wheel in Figure A and loses a dollar
amount equal to odd values indicated by the arrow but wins a dollar amount equal to ten
times even values indicated by the arrow. What is the expected value of the game?
Figure A
#3
An insurance agency sells an insurance policy that pays $50,000.00 in benefits in a given year
if a worker is injured on the job and stays in the hospital one week or more. The policy sells
for a monthly premium of $42.00. Qualified workers must work for a company whose safety
regulations give the workers only a 0.002 probability of injury. What is the expected value
of the policy for the insurance agency?
#4
Consider an experiment that requires spinning the dial in Figure A. What is the probability
that the arrow will indicate the number seven exactly five times in nine trials?
#5
The mean number of vehicles entering a tunnel per two-minute interval is one. Find the
probability that the number of vehicles entering the tunnel during a two minute period
exceeds three.
Bonus
Assume that the tunnel from problem five is watched during ten two-minute intervals, thus
giving ten independent observations, X 1 , X 2 , … , X 10 , on the Poisson random variable. Find
the probability that X > 3 exactly two times.
52
Instruction: The Normal Distribution
This lecture discusses the normal distribution (also called the Gaussian distribution).
Previous lectures discussed samples and their distributions. In this section, we will consider a
particular population distribution called the normal curve. The normal curve is a bell-shaped
symmetric curve that is the graph of a theoretical relative frequency distribution of a continuous
variable associated with a large population. Recall that a continuous variable takes values that
represent categories such that an infinite number of possible scores fall between any two
measured scores. Such observations as weights, lengths, and durations are continuous variables.
Consider for example the sample of weights rounded to the nearest tenth of a microgram
and the sample's relative frequency distribution below.
⎧ 2.2, 4.9, 0.6, 2.4, 2.9, 3.1, 1.4, 2.6, 1.7, 2.3,
⎪
W = ⎨1.8, 3.2, 2.1, 4.3, 2.6, 1.9, 3.3, 0.8, 3.9, 2.5,
⎪ 2.7, 1.8, 2.3, 3.4, 1.1, 2.7, 3.5, 1.4, 3.8, 2.1
⎩
⎫
⎪
⎬
⎪
⎭
f 0.45
0.40
0.35
0.30
0.25
0.20
0.15
0.10
0.05
0.00
This symmetrical distribution represents a sample of thirty weights measured in micrograms.
Imagine that the sample represents a random sample of thirty weights taken from a type of krill
in the Atlantic ocean; then imagine the distribution associated with the population of billions of
the same type of krill. The distribution above uses five classes each with a width of one
microgram. For a population of billions, much smaller classes would be used with tiny widths
with the effect that the graph would be "smoothed" into a continuous bell-shaped curve similar to
Figure A.
Figure A
53
Indeed, many such populations have relative frequency distributions whose graph takes a shape
of this type called the normal curve whose properties are given below.
The graph of a normal curve is bell-shaped and symmetric about a
vertical line through the center of the distribution, which corresponds
to the mean, median, and mode. The normal curve approaches the Xaxis asymptotically at the far right and far left.
The functions that define or yield the distribution of a continuous random variable are called
continuous probability density functions. The normal probability density function is given
below.
The normal probability density function, f ( X ) , is given by
f (X ) =
1 ⎡ X −µ ⎤
σ ⎥⎦
2
− ⎢
1
e 2⎣
2πσ
where µ is the mean, σ is the standard deviation, and X is the
continuous random variable.
The independent variable of the normal probability density function is the continuous random
variable. The mean and the standard deviation are parameters such that every distinct
combination of µ and σ produce a different normal probability distribution. As Figure B
shows, normal distributions can vary while maintaining the characteristics that make them
normal.
Figure B
Since the normal curve represents a relative frequency distribution it represents in effect a
probability distribution because the relative frequency of any given interval of X-values equals
the probability that a given object selected at random from the population will have a raw score
that falls in the given interval (assuming that selecting each member of the population is equally
likely). Accordingly, the area under the curve along any interval of X-values corresponds the
probability that the continuous variable will equal a value in the corresponding interval. The total
area under the normal curve equals one square unit, representing the population as a whole
(100% of the data) and corresponding to the certain probability.
According to what is called the empirical rule, the area under the normal curve that
corresponds to an interval of values within one, two, and three standard deviations equals about
68%, 95%, and 99.7% of the area respectively. This means that approximately 68% of the data
of a normal population falls within one standard deviation, approximately 95% of the data of a
normal population falls within two standard deviations, and approximately 99.7% of the data of a
54
normal population falls within three standard deviations. The empirical rule is displayed
graphically below in Figure C.
−3
−2
−1
0
1
2
3
Figure C
The empirical rule has implications that can help solve problems. Consider a population
of 500,000 whose distribution is understood to be normal. If the population mean is 12 and the
standard deviation equals 4. How many members of the population have raw scores between 8
and 16? Note that 8 and 16 are both within one standard deviation (that is, one four-unit
interval) from the mean. According to the empirical rule, about 68% of the data fall within one
standard deviation of the mean. Since 0.68×500,000 = 340,000, there are an estimated 340,000
members with raw scores between 8 and 16.
The symmetry of the normal curve also has implications that can help solve problems.
Consider the same population above. How many members of the population have raw scores
between 12 and 16. We know 340,000 members fall between 8 and 16. Note that the mean
equals the midpoint of 8 and 16. Since the distribution is symmetrical, half of the 340,000
members fall between 8 and the mean while the other half falls between the mean and 16. Thus,
170,000 members have a score between 12 and 16.
The previous paragraphs discussed problems that could be addressed by the empirical
rule, which applies to problems involving regions under the normal curve within 1, 2, or 3
standard deviations, which are Z-scores. If we transform X-values to Z-scores, then it is possible
to standardize the normal probability density function by letting µ = 0 and σ = 1 .
The standardized normal probability density function, f ( Z ) , is
given by
f (Z ) =
1
1 − 2 Z2
e
.
2π
Most textbooks provide tables like Table E.2 in our text (Business Statistics, Levine et.
al.). These tables help answer questions involving fractional units of standard deviations. Table
E.2 shows the area under the curve for intervals that extend from negative infinity to a particular
Z-score.
The full table is in the textbook, but the segment of the table below will help answer the
following four questions regarding a population with a mean of 476 and standard deviation of 20.
1) What percent of the population has a score below 506?
2) What percent of the population has a score greater than 506?
3) What percent of the population has a score between the mean and 506?
4) What percent of the population has a score between 468 and 506?
55
To use the table, convert the raw scores to Z-scores as shown below.
506 − 476
= 1.50
20
468 − 476
=
= −0.4
20
Z 506 =
Z 468
Use the Z-score to consult the table as below.
Z
0.37
0.38
0.39
0.40
0.41
0.42
0.43
A
0.6443
0.6480
0.6517
0.6554
0.6591
0.6628
0.6664
Z
0.93
0.94
0.95
0.96
0.97
0.98
0.99
A
0.8238
0.8264
0.8289
0.8315
0.8340
0.8365
0.8389
Z
1.49
1.50
1.51
1.52
1.53
1.54
1.55
A
0.9319
0.9332
0.9345
0.9357
0.9370
0.9382
0.9394
Z
2.05
2.06
2.07
2.08
2.09
2.10
2.11
A
0.9798
0.9803
0.9808
0.9812
0.9817
0.9821
0.9826
Z
2.61
2.62
2.63
2.64
2.65
2.66
2.67
A
0.9953
0.9955
0.9956
0.9957
0.9959
0.9960
0.9961
Z
3.17
3.18
3.19
3.20
3.21
3.22
3.23
A
0.99924
0.99926
0.99929
0.99931
0.99934
0.99936
0.99938
The table contains the answer to question one: 93.32% of the area under the curve falls below
the Z-score of 1.5. Equivalently, 93.32% of the population has a raw score below 506.
For question two, we use the complement principle. If 93.32% of the data falls below the
raw score of 506, then the rest of the data must fall above 506. Subtracting the answer to
question one from the entirety finds the answer to question two: 100% − 93.32% = 6.68% .
For question three, we will find a difference. According to the table, 93.32% of the area
falls below 1.5. Also, 50% of the area falls below the mean. Thus, 43.32% (93.32 – 50 = 43.32)
of the area falls between the mean and the Z-score 1.5. Equivalently, 43.32% of the population
has a raw score between the mean and 506.
Table E.2 in the textbook shows areas associated with negative Z-scores, but our partial
table above does not. Nevertheless, we can answer question four using the symmetrical property
of the normal curve. We need the area below the raw score 468, which has a Z-score of –0.4.
We find the area below a positive 0.4, which is 66.64%. Subtracting the area below the mean
gives the area between the mean and 0.4: 66.64% − 50.0% = 16.64% , but recalling that the
normal curve is symmetrical, we know that 16.64% of the data also falls between –0.4 and the
mean. Since we know from question three that 43.32% of the data falls between the mean and
1.5, we know that 59.96% of the data falls between the Z-scores –0.4 and 1.5 (because 16.64 plus
43.32 equals 59.96). Equivalently, 59.96% of the data falls between the raw scores 468 and 506.
Assignment 5
56
Problems
#1
Use the empirical rule for the normal distribution to answer the following two questions.
A)
In a survey conducted by the National Center for Health Statistics, the sample mean
height of women in the United States (ages 20-29) was 64 inches, with a sample standard
deviation of 2.75 inches. If the sample is normally distributed, about what percent of the
women have heights between 64 inches and 69.5 inches?
B) The mean mileage (in thousands) for a rental car company’s fleet is twelve and the standard
deviation (in thousands) is approximately 3.2. Between what two values do 99.7% of the data
lie? (Assume normality.)
#2
#3
#4
#5
Assume the mean annual consumption of peanuts is normally distributed with a mean of 5.9
pounds per person and a standard deviation of 1.8 pounds per person.
A)
What percent of people annually consume less than 3.1 pounds of peanuts?
B)
What percent of people annually consume more than 3.1 pounds of peanuts?
The weights of adult male rhesus monkeys are normally distributed, with a mean of 15 pounds
and a standard deviation of 3 pounds. A rhesus monkey is randomly selected and weighed.
A)
Assume that a rhesus monkey is randomly selected and weighed. Find the probability
that the monkey's weight is less than thirteen pounds.
B)
Assume that a rhesus monkey is randomly selected and weighed. Find the probability t
hat the monkey's weight is more than seventeen pounds.
According to the National Marine Fisheries Service, the lengths of Atlantic croaker fish are
normally distributed with a mean of ten inches and a standard deviation of two inches.
A)
Assume that an Atlantic croaker fish is selected at random. Find the probability that the
fish is less than seven inches in length.
B)
Assume that an Atlantic croaker fish is selected at random. Find the probability that the
fish is between seven inches and fifteen inches in length.
Assume that a normally distributed population of weights of a certain species of fish has a
mean of forty pounds and a standard deviation of eight pounds. A certain fishing trawler
throws back any netted fish (of the species in question) that do not weight at least sixty-four
pounds. Find the probability that at least one acceptable fish will be caught per netting of 100
fish (of the species in question).
Lecture 6
57
Instruction: Sampling Distributions
A population can be thought of as a set of measurements, either existing or conceptual.
Recall that a sample is a subset of measurements from the population. Recall also that a
population parameter is a numerical descriptive measure of the population. For example, the
population mean µ is a parameter. A statistic, on the other hand, is a numerical descriptive
measure of a sample such as the sample mean X .
Often we do not have access to all the measurements of an entire population, so we must
use samples instead. In such cases, we will use a statistic to make inferences about
corresponding population parameters. In order to evaluate the reliability of our inferences, we
will need to know the probability distribution for the statistic we are using. This probability
distribution is called a sampling distribution. Note that a sampling distribution is specific to a
particular statistic. For example, the sampling distribution of the mean is the distribution of all
the possible sample means of certain-sized samples. While the X -distribution is not the only
sampling distribution, it is a very important one.
Instruction: Sampling Distribution of the Mean
Consider a set of data that includes 100 samples of ten measurements. Suppose the table
below reflects the means of the 100 samples.
Classes of X for the 100 Samples
6<X<7
7<X<8
8<X<9
9 < X < 10
10 < X < 11
11 < X < 12
12 < X < 13
13 < X < 14
14 < X < 15
15 < X < 16
f f/100 = Relative Frequency
3
0.03
5
0.05
9
0.09
12
0.12
14
0.14
17
0.17
16
0.16
14
0.14
6
0.06
4
0.04
Since the relative frequencies may be thought of as probabilities, the table effectively represents
a probability distribution. Since X represents the mean measurement, then we can estimate the
probability of X falling into each class by using the relative frequencies. Accordingly, the
grouped relative frequency distribution given in Figure 1 represents a probability distribution of
the X values.
Lecture 6
58
0.2
0.15
0.1
0.05
0
6.
07.
0
7.
08.
0
8.
09.
9. 0
010
10 .0
.0
-1
1
11 .0
.0
-1
2
12 .0
.0
-1
3
13 .0
.0
-1
4
14 .0
.0
-1
5
15 .0
.0
-1
6.
0
Relative Frequency, f /100
Figure 1
Measurements
Each bar in Figure 1 represents the estimated probabilities of X values based on the table; thus,
the graph represents a probability sampling distribution for the sample mean based on random
samples of ten measurements.
We can see that the distribution is mound-shaped and almost bell-shaped. Irregularities
occur due to the small number of samples used (only 100 sample means) and the rather small
sample size (ten measurements per sample). These irregularities would become less obvious and
even disappear if the number of samples increased, if the number of classes increased, and if the
number of measurements per sample increased. In fact, the curve would eventually become a
perfect bell-shaped curve. This property of the sampling distribution for the sample mean is the
main conclusion of the two theorems discussed in the next portion of this lecture.
Instruction: Central Limit Theorem
The sample mean is said to be unbiased because the mean of all the possible sample
means of a certain size equals the population mean. Indeed, we can rely on the Sample Mean
Theorem stated below.
Let X be a random variable with a normal distribution whose mean is µ and
standard deviation is σ . Let X be the sample mean corresponding to
random samples of size n taken from the X-distribution. Then the Sample
Mean Theorem asserts that the following three statements are true:
a) The X -distribution is a normal distribution.
b) The mean of the X -distribution is µ .
c) The standard deviation of the X -distribution , called the standard
error of the mean, is σ n .
Lecture 6
59
Using the Sample Mean Theorem, we conclude that the X -distribution will be normal provided
that the X-distribution is normal regardless of the sample size. Furthermore, we can convert the
X -distribution to the standard normal Z-distribution using the formula below.
The Z-score for the sampling distribution of the mean is given by
Z=
X − µX
σX
=
X −µ
σ
n
=
(
n X −µ
σ
).
The Sample Mean Theorem gives complete information about the X -distribution provided the
original X-distribution is normal. It turns out, however, that the same conclusions can be had as
long as the sample size is "large enough" regardless of whether or not the X-distribution is
normal. This is the conclusion of the Central Limit Theorem stated below.
The Central Limit Theorem states that if X possesses any distribution with mean
µ and standard deviation σ , then the sample mean X based on a random
sample of size n will have a distribution that approaches the distribution of a
normal random variable with mean µ and standard deviation of σ n as n
increases without limit.
According to the Central Limit Theorem, the X -distribution will approximate the normal as the
sample size n increases without limit. Most statisticians agree that once n reaches at least thirty
the X -distribution will approximate a normal distribution closely enough to treat the
X -distribution as essentially normal.
Instruction: Normal Approximation to the Binomial Distribution
Sometimes the random variable of an experiment is categorical and can take only two
"values" (that is two categorical identities). For instance, consider a vaccine that protects 95% of
adults from a vaccine. From a population of vaccinated adults, a sample of adults could be
chosen and then observed to be protected or not protected. The random categorical variable, X,
takes on the so-called values of protected and not protected. In cases like this, the probability
that 480 adults from a sample of 500 are protected can be calculated using the binomial
distribution, but doing so would require tedious calculations. Luckily, the normal distribution
can be used to approximate the binomial distribution given the conditions stated below.
Let p be the probability of success and let 1 – p be the probability of failure in a single
binomial trial. Let n be the number of trials in the binomial experiment. If n, p, and
1 – p are such that both np > 5 and n(1 – p) > 5, then the normal probability
distribution with µ = np and σ = np (1 − p ) will be a good approximation to the
binomial distribution, and as n gets larger the approximation gets better.
Lecture 6
60
When the conditions above hold, the binomial distribution approximates the normal distribution.
In practice, one must keep in mind that the binomial distribution is discrete while the normal
distribution is continuous. Assume that the normal distribution is being used to approximate the
binomial for X successes. If X is a left endpoint of an interval, we subtract 0.5 to get the
corresponding normal variable X. If X is a right endpoint of an interval, we add 0.5 to get the
corresponding normal variable X. For instance, if we are interested in P ( X < 6 ) where X is a
binomial variable, we would approximate it with a normal variable X by calculating P ( X < 6.5 ) .
Similarly, if we are interested in P ( X > 9 ) where X is a binomial variable, we would
approximate it with a normal variable X by calculating P ( X > 8.5 ) .
Instruction: Sampling Distribution of the Proportion
Assume that 60% of a population meets a particular characteristic (while 40% of the
population does not). The parameter π indicates the proportion of the population that are
identified with the characteristic while the statistic p indicates the proportion of members of a
sample that are identified with the characteristic. If the sample proportion was calculated for
each of every possible n-sized sample, the distribution of the calculated p-values would be the
sampling distribution of the proportion, which is equal to the binomial distribution, which
approximates the normal distribution under certain conditions as we have seen.
The mean of the sampling distribution of the proportion equals π . The standard
deviation of the sampling distribution of the proportion is called the standard error of the
proportion is given by the equation below.
The standard error of the proportion denoted σ p is given
by
σp =
π (1 − π )
n
Using π for the population mean, p for the sample mean, and σ p for sample standard deviation,
we attain the Z-score for the sampling distribution of the proportion given below.
The Z-score for the sampling distribution of the proportion is given by
Z=
p −π
σp
=
p −π
π (1 − π )
n
Assignment 6
61
Problems
#1
Suppose a team of marine biologists studying a population of trout lengths has determined that
X has a normal distribution with µ = 10.2 inches and a standard deviation of σ = 1.4 inches.
What is the probability that the mean length of five trout taken at random is between 8 and 12
inches?
#2
A certain strain of bacteria occurs in all raw milk. Let X be the bacteria count per milliliter of
milk. The health department has found that if the milk is not contaminated, then X has a
distribution that is more or less mound-shaped but not symmetric. The mean of the Xdistribution is µ = 2,500 and the standard deviation is σ = 300 . In a large commercial dairy
the health inspector takes 42 random samples of the milk produced each day. At the end of the
day the bacteria in each of the 42 samples is averaged to obtain the sample mean bacteria count
X.
A) Assuming the milk is not contaminated, what is the mean and standard deviation of the
distribution of X ?
B) Assuming the milk is not contaminated, what is the probability that the average bacteria
count X for one day is less than 2,650 bacteria per milliliter?
C) At the end of each day, the health inspector should write a report to accept or reject the milk
produced that day. What should the health inspector do if the X for the day is greater than
2,650?
#3
The owner of a new apartment building must install twenty-five water heaters. From past
experience in other apartment buildings the owner knows that Sun-Temp is a good brand;
indeed, Consumer Reports has determined that the probability that a Sun-Temp water heater
will last ten years or more is 0.25. What is the probability that eight or more of the owner's
twenty-five new Sun-Temp water heaters will last at least ten years?
#4
According to Horseman's Quarterly, two out of five qualifying racehorses win money. If fifty
qualifying racehorses are selected at random, what is the probability that less than two-thirds of
the fifty horses will win money?
62
Instruction: Confidence Interval Estimates
In this lecture, we begin making statistical inferences, that is, we begin forming
conclusions about the population based on a sample. In particular, we will use X to estimate the
population mean, µ .
If a single sample statistic is used to estimate a population parameter, it is called a point
estimate. Of course, we would not expect a single sample's mean to actually equal the
population mean. Statistical methods have been developed that build an interval of values
around a point estimate in such a way that it is highly likely that the population falls within the
interval. We call these intervals confidence interval estimates.
A point estimate is a single sample statistic used to estimate a
population parameter.
A confidence interval estimate is an interval of values for which the
probability that a population parameter is within that interval is
significant.
Note the modifier "significant" in the definition of confidence interval estimate. What is
significant is open to the statistician performing the estimation. Thus, the level of significance or
confidence is an arbitrary probability value. Usually, the level of "significance"— called the
confidence level—is some constant c close to the numerical value of one such as 0.90, 0.95, or
0.99. In either case, Z c is the number such that the area under the standard normal curve falling
between − Z c and Z c is equal to c. Since area under the standard normal curve corresponds to
probability, we have the desired probability for the chosen confidence level.
If c is the confidence level and x is the point estimate then
P ( −Zc ≤ Z x ≤ Zc ) = c
The value Z c is called the critical value for the confidence level of c.
Consider the probability associated with the confidence level c.
P ( −Zc ≤ Z x ≤ Zc ) = c
This probability is associated with the Z-score of a single sample statistic. Assume that the
single sample statistic is a mean. Then, we know by the Central Limit Theorem that X has a
distribution that is approximately normal with mean µ and standard deviation. Thus a single
sample mean can be converted to a standard Z-score as below.
ZX =
X −µ
σ
n
63
Substituting for Z x into the probability for c, gives
⎛
⎞
X −µ
≤ Z c ⎟⎟ = c .
P ⎜⎜ − Z c ≤
σ n
⎝
⎠
Multiplying all parts of the inequality above by −σ
n gives
⎛
σ
σ ⎞
P ⎜ −Z c ⋅
≤ µ − X ≤ Zc ⋅
⎟ = c.
n
n⎠
⎝
Adding X to all sides of the inequality gives
⎛
σ
σ ⎞
P ⎜ X − Zc ⋅
≤ µ ≤ X + Zc ⋅
⎟ = c.
n
n⎠
⎝
The inequality itself is called the confidence interval for a population mean with known standard
deviation.
The confidence interval for µ with known σ is
X − Zc ⋅
σ
n
≤ µ ≤ X + Zc ⋅
σ
n
where Z c , the critical value for the confidence level of c, is the value
c +1
from the standardized normal
corresponding to the cumulative area of
2
distribution.
Let's calculate a the confidence interval estimate for the population mean with known
population standard deviation. Consider the case of a large national investment firm whose
board wants to know the average amount invested by a client during the previous five years.
Statisticians working for the firm take a random sample of 400 client files for the five-year
period. The mean amount invested for this sample of 400 clients equals $5,250 and the known
standard deviation for all the investments during the five years is $800.00. With this given
information, we can construct a 0.95 confidence interval for µ .
Our arbitrary confidence level, c, is 0.95. Thus, the critical value, Z c , is the value
0.95 + 1
= 0.975, which is 1.96 as shown on a table like
corresponding to the cumulative area of
2
the table below.
64
Z
1.8
1.9
2.0
A for 0.00
0.9641
0.9713
0.9772
A for 0.01
0.9649
0.9719
0.9778
A for 0.02
0.9656
0.9726
0.9783
A for 0.03
0.9664
0.9732
0.9788
A for 0.04
0.9671
0.9738
0.9793
A for 0.05
0.9678
0.9744
0.9798
A for 0.06
0.9686
0.9750
0.9803
Now, the confidence interval can be calculated as below.
$5, 250 − 1.96 ⋅
$800
≤ µ ≤ $5, 250 + 1.96 ⋅
$800
400
400
$5, 250 − $78.4 ≤ µ ≤ $5, 250 + $78.4
$5,171.60 ≤ µ ≤ $5,328.4
The interval from $5,171.60 to $5,328.40 is the 0.95 confidence interval for µ . The firm's board
can be confident that 95% of the time the mean amount invested by clients during the previous
five years is somewhere ranging from $5,171.60 to $5,328.40.
The astute reader will note that the above example is not very practical because it is not
often that the population mean is unknown but the population standard deviation is known. In
such a case, we construct confidence intervals using a distribution that approximates the
standardized normal distribution called the Student's t distribution. This distribution changes
slightly for varying degrees of freedom, a value related to the sample size.* For any degree of
freedom the Student's t distribution approximates the standardized normal distribution and we
can construct a confidence interval for a population mean with unknown standard deviation.
The confidence interval for µ with unknown σ is
X − tn −1 ⋅
S
n
≤ µ ≤ X + tn −1 ⋅
S
n
where tn −1 , the critical value for the confidence level of c, is the value
1− c
from the t distribution with n − 1
corresponding to the upper-tail area of
2
degrees of freedom.
Let's calculate a confidence interval estimate for the population mean with unknown
population standard deviation. Consider the case of Atlas International, a company that
manufactures forklifts. The company has a new assembly line and the managers are interested in
knowing the mean lift capacity for each forklift. For obvious expense reasons, the number of
forklifts available for study is limited. Statisticians working for the company select twelve
forklifts from a trial run of the new assembly line. The mean lift capacity for these twelve
*
The degrees of freedom correspond to the number of values in the sample that can vary, that is, "be free" after all
the previous values have been fixed when used as addends of a sum divided by the sample size and equal to the
sample mean.
65
forklifts equals three tons and the sample standard deviation is 0.25 tons. With this given
information, we can construct a 0.95 confidence interval for µ .
Our arbitrary confidence level, c, is 0.95. The degrees of freedom are 12 − 1 = 11 . Thus,
1 − 0.95
= 0.025,
the critical value, t11 , is the value corresponding to the cumulative area of
2
which is 2.201 as shown on a table like the table below.
degrees
of
freedom
10
11
12
t for uppertail area of
0.25
0.6998
0.6974
0.6955
t for uppertail area of
0.10
1.3722
1.3634
1.3562
t for uppertail area of
0.05
1.8125
1.7959
1.7823
t for uppertail area of
0.025
2.2281
2.2010
2.1788
t for uppertail area of
0.01
2.7638
2.7181
2.6810
t for uppertail area of
0.005
3.1693
3.1058
3.0545
Now, the confidence interval can be calculated as below.
3 − 2.201 ⋅
0.25
≤ µ ≤ 3 + 2.201 ⋅
12
3 − 0.159 ≤ µ ≤ 3 + 0.159
2.841 ≤ µ ≤ 3.159
0.25
12
The interval from 2.841 tons to 3.159 tons is the 0.95 confidence interval for µ . The assembly
line managers can be confident that 95% of the mean lift capacity for the forklifts produced by
the new assembly line is somewhere ranging from 2.841 tons to 3.159 tons.
The previous two examples find confidence intervals for µ , once with σ known, once
with σ unknown. Naturally, confidence intervals can be constructed for other parameters as
well. In particular, we can construct confidence intervals for the population proportion, π , using
the interval detailed in the box below.
The confidence interval for π is
p − Zc ⋅
p (1 − p )
n
≤ π ≤ p + Zc ⋅
p (1 − p )
n
where Z c , the critical value for the confidence level of c, is the value
c +1
corresponding to the cumulative area of
from the standardized normal
2
distribution.
Assignment 7
66
Problems
For the following problems, assume that S σ as long as the sample size is at least thirty.
#1
A random sample of 40 cups of coffee dispensed from an automatic vending machine showed
that the amount of coffee the machine gave was X = 7.1 ounces with standard deviation
S = 0.3 ounces. Find a 90% confidence interval for the population mean of the amount of
coffee dispensed by the machine.
#2
A hospital's chief inspector wants to estimate the average number of days a patient stays in the
mental health ward. A random sample of 100 patients shows the average stay to be 5.2 days
with standard deviation of 1.9 days. Find a 0.90 confidence interval for the mean number of
days a patient stays in the ward.
#3
In wine making, acidity of the grape is a crucial factor. A ph range of 3.1 to 3.6 is considered
very acceptable. A random sample of twelve bunches of ripe grapes was taken from a particular
vineyard. For each bunch of grapes the acidity as measured by ph level was found to be:
3.2
3.5
3.7
3.3
3.4
3.6
3.6
3.1
3.5
3.2
3.1
3.4
Find a 99% confidence interval for the mean acidity of the entire harvest of grapes from the
vineyard of interest.
#4
A random sample of 100 felony trials in San Diego shows the mean waiting time between
arrest and trial is 173 days with standard deviation 28 days. Find a 0.99 confidence interval for
the mean number of days between arrest and trial.
#5
An anthropologist is studying a large pre-historic communal dwelling in northern Arizona. A
random sample of 127 individual family dwellings showed signs that nineteen belonged to the
Sun Clan. Let π be the probability that a dwelling selected at random was a dwelling of a Sun
Clan member. Find a point estimate for π and a confidence interval estimate for π.
67
Instruction: Hypothesis Testing
Suppose the space shuttle carries sundry packets containing 25-seeds of a certain plant
into orbit. These packets are stored in the space station for three months then taken back to earth
by the shuttle. On earth, botanists open each packet and plant each set of 25-seeds in a fertile
garden of its own. After a pre-determined duration, the heights of the resulting plants are
recorded.
The heights in millimeters below correspond to one randomly chosen garden. The
botanists send this data set to a statistician for study.
5.8
6.5
6.6
6.0
5.7
5.9
6.8
5.7
5.8
5.9
5.1
5.7
5.8
5.7
5.6
5.9
5.2
5.6
4.8
5.7
6.4
5.0
5.9
5.9
6.0
The mean of this sample is 5.8 millimeters.
Botanists know that under widely variable conditions on earth, the standard deviation, σ ,
for the plant height is 1.0 mm. In a preliminary investigation, botanists assume σ = 1.0 for the
plants from space-borne seeds. In addition, on earth the mean height, µ , is 5.0 mm.
If the sample above is representative of plants grown from space-borne seeds, it seems
plants from space-borne seeds grow taller on average than plants from normal seeds, but the
statistician must ask, "Is this point estimate really significant?" In this lecture, we demonstrate a
mathematical procedure that leads to an answer to this question.
Before continuing with the specific procedure, we recall some facts about
normally distributed data and state some assumptions. First, recall the facts in the table below.
If data is normally distributed,
68.26% of observations are within 1σ;
95.44% of observations are within 2σ;
99.74% of observations are within 3σ;
therefore,
15.87% of observations fall above (or below)
1σ.
2.28% of observations fall above (or below)
2σ.
0.13% of observations fall above (or below)
3σ.
Second, we make some assumptions for a population with mean µ , standard deviation σ ,
and sample size n.
1. The X -distribution has a mean equal to the population mean: µ X = µ . ∗
2. For the standard deviation of X , we assume σ X =
∗
σ
n
.
The symbol X here indicates a distribution, i.e., there are lots of X 's. The mean of this distribution µ x is the same
as the mean of the population, that is, the X -distribution .
68
3. If n is "large enough," then X is approximately normally distributed.
Now, we can apply a simple application of the normal distribution. We have a particular
value, 5.8, of the distribution, X . We assume that µ X = 5. How likely is it that, although
µ X = 5, our particular sample of plants from space-borne seeds has a mean equal to 5.8?
Let the null hypothesis be H 0 : µ X = 5 . (We call this the null hypothesis because it states
that the difference between 5 and µ X is zero, i.e., the difference is null). Let the alternative
hypothesis be H A : µ X > 5 . Now we assign some level of significance denoted α . In practice, it is
good statistical practice to select the level of significance before any samples have been taken.
The level of significance equals the probability that we will reject the null hypothesis when it is
in fact true and corresponds to the area under the right tail of a standard normal curve. See
graph.
α
↓
µ
µ + zσ
Using the level of significance, we reason as follows:
•
•
If our particular sample mean falls within α , we reject H 0 .
If our particular sample mean falls in the area to the left of α , we accept
H0 .
For our problem, we let α = 0.0013 . For convenience, we choose α so that it
corresponds with the area to the right of µ + 3σ , which equals the critical value of our level of
significance. This means we will reject the null hypothesis only in the case that the sample mean
falls more than three standard deviations above the population mean. Naturally, we expect some
sample means to be larger than the population mean. By assigning α to be 0.0013, we are saying
that the difference in the sample mean and population mean is statistically significant only if the
sample mean is so large that there is only a 0.13% probability that it came from the normal
population.
Now using our second assumption, we find the standard deviation of our sample using
the standard error of the sampling mean.
69
σX =
σ
n
=
1
25
=
1
= 0.2
5
Since we assume X to be normally distributed, we can calculate the Z-score of our sample mean.
Z 5.8 =
5.8 − 5 0.8
=
=4
0.2
0.2
Therefore, we have a sample mean that is four standard deviations above the mean, an unlikely
occurrence. See the graph.
µ µ + σ µ + 2σ µ + 3σ µ + 4σ
Accordingly, we reject H 0 . There is not enough evidence to conclude that the plants from
the space-borne seeds come from a population of plants where the mean height equals five
millimeters. Accordingly, we suspect that the plants from space-borne seeds come from a
population whose mean height is greater than five millimeters. Using our results, botanists might
carry out further studies with seeds in space looking for a possible way to produce larger plants.
The example above is called a one-tail test because the alternate hypothesis created an
emphasis on one tail of the standardized normal distribution. Sometimes the alternate hypothesis
simply asserts that µ X ≠ µ , in which case, a two-tail test is necessary, and the level of
significance corresponds to the combined areas under the curve at two ends of the standardized
normal distribution, which means that the null hypothesis is only rejected if the sample mean's
Z-score falls above or below the critical value associated with ±
α
. Of course, hypothesis
2
testing can also be performed for other parameters such as the population proportion.
Assignment 8
70
Problems
#1
From lots of practice, a golfer knows that his average drive is 250 yards with a standard
deviation of twenty-five yards. Recently, the golfer switched to a new type of driver. Using the new
driver with one hundred shots, the golfer found that his average drive was 261 yards. Perform an
hypothesis test to see if the new driver has changed the average drive of the golfer using a 1% level of
significance.
#2
Roy's commute to weekly commute to work has been 7.5 hrs with a standard deviation of
σ = 0.5 hrs. Recently, however, Roy has changed his route to take advantage of a new toll road. After
forty weeks commuting along the new route, Roy calculates a new mean weekly commute of 7.2 hrs.
Test whether or not the new route has lessened the mean weekly commute for Roy using a 5% level of
significance.
#3
An aerospace company manufactures large rocket engines. To meet NASA specifications, the
rockets should use an average of 5,500 pounds of rocket fuel the first fifteen seconds of operation. The
company claims their rockets meet specifications. To test this claim, an inspector test fired six
randomly selected engines. The average fuel consumption over the first fifteen seconds of operation
was 5,690 pounds of fuel with a standard deviation of 250 pounds. Test whether or not the aerospace
company's claim is justified using a two-tailed hypothesis test with a 0.05 level of significance.
#4
A botanist has produced a new variety of hybrid wheat that is better able to withstand drought.
The botanist knows that for the parent plants the probability of seed germination is 80%. The
probability of seed germination for the hybrid variety is unknown, but the botanist claims that it is
80%. To test this claim 400 seeds from the hybrid plant are planted and 312 germinate. Does the
hybrid plant have an equal probability of germination as the parent plant?
Bonus:
A large company has noticed high absenteeism. According to its records, the company
knows that its employees are absent on average 8.5 times per quarter with a standard deviation of 2.5
absences. In order to test ways to reduce absenteeism, the company restructured the bonus schedule
for 49 employees and noted that these employees were absent on average only 7.8 times per quarter.
Test whether or not the new bonus schedule lowers absenteeism using a one-tailed hypothesis test with
α = 0.05 .